“ 或许你曾经困扰过:明明自家产品有自己的数据,明明算法模型很多开源,可为什么开发起来却问题多多? 要么拿到问题无从下手?”
每一个大厨,心中都有自己的菜谱。要烹制一桌山珍海味,美味佳肴,自然要熟知三件事,原料(模型),调料(优化算法)和秘籍菜谱(这里常常只paper:paper会告诉你解决什么问题用什么模型与算法)。有了这三样,还要基本功扎实,拌、腌、炒、烧、蒸、炸、煮、煲基本手法样样不能少。(基本功扎实才能模型复现)
如果 你说 我只是个小学徒啊,厨艺小白,想自己学可怎么做,那就照着大厨的菜谱学着做。
如果 你说 我是个AI小白,也想了解人工智能深度学习,尤其是想解决应用方面的问题,那就照着下面这张地铁图,按不同方向,来学习菜谱,原料,调料和基本功吧。
01
—
地铁图总览
从AI研究的角度来说,AI的学习和跟进是有偏向性的,更多的精英是擅长相关的一到两个领域,在这个领域做到更好。而从AI应用的角度来说,每一个工程都可能涉及很多个AI的方向,而他们需要了解掌握不同的方向才能更好的开发和设计。因此我们从应用的角度 提出一个 roadmap ,描述不同方向的经典算法模型发展,以及应用上热门的算法。
第一个版本涉及的是 人,物 与艺术,三个大的部分。主要包括了图像方向的十二个子方向,里面列的模型除了商业化的部分外,其他大部分具有相关的开源算法与模型。
详细算法,文章,开源代码等具体可以参见网址,如果喜欢别忘记右上角star一下哦:
https://github.com/weslynn/AlphaTree-graphic-deep-neural-network
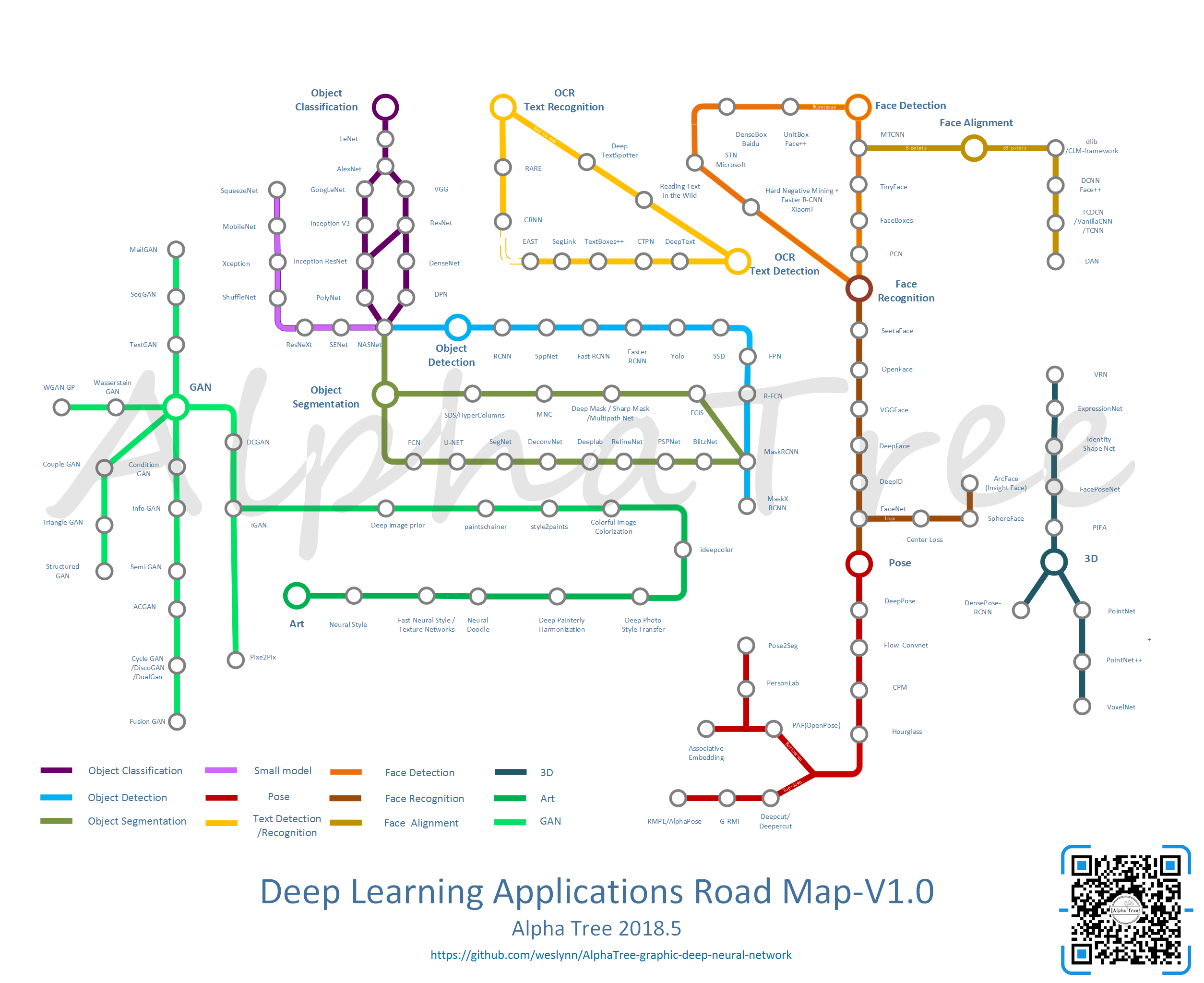
大图链接
https://raw.githubusercontent.com/weslynn/graphic-deep-neural-network/master/map/mapclean_1.0.png
02
—
物
“ 当我们谈论万物时,也许在谈论整个世界”
成千上万的物体组成我们的世界,我们能够区分万物,也希望人工智能能够像我们一样理解这个世界。也就有了物体相关的算法发展。
最基础的是物体分类Object Classification。深度学习的发展证明它非常擅长解决分类问题。Object Classification 是所有发展的基础,很多其他方向的模型都是基于这个主线来改进的。
为什么算法都从图像领域发展而来?由于图像的数据最为丰富,卷积神经网络在图像上分类的稳定有效,1998年,LeNet,这个商用的手写数字识别网络就做出了有力的证明。而到了2012年,Alex Krizhevsky 设计了AlexNet 在当年的ImageNet图像分类竞赛中下第一,开始了深度学习的黄金时代。
学术界发表的paper一般可以分为两大类,一类是网络结构的改进,一类是训练过程的改进,如droppath,loss改进等。而网络结构设计发展主要有两条主线,
一条是Inception系列(即上面说的复杂度),从GoogLeNet 到Inception V2 V3 V4,Inception ResNet。 Inception module模块在不断变化,
一条是VGG系列(即深度),用简单的结构,尽可能的使得网络变得更深。从VGG 发展到ResNet ,再到DenseNet ,DPN等。
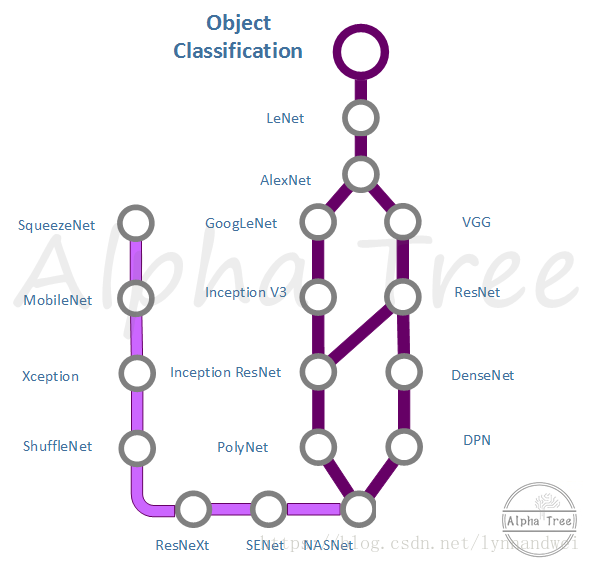
最终Google Brain用500块GPU训练出了比人类设计的网络结构更优的网络NASNet。
此外,应用方面更注重的是,如何将模型设计得更小,这中间就涉及到很多卷积核的变换。这条路线则包括 SqueezeNet,MobileNet V1 V2 Xception shuffleNet等。ResNet的变种ResNeXt 和SENet 都是从小模型的设计思路发展而来。
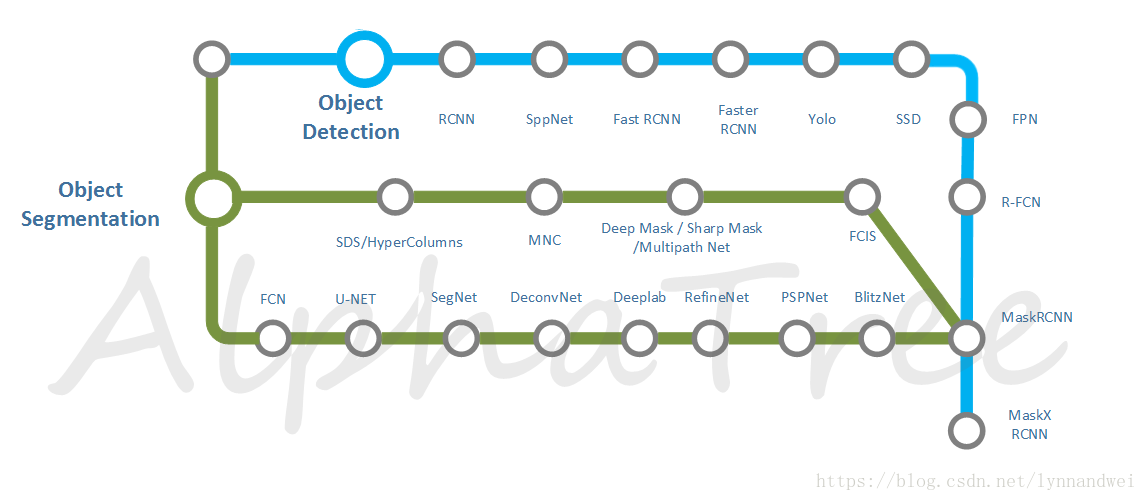
Object Detection 与Object Segmentation
对世界的理解仅仅通过分类知道这张图是关于什么的,是远远不够的,而物体检测和物体分割才能够达到对世界进行与人类似的理解。物体检测和语义分割,以及分割加检测结合的实例分割各发展了几年,但是最终发展到MaskRCNN算法对物体同时完成检测与分割的任务,并且有更优的表现。
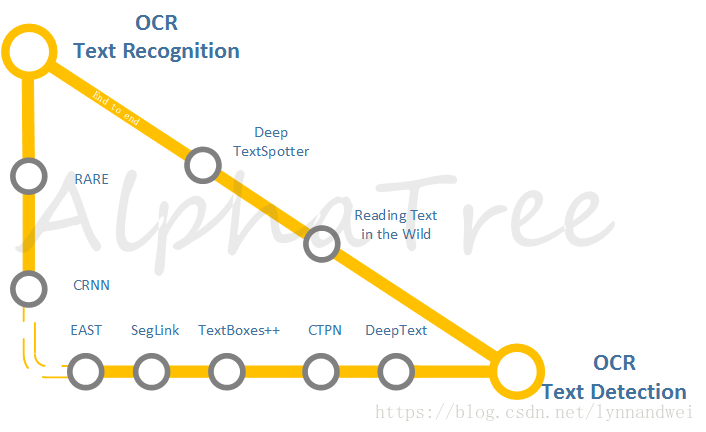
人类文明的传承,离不开的是文字。文字的识别和理解在应用上有着特别的意义。传统的文档识别,早就有了相对稳定的解决方案,开源的Tesseract 是常用的方法,收费的ABBYY则一直效果处于世界前列。而复杂环境中的文字识别则随着DL的发展有着不错的进展。一方面是还是独立的检测与识别,一方面是也有了两者联合的端对端网络的探索。这一块国内白翔老师组 乔宇老师组都有一些模型在应用上效果不错。
03
—
人
“ 当我们谈论人时,也许在尝试了解自己”
能让人工智能像我们一样理解我们自身,能够认识他是谁,理解他表达的喜怒哀乐,能够知道他在做什么,一直就是让人着迷的事情。一直以来,无数科研工作者都在相关方向上奋斗。而DL模拟人类视觉系统,首先取得较好成绩的也是在人脸相关的领域。
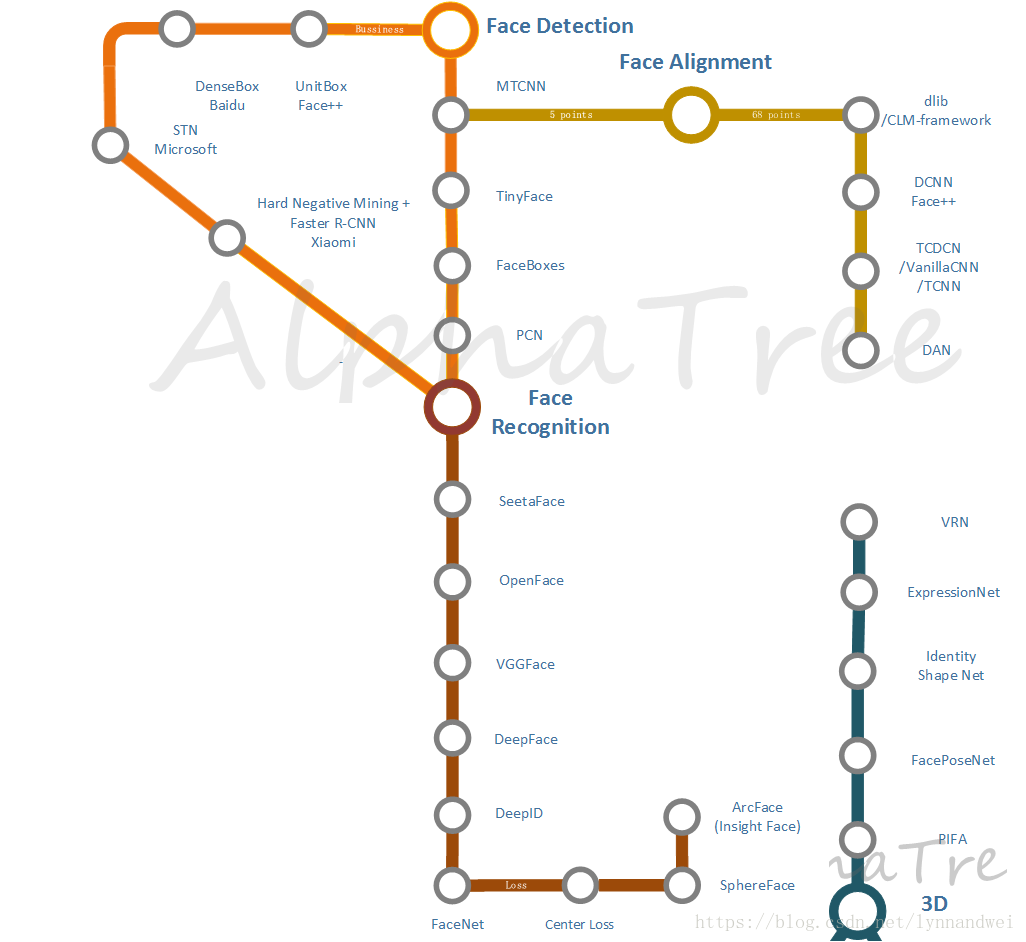
人脸相关领域在应用上的主要有:
1 人脸检测与追踪
2 人脸矫正与关键点检测
3 表情,性别,年龄,种族分析
4 人脸像素基本解析
5 人脸识别
6 活体检测与验证
7 大规模人脸检索
8 人脸的3D重建
其中 表情,性别,年龄,种族分析 就是基本分类问题,使用Object Classification中的方法就可以解决。而活体检测与验证一般通过增加其他设备,使用结构光,如红外,iphonex的FaceID,或者增加活体行为来进行,如常用的点头,眨眼,张嘴等。 而后者的基础,还是在 2 人脸矫正和关键点检测上。大规模人脸检索是在人脸识别的基础上更加工程化的工作。因此在这里我们选择了1 2 5 8 等四个方面来进行分析。
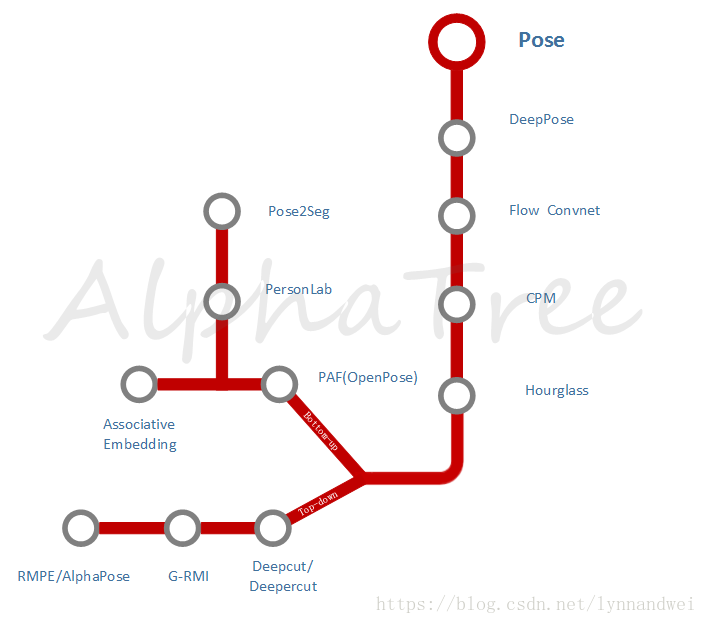
对于人的理解,还有一个关键,就是Pose Estimation 姿态估计
单人算法发展,2016年 stacked hourglass 算法的提出,是一个重要标志,它结构简单,可扩展性强,性能优越,当时就拿下了MPII姿态分析竞赛 的冠军。即便到今天(2018/05/30),这个比赛单人组现在的第一名也是在它的基础上进行改进。
多人的算法,分成两个方向,一个自顶向下 top-down,主要关注上海交大 卢策吾组的RMPE/AlphaPose, 一个自底向上,bottom-up,主要关注CMU的 OpenPose。
此外,基于Pose相关的Segment也在发展,从2D到3D则有DensePose-RCNN。
04
—
艺术
“ 艺术,改变的是你看世界的方式”
艺术是人类对世界的表达,以及我们对虚拟世界的创造。
用科技探索艺术是一件非常有意思的事情,而这些在应用上往往也能产生很好的产品。最知名的就是风格转换 (Neural Style),而探索的方法 有的基于基本的DL网络,有的基于GAN对抗生成网络。因此在这里用渐变色的绿色绘制了这个独特的轨道。深绿色是各种应用,浅绿色则代表了GAN的发展路线。
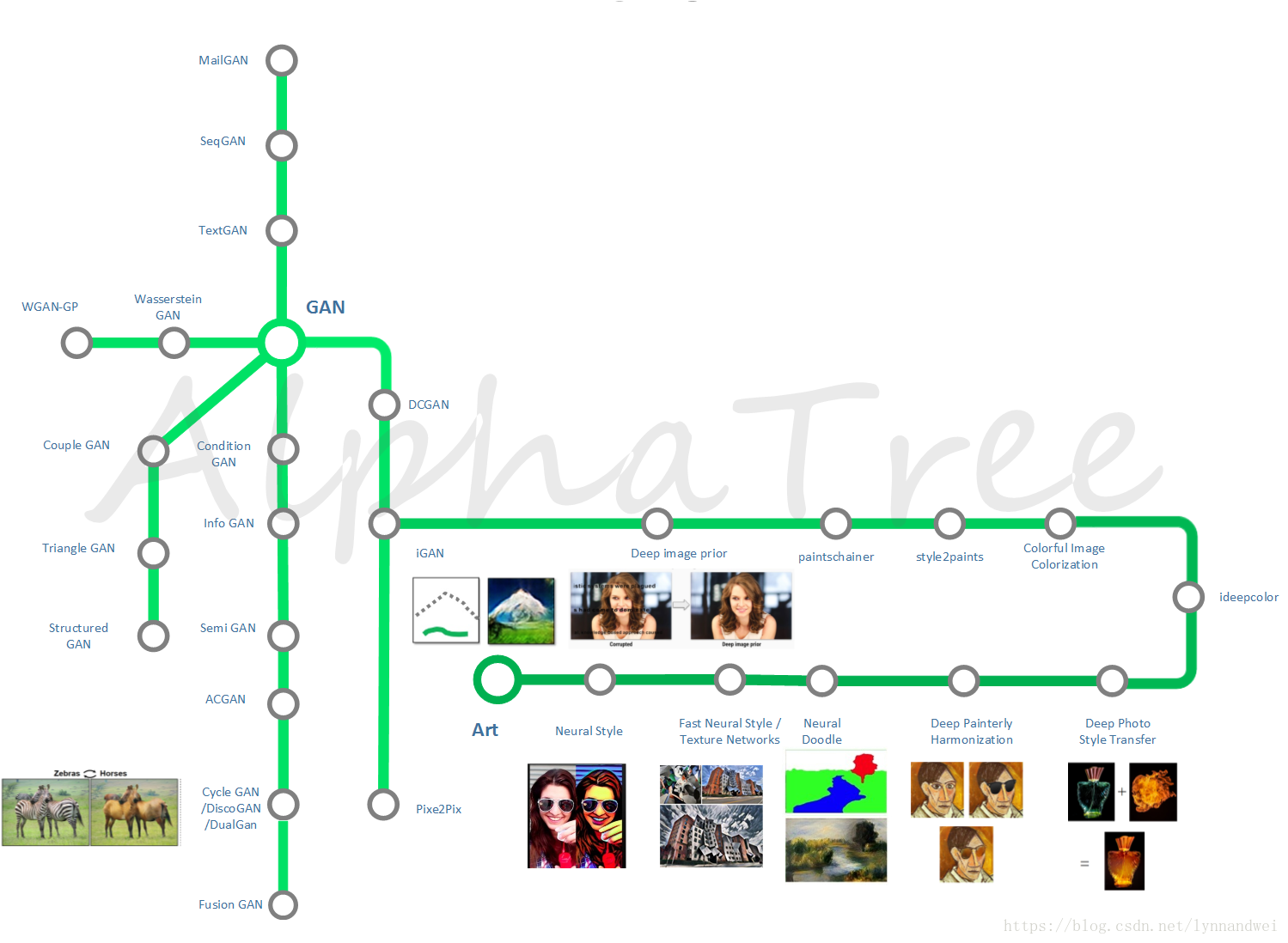
这里列出了很多很酷的应用,譬如说
Neural Doodle 使用深度神经网络把你的二流涂鸦变成艺术品。
Deep Painterly Harmonization 深度学习的一键P图
Deep Photo Style Transfer 风格转换的变种:照片风格转换
自动上色 等等
代码均可在下面网址找到
https://github.com/weslynn/AlphaTree-graphic-deep-neural-network
05
—
关于AlphaTree
AI中每一个领域都在日新月异的成长,而每一位研究人员写paper的风格都不一样,相似的模型,为了突出不同的改进点,他们对模型的描述和图示都可能大不相同。
为了帮助更多的人在不同领域能够快速跟进前沿技术,我们构建了“AlphaTree计划”,对上面提到的文章会对应开源代码,进行统一的图示,便于大家对模型的理解。模型的绘制设计 受到Fjodor van Veen所作的A mostly complete chart of Neural Networks 和 FeiFei Li AI课程中对模型的画法的启发
将一个深度神经网络模型简化成下图:
里面用到的图标有:
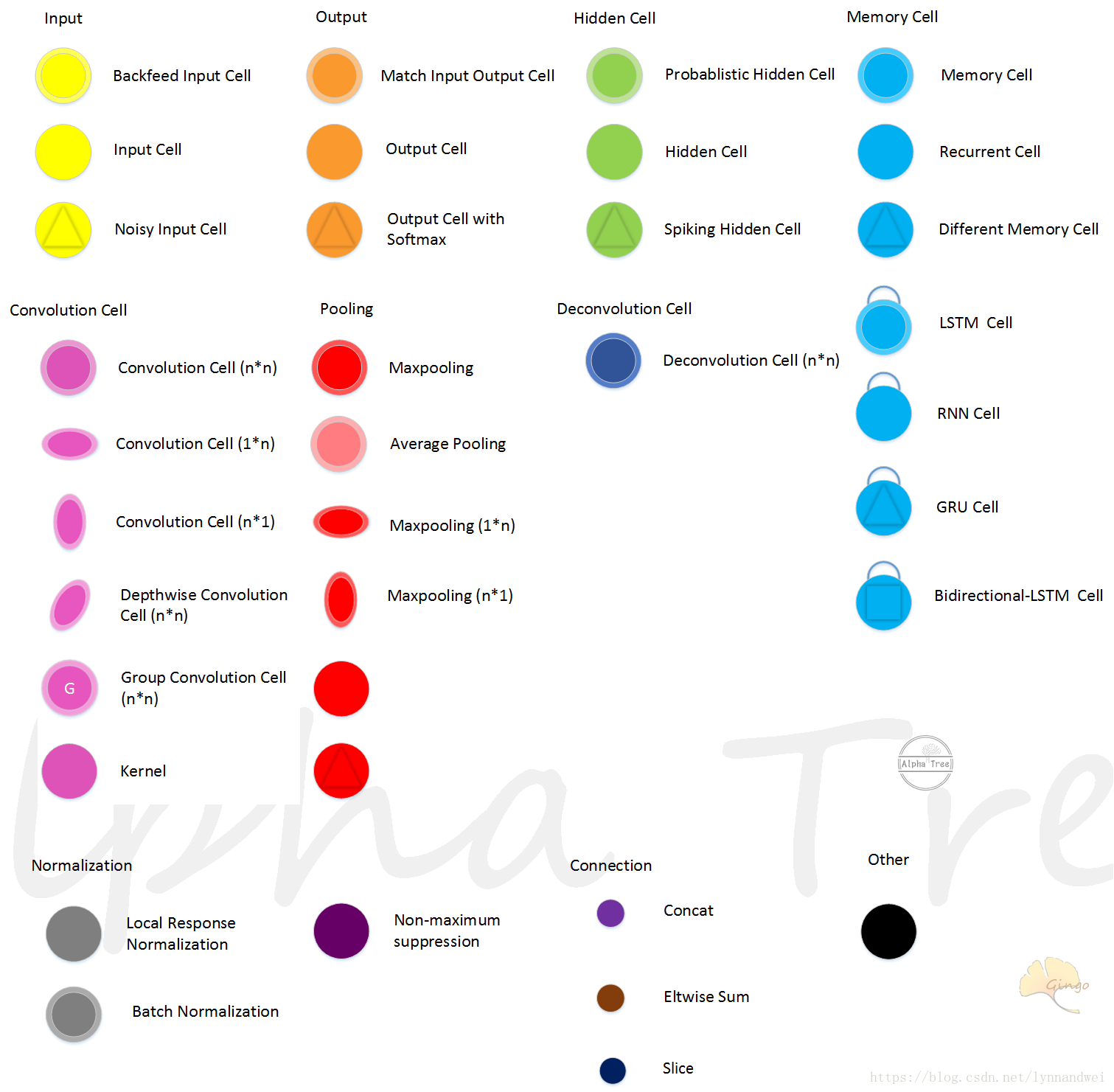
其实 简单来说 ,为了方便记忆,重要的结构只会选用七种彩虹色。 红橙黄绿蓝靛紫。 由于兼容Fjodor van Veen的设置,输入和输出暂时占用了两种颜色。 如果根据需求后期可能将输入输出改成其他不重要的颜色。
紫色(这里用的紫红色)为卷积,
红色为pooling,
绿色为全连接,
蓝色为Memory Cell,
靛(深蓝色)是反卷积。
现在Object Classificaiton部分里面涉及到的模型都根据源代码绘制完成了。
2018/05/30 目前object classification 主干部分基本完成 包括 LeNet, AlexNet, GoogLeNet, Inception V3,Inception-Resnet-V2, VGG, ResNet ,ResNext, DenseNet ,DPN等。
2018/06/15 完成 MobileNet 与 MobileNet V2.
其他: Face : mtcnn
OCR : CRNN CTPN Textboxes Textboxes++
Object Detection:ssd
等
譬如LeNet结构如下,一目了然,三层卷积层,进行了两次maxpooling,两层全连接层,最后输出接softmax:
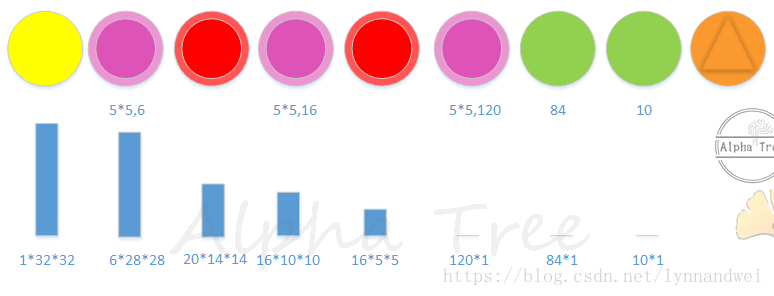
下面一行是输入的图像 经过每一层后输出的尺寸。每个模型也会有对应paper中的结构介绍。欢迎大家围观,也欢迎大家加入。
如果有帮助,记得右上角star哦~ ღ( ´・ᴗ・` )比心
06
—
最后的最后
为什么要画这个?现在画合适吗?
其实 整理发展趋势,跟进论文的事情 一直在做,而图示各种模型的想法也早就有了。但是之前算法更新迭代非常迅速,很多发展方向都没有稳定下来,所以这件事情一直也没有着手去做。
平时沟通中,通过图示模型的表达也帮助过一些人理解,包含CEO,产品经理,程序员,AI小白…… 总体反响还不错,但是之前没有完整系统的输出。之前都是简版的沟通,也担心大家觉得看懂了图示,但觉得和paper的表达会不会有差距,就干脆图示和paper,代码做到了对应。
但是2017年年底 nasnet出来,机器设计的深度神经网络在性能上已经超越了人工设计的网络,在我看来,这是个很重要的信号。AI 从某种意义上来说,成为真正的AI。而以后人们常用的模型结构可能都是神经网络自我设计,或者teaching-student模型学习出来,里面的结构再也不是人类所能理解的。而一个优秀的新模型的诞生,是巨头们计算设备的比拼。
而对于很多公司,重心将转移到如何利用现有的模型,结合自己的数据,设计出最适合自己的模型。全民AI的时代正在到来。
最后,无论是想撩一撩,想加入AlphaTree ,想得到更多资讯,更多福利信息,教学视频,都可以去公众号找哦~