原创 | 文 BFT机器人
2023年8月14日-15日,第七届GAIR全球人工智能与机器人大会在新加坡乌节大酒店成功举办。
在「AIGC 和生成式内容」分论坛上,南洋理工大学科学与工程学院助理教授潘新钢以《Interacitve Point-Dragging Manipulation of Visual Contents》为主题分享了点拖拽的交互式编辑方向研究成果——DragGAN

潘新钢指出,当下用户对图像的创作不只停留于粗粒度编辑,而是期待对图像空间属性进行精细化控制。针对这一需求,DragGAN应运而生。通过DragGAN,用户可以选择性地指定一块可编辑区域,确定A、B两点,然后自如地将点A移动到点 B 的位置。
更重要的是,DragGAN能够呈现的不仅仅是最终编辑完成后的图片,而是整个中间过渡的过程,即一个视频或动画的效果,丰富了其可应用场景。

DragGAN这样一个关键点拖拽式的编辑工具对目前大热的文生图的生成方式提供了一个非常好的补充,一经公布就得到了很多的关注和应用。
图像合成中我们遗漏了什么?

虽然生成式AI已经能够非常好地根据文字生成图片,但是实现更高级的图像微调仍然面临挑战。比如,我们可以把一段话术输入到Midjourney或者Stable Diffusion中,让它生成一个逼真的狮子。但是很多时候,创作的过程并不会在这里结束。
文字对图像的描述只是粗粒度的,用户更多的希望继续细粒度的去微调图像的内容,例如去改变所生成内容的姿态、转动狮子的头、增大或缩小物体的大小、移动物体的位置、甚至改变狮子的表情。这一系列操作都是关于物体空间属性的精细控制,如何对这些属性进行精细控制仍然面临比较大的挑战。
为了实现更精细的图像微调,用户需要提供更加详细和准确的信息描述,包括对图像中每个物体的具体位置、大小、姿态、纹理和颜色等属性进行描述。这些信息对于生成更加逼真和精确的图像来说非常重要。
然而,要实现高质量的图像微调并不是一件容易的事情。需要大量的数据和算法训练来提高生成器模型的精度和效果,而且还需要开发更加智能和自适应的算法来处理不同类型的输入文本。除此之外,还需要考虑如何在生成过程中保护知识产权和隐私,避免侵权行为的发生。
我们应该如何控制空间属性?

为了实现对物体空间属性的精细控制,我们可以通过沿袭文生图的方法,根据文字的描述编辑图片。目前,学术界已经有一些根据文字来改变图片内容的方法,例如让狮子的鼻子向右移动30像素。但是,这种编辑方式存在一些问题。首先,这种文字编辑需要文本模型的支持,以便理解所有可能的物体空间属性编辑方式。除了向右移动之外,还有许多其他方法可以进行编辑。其次,对于语言模型来说,它实际上很难理解30个像素在当前图像中的精确长度。因此,对于目前的文生图语言来说,精确编辑仍然是一个较大的挑战。
什么是交互式点拖动?

用户可以通过点击两个关键点来调整图像的空间属性,将红点所代表的图像语义部分移动到蓝点处,实现对图像空间属性的编辑。
这种方式具有以下几个优点:首先,它非常简单易用,只需要两个点的坐标信息;其次,用户可以精确指定抓取点和目标点的位置和距离,从而实现高度精确的编辑和调整;最后,它非常灵活,可以应用于各种不同的图像编辑场景,例如改变图像的大小、姿态、位置等。
点交拖拽的交互式编辑方向的成果——DragGAN
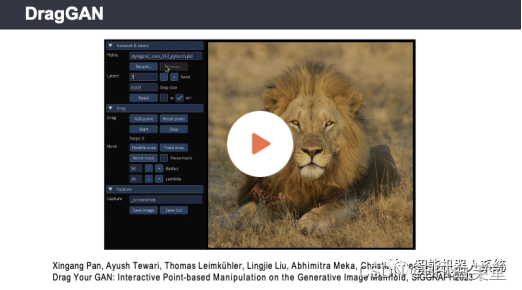
可以看到,用户可以选择性地指定一块可编辑区域,然后通过指定红点和蓝点,算法会将红点移到蓝点的位置。并且值得一提的是,所得到的并不仅仅是最终编辑完成后的图片,而是整个中间过渡的过程。所以,最终呈现出来的是视频或动画的效果,这对于视频或者动画方向来说也具有一定的应用场景。
作者 | 居居手
排版 | 春花
审核 | 猫
若您对该文章内容有任何疑问,请与我们联系,将及时回应。想要了解更多资讯,请关注BFT智能机器人系统~