说明
原文链接:Ako | Proceedings of the Seventh ACM Symposium on Cloud Computing
读了论文后的记录以及部分自己的想法。
ABS
在分布式机器学习中,往往需要根据带宽,工作结点的性能等参数来设置工作结点的个数。
本文提出了一种方法该方法在给定工作结点的带宽和模型大小后,能够自动的调整每轮参与同步的梯度比例,从而达到提高分布式机器学习的计算速度。
1 INTRO
传统的分布式机器学习需要设置工作结点和参数服务器(工作结点进行本地计算后上传数据,参数服务器进行数据聚合后下发新的参数),当模型增大时,节点之间的通信负担将会增大,网络带宽成了分布式机器学习的瓶颈。
而单纯地增加参数服务器的个数,通过不同的参数服务器来管理不同的梯度并不能很好的解决上述的问题(参数服务器与工作结点之间的带宽依然很容易成为瓶颈)。
因此当结点个数固定的时候,如何协调工作结点与参数服务器的比例是实现资源高效利用的关键问题。
关于工作结点与参数服务器的结点个数划分通常是通过人工来微调。而近期提供了一种新的方法:让每个结点上都有一个工作结点和参数服务器,也就是让参数服务器的个数与工作结点的个数相等。但是这在后续的实验发现这样的效果并不是很好。
因此作者希望能够设计一种算法能够尽可能的在分布式机器学习的过程中尽可能的利用计算资源和网络资源。为了防止资源在服务器与工作结点之间的划分,作者直接舍弃了服务器的设置,所有节点均是工作结点(或者说所有节点均能担当服务器的作用,但是这里的服务器与传统的参数服务器又有所不同)。
作者需要实现的主要目标是:
- 具有模型聚合的网络可扩展性(即当升级网络的时候,系统依然能够胜任);
- 收敛的够快(至少应该是和带有参数服务器的架构具有相近的收敛速度);
之前提出过的同步方法(等待所有工作结点本轮完成,参数服务器进行聚合)不能满足上述的第二点目标,因为每轮的更新需要等待计算最慢的工作结点,这会严重影响收敛速度。
本文设计的架构叫做 A k o Ako Ako(毛利与中去学习的意思), A k o Ako Ako能够虽然没有参数服务器,但是它依然能够不牺牲可扩展性和效率,而这主要是因为以下两点原因:
- 可扩展的去中心化同步:工作结点每轮同步不会交换所有的梯度,而是会根据带宽将梯度进行一次划分每次两个结点之间只需要交换部分的梯度( p a r t i a l g r a d i e n t e x c h a n g e partial \ gradient\ exchange partial gradient exchange)。这样的设定让 A k o Ako Ako能够根据网络带宽进行很好的扩展:网络带宽增大时,只需要减少划分数量;网络带宽减少时,只需要增加划分的数量;
- 计算资源与网络资源的解耦:同步的 S G D SGD SGD意味着在等待最慢的结点的时候,大部分的结点并没有进行计算,这导致了计算资源的浪费,同时,同步 S G D SGD SGD中大部分的结点完成某一轮计算的时间非常接近,这会导致,在某段时间网络大量的占用,导致传输速度变慢,而在这个过程中参与通信的结点并不能进行计算,势必导致计算资源不能合理利用。而 A k o Ako Ako去除服务器结点之后,通信变为异步,同时会根据网络带宽减少或增加数据的交换,这使得阻塞的时间会变短,计算资源也就能过尽早的被利用。
后续的实验表明 A k o Ako Ako能够在 I m a g e N e t ImageNet ImageNet上比人工设置服务器个数与工作结点个数的架构的收敛时间减少 25 % 25\% 25%。
2 Resource Allocation in DNN Systems
2.1 A Primer on Deep Learning
这一部分介绍了深度学习使用的方法:使用神经网络和梯度下降进行深度学习。
2.2 DNN Systems With Parameter Servers
这一部分介绍带有参数服务器的架构如何进行深度神经网络的训练。
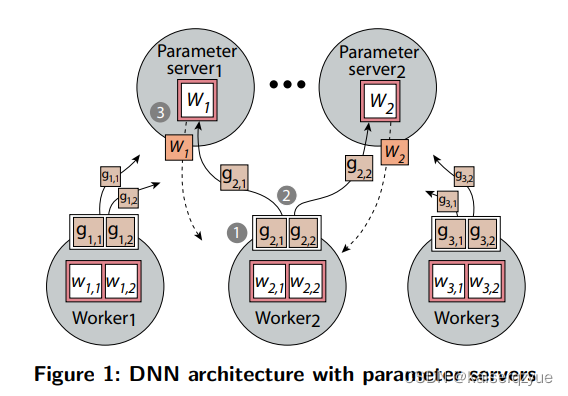
整个的过程大致如 F i g u r e 1 Figure\ 1 Figure 1所示,可以从图中看到存在多个工作结点与参数服务器,每个参数服务器负责一部分参数的更新,整个过程分为三步:
- 每轮开始的时候工作结点需要从参数服务器获取最新的参数;
- 利用获取到的参数对工作结点本地的数据计算损失,根据损失计算出梯度;
- 将梯度发送给对应的参数服务器,参数服务器收到所有参数后,对收到的梯度进行聚合完成权重的更新,至此一轮的训练结束,而训练过程往往需要持续多轮。
上面展示的同步训练(参数服务器需要收集到本轮所有的梯度后才能进行参数的更新)的过程。而已经提出了异步训练的过程,参数服务器并不需要收集到所有的梯度再进行计算,而是只要收到梯度就可以进行更新,不过这存在梯度过期的问题(指更新后收到上一轮其他结点发送的梯度),为了防止梯度过期导致的训练发散,这种系统需要设置一个阈值来缓解该问题。
一个分布式机器学习系统的好坏往往可以通过以下两个指标来评价:
- 硬件效率高:完成一轮迭代所需要的时间;
- 静态效率高:每轮迭代带来的提升(也可以等价成达到固定准确度需要的迭代轮数的倒数),要想提升这一点往往需要尽可能的进行同步操作。
和很多其他的成对出现的评价指标一样,这两者往往也是矛盾的、需要权衡的:如果每轮迭代计算的数据少,那么每轮迭代所需要的时间就会变少,硬件效率就高了,但是由于计算的数据少了,那么每轮迭代带来的提升自然就少了,静态效率就会下降;相反,如果没有迭代计算的数据量多,那么每轮迭代所需要的的时间就会变多,硬件效率就低了,但是每轮的提升就会变大,这样静态效率就提高了。
上述的矛盾在分布式机器学习中的体现是当结点个数固定时增大或减少服务器的比例:当增大服务器比例的时候,能够进行更多的同步操作,那么静态效率就会提高,但是参与每轮计算的工作结点少了,所以硬件效率会有所降低;而当增加工作结点的数量的时候,能进行同步的操作就会减少,此时静态效率会有所下降,但是每轮参与计算的工作结点变多了,硬件效率就会有所提高。
有了上面的认知,也就不奇怪为什么需要进行服务器与工作结点之间的分配了,很多框架都做了这一部分的工作。
2.3 Resource Allocation Problem
这一部分主要说明分配的好坏有很多影响因素。

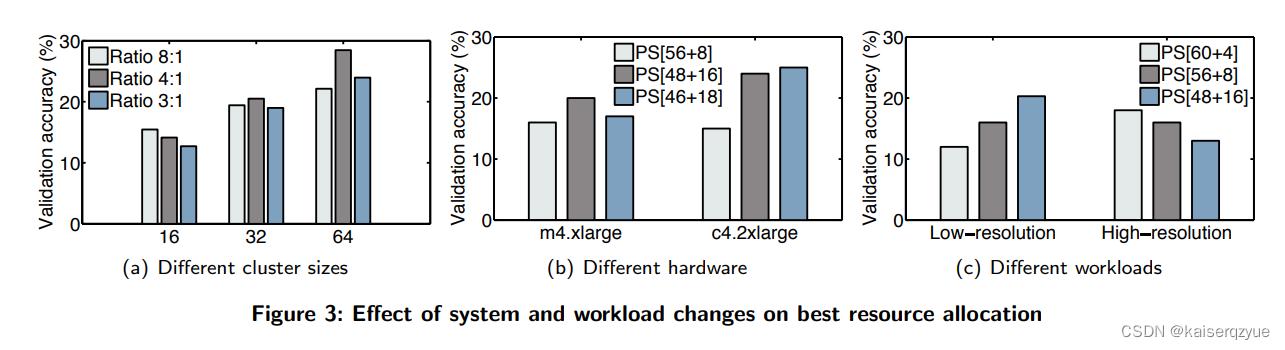
F i g u r e 2 Figure\ 2 Figure 2展示了 64 64 64个机器的情况下,不同的分配方式在某个模型下训练一个小时能够达到的准确度。
集群的大小:即机器个数, F i g u r e 3 ( a ) Figure\ 3(a) Figure 3(a)中给出了不同集群大小下不同分配方法下,训练一小时的准确度。从图中可以看出,当结点个数为 16 16 16的时候,设置 2 2 2个( 8 : 1 8:1 8:1)服务器效果最好,而 32 32 32个结点的时候设置 9 9 9个( 4 : 1 4:1 4:1)服务器效果最好, 64 64 64个结点的时候 16 16 16个( 4 : 1 4:1 4:1)服务器效果最后。
硬件: F i g u r e 3 ( b ) Figure\ 3(b) Figure 3(b)展示了不同机器上不同比例训练一个小时的准确率。
工作量:往往是指数据的不同对于分配方式也有不同的影响, F i g u r e 3 ( c ) Figure\ 3(c) Figure 3(c)展示了高低两种分辨率下不同比例进行训练一小时的准群率。
集中部署方式:集中部署是指每个结点上同时设置工作进程和服务器进程,然后进行进行两个进程可以的内存划分(在这种情况下,可以理解为工作结点和服务器结点的个数相同),但是这种情况的收敛效果并不是很好,在后面的实验会进行详细的说明, F i g u r e 4 Figure\ 4 Figure 4展示了不同的内存分配方式进行训练一小时后的准确率。

3 Partial Gradient Exchange
之前有人提出了是由 A l l − t o − A l l All-to-All All−to−All的方式进行参数的同步,但是这样的话,需要的带宽的程度会达到 O ( n 2 ) O(n^2) O(n2)( n n n为工作结点的个数,这是因为每个工作结点需要和其他所有的工作结点进行数据交换)。
为了减少带宽的压力,作者提出实际上可以不直接进行更新,而是通过延迟更新的方法,每个结点一次性并不发送所有的梯度信息,而是只发送部分的梯度信息,而剩下的梯度信息在后续进行聚合之后发送,这样达到减缓带宽压力的目的。
作者希望提出的方案不仅能够将带宽的压力减少,同时还希望并不怎么影响模型的准确率。
3.1 Partial Gradient Exchange Algorithm
在该算法中,当一个工作结点计算完本地的梯度之后,会将这些梯度划分成不相交的部分( p a r t i t i o n partition partition操作),在每一轮的更新中,一个工作结点只会像其他的工作结点发送一个 p a r t i t i o n partition partition,这样通信的数据量就会有向所有节点发送所有的梯度变成了向所有结点发送部分梯度,如果是划分成 n n n个 p a r t i t i o n s partitions partitions那么通信的数据量就会从 O ( n 2 ) O(n^2) O(n2)变成 O ( n ) O(n) O(n)。而具体划分成多少个 p a r t i t i o n partition partition是需要根据环境的带宽来决定。

F i g u r e 5 Figure\ 5 Figure 5展示了 P G E PGE PGE的详细步骤:
- 各个工作结点计算本地的梯度,并进行划分;
- 向其他工作结点发送某一个梯度信息;
- 其他的工作结点在完成本地梯度的计算后也会继续发送梯度的划分。
更多的细节:
- 梯度划分的个数可能并不会刚好与工作结点的个数相等,在梯度的划分个数较多的情况下,每一轮会依次选择其中的 N − 1 N-1 N−1个进行发送指到保证所有的梯度能够延迟到达其他工作结点(后续会解释如何实现延迟到达),如果梯度划分的个数较少的情况下,则可能会出现多个结点收到的同一份梯度(也就是进行拷贝操作)。
- 在梯度划分个数和结点个数减一相同的情况下(不同的情况下可以通过选择部分或者拷贝保证每轮参与梯度划分个数与结点个数相同),会保证在延迟发送的时候,每一轮其他工作结点当前收到的梯度与之前收到的不同,一个简单的实现是:例如当前有四个工作结点,当前的工作结点 1 1 1将梯度划分为三份 1 , 2 , 3 1, 2, 3 1,2,3那么第一轮工作结点 2 , 3 , 4 2,3,4 2,3,4收到的来自工作结点 1 1 1的梯度划分依次是: [ 1 , 2 , 3 ] [1, 2, 3] [1,2,3];那么下一轮就会收到 [ 2 , 3 , 1 ] [2, 3, 1] [2,3,1]在下一轮会收到 [ 3 , 1 , 2 ] [3, 1, 2] [3,1,2]。(这一部分会在 A l g o r i t h m 1 Algorithm\ 1 Algorithm 1中具体体现)。
上述的过程中表明当一个工作结点进行梯度的发送的时候,另外一个工作结点只能收到部分梯度,这就导致了延迟。为了减少延迟的影响,作者保证能够在一定数量的通信后让之前未参与聚合梯度也参与聚合。
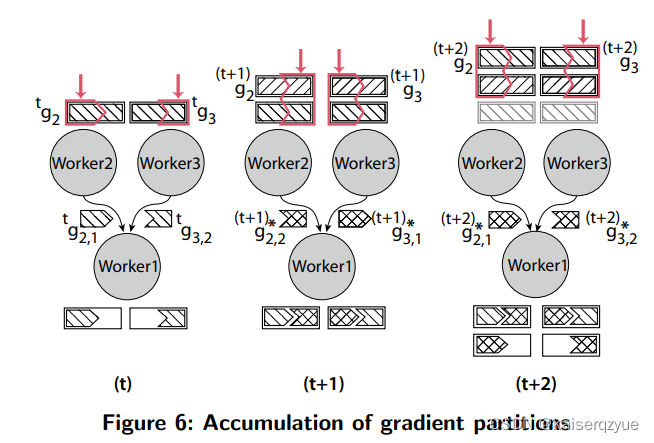
F i g u r e 6 Figure\ 6 Figure 6展示了这个过程:
- 当一个结点在 t t t时刻向其他的结点发送了部分梯度后会在本地节点保存所有的梯度信息,该结点在 t + 1 t+1 t+1时刻计算出新的梯度之后,会将当前算出的梯度与保存的梯度进行一次聚合。
- 工作结点在 t + 1 t+1 t+1时刻发送的梯度则是当前的梯度和之前保存的梯度聚合后的值。
- 工作结点在 t + 2 t+2 t+2时刻同样会重复上述的过程。
可以看到如果将梯度划分为 p p p部分,那么最多 p p p轮之后每个结点会受到 p p p轮之前的所有梯度,也就是梯度所有的梯度的延迟不会超过 p p p轮。
A l g o r i t h m 1 Algorithm\ 1 Algorithm 1展示了具体的各个细节,指的指出的是,其中蓝色圈出的地方应该更改为 k ← ( i + t ) m o d p k\leftarrow (i+t) mod p k←(i+t)modp这样才能保证每轮收到的延迟更新不同(不知道这里作者只是论文中写错了,还是整个实验使用的代码也写错了):

算法中的 c j , s j , i c_j,s_{j, i} cj,sj,i等参数是用来控制同步的延迟的,在 s e c t i o n 3.3 section 3.3 section3.3会详细的说明。
上述的算法过程在工作结点主要就是计算梯度然后进行梯度划分,然后进行局部的梯度聚合,之后决定各个工作结点收到的梯度划分,最后进行发送操作。
A l g o r i t h m 1 Algorithm\ 1 Algorithm 1中的梯度聚合操作为什么会有一个减去一部分梯度的操作?这是因为在进行聚合的时候上一轮的操作实际上已经增加了一部分的梯度,而这一部分增加的梯度在本轮就会不需要再发送(因为所有结点都已经收到了这一部分的梯度),所以在当前轮数的时候需要将这一部分梯度给减掉。
3.2 Number of Gradient Partitions
各个梯度的划分个数可以通过下列的公式来进行确定:
p = ⌈ γ m ( n − 1 ) B ⌉ p = \lceil\frac{\gamma m (n-1)}{B}\rceil p=⌈Bγm(n−1)⌉
γ \gamma γ代表工作结点计算一轮新梯度的速度, m m m代表模型的大小, n n n代表工作结点的个数, B B B代表结点之间的带宽。
那么 m ( n − 1 ) m(n-1) m(n−1)代表一个工作结点像其他所有工作结点发送完整的梯度模型的数据量,为了让计算资源和网络资源尽可能的被利用,我们需要让用于通信的时间和产生一轮新梯度的时间相等,这样在一个梯度产生的时候,信息刚好发送完成,这样又可以进行新的梯度的发送,这样能够让计算资源和网络资源理论上被最大成都利用,也就是需要满足:
m ( n − 1 ) B p = 1 γ \frac {m(n-1)}{Bp}=\frac1{\gamma} Bpm(n−1)=γ1
左边是通信一轮的耗时,右边是计算的耗时,对上式进行整理就可以得到 p p p的计算公式。
注意:上述的过程说明发送梯度的操作是异步的,也就是只要有发送操作就可以进行获取参数进行下一轮梯度的计算而不需要等待当前的参数发送完成并且参与梯度的更新后再进行参数的获取。
3.3 Bounding Staleness
延迟来自于两部分:
- 本地模型的异步更新;(一个工作结点在计算梯度的过程中,其余的工作结点上传了梯度,导致当前正在计算梯度的结点的参数出现过期的情况)
- 分布式聚合的延迟;(按照上面提出的算法必须要等到 p p p轮之后才能收到之前的所在梯度)
为了保证模型的可收敛于是设置了一些参数对于延迟的控制:
- 用 s j , i s_{j, i} sj,i表示工作结点 j j j从工作结点 i i i收到梯度的次数。
- 用 c j c_j cj表示工作结点 c j c_j cj发送梯度的次数
A l g o r i t h m 1 Algorithm\ 1 Algorithm 1中的 p p p代表梯度划分的个数,而 τ \tau τ是一个人为设置的超参数,当 τ \tau τ越大代表可以容忍的延迟越久,而如果越小则代表越不能容忍延迟。
通过对 τ \tau τ的设置来控制对于延迟的控制。
4 Ako Architecture
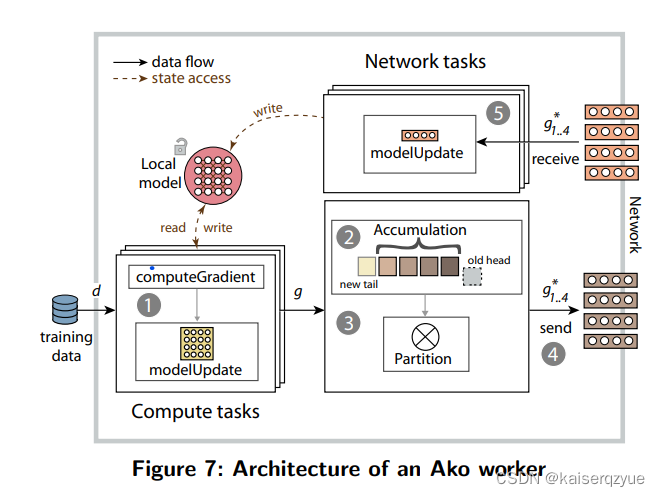
整个设计结构如 F i g u r e 7 Figure\ 7 Figure 7所示:
4.1 Design Goals
- 充分利用网络资源和计算资源。希望在整个的工作过程中,网络资源和计算资源都充分利用,而不是出现大量时间只有计算资源在进行工作或者网络时间进行工作,而另外的资源闲置,例如同步 S G D SGD SGD中在进行通信过程中,计算资源必须等待通信完成才能开始计算,而本文提出的算法由于只需要每次交换的数据量很少所以等待的时间比较短。
- 较低的模型竞争。
- 较低的同步延迟。
- 对于复杂处理的支持。
4.2 Architecture and Implementation
整个架构如 F i g u r e 7 Figure\ 7 Figure 7所示,上述的过程具体描述如下:(其中的大部分不进行说明)
- Gradient Computation:这个过程并不需要锁的参与(获取数据),这虽然可能会导致不一致的问题,但是在整体的准确度的影响却几乎没有。
- Gradient Accumulation
- Gradient Partitioning
- Gradient Sending
- Gradient Receiving:在获取到梯度进行数据更新的过程中不需要锁,也就是还在更新数据的时候,其他的工作结点获取数据可以直接获取,这会导致不一致,但是实验结果表明对于准确性的结果影响微乎其微。
上述的过程中不使用锁能够提高整个系统的吞吐量。
个人看法:不使用锁从实验结果可能是不会影响准确率,但是我认为这可能会导致需要更多的迭代轮数来进行训练,是不是可以尝试在获取数据(读取参数的时候如果参数此时在进行更新则发送更新前的参数,或者等待当前的更新完成后再获取参数)的时候加锁。
4.3 Fault Tolerance
使用的方法类似于 T e n s o r F l o w TensorFlow TensorFlow中的方法使用保存点,定期保存中间状态,当一个结点故障重启后,读取中间状态后继续参与训练。
5 Evaluation
实验目标:
- 探索 A k o Ako Ako的可扩展性和带参数服务器相比的收敛情况
- 观察静态效率和硬件效率
- 通过观测资源的使用来解释 A k o Ako Ako高效的原因
- 研究梯度划分产生的影响
5.1 Experimental Set-up
使用的数据集以及模型可以在原文中找到,这里不赘述,只是说明实验的思路。
实验会做 A k o Ako Ako版本,带有参数服务器的版本, a l l − t o − a l l all-to-all all−to−all版本。
同时如果使用的参数服务器版本的工作结点个数与参数服务器的个数是选取的最优情况下进行实验会被标注带有 ∗ * ∗。
同时还测试了 c o − l o c a t e d co-located co−located版本(工作结点个数与参数服务器的个数相同)。
各个集群的详细信息可以在原文中找到,这里也不做赘述。
5.2 What is the Convergence and Scalability?
F i g u r e 8 Figure\ 8 Figure 8和 F i g u r e 9 Figure\ 9 Figure 9(两个图片的数据集不同)展示了不同的方法随着训练时间的增加的收敛情况。
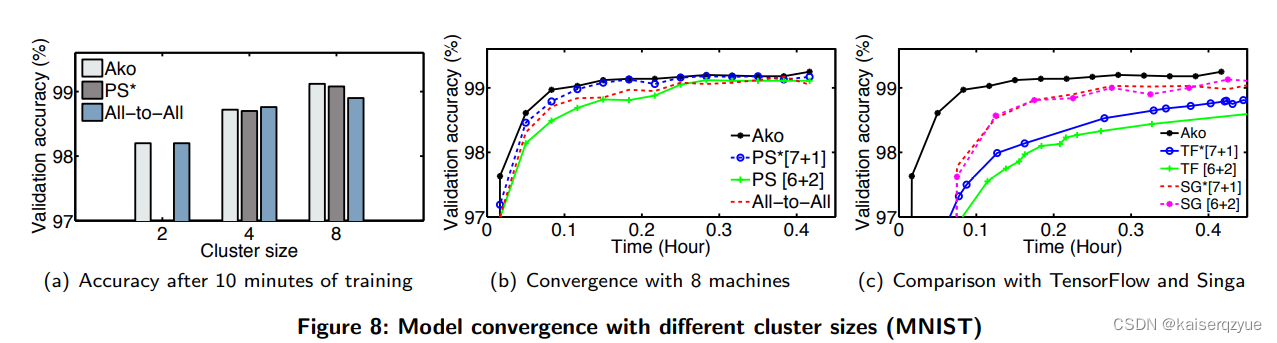
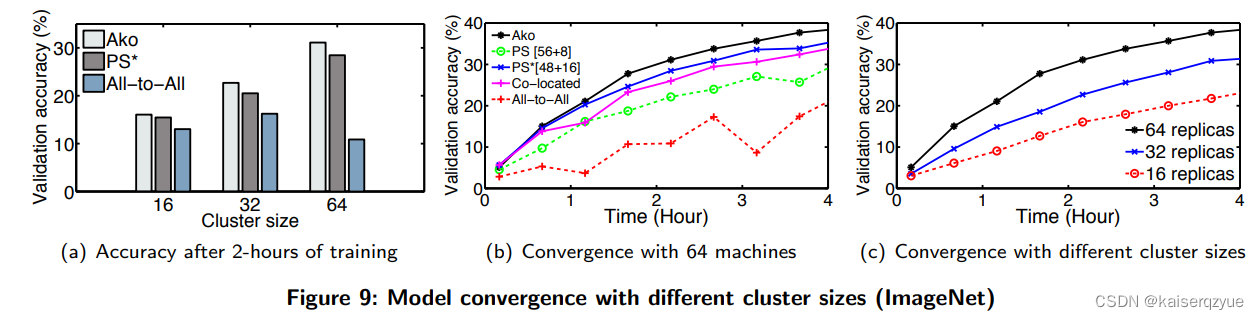
T a b l e 1 Table\ 1 Table 1展现了达到指定的准确度不同的方法需要的时间:

F i g u r e 10 ( a ) Figure\ 10(a) Figure 10(a)中也可以看出 A k o Ako Ako与 T e n s o r F l o w TensorFlow TensorFlow相比的收敛优势。
5.3 What is the Statistical Efficiency?
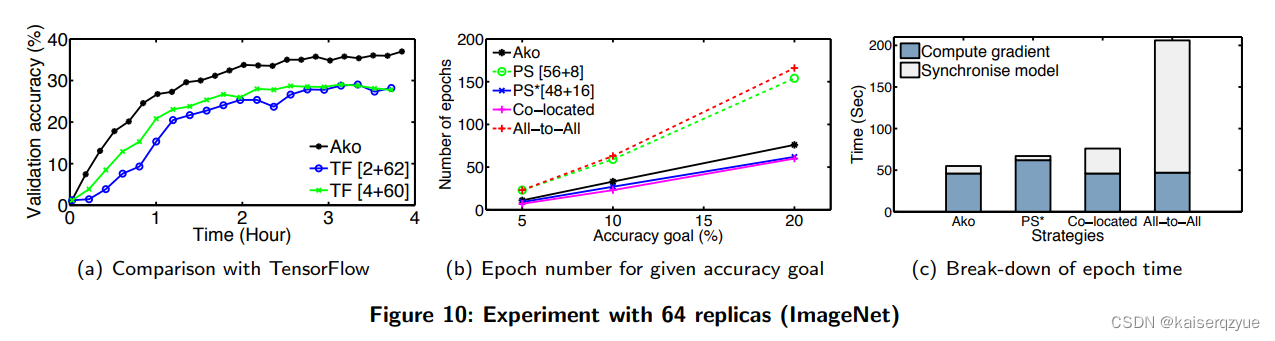
静态效率可以通过固定准确率来记录达到固定准确度需要的轮数来衡量,需要的轮数越少那么静态效率越高, F i g u r e 10 ( b ) Figure\ 10(b) Figure 10(b)给出了达到固定准确率需要的训练轮数。
5.4 What is the Hardware Efficiency?
再一轮更新的过程中往往用于计算的时间的比率越大那么动态的效率越高(参与计算的时间增加)。
F i g u r e 10 ( c ) Figure\ 10(c) Figure 10(c)展示了不同方法每一轮实践中用于计算时间和通信时间的具体比率。
5.5 What is the Resource Utilization?
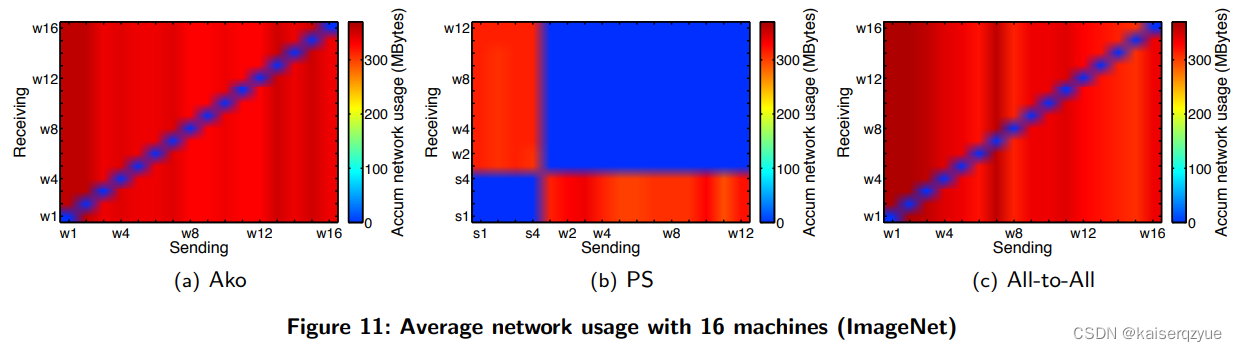
F i g u r e 11 Figure\ 11 Figure 11是不同方法下各个节点之间的网络使用情况。
同时 A k o , P S ∗ [ 12 + 4 ] , A l l − t o − A l l Ako,PS^*[12+4],All-to-All Ako,PS∗[12+4],All−to−All的 C P U CPU CPU平均使用率分别为: 87 % , 84 % , 85 % 87\%,84\%,85\% 87%,84%,85%。
5.6 What is the Effect of Gradient Partitions?
F i g u r e 12 ( a ) Figure\ 12(a) Figure 12(a)展示了不同的划分数训练一个固定时间后的准确率, F i g u r e 12 ( b ) Figure\ 12(b) Figure 12(b)展示了不同梯度划分的情况下实际带宽的利用情况与根据之前的模型预测带宽使用的情况(即 s e c t i o n 3.2 section 3.2 section3.2中的公式)。
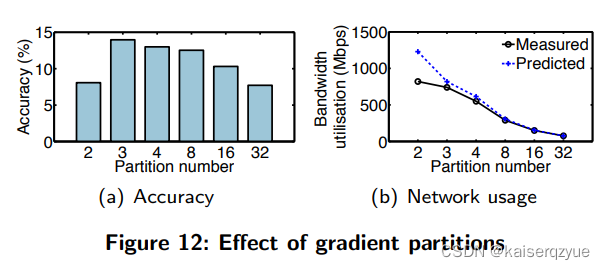
值得注意的是 3 3 3也是之前公式的计算结果,此时如果继续增大划分的个数,各个结点之间的交互将会变得低效(每轮交换的梯度量减少)这会导致静态效率下降(每轮带来的收益减少);而如果减少划分,那么对于带宽会存在压力,导致固定训练时间下的准确度较低。
5.7 What is the Benefit of Gradient Accumulation?
这里的聚合是指之前没有发送的梯度聚合到当前轮数的梯度上一起发送的过程。
下面的实验中使用聚合的就是本文提出的 A k o Ako Ako而不使用聚合则是指 A k o Ako Ako在每轮更新的时候只发送当前轮数的梯度而不聚合之前的梯度。
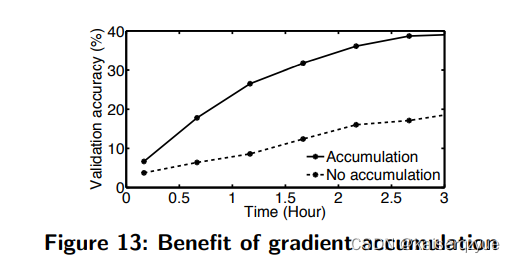
F i g u r e 13 Figure\ 13 Figure 13展示了使用聚合和不使用聚合的准确率随着训练时间的变化。
6 Related Work
介绍了一些带参数服务器的系统和一些不带参数性的系统。
7 Conclusion
设计并实现了 A k o Ako Ako能够充分利用计算资源和网络资源并且模型的准确度没有受到太大的影响。