YOLOV5 optimization on Triton Inference Server
在Triton中部署yolov5目标检测服务, 并分别进行了如下优化:
其中Pipelines分别通过Ensemble和BLS两种方式来实现,Pipelines的infer模块是基于上述1中精简后的TensorRT Engine部署, Postprocess模块则通过Python Backend实现, 工作流参考如何部署Triton Pipelines
Environment
- CPU: 4cores 16GB
- GPU: Nvidia Tesla T4
- Cuda: 11.6
- TritonServer: 2.20.0
- TensorRT: 8.2.3
- Yolov5: v6.1
Benchmark
一台机器部署Triton Inference Server, 在另外一台机器上通过Perf_analyzer通过gRPC调用接口, 对比测试BLS Pipelines、Ensemble Pipelines、BatchedNMS这三种部署方式在并发数逐渐增加条件下的性能表现。
-
python generate_input.py --input_images <image_path> ----output_file <real_data>.json -
利用真实数据进行测试
perf_analyzer -m <triton_model_name> -b 8 --input-data <real_data>.json --concurrency-range 1:10 --measurement-interval 10000 -u <triton server endpoint> -i gRPC -f <triton_model_name>.csv
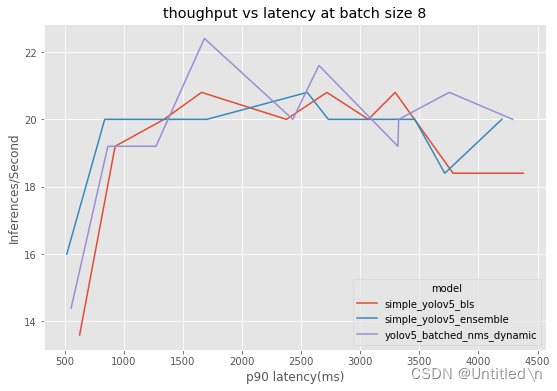
数据显示BatchedNMS这一方式整体性相对更好,更快在并发数较大的情况下收敛到最优性能,在低时延下达到较高的吞吐; 而Ensemble Pipelines和BLS Pipelines则在并发数较小时性能更好,但是随着并发数的增加,性能下降的幅度更大。
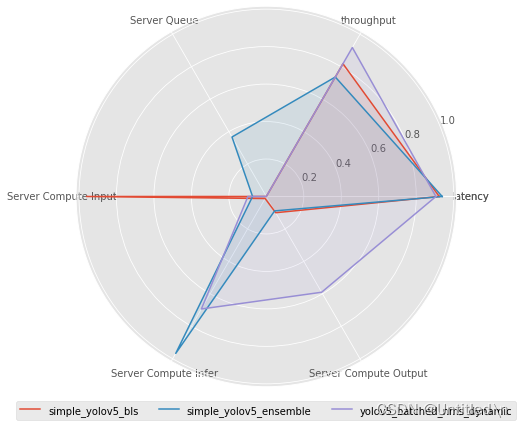
选取了六个指标进行对比,每个指标均通过处理,并归一化到0-1区间,数值越大表示性能越好。每个指标的原始释义如下:
- Server Queue: 数据在Triton队列中的等待时间
- Server Compute Input: Triton处理Input Tensor的时间
- Server Compute Infer: Triton执行推理的时间
- Server Compute Output: Triton处理Output Tensor的时间
- latency: 端到端延迟的90分位数
- throughput: 吞吐