评分模型开发主要分为变量处理、模型建立、评分转换、模型评估4个步骤。
其中在变量处理的时候涉及IV值和WOE值的计算。
基于抽样后得到训练样本集数据,由于变量数量通常较多,不推荐直接采用逐步回归的方法进行筛选。
由于各个变量的量纲和取值区间存在很大的差别,通常会对变量的取值进行分箱并计算 证据权重 WOE值(weight of evidence) ,从而降低变量属性的个数,并且平滑的变量的变化趋势。
接下来,在此基础上计算 信息价值IV(information value) ,
**一般我们选择 IV值大于0.02的那些变量进入模型。
如果IV值大于 0.5 ,改变量就是属于过预测变量,通常被选座分群变量,将样本拆分成多个群体,针对不同的群体分别开发评分卡。**
分群的依据通常也会根据业务上的需要进行设定,常见以区域变量作为分群的标准。
证据权重WOE是用来衡量变量某个熟悉的风险的指标,WOE的计算公式:
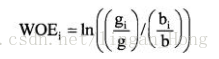

WOE 的值越高,代表着该分组中客户是坏客户的风险越低。
IV值是用来衡量某个变量对好坏客户区分能力的一个指标,IV值公式如下:
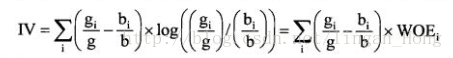
IV值越大表示好坏客户在该变量上的分布差异就越大,也就是该变量的区分能力就越好。
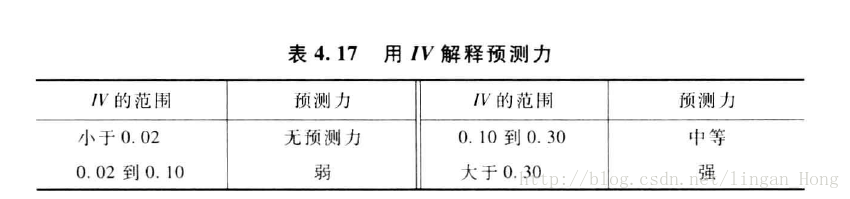
对于IV值的解释预测力
R语言计算IV值很方便:
代码如下:
library('smbinning') #最优分箱
library('DMwR') #检测离群值
library('xlsx')
###客户基本信息 和 征信数据衍生变量
#readFilePath<-"F:/TS/Lending_Club/05_middle/data_loan.csv"
readFilePath<-"C:/Users/Administrator/Desktop/df7.csv"
df<-read.csv(readFilePath)
head(df)
names(df)
#smbinning(df, y, x, p = 0.05)
#df: 数据
#y: 二分类变量(0,1) 整型
#x:连续变量:至少满足10 个不同值,取值范围有限
#p:每个Bin记录数占比,默认5% (0.05) 范围0%-50%
#smbinning.plot, smbinning.sql,and smbinning.gen.
result1<-smbinning(df=df,x="acc_open_past_24mths",y="y",p=0.05)
smbinning.plot(result1,option="WoE",sub="acc_open_past_24mths")
r1 <- merge(result1$x,result1$ivtable)
result2<-smbinning(df=df,x="inq_last_12m",y="y",p=0.05)
smbinning.plot(result2,option="WoE",sub="inq_last_12m")
r2 <- merge(result2$x,result2$ivtable)
r_total <- rbind(r1,r2)
outFilePath <- "F:/TS/Lending_Club/04_output/03_r_smbining/r_best_binging.xlsx"
write.xlsx(r_total, outFilePath)
####################################################################################
# Information Value for all variables in one step ---------------------------
smbinning.sumiv(df=df,y="y") # IV for eache variable
# Plot IV for all variables -------------------------------------------------
sumivt=smbinning.sumiv(df,y="y")
sumivt # Display table with IV by characteristic
par(mfrow=c(1,1))
smbinning.sumiv.plot(sumivt,cex=1) # Plot IV summary table
####################################################################################- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
[1]参考资料:《SAS开发经典案例解析》(杨驰然)
https://blog.csdn.net/lingan_Hong/article/details/77718123