这是pattern的吐槽(跳过)
1.因为工作需要,需要一个单词还原工具,平时用的是php,找到一个php的代码,看了一下还原率不是很满意(主要是有不少常用词库不能还原),毕竟不是专业的nlp工具.
2.然后在网上找到了 NLTK Pattern TextBlob 等工具,发现 Pattern 比较简单, 不需要先标注词性.
3.然后在windows上面开始安装 python3(不确定Pattern 是否不支持python3 我没有看到说不支持所以用的python3,另外英文不好官方文档也没有注意),发现 python3在windows真的是浪费生命啊,根据教材一步一步的安装,缺库装库,装了大半天卧槽这玩意儿居然高速我要 vs2015 卧槽 那玩意儿好几个GB安装要好几个小时(1小时左右吧,编译php的时候装过后来嫌占用空间卸载了.(半天时间后)放弃
4.还是linux好 切换 到虚拟机 centos7,安装python3 pip3
修改 pip源 为阿里云源,然后安装 Pattern
然后后又是各种缺库…说好的 linux 自动安装的了? 说好的自动判断缺库的了?
好吧 无法找到mysql_config文件配置 解决(需要安装mysql-devel)
还有其他问题一路解决(半天时间又没有了)
最后出来一行python 代码报错 卧槽 这是比较流行的开源库啊 也不是缺库 你居然报错 ,看不懂 本来只想简单用一下的. 只能放弃.
5.结论 我真的不适合 python 以前安装python的其他 开源程序也是 没有成功,另外你们说的linux简单的,我发现我在linux 安装程序 除了非常常用的程序以外几乎没有顺利的,什么一条命令解决啊 全是报错 缺库 好多程序用yum 根本无法一次性安装成功.
CoreNLP 是一个java写的nlp工具,可以通过http api调用
优点
java写的,可以通过http api调用 基本没有编程语言限制.
适合 非专业nlp当做工具使用
参考:
下载安装:https://blog.csdn.net/quiet_girl/article/details/79974788
http服务器启动:https://blog.csdn.net/u014033218/article/details/89301572
安装
1.CoreNLP 需要jdk1.8以上版本 ,安装jdk1.8_64. 然后需要吧 jdk目录(java.exe目录)加入到环境变量 path
2.保证cmd中执行 java 不会找不到程序(环境变量),我这边发现一个bug(其中一台有不知道原因),右键在当前位置打开cmd 找不到java,直接打开cmd 定位到 目标目录可以.
3.下载程序
下载地址:https://stanfordnlp.github.io/CoreNLP/,下载界面如下图:
只是单词还原的话不需要下载语言文件(分析中文好像必须要下载语言文件).
启动web服务器
1.解压到英文目录(最好是英文目录).
在CoreNLP根目录(有很多jar文件的目录)执行(启动cmd定位到这个目录),
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000
这句话的意思是 启动web服务 端口 为 9000 超时为15000毫秒,如果有防火墙拦截提醒的点击允许.
#加载中文语言模型
java -Xmx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -serverProperties StanfordCoreNLP-chinese.properties -port 9000 -timeout 15000
2.浏览器访问 http://localhost:9000/
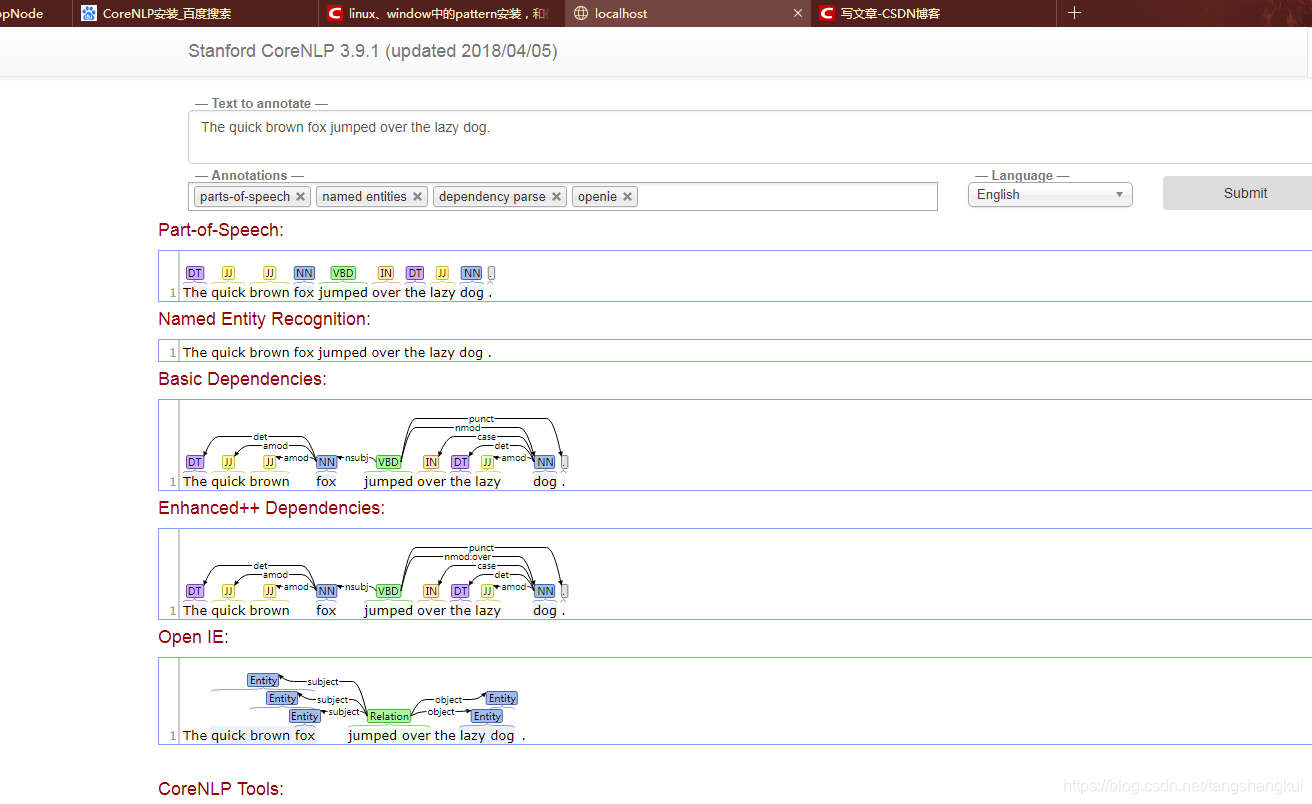
可以测试 效果了
输入需要测试的句子,点击 “submit”,耐心等待,第一次需要初始化 估计需要好几分钟左右(大约占用4Gb内存).如果长时间没有反应 cpu居高不下(5分钟以上),可以考虑结束java进程 重新再来,另外 运行的时候尽量不要运行其他java 程序,我发现 finalshell(java的一个ssh工具)和他就有冲突.
效果如下
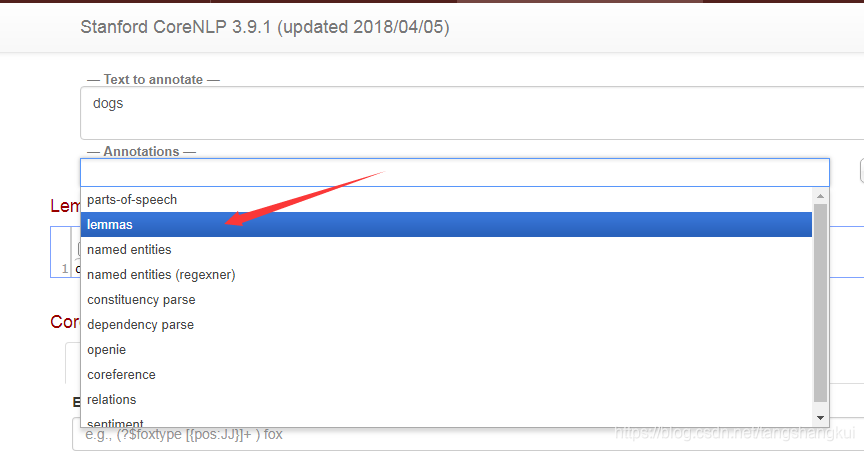
3.如果只需要 词性还原的话 , 删除其他选择 只选择 “lemmas”,这样初始化快一些 内存只需要200m

api调用
1.查询api最简单的方法不是查看官方文档(如果你看得懂英文另说)
2.f12 打开浏览器的调试功能 然后 在页面测试想要的功能,查看http请求.
因为 CoreNLP 默认的请求 不需要安全认证所以非常简单
3.这是单词还原的url 可以看到 url中有一个格式化的时间,然后查询数据通过post发送.
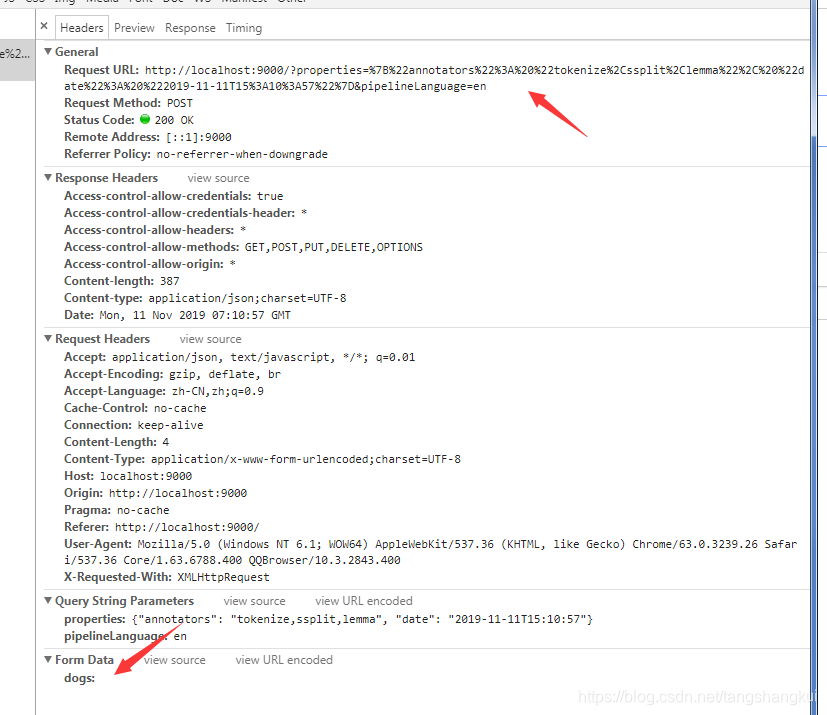
#解码后的url
http://localhost:9000/?properties={"annotators": "tokenize,ssplit,lemma", "date": "2019-11-11T15:10:57"}&pipelineLanguage=en
我们只需要 使用任意可以发送post请求的编程语言(不支持的语言可以是用命令行调用wget),来调用CoreNLP 的接口了.
官方的 php api 我看了一下 并不好用,相关中文教程 说明也基本没有.
其他功能 用户认证
请参考 https://blog.csdn.net/u014033218/article/details/89301572