基于已有的图像模型和文本模型构建多模态模型。最终模型的输入是图像、视频和文本,输出是文本。
Vision encoder来自预训练的NormalizerFree ResNet (NFNet),之后经过图文对比损失进一步学习。图片经过Vision encoder的输出是2D grid,视频按1FPS的频率采样后经过Vision encoder的输出是3D grid,都展开成1D送入Perceiver Resampler。
Perceiver Resampler能将变长的图片或者视频的特征变成固定长度,结构如下图所示。通过输入可学习的latent queries经过Attention和FFW层,得到视觉表示。
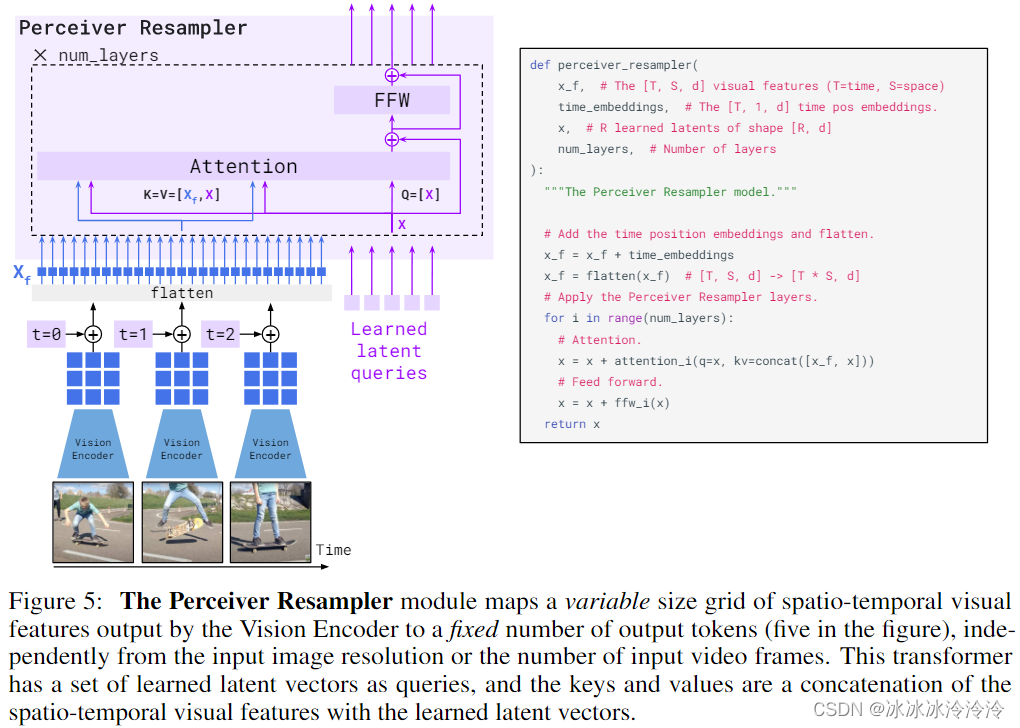
文本模型基于Chinchilla models。
通过gated cross-attention dense模块结合视觉特征和文本特征。gated cross-attention dense模块使用了tanh-gating机制,用tanh(a)乘以文本和视觉模态cross-attention后的输出。a初始化为0。tanh-gating机制保证初始化的时候,模型不受视觉特征的影响,输出就是语言模型的输出。

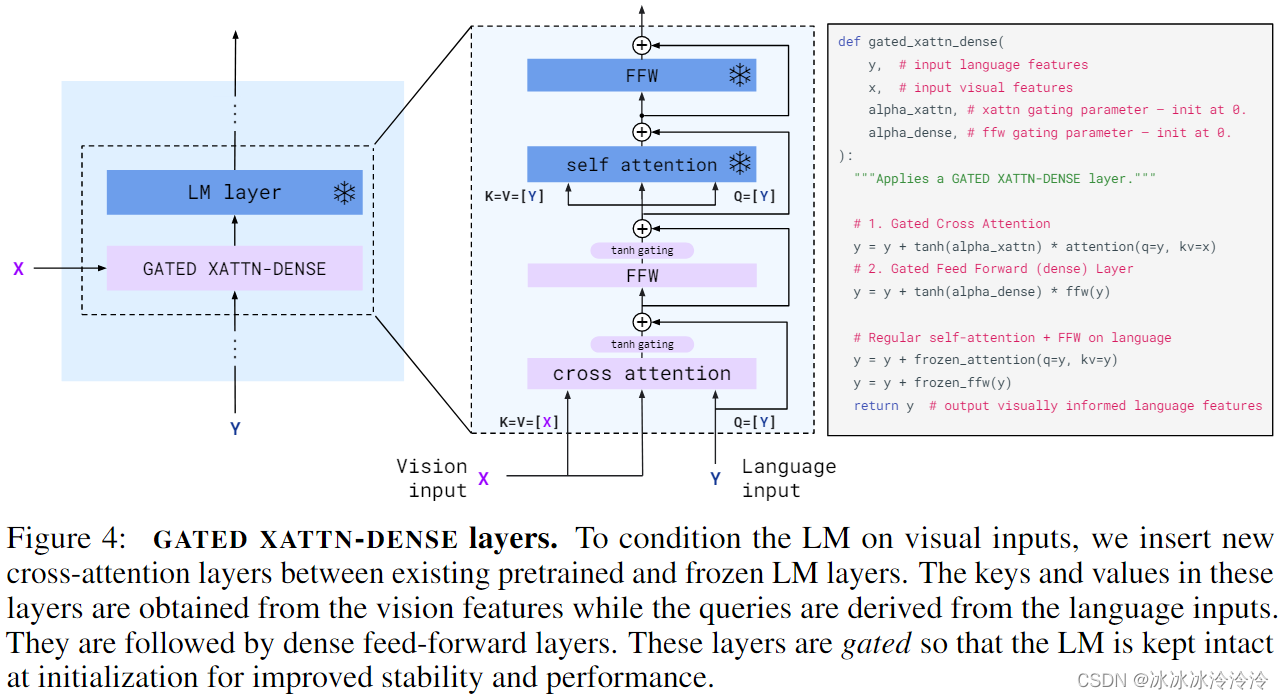
视觉和文本计算cross-attention的时候使用的是single-image cross-attention,在计算图像和文本的cross-attention时,通过mask,让文本token只能看到前面的一幅图像的token。

训练数据数据集包括公开数据和自建数据。M3W(43 million webpages)、ALIGN dataset(1.8 billion images with alt-text 43 million webpages)、312 million image and text pairs、27 million short videos and text pairs。