首先,hash方法用来干什么?
在搞清楚原理之前,我们先站在巨人的肩膀浅浅了解一下hash方法的本质作用。
实质上,它的作用很朴素,就是用key值通过某种方式计算出一个hash码
而且这个hash码我们后面要用来计算key存在底层数组的下标,所以它必须保持一定的随机性,让计算出的数组元素下标更加均衡分布,减少碰撞,其实就是更大程度上的避免hash冲突。
注:保持随机性这一性质,只有在hash方法计算hash值这一步会有所体现,后面的取模运算只是单独的为了取到余数,与保证随机性没有关系
Hash方法是什么?
这里先直观的给出它的源码:

这短短的一行代码,汇聚不少计算机巨佬们的聪明才智。理论上,哈希值(即hashcode方法返回的值)是一个 int 类型,大家都知道int型在java中占4个字节,即32位,范围从 -2147483648 到 2147483648 。前后加起来大概 40 亿的映射空间,只要哈希值映射得比较均匀松散,一般是不会出现哈希碰撞(哈希冲突会降低 HashMap 的效率)。但问题是一个 40 亿长度的数组,内存是放不下的。 HashMap 扩容之前的数组初始大小只有 16 ,所以这个哈希值是不能直接拿来用的,用之前要和数组的长度做取模运算(前文提到的 (n - 1) & hash ),用得到的余数来访问数组下标才行。
对h ^ h>>>16如何理解?
上面的h其实就是我们调用key的hashcode()方法得到的hashcode值,我们将它右移16位(因为是int型,所以总共是32位),前面16位补0,然后我们让它与原本的hashcode值进行异或,因为异或的逻辑是不同为1,相当于就是前16位与后16位进行会进行一次异或,占据最终返回的hash的后16位,然后前16位与进行补位的16个0进行异或,占据最终返回的hash的前16位,得到最终return的hash码。
上面的流程可以参考下面的图进行思考:
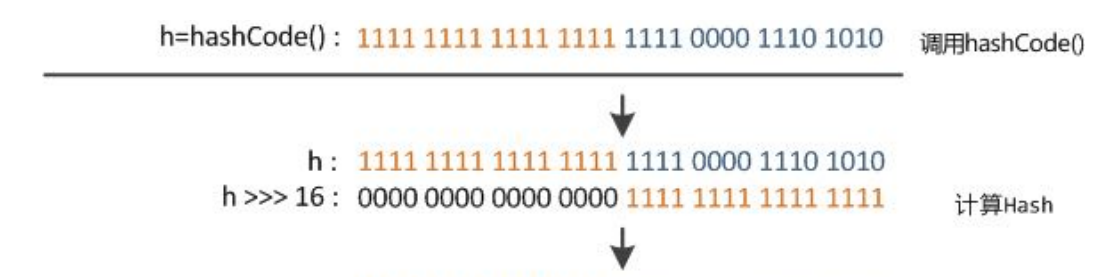
这样大家可能会比较疑惑,这么翻来覆去是为了啥呀,其实都是为了一个:hash码的随机性,目的还是为了避免hash冲突,毕竟hash冲突会降低HashMap的效率。
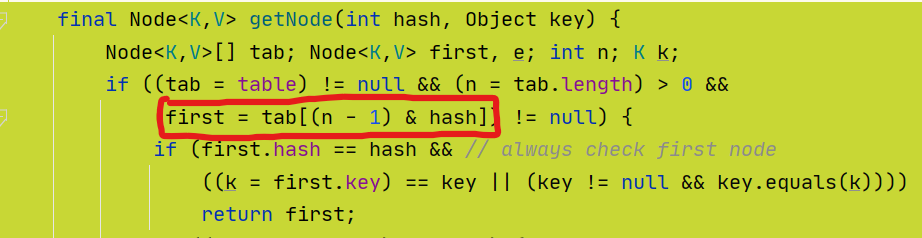
计算好了hash值,然后我们怎么使用hash值计算下标?
我们使用(n - 1)& hash的方式获取下标;(其实就是取模运算)
![]()
大家可能会比较好奇,要进行取模运算难道不该用% 吗?为什么要用位运算 &呢?
这是因为%虽然确实可以实现,但是实际效率却还是不如&
并且我们的&能够取代%,是要有一个前提条件的:
只有当 b 为 2 的 n 次方时,才存在这样一个公式:a % b = a & (b-1)
我们可以对其进行一个验证:
我们来验证一下,假如 a = 14 , b = 8 ,也就是 2^3 , n=3 。14%8 (余数为 6), 14 的二进制为 1110 , 8 的二进制 1000 , 8-1 = 7 , 7 的二进制为 0111 , 1110&0111=0110 ,也就是 0 * 2^0+1 * 2^1+1 * 2^2+0 * 2 ^3=0+2+4+0=6 , 14%8 刚好也等于 6 。害,计算机就是这么讲道理,没办法
顺着上一个问题的图,我们再看这个步骤进行理解:

知道了hash方法的原理以及并将其计算出来,我们还需要知道:
hash方法在哪里被用到?
1.首先当然是我们最经典的put方法 ,后面的putval会通过hash值来计算下标


2.其次是我们使用get方法获取元素时,会调用getNode方法,其中用到hash值