一、准备数据
图像在my_1imgs中,一个是原图jpg,一个是用labelimg画的标签xml文件。(这个画的是一个矩形框)
把自己的数据集(原图和标签准备好后),这两个文件复制到VOCdevkit中,ImageSets为空。
二、修改模型训练预测过程
①去model_data找到文件my_classes.txt,里面写自己的识别类型。
②打开voc_annotation.py文件。只需要修改classes_path="model_data/my_classes.txt"(即定位到刚刚修改的文件,修改为自己的类型)
③运行voc_annotation.py文件生成:之前ImageSets为空,现在里面有test.txt、train.txt等;还有2007_train.txt和2007_val.txt。
一定要看这些文件里面有没有东西,就是自己图像和标签的具体路径和名字,如果为空或者有错,则不能训练。
④打开train.py文件,修改内容准备训练。具体修改可看注释。主要需要修改的为:
a、classes_path(和上面的一样)
b、model_path(预训练权值,.pth文件,这个根据不同模型选择不同的权重,都是需要下载好的,不需要自己编写)
c、Cuda=True或者False(要不要用cuda,显存小不要用;没有NVIDIA就是不能用GPU跑,也不要用)
d、Freeze_Epoch修改,一般为50,100,200等
⑤运行train.py文件。正常会开始运行,对应的权值文件结果会保存在logs文件夹下。
⑥训练结束,找到最好的权值logs/best_epoch_weights.pth文件,这个就是训练过的最终权值文件,预测需要它。
⑦先打开yolo.py文件修改参数再预测。(对应文件修改)有两class YOLO_ONNX和class YOLO下的 "model_path" 和"classes_path"都要修改。
"model_path" : 'logs/best_epoch_weights.pth',
"classes_path" : 'model_data/my_classes.txt',
⑧运行yolo.py,再运行predict.py进行预测,按照上面的做就不会出错,可以正常预测了。
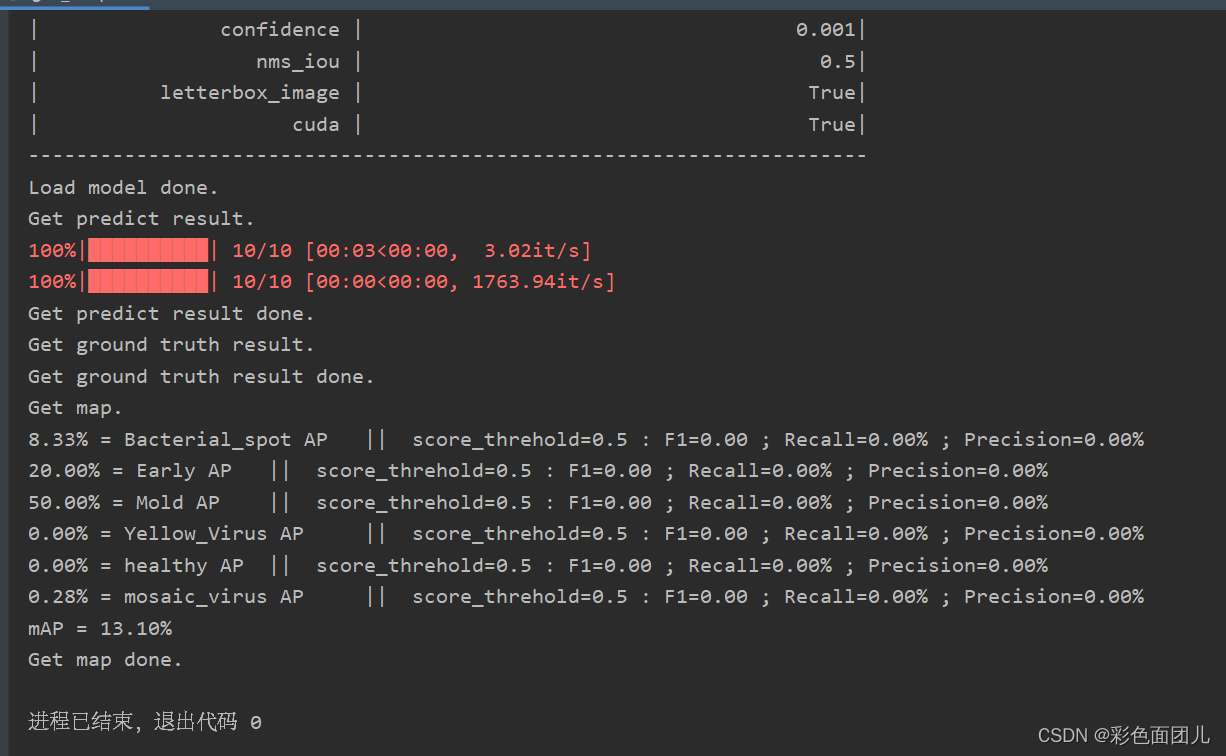
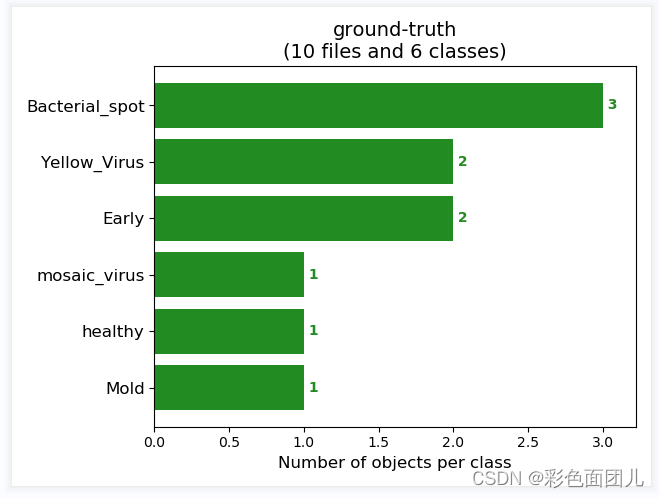
⑨运行get_map.py进行客观指标分析。map(F1 ; Recall ; Precision)结果图都会保存在map_out中。
代码:
链接:https://pan.baidu.com/s/1tEnjGHej39BLnWsRBEMiJg
提取码:t278
说明:win10+64位、pytorch1.2.0、python3.6
数据集准备的不好,所有训练预测效果不好。