全解ORA-1555快照太旧错误原理及解决方案
一、背景说明
不论你的工作是管理Oracle数据库,还是开发、维护Oracle上的应用程序,通常来讲你都遇到过ORA-01555:snapshot too old这样的错误。本文为你详解错误产生的原因以及最佳解决方案。
二、ORA-01555产生的过程
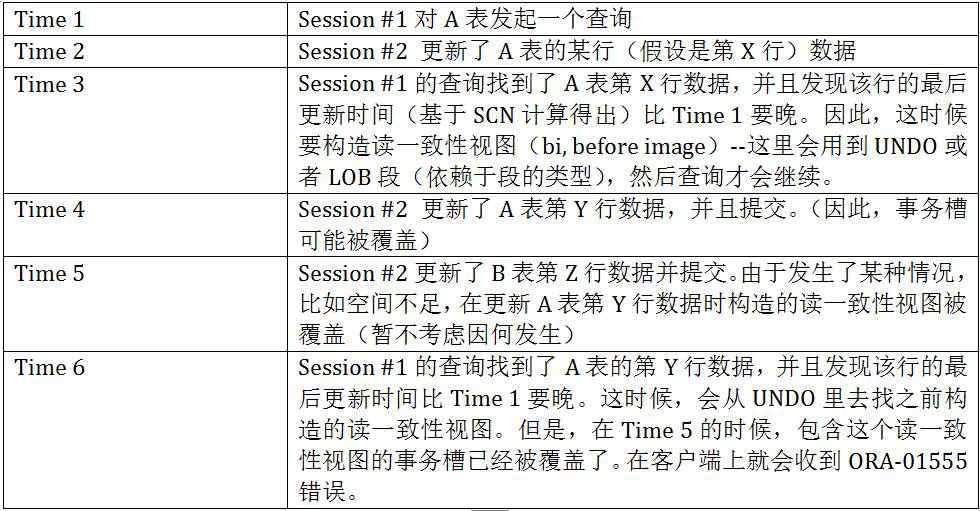
2.1 我们先来看看ORA-01555是怎样产生的:
2.2 错误记录在哪?
通常,这个错误可能会在以下文件中出现:1Alert 告警日志文件
报错信息类似:ORA-01555: snapshot too old: rollback segment number 107 with name “_SYSSMU107_1253191395$” too small
2.3 问题发生时的跟踪日志文件
默认情况,ORA-01555错误发生时不会自动生成跟踪日志文件。但是可以在系统里设置下面的事件,让它在错误发生时同时生成:alter system set events ‘1555 trace name errorstack level 3’;
设置了1555事件后,一旦错误发生,就会生成相应的日志文件,类似如下:

2.4 错误因何而来?
产生ORA-01555错误的根本原因是由于UNDO块被覆盖,查询语句不能获取到查询语句发起时刻所构造的数据副本。
已知的一些原因如下:
2.4.1 相应行数据的UNDO记录已经过期了
这里说的过期是当前时间(指错误发生时)离数据提交时间已经超过UNDO_RETENTION设定的值。一旦已提交的记录对应的UNDO记录是“expired”状态,就表明这部分空间可以重用,数据可以被覆盖了。
你可能会问,为什么有时候我们遇到ORA-01555错误时,查询语句运行时间比UNDO_RETENTION要长很多,有时候却短很多呢?这没什么明确的答案。
要看具体问题发生时UNDO表空间有多忙,系统负载有多大。
提示:一个活动或者未提交的事务对应的UNDO记录会被标记为“ACTIVE”状态。一旦事务被提交,相应的UNDO记录被标记为“UNEXPIRED”,它将持续一段时间(这段时间由UNDO_RETENTION参数决定,如果使用了自动还原段管理,那是由TUNED_UNDORETENTION决定,该参数的值系统自动评估),过了这一时间后,这一UNDO记录被标记为“EXPIRED”,该空间可被重用。
2.4.2 应行数据的UNDO记录状态并非过期,但仍然被覆盖了
发生这种情况有2个必要条件:
- 对UNDO表空间没有设置RETENTION GUARANTEE
- UNDO表空间满了
这个时候,“UNEXPIRED”状态的UNDO记录就可能被覆盖了。
2.4.3 LOB段的LOB段的读一致性副本不再可用
依赖于LOB字段是怎样配置的,in-row还是out-of-row,in-row方式的LOB字段在UNDO表空间中采用跟普通行一样的UNDO算法。
Out-of-row方式的LOB字段不一样,它的读一致性副本有下面2种控制方式:
1)老的方式:PCTVERSIOIN
这个参数关系到LOB数据的一致读,指的是表lob字段所在的表空间需要预留给lob的前映象使用的最大百分比,默认值是10。也就是说,只要使用不超过10%,LOB字段的前映像的数据是不会被覆盖的。
2) 新的方式(自动还原段管理使用):RETENTION
Oracle用UNDO_RETENTION参数来决定在数据库中保留多少已经提交的UNDO数据。这种方式LOB段跟普通段使用相同的过期策略。
在这种方式中,用LOB字段的语句发生ORA-1555的话,意味着:
LOB字段的前映像的使用已经超过PCTVERSION,读一致性数据被覆盖。
或者,LOB字段前映像超过了RETENTION的值,在查询发生时一些行的LOB字段前映像已经被覆盖,于是ORA-1555触发。
三、解决方案
3.1 检查错误日志信息
通过检查告警日志,或者包含ORA-1555错误信息的跟踪日志,可以更详细的看到具体的错误类型:
3.1.1 提示回滚段太小
错误提示:ORA-01555: snapshot too old: rollback segment number with name “” too small(注意!!!这里的回滚段名字是空的)
或者,
ORA-22924: snapshot too old
这种错误说明是访问的UNDO数据是LOB字段类型。
LOB字段访问遇到ORA-1555错误通常是下面几个原因导致的:
LOB段损坏
参考MOS文档检查是不是这个问题:
Document 452341.1 ORA-01555 And Other Errors while Exporting Table With LOBs, How To Detect Lob Corruption
如果没有LOB损坏,检查Retention/Pctversion值是不是合适
参考MOS文档,确认是不是需要调高Retention/Pctversion:Document 846079.1 LOBs and ORA-01555 troubleshooting
ORA-01555: snapshot too old: rollback segment number 107 with name “_SYSSMU107_1253191395$” too small
注意,这个错误提示跟上面不一样。"_SYSSMU107_1253191395$"表示UNDO数据是在UNDO表空间的。
这个ORA-1555错误报告是在访问UNDO表空间的UNDO数据时发生错误的,用后续的方法来诊断问题。
3.1.2 查询耗时太长
在一些ORA-1555错误发生时,会在alert日志或者是应用日志中出现查询失败时耗时(Duration)的秒数:
ORA-01555 caused by SQL statement below (Query Duration=1974 sec, SCN: 0x0002.bc30bcf7):
如果发现错误日志中,duration=0或者耗时很短,查看下面的文档:
Document 1131474.1 ORA-01555 When Max Query Length Is Less Than Undo Retention, small or 0 Seconds
如果查询耗时超过UNDO_RETENTION值,可以考虑加大UNDO_RETETION,同时要记得调整UNDO表空间大小。
如果查询耗时等于或者接近UNDO_RETENTION,继续看后面的文字。
3.2 检查UNDO数据文件

如果UNDO数据文件没有关闭自动扩展功能,可能会导致TUNED_UNDORETENTION值被计算得很高,因此UNDO空间分配是偏向于更多的空间。那怎么破呢?使用UNDO数据文件自动扩展功能,即使存储可用空间足够的时候也带上MAXSIZE。
注意:强烈建议,不要让UNDO表空间里同时存在关闭自动扩展功能的UNDO数据文件和打开自动扩展功能的UNDO数据文件,因为这会导致TUNED_UNDORETENTION计算错乱。
3.3 检查 TUNED_UNDORETENTION

3.3.1 TUNED_UNDORETENTION比MAXQUERYLEN小
这种情况表明UNDO表空间有空间上的压力,实际保留的UNDO记录比理论上的要少。
解决办法是扩大UNDO表空间。
3.3.2 TUNED_UNDORETENTION比MAXQUERYLEN大很多
通常发生在UNDO表空间的数据文件关闭自动扩展选项的情况下。内部的算法是尽可能久的保持UNDO记录,因此TUNED_RETENTION的值就会比较高。
解决办法是把所有的UNDO数据文件设置为自动扩展,并且加上MAXSIZE选项。
长时间运行的查询语句也会把TUNED_RETENTION的值搞得很高。这种情况。就要优化SQL语句来避免保留过多UNDO数据在UNDO表空间了。
通过下面的语句来识别哪些查询语句耗时较久:

3.3.3 状态为ACTIVE/UNEXPIRED的UNDO占比很高

下面的几种情况可能会产生大量ACTIVE/UNEXPIRED状态的UNDO:
UNDO_RETENTION或TUNED_UNDORETENTION值很大
在某个特定时间点产生了大量UNDO数据。用下面的语句诊断:

大量的死事务回滚,使用了闪回数据查询
关于状态为ACTIVE的UNDO的信息,可以参阅:Document 1337335.1 How To Check the Usage of Active Undo Segments in AUM
3.4 UNDO_RETENTION
建议将UNDO_RETENTION的值至少设置为MAXQUERYLEN的一半。如果发生了ORA-1555错误,则适当调大。
到此,基本上涉及ORA-01555错误的原理和诊断就说完了。