文章目录
JAVA12概述
2019年3月19日,java12正式发布了,总共有8个新的JEP(JDK Enhancement Proposals)
JDK 12 is the open-source reference implementation of version 12 of the Java SE12
Platform as specified by by JSR 386 in the Java Community Process.
JDK 12 reached General Availability on 19 March 2019. Production-ready binaries under
the GPL are available from Oracle; binaries from other vendors will follow shortly.
The features and schedule of this release were proposed and tracked via the JEP
Process, as amended by the JEP 2.0 proposal. The release was produced using the JDK
Release Process(JEP 3).
JAVA12的版本特性地址

语法层次的改变
switch 表达式(预览)
传统的switch声明语句(switch statement)在使用中有一些问题:
- 匹配自上而下,若无break,后面的case语句都会执行。
- 不同的case语句定义的变量名不能重复。
- 不能在一个case里写多个执行结果一致的条件。
- 整个switch不能作为表达式返回。
Java 12提供增强版的 switch 语句或称为 "switch 表达式"来写出更加简化的代码。
什么是预览?
Switch 表达式也是作为预览语言功能的第一个语言改动被引入新版 Java 中来的,这是一种引入新特性的测试版的方法。通过这种方式,能够根据用户反馈进行升级、更改。如果没有被很好的接纳,则可以完全删除该功能。预览功能的没有被包含在Java SE 规范中。也就时说: 这不是一个正式的语法,是暂时进行测试的一种语法.
switch详细语法
扩展的 switch 语句,不仅可以作为语句(statement),还可以作为表达式(expression),并且两种写法都可以,使用传统的 switch 语法,或者使用简化的“case L ->”模式匹配语法作用于不同范围并控制执行流。这些更改将简化日常编码工作,并为 switch 中的模式匹配(JEP 305)做好准备。
- 使用 Java 12 中 switch 表达式的写法,省去了 break 语句,避免了因少写 break 而出错。
- 同时将多个 case 合并到一行,显得简洁、清晰也更加优雅的表达逻辑分支,其具体写法就是将之前的 case 语句表成了:case L ->,即如果条件匹配 case ,则执行标签右侧的代码 ,同时标签右侧的代码段只能是表达式、代码块或 throw 语句。
- 为了保持兼容性,case 条件语句中依然可以使用字符 : ,这时 fall-through 规则依然有效的,即不能省略原有的 break 语句,但是同一个 switch 结构里不能混用 -> 和 : ,否则会有编译错误。并且简化后的 switch 代码块中定义的局部变量,其作用域就限制在代码块中,而不是蔓延到整个 Switch 结构,也不用根据不同的判断条件来给变量赋值。
JAVA12之前switch语法的使用:
public static void main(String[] args) {
Month month=Month.APRIL;
String season;
switch (month){
case DECEMBER:
case JANUARY:
case FEBRUARY:
season="冬";
break;
case MARCH:
case APRIL:
case MAY:
season="春";
break;
case JUNE:
case JULY:
case AUGUST:
season="夏";
break;
case SEPTEMBER:
case OCTOBER:
case NOVEMBER:
season="秋";
break;
default:
throw new RuntimeException("NoSuchMonthException");
}
System.out.println(season);
}
JAVA12之后,switch语法的用法:
public static void main(String[] args) {
Month month=Month.APRIL;
String season;
switch (month){
case DECEMBER,JANUARY,FEBRUARY ->season="冬";
case MARCH,APRIL,MAY -> season="春";
case JUNE,JULY,AUGUST -> season="夏";
case SEPTEMBER,OCTOBER,NOVEMBER -> season="秋";
default -> throw new RuntimeException("无效数据");
}
System.out.println(season);
}
可以看出,JAVA开发者或将逐渐的从复杂繁琐的底层抽象代码的编写中解放出来,编写一些更高层次更优雅的代码,减少出错,提高开发效率.。目前switch表达式支持数据类型:byte、char、short、int、enum、String。
API层次的改变
支持数字压缩格式化
NumberFormat 添加了对以紧凑形式格式化数字的支持。紧凑数字格式是指以简短或人类可读形式表示的数字。例如,在en_US语言环境中,1000可以格式化为“1K”,1000000可以格式化为“1M”,具体取决于指定的样式NumberFormat.Style。
var cnf = NumberFormat.getCompactNumberInstance(Locale.CHINA,
NumberFormat.Style.SHORT);
System.out.println(cnf.format(1_0000));
System.out.println(cnf.format(1_9200));
System.out.println(cnf.format(1_000_000));
System.out.println(cnf.format(1L << 30));
System.out.println(cnf.format(1L << 40));
System.out.println(cnf.format(1L << 50));
String新方法
String#transform(Function) : 它提供的函数作为输入提供给特定的String实例,并返回该函数返回的输出。
public static void main(String[] args) {
var result = "波波".transform(input -> input + "烤鸭");
System.out.println(result); //波波烤鸭
result = "bobo"
.transform(input -> input + " kaoya")
.transform(String::toUpperCase);
System.out.println(result);
}
String#indent方法:该方法允许我们调整String实例的缩进。
public static void main(String[] args) {
String result = "Java\nGolang\nPython".indent(3);
System.out.println(result);
}
换行符 \n 后向前缩进 n 个空格,为 0 或负数不缩进。
Files新增mismatch方法
mismatch方法:对比两个文件的差异,返回从哪个字节开始出现了不一致
FileWriter fileWriter = new FileWriter("d:/a.txt");
fileWriter.write("a");
fileWriter.write("b");
fileWriter.write("c");
fileWriter.close();
FileWriter fileWriterB = new FileWriter("d:/b.txt");
fileWriterB.write("a");
fileWriterB.write("1");
fileWriterB.write("c");
fileWriterB.close();
System.out.println(Files.mismatch(Path.of("d:/a.txt"),Path.of("d:/b.txt")));
关于GC的特性
Shenandoah GC
Shenandoah GC:低停顿时间的GC(预览):Shenandoah 垃圾回收器是 Red Hat 在 2014 年宣布进行的一项垃圾收集器研究项目 Pauseless GC 的实现,旨在针对 JVM 上的内存收回实现低停顿的需求。该设计将与应用程序线程并发,通过交换 CPU 并发周期和空间以改善停顿时间,使得垃圾回收器执行线程能够在 Java 线程运行时进行堆压缩,并且标记和整理能够同时进行,因此避免了在大多数 JVM 垃圾收集器中所遇到的问题。据 Red Hat 研发 Shenandoah 团队对外宣称,Shenandoah 垃圾回收器的暂停时间与堆大小无关,这意味着无论将堆设置为 200 MB 还是 200 GB,都将拥有一致的系统暂停时间,不过实际使用性能将取决于实际工作堆的大小和工作负载。与其他 Pauseless GC 类似,Shenandoah GC 主要目标是 99.9% 的暂停小于 10ms,暂停与堆大小无关等。这是一个实验性功能,不包含在默认(Oracle)的OpenJDK版本中。
Shenandoah工作原理:
从原理的角度,我们可以参考该项目官方的示意图,其内存结构与 G1 非常相似,都是将内存划分为类似棋盘的
region。整体流程与 G1 也是比较相似的,最大的区别在于实现了并发的 疏散(Evacuation) 环节,引入的 Brooks Forwarding Pointer 技术使得 GC 在移动对象时,对象引用仍然可以访问。
Shenandoah GC 工作周期如下所示:
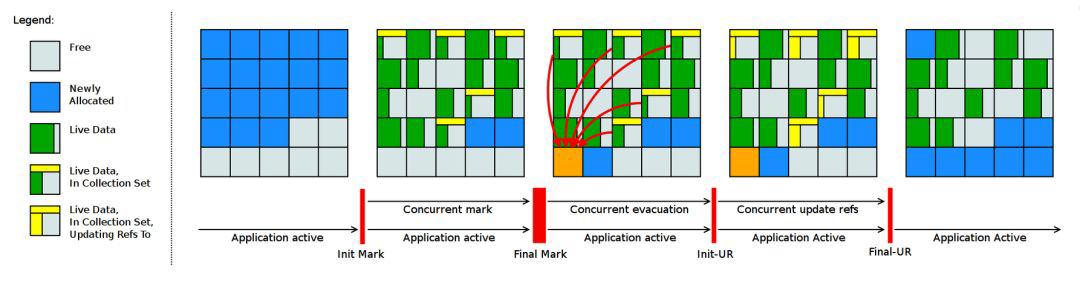
- Init Mark 启动并发标记阶段
- 并发标记遍历堆阶段
- 并发标记完成阶段
- 并发整理回收无活动区域阶段
- 并发 Evacuation 整理内存区域阶段
- Init Update Refs 更新引用初始化 阶段
- 并发更新引用阶段
- Final Update Refs 完成引用更新阶段
- 并发回收无引用区域阶段
了解 Shenandoah GC 的人比较少,提及比较多的是 Oracle 在 JDK11 中开源出来的 ZGC,或者商业版本的 Azul C4(Continuously Concurrent Compacting Collector)。也有人认为Shenandoah 其实际意义大于后两者,原因有一下几点:
- 使用 ZGC 的最低门槛是升级到 JDK11,版本的更新不是一件容易的事情,而且 ZGC 实际表现如何也是尚不清楚。
- C4 成本较高,很多企业甚至斤斤计较几百元的软件成本。
- Shenandoah GC 可是有稳定的 JDK8u 版本发布的。甚至已经有公司在 HBase 等高实时性产品中有较多的实践。
- ZGC也是面向low-pause-time的垃圾收集器,不过ZGC是基于colored pointers来实现,而Shenandoah GC是
- 基于brooks pointers来实现。
不是唯有 GC 停顿可能导致常规应用程序响应时间比较长。具有较长的 GC 停顿时间会导致系统响应慢的问题,但响应时间慢并非一定是 GC 停顿时间长导致的,队列延迟、网络延迟、其他依赖服务延迟和操作提供调度程序抖动等都可能导致响应变慢。使用 Shenandoah 时需要全面了解系统运行情况,综合分析系统响应时间。下面是jbb15benchmark 中,Shenandoah GC 相对于其他主流 GC 的表现。
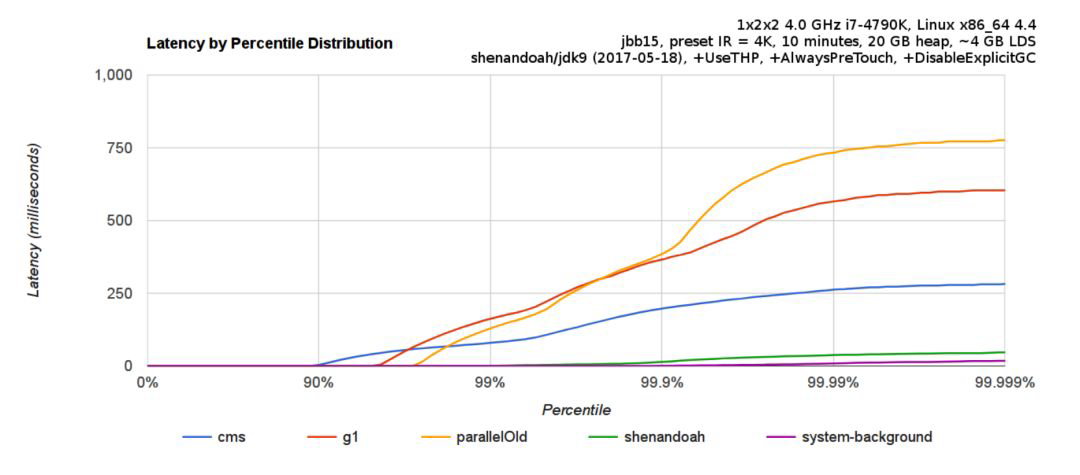
可中断的 G1 Mixed GC
当 G1 垃圾回收器的回收超过暂停时间的目标,则能中止垃圾回收过程。
G1是一个垃圾收集器,设计用于具有大量内存的多处理器机器。由于它提高了性能效率,G1垃圾收集器最终将取代CMS垃圾收集器。该垃圾收集器设计的主要目标之一是满足用户设置的预期的 JVM 停顿时间。
G1 采用一个高级分析引擎来选择在收集期间要处理的工作量,此选择过程的结果是一组称为 GC 回收集(collection set( CSet ))的区域。一旦收集器确定了 GC 回收集并且 GC 回收、整理工作已经开始,这个过程是without stopping的,即 G1 收集器必须完成收集集合的所有区域中的所有活动对象之后才能停止;但是如果收集器选择过大的 GC 回收集,此时的STW时间会过长超出目标pause time。
这种情况在mixed collections时候比较明显。这个特性启动了一个机制,当选择了一个比较大的collection set,Java 12 中将把 GC 回收集(混合收集集合)拆分为mandatory(必需或强制)及optional两部分( 当完成mandatory的部分,如果还有剩余时间则会去处理optional部分)来将mixed collections从without stopping变为abortable,以更好满足指定pause time的目标。
增强G1
目前 Java 11 版本中包含的 G1 垃圾收集器暂时无法及时将已提交的 Java 堆内存返回给操作系统。为什么呢? G1目前只有在full GC或者concurrent cycle(并发处理周期)的时候才会归还内存,由于这两个场景都是G1极力避免的,因此在大多数场景下可能不会及时归还committed Java heap memory给操作系统。除非有外部强制执行。
在使用云平台的容器环境中,这种不利之处特别明显。即使在虚拟机不活动,但如果仍然使用其分配的内存资源,哪怕是其中的一小部分,G1 回收器也仍将保留所有已分配的 Java 堆内存。而这将导致用户需要始终为所有资源付费,哪怕是实际并未用到,而云提供商也无法充分利用其硬件。如果在此期间虚拟机能够检测到 Java 堆内存的实际使用情况,并在利用空闲时间自动将 Java 堆内存返还,则两者都将受益。