搞过其他开发语言的童鞋使用python引包,引用类文件或者方法都会觉得有些别扭吧。反正我是这么觉得的。
比如你有目录文件,结构如下:
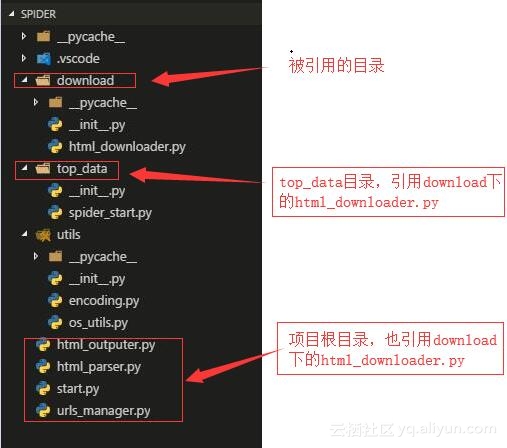

首先项目下任何目录文件调用文件夹下面的文件,比如调用untils文件夹下面的os_utils.py,必须创建一个文件名为__init__.py的文件,即使是空文件。作用是声明该文件夹可以作为项目的目录使用。
现在
根目录下的文件引用文件夹download下的html_downloader.py文件。正常的情况下使用:
from download import html_downloader
from download import html_downloader 是不会报错的,但是执行if __name__ == "__main__" 主函数的话会报错:
No module named XXX
网上解决该问题的方案很多,但是多少有效果。暂时我使用的方式是:
import os #引入os
import sys #引入sys
o_path = os.getcwd() #获取项目的路径,这个路径是绝对路径,比如你的项目放在D盘根目录下,打印o_path的结果是D:\项目目录
sys.path.append(o_path) #将该目录添加到该文件夹下,把当前目录当成根目录使用
from download import html_downloader #然后可以跟根目录下的文件一样使用这样的方式引用import download.html_downloader as downloader #不知道是为什么?没弄明白
这样的方式是目前唯一发现的可行的方案。也许有更好的方式,希望大神们在下面指教。
另外 使用 from .. import download.html_downloader的方式也会报错:E0402:Attempted relative import beyond top-level package,平常理解的..和.在python里都是不一样的。引包方式还是Java比较强大和人性化,不过毕竟python是解释型语言,需要更多的说明而不是写更多的代码。
最近在写一些东西用来方便自己,需要用到爬虫。也许你也用的到,也许也会碰到中文乱码问题。网络上的html大多使用utf-8编码,但是国内也有一些使用ISO-8859-1,gb2312,gbk等,遇到这种编码使用bytes(str, encoding=“gbk”) 由于GB18030>GBK>GB2312,转化GBK编码的页面使用gb18030比较可靠一些,在转str(btyes, encoding="utf-8),麻烦而且效果不好,只有小部分页面能够转化成功。
A没有使用转码的效果,B使用bytes和str转码后的效果,C是我这次使用的方法:
上代码: