Mysql性能优化的五个维度
一、 数据库连接配置优化
1、服务端需要做的就是尽可能地多接受客户端的连接,或许你遇到过error 1040: Too many connections的错误?就是服务端的连接数不够。
2、客户端能做的就是尽量减少和服务端建立连接的次数,已经建立的连接能凑合用就凑合用,不要每次执行个SQL语句都创建个新连接,服务端和客户端的资源都吃不消。
1、服务器最大连接数优化配置
服务端需要做的就是尽可能地多接受客户端的连接,或许你遇到过error 1040: Too many connections的错误?就是服务端的连接数不够。
客户端能做的就是尽量减少和服务端建立连接的次数,已经建立的连接能凑合用就凑合用,不要每次执行个SQL语句都创建个新连接,服务端和客户端的资源都吃不消。
解决的方案就是使用连接池来复用连接。
可以从两个方面解决连接数不够的问题:
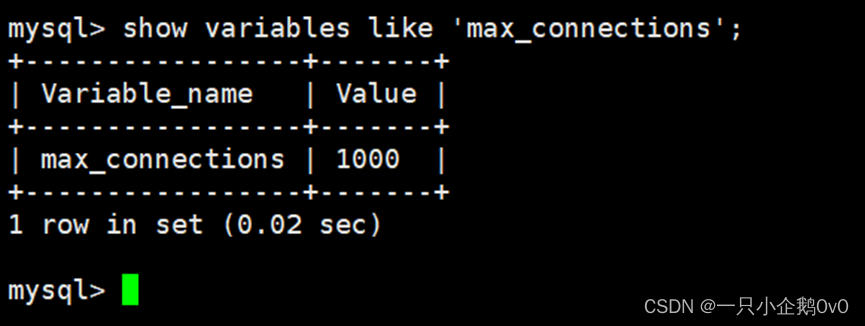
(1)、方法一:增加可用连接数,修改环境变量max_connections,默认情况下服务端的最大连接数为151个
mysql> show variables like ‘max_connections’;
±----------------±------+
| Variable_name | Value |
±----------------±------+
| max_connections | 151 |
±----------------±------+
1 row in set (0.01 sec)
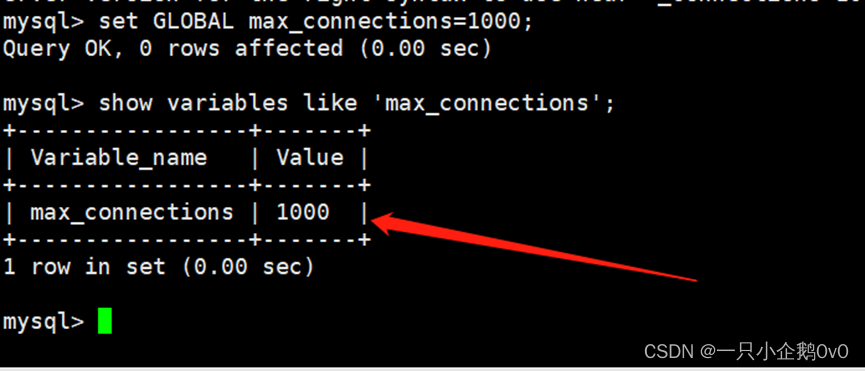
set GLOBAL max_connections=1000; #修改最大连接数为1000
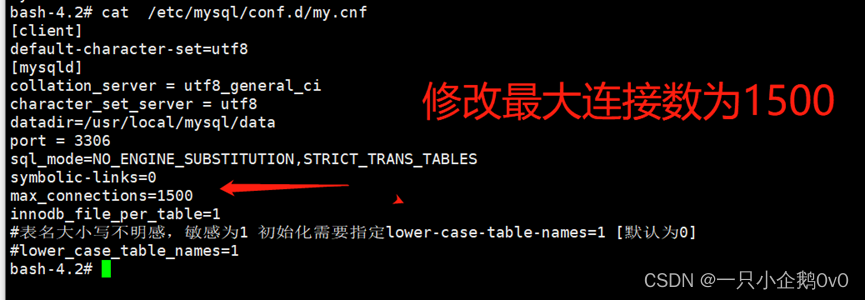
(2)、方法二
/etc/my.cnf #数据库配置文件添加配置
max_connections=1500 #修改最大连接数为1500
修改后重启数据库即可

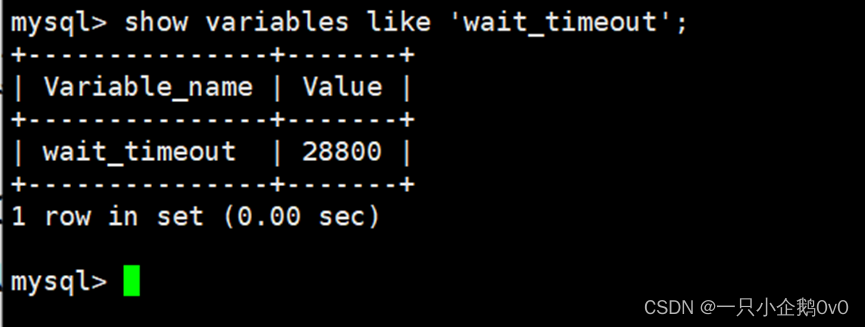
2、释放不活动的连接
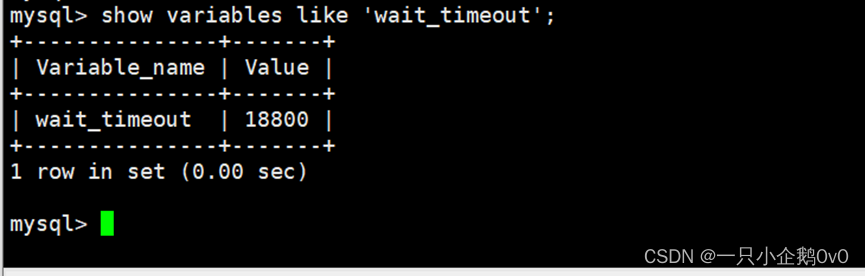
及时释放不活动的连接,系统默认的客户端超时时间是28800秒(8小时),我们可以把这个值调小一点
mysql> show variables like ‘wait_timeout’;
±--------------±------+
| Variable_name | Value |
±--------------±------+
| wait_timeout | 28800 |
±--------------±------+
1 row in set (0.01 sec)
修改配置文件
/etc/my.cnf
interactive_timeout=18800
wait_timeout=18800
重启数据库
二、 架构优化
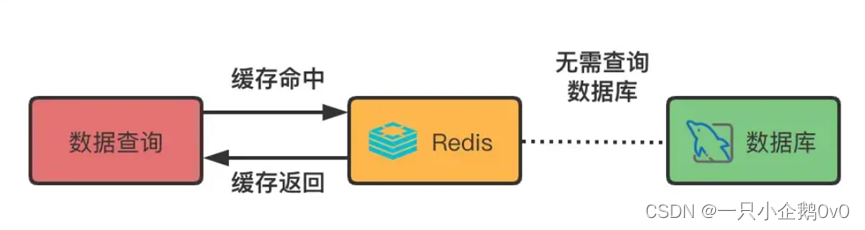
1、 使用缓存
(1)、如果数据的实效性不是特别强(不是每时每刻都会变化,例如每日报表),我们可以把此类数据放入缓存系统中,在数据的缓存有效期内,直接从缓存系统中获取数据,这样就可以减轻数据库的压力并提升查询效率。
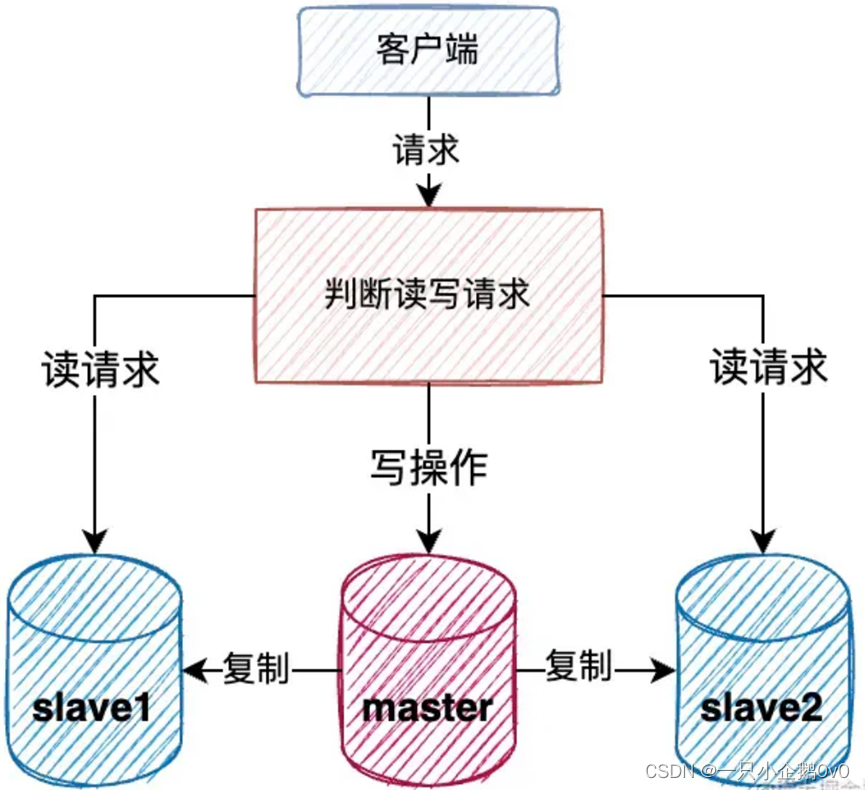
2、 读写分离
(1)、可以同时使用多台数据库服务器,将其中一台设置为为小组长,称之为master节点,其余节点作为组员,叫做slave。用户写数据只往master节点写,而读的请求分摊到各个slave节点上。这个方案叫做读写分离。
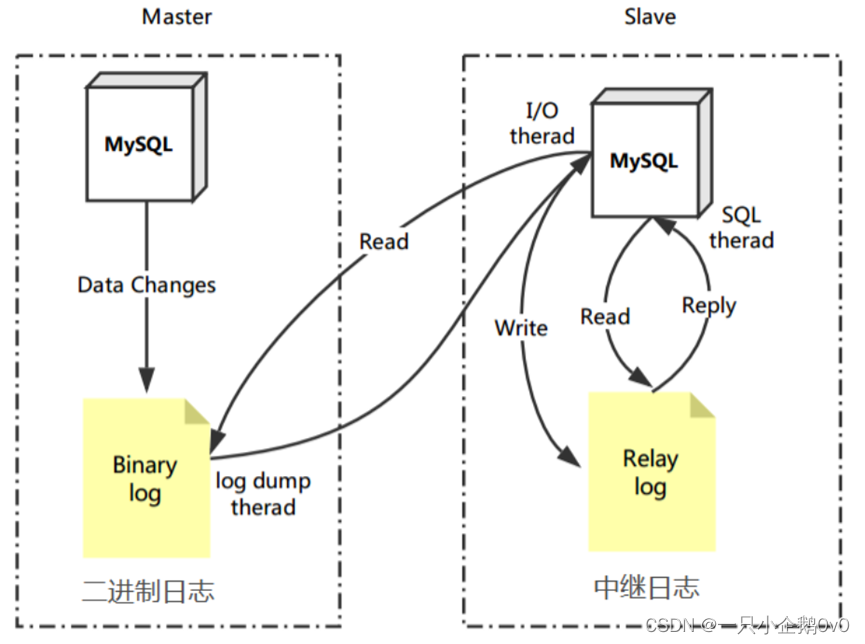
(2)、使用集群必然面临一个问题,主从复制来保持多个节点之间数据的一致性。
binlog是实现MySQL主从复制功能的核心组件。
①、slave端的IO线程发送请求给master端的binlog (二进制日志)线程
②、master端binlog dump线程获取二进制日志信息(文件名和位置信息)发送给slave端的IO线程
③、salve端IO线程获取到的内容依次写到slave端relay log(中继日志)里,并把master端的bin-log文件名和位置记录到http://master.info里
④、salve端的SQL线程,检测到relay log中内容更新,就会解析relay log里更新的内容,并执行这些操作,从而达到和master数据一致
3、 分库分表
分库分表总结:总结:水平分,主要是为了解决存储的瓶颈;垂直分,主要是为了减轻并发压力。
(1)、垂直分库
分库分表中的节点的含义比较宽泛,要是把数据库作为节点,那就是分库;如果把单张表作为节点,那就是分表。
分库分表分成垂直分库、垂直分表、水平分库和水平分表。
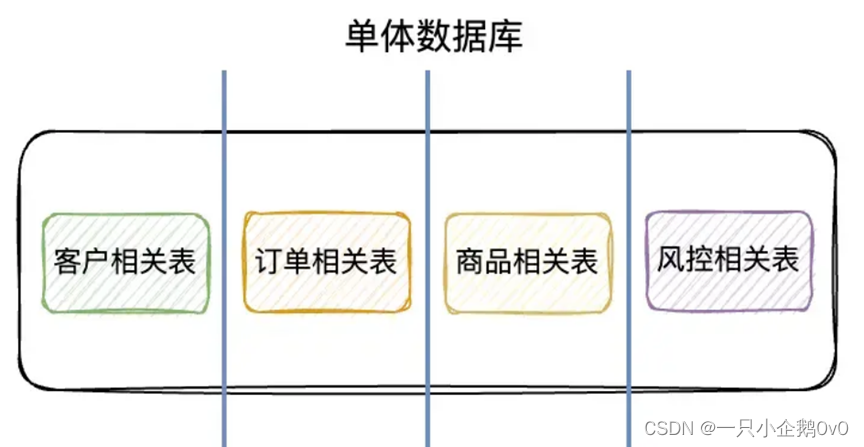
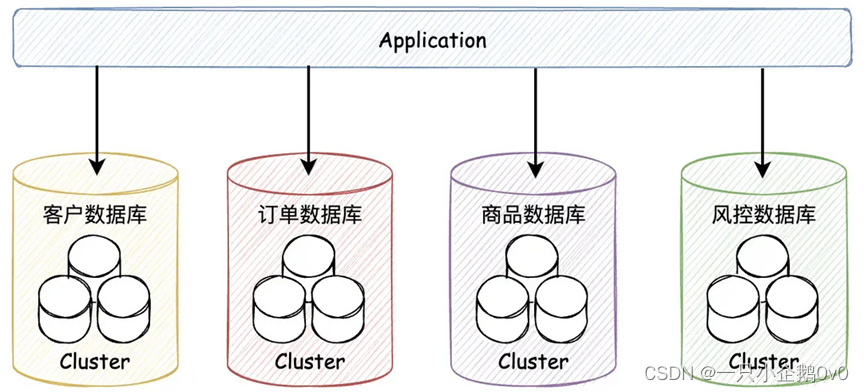
在单体数据库的基础上垂直切几刀,按照业务逻辑拆分成不同的数据库,这就是垂直分库
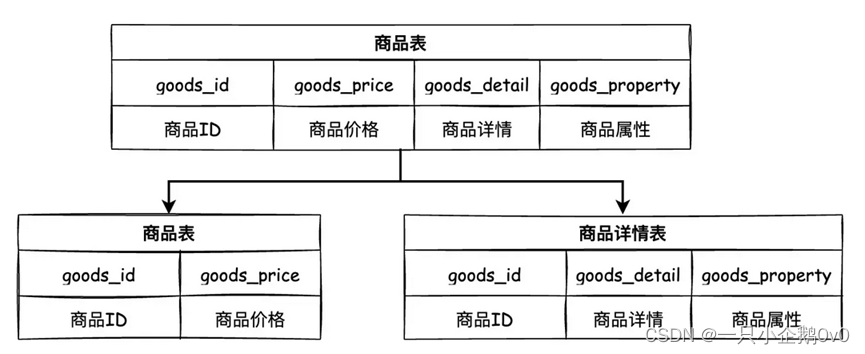
(2)、垂直分表
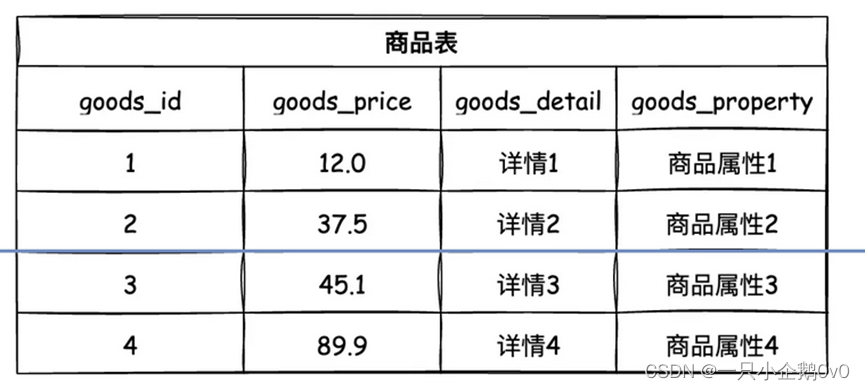
垂直分表就是在单表的基础上垂直切一刀(或几刀),将一个表的多个字短拆成若干个小表,这种操作需要根据具体业务来进行判断,通常会把经常使用的字段(热字段)分成一个表,不经常使用或者不立即使用的字段(冷字段)分成一个表,提升查询速度。
(3)、水平分表
把单张表的数据按照一定的规则(行话叫分片规则)保存到多个数据表上,横着给数据表来一刀(或几刀),就是水平分表

(4)、水平分库
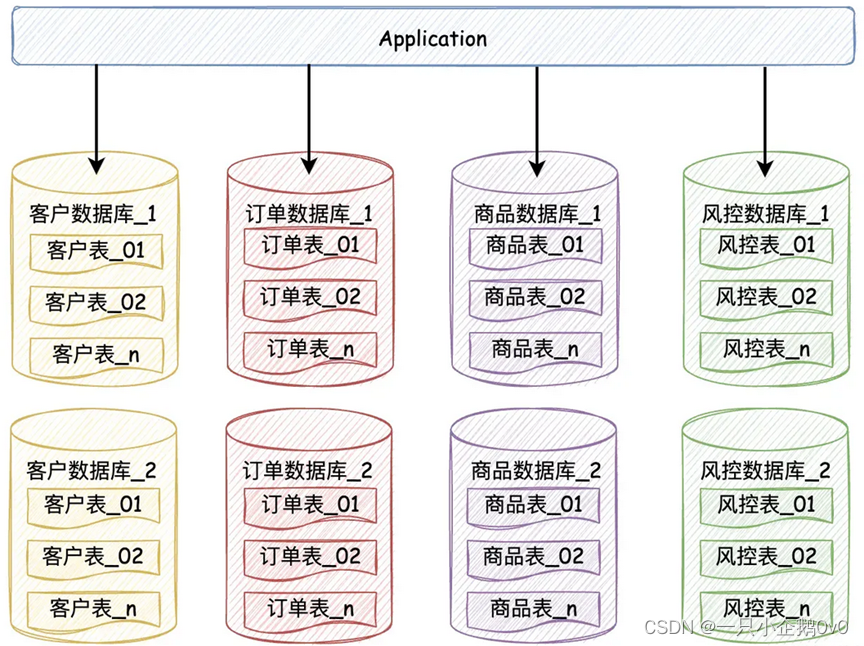
水平分库就是对单个数据库水平切一刀,往往伴随着水平分表。
4、 消息队列
通常情况下,用户的请求会直接访问数据库,如果同一时刻在线用户数量非常庞大,极有可能压垮数据库(参考明星出轨或公布恋情时微博的状态)。
这种情况下可以通过使用消息队列降低数据库的压力,不管同时有多少个用户请求,先存入消息队列,然后系统有条不紊地从消息队列中消费请求。

三、 SQL分析与优化
1、慢查询
慢查询就是执行地很慢的查询,只有知道MySQL中有哪些慢查询我们才能针对性地进行优化。
因为开启慢查询日志是有性能代价的,因此MySQL默认是关闭慢查询日志功能,使用以下命令查看当前慢查询状态。
show variables like ‘slow_query%’;
mysql> show variables like ‘slow_query%’;
±--------------------±-------------------------------------+
| Variable_name | Value |
±--------------------±-------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/9e74f9251f6c-slow.log |
±--------------------±-------------------------------------+
2 rows in set (0.00 sec)
slow_query_log表示当前慢查询日志是否开启,slow_query_log_file表示慢查询日志的保存位置。
除了上面两个变量,我们还需要确定“慢”的指标是什么,即执行超过多长时间才算是慢查询,默认是10S,如果改成0的话就是记录所有的SQL
show variables like ‘%long_query%’;
mysql> show variables like ‘%long_query%’;
±----------------±----------+
| Variable_name | Value |
±----------------±----------+
| long_query_time | 10.000000 |
±----------------±----------+
1 row in set (0.00 sec)
2、打开慢查询日志
(1)、方法一:修改配置文件my.cnf
此种修改方式系统重启后依然有效
#是否开启慢查询日志
slow_query_log=ON
long_query_time=2
slow_query_log_file=/var/lib/mysql/slow.log
(2)、方法二:动态修改参数(重启后失效)
mysql> set @@global.slow_query_log=1;
Query OK, 0 rows affected (0.06 sec)
mysql> set @@global.long_query_time=2;
Query OK, 0 rows affected (0.00 sec)
3、慢查询日志分析
MySQL不仅为我们保存了慢日志文件,还为我们提供了慢日志查询的工具mysqldumpslow,为了演示这个工具,我们先构造一条慢查询:
mysql> SELECT sleep(5);
查看慢查询日志记录数:
SHOW GLOBAL STATUS LIKE ‘%Slow_queries%’;
然后我们查询用时最多的1条慢查询:
mysqldumpslow -s t -t 1 -g ‘select’ /var/lib/mysql/9e74f9251f6c-slow.log
Reading mysql slow query log from /var/lib/mysql/9e74f9251f6c-slow.log
Count: 1 Time=10.00s (10s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@localhost
SELECT sleep(N)
其中
Count:表示这个SQL执行的次数
Time:表示执行的时间,括号中的是累积时间
Locks:表示锁定的时间,括号中的是累积时间
Rows:表示返回的记录数,括号中的是累积数
cat /var/lib/mysql/data/slow.log
SHOW profiles 查看 SQL 的耗时
查询SQL 整个生命周期的耗时
通过 Query_ID 可以得到具体 SQL 从连接——服务——引擎——存储四层结构完整生命周期的耗时
SHOW profile CPU, BLOCK IO FOR QUERY 4;
可用参数 type:
ALL # 显示所有的开销信息
BLOCK IO # 显示块IO相关开销
CONTEXT SWITCHES # 上下文切换相关开销
CPU # 显示CPU相关开销信息
IPC # 显示发送和接收相关开销信息
MEMORY # 显示内存相关开销信息
PAGE FAULTS # 显示页面错误相关开销信息
SOURCE # 显示和 Source_function,Source_file,Source_line 相关的开销信息
SWAPS # 显示交换次数相关开销的信息
4、查看运行中的线程
我们可以运行show full processlist查看MySQL中运行的所有线程,查看其状态和运行时间,找到运行时间长的现场,直接kill。
其中
Id:线程的唯一标志,可以使用Id杀死指定线程
User:启动这个线程的用户,普通账户只能查看自己的线程
Host:哪个ip和端口发起的连接
db:线程操作的数据库
Command:线程的命令
Time:操作持续时间,单位秒
State:线程的状态
Info:SQL语句的前100个字符
5、查看服务器运行状态
直接使用show status指令得到300多条记录,会让我们看得眼花缭乱,因此我们希望能够「按需查看」一部分状态信息。这个时候,我们可以在show status语句后加上对应的like子句。例如,我们想要查看当前MySQL启动后的运行时间,我们可以执行如下语句:
使用SHOW STATUS命令来可以查看服务器的状态信息。
具体命令如下:加global代表的是全局变量。
1)查看select语句的执行数:
show [global] status like ‘com_select’;
2)查看insert语句的执行数:
show [global] status like ‘com_insert’;
3)查看update语句的执行数:
show [global] status like ‘com_update’;
4)查看delete语句的执行数:
show [global] status like ‘com_delete’;
5)查看试图连接到MySQL(不管是否连接成功)的连接数:
show status like ‘connections’;
6)查看线程缓存内的线程的数量:
show status like ‘threads_cached’;
7)查看当前打开的连接的数量:
show status like ‘threads_connected’;
8)查看创建用来处理连接的线程数:
show status like ‘threads_created’;
9)查看激活的(非睡眠状态)线程数:
show status like ‘threads_running’;
10)查看立即获得的表的锁的次数:
show status like ‘table_locks_immediate’;
11)查看不能立即获得的表的锁的次数。如果该值较高,并且有性能问题,你应首先优化查询,然后拆分表或使用复制:
show status like ‘table_locks_waited’;
12)查看创建时间超过slow_launch_time秒的线程数:
show status like ‘slow_launch_threads’;
13)查看查询时间超过long_query_time秒的查询的个数:
show status like ‘slow_queries’;
14)查看MySQL本次启动后的运行时间(单位:秒):
show status like ‘uptime’;
15) 查看查上一个查询的开销
show status like ‘last_query_cost’
16)查看查询缓存信息
show status like ‘qcache%’;
6、查看存储引擎运行状态
(1)、SHOW ENGINE用来展示存储引擎的当前运行信息,包括事务持有的表锁、行锁信息;事务的锁等待情况;线程信号量等待;文件IO请求;Buffer pool统计信息等等数据。
(2)、查询InnoDB版本
show variables like ‘innodb_version’\G;
或select * from information_schema.plugins;
mysql> show variables like ‘innodb_version’\G;
*************************** 1. row ***************************
Variable_name: innodb_version
Value: 5.7.31-34
1 row in set (0.01 sec)
查询InnoDB状态
从以下查询看出,是最近47s计算的每秒平均数,即:每次查询时,参数动态变化。
mysql> show engine
innodb status\G;
** 1. row ***************
Type: InnoDB
Name:
Status:
===============
2022-06-27 09:33:40 0x
7fa1c8a5f700 INNODB
MONITOR OUTPUT
===============
Per second averages
calculated from the last
47 seconds
BACKGROUND THREAD
(后台线程)
srv_master_thread loops
: 13285067 srv_active, 0
srv_shutdown, 1060666
6 srv_idle
srv_master_thread log
flush and writes: 238917
33
#####以上查询所示,srv
master_thread loops是
Master Thread的循环次
数,每次循环时会选择一
种状态(active、
shutdown、idle)执行,
其中active数量增加与数
据变化有关,与查询无关
,
#####可以通过srv
active和srv_idle的差异可
以看出,通过对比active
和idle的值,来获得系统
整体负载情况,如果
active的值越大,证明服
务越繁忙。
#####srv_master_
thread log是Master
Thread对重做日志(redo
log)写入磁盘的次数
SEMAPHORES (信号量
)
OS WAIT ARRAY INFO:
reservation count 57836
764 #####OS的等待阵
列信息:预计计数(
InnoDB分配槽的额度)
OS WAIT ARRAY INFO:
signal count 269276481
#####OS的等待阵
列信息:信号计数(线程
通过阵列得到信号频率)
RW-shared spins 0,
rounds 171890114, OS
waits 34656067 ###
##RW的共享锁的计数,
轮询次数,等待时间
RW-excl spins 0, rounds
1245774156, OS waits
18379769 #####
RW的排他锁的计数,轮
询次数,等待时间
RW-sx spins 80621,
rounds 1707842, OS
waits 34552 #
####RW的sx(意向排他
锁)的计数,轮询次数,
等待时间
Spin rounds per wait: 17
1890114.00 RW-shared,
1245774156.00 RW-
excl, 21.18 RW-sx ##
###每个spin rounds per
wait显示的是:每个操作
系统等待mutex的
spinlock round
… … …
上面这条语句可以展示innodb存储引擎的当前运行的各种信息,据此找到MySQL当前的问题,大家只要知道MySQL提供了这样一个监控工具就行了,等到需要的时候再详细查询
- BACKGROUND THREAD(后台线程)
- SEMAPHORES(信号量)
- LATEST DETECTED DEADLOCK(检测到的死锁)
- TRANSACTIONS(事务)
- FILE I/O(文件IO)
- INSERT BUFFER AND ADAPTIVE HASH INDEX(插入缓冲和自适应哈希索引)
- LOG(日志)
- BUFFER POOL AND MEMORY(缓冲池与内存)
- ROW OPERATIONS(行操作)
7、EXPLAN执行计划
通过慢查询日志我们可以知道哪些SQL语句执行慢了,可是为什么慢?慢在哪里呢?
MySQL提供了一个执行计划的查询命令EXPLAIN,通过此命令我们可以查看SQL执行的计划
EXPLAIN在MySQL5.6.3之后也可以针对UPDATE、DELETE和INSERT语句进行分析,但是通常情况下我们还是用在SELECT查询上。
SQL优化指的是SQL本身语法没有问题,但是有实现相同目的的更好的写法。比如:
使用小表驱动大表;用join改写子查询;or改成union
连接查询中,尽量减少驱动表的扇出(记录数),访问被驱动表的成本要尽量低,尽量在被驱动表的连接列上建立索引,降低访问成本;被驱动表的连接列最好是该表的主键或者是唯一二级索引列,这样被驱动表的成本会降到更低
大偏移量的limit,先过滤再排序
针对最后一条举个简单的例子,下面两条语句能实现同样的目的,但是第二条的执行效率比第一条执行效率要高得多(存储引擎使用的是InnoDB),大家感受一下:
– 1. 大偏移量的查询
mysql> SELECT * FROM user_innodb LIMIT 9000000,10;
Empty set (8.18 sec)
– 2.先过滤ID(因为ID使用的是索引),再limit
mysql> SELECT * FROM user_innodb WHERE id > 9000000 LIMIT 10;
Empty set (0.02 sec)
索引优化
为慢查询创建适当的索引是个非常常见并且非常有效的方法,但是索引是否会被高效使用是另一话题
四、 存储引擎与表结构优化
1、选择存储引擎
一般情况下,我们会选择MySQL默认的存储引擎存储引擎InnoDB,但是当对数据库性能要求精益求精的时候,存储引擎的选择也成为一个关键的影响因素。
查询操作、插入操作多的业务表,推荐使用MyISAM;
临时表使用Memory;
并发数量大、更新多的业务选择使用InnoDB;
不知道选啥直接默认。
2、优化字段
字段优化的最终原则是:使用可以正确存储数据的最小的数据类型
整数类型:不同的存储类型的最大存储范围不同,占用的存储的空间自然也不同
字符类型:如果不确定字段的长度,肯定是要选择varchar,但是varchar需要额外的空间来记录该字段目前占用的长度;因此如果字段的长度是固定的,尽量选用char,这会给你节约不少的内存空间。
非空:非空字段尽量设置成NOT NULL,并提供默认值,或者使用特殊值代替NULL
不要用外键、触发器和视图功能
图片、音频、视频存储:不要直接存储大文件,而是要存储大文件的访问地址
大字段拆分和数据冗余
五、 业务优化
1、业务方面的优化已经不算是MySQL调优的手段了,但是业务的优化却能非常有效地减轻数据库访问压力,这方面一个典型例子就是淘宝
1、以往都是双11当晚开始买买买的模式,最近几年双11的预售战线越拉越长,提前半个多月就开始了,而且各种定金红包模式丛出不穷,这种方式叫做预售分流。这样做可以分流客户的服务请求,不必等到双十一的凌晨一股脑地集体下单;
2、双十一的时候支付宝极力推荐使用花呗支付,而不是银行卡支付,虽然一部分考量是提高软件粘性,但是另一方面,使用余额宝实际使用的阿里内部服务器,访问速度快,而使用银行卡,需要调用银行接口,相比之下操作要慢了许多。
