文章目录
监控对于企业和运维工作的重要性
监控?
监控,就是对服务器的行为状态进行观察、记录的一套动作。
告警?
告警,是对监控到的行为数据进行分析,一旦监控数据出现异常或是,出现预期之外的服务器动作,告警机制则会通过某种方式将该信息传达至运维或是服务器管理人员。
监控和告警的关系
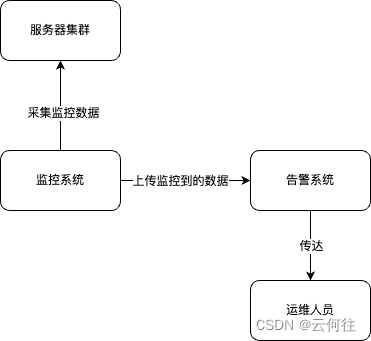
数据采集
监控所需要的数据需要通过数据采集得来,而数据采集会为监控提供抓手、分析用户行为和制定安全策略等能力。
Prometheus介绍
Prometheus相对于老牌监控的优势和不足
优势
- 监控数据的精细程度:1~4秒
- 使用监控脚本部署集群的速度快
- 插件丰富功能多样,包括exporter、pushgateway等
- 本身基于数学模型,有大量的实用模型,可以实现很多复杂功能的监控业务逻辑
- 图形展示优美,可视化出众
不足
- 如果集群数量太大,那么单点的监控有性能瓶颈 目前尚不支持集群 只能
workaround - 对磁盘资源也是耗费的较大,这个具体要看 监控的集群量 和 监控项的多少 和保存时间的长短
理想的监控系统的实现
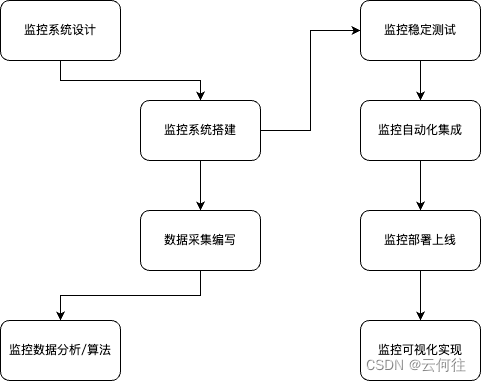
监控系统设计(架构师)
整体的系统设计是形成系统尤为重要的事,设计的不好,整个监控系统就不会实现其该有的功能。
设计部分包括如下的内容:
• 评估系统的业务流程 业务种类 架构体系
各个企业的产品不同,业务方向不同,程序代码不同,系统架构更不同
对于各个地方的细节 都需要有一定程度的认知 才可以开起设计的源头
• 分类出所需的监控项种类
一般可分为 : 业务级别监控 、 系统级别监控 、网络监控 、程序代码监控、日志监控 、用户行为分析监控、其他种类监控
监控种类划分
• 业务监控
可以包含用户访问QPS,DAU日活,访问状态(http code), 业务接入(登陆,注册,聊天,上传,留言,短信,搜索),产品转化率,充值额度,用户投诉等等这些很宏观的概
念(上层)
• 系统监控
主要是跟操作系统相关的,基本监控项 CPU/ 内存 / 硬盘 / IO / TCP链接 / 流量 等等(Nagios - plugins, prometheus)
• 网络监控
(IDC)对网络状态的监控(交换机,路由器,防火墙,VPN) 互联网公司必不可少 但是很多时候又被忽略。例如:内网之间(物理内网,逻辑内网 可用区 创建虚拟机 内网IP 外网 丢包率、延迟等等
• 日志监控
监控中的重头戏(Splunk,ELK),往往单独设计和搭建,全部种类的日志都有需要采集 (syslog, soft, 网络设备,用户行为)
• 程序监控
一般需要和开发人员配合,程序中嵌入各种接又 直接获取数据 或者特质的日志格式
监控系统的搭建
包括一下步骤:
- 单点服务端的搭建(Prometheus)
- 单点客户端部署
- 单点客户端服务器的测试
- 采集程序单点部署
- 采集程序集群部署
- 监控端HA/cloud
- 监控端数据可视化,grafana
- 报警系统测试,paperduty
- 报警规则测试
- 监控+报警联合测试
- 正式上线监控
数据采集的编写
实用脚本编写数据采集工具
shell、python、PHP、go语言等
数据采集的方式
- 一次性采集的模式
稳定性较好 不容易出现各种错误 和性能瓶颈,且开发逻辑简单、实
现快速;对于有些采集项目实现起来不够智能、也不够到位、例如:日志的实时采集
(使用一次性采集 日志文件 200/5xx diff grep 也可以实现 但是很low 不够准确 不够直观) - 后台式采集: 采集程序以守护进程运行在Linux后台,持续不断的采集数据pormetheus exporter 例如,python/go开发的daemon程序 后台持续不断的采集
优点: 后台采集程序,数据准确性高,采集密度精细,管理方便
缺点:后台采集程序 如果开发过程不够仔细 可能会出现各种 内存泄漏 僵尸进程 性能瓶颈的问题, 且开发周期较长 - 桥接式采集: 本身以后台进程运行 但是采集不能独立 依然跟服务器关联 以桥接方式收集采集数据
例如:NRPE for nagios
监控数据分析和算法
需要一个非常专业的数据计算团队才可以给出一个最合理的算法协助我们的报警规则。
业务级别监控的算法,运维自身无法做到十分专业。因为本身跟操作系统无关,是跟数据算法相关。
举个例子:如果我想通过Prometheus实现对用户访问QPS的 精确监控,那么对于 监控图形 曲线 QPS上涨 QPS下跌,QPS凸起,QPS和历史数据的比较方法 等等这些 都属于业务级别的监控阈值类型,需要有专业的数据分析人员的协助 才可以算出优良的算法。
稳定性测试
不管是一次性采集,还是后台采集,只要是在Linux上运行的东西 都会多多少少对系统产生一定的影响。
而稳定性测试,就是通过一段时间的单点部署来观察对线上有没有任何影响。
监控自动化
监控客户端的批量部署,监控服务端的HA再安装,监控项目的修改,监控项目的监控集群变化种种,这些地方都需要大量的人工自动化的引进,会很大程度上缩短我们对监控系统的维护成本。
这里给出几个实例:
Puppet(配置文件部署)
Jenkins(CI 持续集成部署)
CMDB(运维自动化的最高资源管理平台和理念 )等
利用好如上这几个聚的例子,就可以实现对监控自动化的掌控
图形化展示
采集的数据和准备好的监控算法,最终需要一个好的图形展示才能发挥最好的作用