Redis,作为一款开源的、内存中的数据结构存储系统,以其出色的性能和丰富的数据结构在业界赢得了广泛的认可。然而,当我们面临大量数据和高并发请求时,单个 Redis 实例可能无法满足我们的需求。这时,我们就需要使用到 Redis 的集群模式。通过集群模式,我们可以提高数据的可用性和可靠性,提高系统的性能和扩展性。在接下来的文章中,我将详细介绍 Redis 集群的基本概念,以及 Redis 集群的工作原理,故障转移和扩容等操作。
文章目录
1、Redis集群模式介绍
1.1、Redis集群模式概述
Redis 集群模式是 Redis 提供的分布式解决方案,哨兵解决了高可用的问题,而集群就是终极方案,一举解决高可用和分布式问题。在集群模式下,数据会被分散在多个 Redis 节点上,每个节点负责存储整个数据库的一部分,这种方式称为数据分片。
Redis 集群没有使用一致性哈希,而是引入了哈希槽的概念。Redis 集群有 16384个 哈希槽,当需要在 Redis 集群中放置一个键值对时,Redis 首先会对键进行 CRC16计 算,然后对 16384 取余数,得到的结果就是这个键应该被放置的哈希槽的编号。
每个 Redis 节点负责一部分哈希槽,例如在一个有3个节点的 Redis 集群中,可能节点 A 负责 0-5500 号哈希槽,节点 B 负责 5501-11000 号哈希槽,节点 C 负责 11001-16383 号哈希槽。
这样,当一个键需要被访问(读取、写入)时,Redis 集群会根据键名计算出哈希槽号,然后找到负责这个哈希槽的节点。
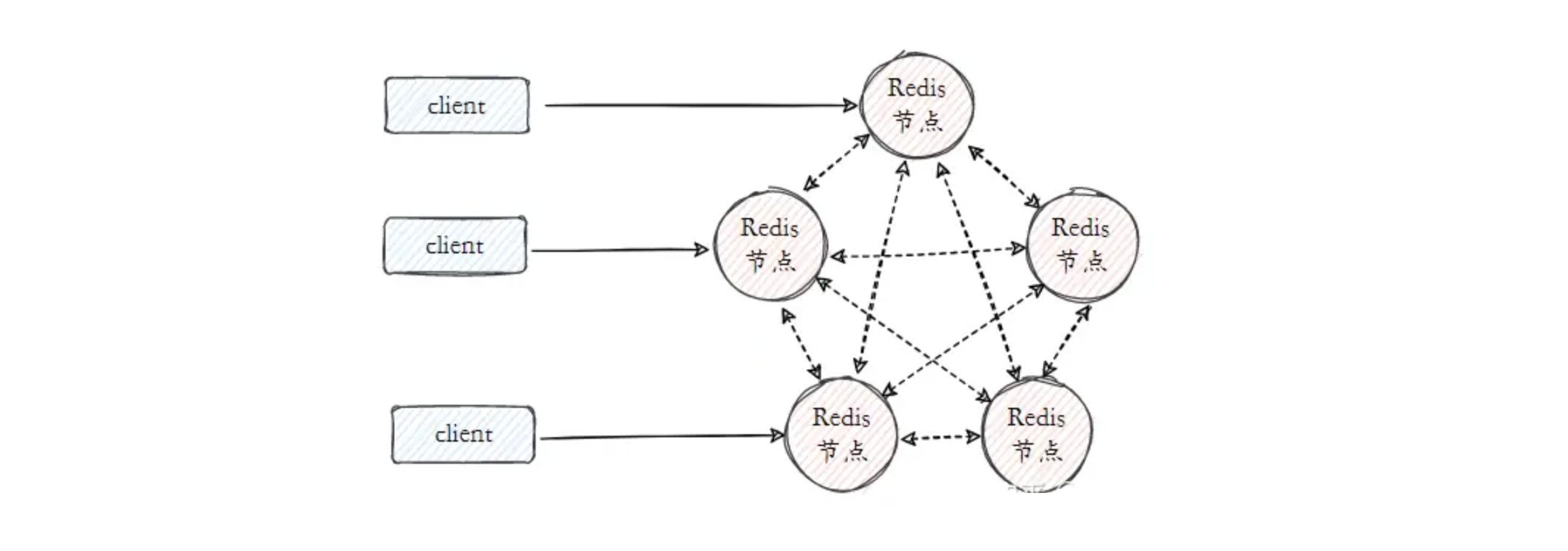
Redis 集群支持主从复制模式,每个节点都会有 0 个或多个从节点,数据会从主节点复制到从节点。当主节点宕机时,从节点可以提升为主节点,继续提供服务。
Redis 集群提供了高可用和分布式能力,但是客户端在使用时需要有一定的复杂性,例如在处理跨节点的事务和 Lua 脚本时,以及在添加、删除节点时重新分配哈希槽等。
1.2、Redis集群的虚拟槽分区
分布式的存储中,要把数据集按照分区规则映射到多个节点,常见的数据分区规则三种:节点取余分区、一致性哈希分区、虚拟槽分区。
节点取余分区(Modulo Partitioning):这种方式是通过取余数的方式将数据映射到不同的节点上。例如,我们可以将用户 ID 对节点数量取余,然后将数据存储在对应的节点上。这种方式的优点是实现简单,数据分布相对均匀。但是,当节点数量变化时,大部分数据都需要重新分配,这会导致大量的数据迁移;
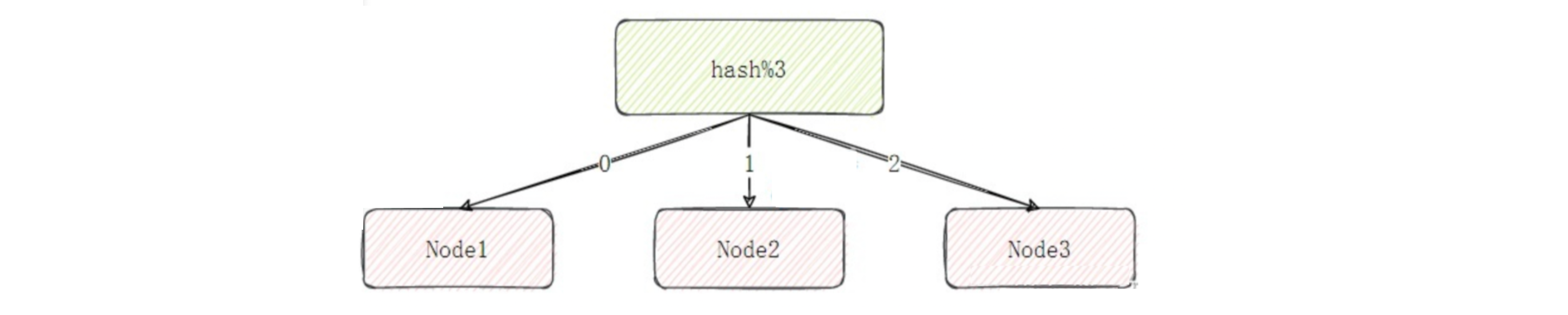 一致性哈希分区(Consistent Hashing Partitioning):这种方式是通过一致性哈希算法将数据映射到不同的节点上。一致性哈希算法的优点是,当节点数量变化时,只需要迁移哈希环上的一小部分数据,大大减少了数据迁移的开销。同时,一致性哈希算法也能保证数据分布的相对均匀。
一致性哈希分区(Consistent Hashing Partitioning):这种方式是通过一致性哈希算法将数据映射到不同的节点上。一致性哈希算法的优点是,当节点数量变化时,只需要迁移哈希环上的一小部分数据,大大减少了数据迁移的开销。同时,一致性哈希算法也能保证数据分布的相对均匀。
比如说下面 这张图里面,Key1 和 Key2 会落入到 Node1 中,Key3、Key4 会落入到 Node2 中,Key5 落入到 Node3 中,Key6 落入到 Node4 中。
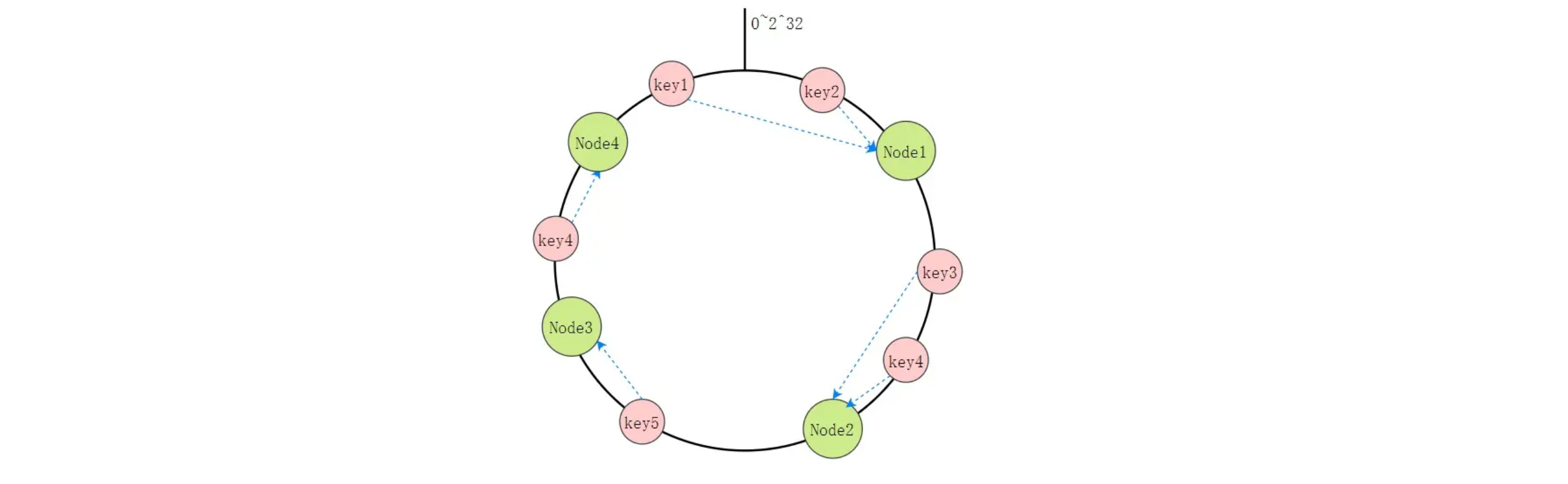
但它还是存在问题:缓存节点在圆环上分布不平均,会造成部分缓存节点的压力较大;当某个节点故障时,这个节点所要承担的所有访问都会被顺移到另一个节点上,会对后面这个节点造成力。
虚拟槽分区(Virtual Slot Partitioning):这种方式是将数据空间分割成多个虚拟槽,然后将这些虚拟槽映射到不同的节点上。Redis Cluster 就是使用的虚拟槽分区方式,它将所有的键空间分割成 16384 个虚拟槽。这种方式的优点是,当节点数量变化时,只需要重新分配虚拟槽而不是数据,减少了数据迁移的开销。同时,虚拟槽分区也能保证数据分布的相对均匀。
1.3、Redis集群常用命令
以下是一些 Redis 集群常用的命令:
CLUSTER ADDSLOTS <slot> [slot ...]:在当前节点上添加一个或多个槽。CLUSTER COUNT-FAILURE-REPORTS <node-id>:返回其他节点对指定节点的故障报告数量。CLUSTER COUNTKEYSINSLOT <slot>:返回指定槽中的键值对数量。CLUSTER DELSLOTS <slot> [slot ...]:在当前节点上删除一个或多个槽。CLUSTER FAILOVER [FORCE|TAKEOVER]:手动触发故障转移,如果指定了FORCE或TAKEOVER,则无需等待其他节点的授权。CLUSTER FLUSHSLOTS:删除当前节点的所有槽信息。CLUSTER FORGET <node-id>:从集群中移除一个节点。CLUSTER GETKEYSINSLOT <slot> <count>:返回指定槽中的一些键。CLUSTER INFO:返回集群的信息。CLUSTER KEYSLOT <key>:返回键应该被放置在哪个槽上。CLUSTER MEET <ip> <port>:向集群中添加一个新节点。CLUSTER NODES:返回集群中所有节点的信息。CLUSTER REPLICATE <node-id>:将当前节点设置为指定节点的从节点。CLUSTER RESET [HARD|SOFT]:重置当前节点。CLUSTER SAVECONFIG:将节点的配置保存到磁盘。CLUSTER SET-CONFIG-EPOCH <epoch>:设置节点的配置纪元。CLUSTER SETSLOT <slot> <subcommand> [node-id]:设置槽的状态。CLUSTER SLAVES <node-id>:返回指定节点的所有从节点。CLUSTER SLOTS:返回集群中所有槽的信息。
2、Redis集群模式原理
2.1、集群创建
Redis 集群创建时会有以下步骤:
- 启动节点:在每个预设的节点上启动 Redis 服务。Redis 集群模式最小节点数量为 3 个,这 3 个都是主节点。这是为了满足 Redis 集群的最小高可用性要求,即在主节点出现故障时,可以通过其他主节点进行故障转移。但是,这种配置下,如果一个主节点出现故障,集群将无法提供服务,因为没有足够的主节点来达成多数派。因此,为了保证高可用性,通常推荐至少 6 个节点,其中 3 个主节点,3 个从节点。
- 创建集群:也称节点握手,是指 Redis 集群中节点间建立联系的过程,通过 Gossip 协议进行通信。当一个新的节点需要加入到集群中时,它会向集群中的任意一个节点发送
CLUSTER MEET命令,包含自己的 IP 地址和端口号。收到命令的节点会更新自己的节点表,并将这个新的节点信息通过 Gossip 协议传播给集群中的其他节点,这样就完成了节点握手,新的节点成功地加入到了集群中;
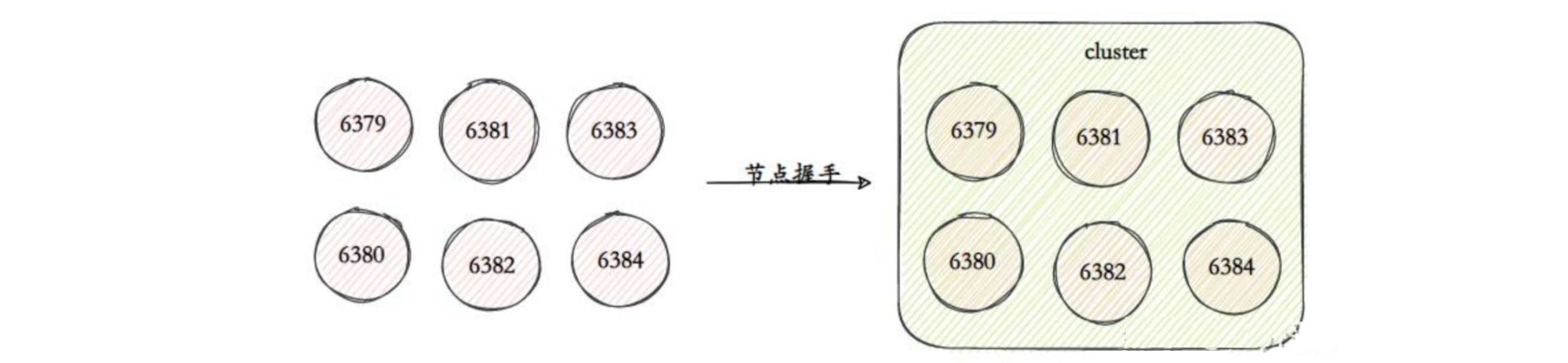
- 分配槽:在 Redis 集群中,所有的数据都会被映射到 16384 个槽中。每个节点负责一部分槽,只有当节点被分配了槽,它才能处理和这些槽关联的键的命令。在创建集群或者调整集群结构时,可以通过
CLUSTER ADDSLOTS命令为节点分配槽; - 设置主从关系:如果集群中有多个节点,需要设置主从关系,以实现数据的备份和高可用
2.2、故障发现
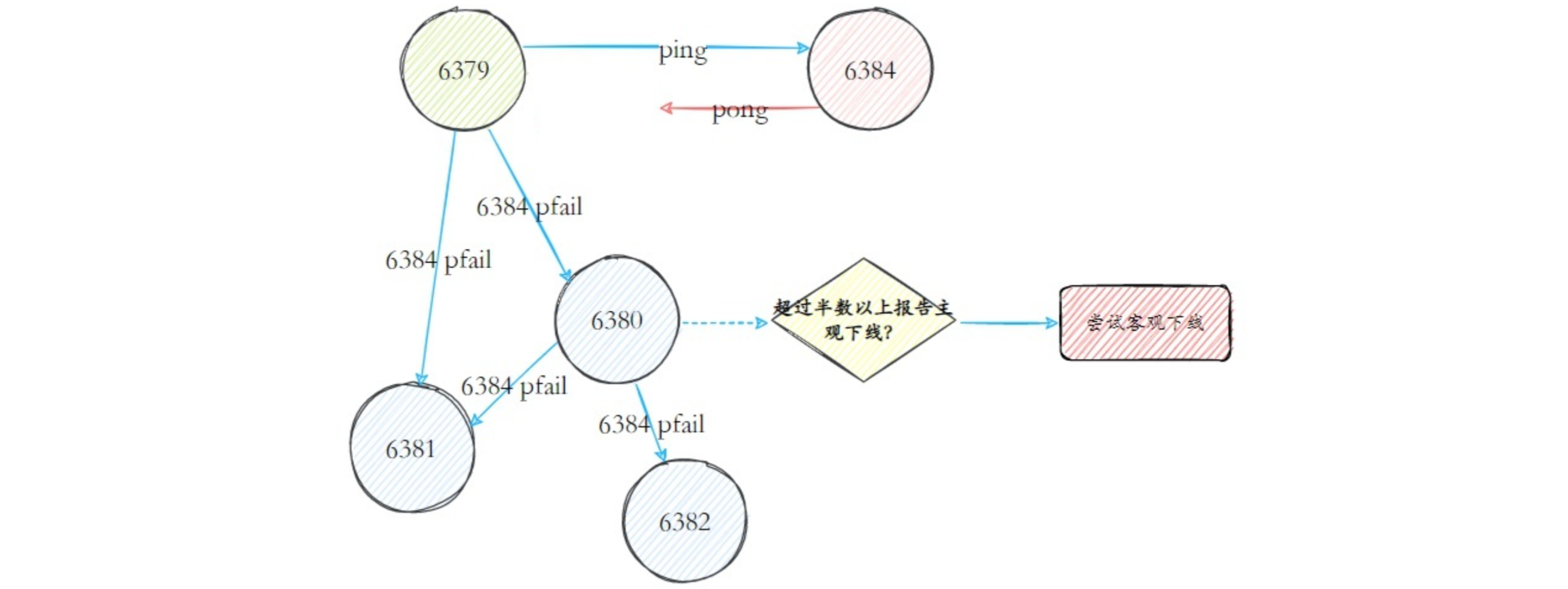
在 Redis 集群中,节点之间通过发送 ping/pong 消息进行通信,这是 Gossip 协议的一部分。每个节点都会定期向其他节点发送 ping 消息,如果在 cluster-node-timeout 时间内没有收到某个节点的 pong 消息,就会认为这个节点出现了故障,将其标记为主观下线(pfail)状态。

当一个节点被标记为主观下线后,这个信息会通过 Gossip 协议在集群中传播。当半数以上的主节点都标记某个节点为主观下线时,这个节点就会被标记为客观下线(fail)状态,触发故障转移流程。
2.3、故障转移
当一个主节点出现故障时,集群中的其他主节点会通过 Gossip 协议感知到这个故障。然后,这些主节点会从故障主节点的从节点中选举出一个来替换故障的主节点,这个过程称为故障转移。
这种方式和 Redis 哨兵模式的故障转移有些类似,但是在哨兵模式中,只有哨兵节点会参与到故障检测和故障转移的过程中来,而在集群模式中,所有的主节点都会参与到这个过程中来。这样可以提高故障转移的效率,减少故障恢复的时间。
具体流程如下:
-
资格检查:故障主节点的所有从节点会检查自己最后一次与主节点通信的时间,判断自己是否有资格替换故障的主节点。
-
准备选举时间:符合故障转移资格的从节点会设置一个故障选举的时间,只有到达这个时间后,才能发起选举流程。
-
发起选举:当从节点定时任务检测到故障选举时间(failover_auth_time)到达后,会发起选举流程。
-
选举投票:持有槽的主节点会处理故障选举的消息,进行投票。每个持有槽的主节点在每个配置纪元内只能投票给一个从节点,这样可以保证只有一个从节点能够获得超过半数的选票。
-
选举新的主节点:获得超过半数选票的从节点会被选为新的主节点。
-
通知集群:新的主节点会向集群中的其他节点发送消息,通知它们自己已经被选为新的主节点。
-
更新槽映射:新的主节点会接管故障主节点的所有槽,集群中的其他节点在接收到新的主节点的消息后,会更新自己的槽映射信息。
-
开始提供服务:新的主节点开始提供服务,处理客户端的请求。这个过程确保了当主节点出现故障时,集群能够快速地进行故障转移,提高集群的可用性。
在 Redis 集群中,故障转移的过程需要半数以上的主节点的投票。如果集群中的主节点数量不足,或者多个主节点部署在同一台机器上导致无法正常工作,那么就无法收集到足够的投票,故障转移的过程就会失败。
因此,为了避免单点故障,我们在部署 Redis 集群时,需要尽量保证所有的主节点都分布在不同的物理机上。这样即使某一台物理机出现故障,也不会影响到半数以上的主节点,保证了集群的高可用性。
2.4、集群扩容
当 Redis 集群的负载过高或者存储空间不足时,可以通过添加新的节点来进行扩容。添加新节点后,需要将一部分槽(slot)迁移到新的节点上,这样新的节点就可以开始提供服务。这个过程可以通过 CLUSTER ADDSLOTS 命令来完成。
在扩容过程中,管理员或者运维人员需要通过 Redis 的命令行工具(redis-cli)或者其他管理工具,向集群发送命令,执行添加新节点、分配槽、迁移槽等操作。
Redis 集群的扩容过程主要包括以下步骤:
- 添加新节点:首先,我们需要在新的服务器上启动一个 Redis 实例,并将其添加到现有的 Redis 集群中。这可以通过
CLUSTER MEET命令来完成。 - 分配槽:然后,我们需要为新的节点分配一部分槽。这可以通过
CLUSTER ADDSLOTS命令来完成。 - 迁移槽:接下来,我们需要将一部分数据从旧的节点迁移到新的节点上。这可以通过
CLUSTER MIGRATESLOT命令来完成。在这个过程中,被迁移的槽会暂时无法提供服务。 - 更新槽映射:最后,我们需要更新集群中所有节点的槽映射信息,让它们知道新的槽分配情况。这可以通过
CLUSTER NODES命令来完成。
以上就是 Redis 集群的扩容过程。需要注意的是,这个过程可能会影响到集群的服务,因为在迁移槽的过程中,被迁移的槽会暂时无法提供服务。因此,我们在进行扩容操作时,需要尽量选择在负载较低的时候进行,以减少对服务的影响。
2.5、集群缩容
当 Redis 集群的负载过低或者有过多的空闲资源时,可以通过移除一些节点来进行缩容。移除节点前,需要先将这个节点上的所有槽迁移到其他节点上,然后再移除这个节点。这个过程可以通过 CLUSTER DELSLOTS 命令来完成。
Redis 集群的缩容过程主要包括以下步骤:
- 数据迁移:首先,我们需要将需要缩容的节点上的所有数据迁移到集群中的其他节点上。这可以通过
CLUSTER MIGRATESLOT命令来完成。在这个过程中,被迁移的槽会暂时无法提供服务。 - 移除槽:然后,我们需要将需要缩容的节点上的所有槽移除。这可以通过
CLUSTER DELSLOTS命令来完成。 - 移除节点:最后,我们需要将需要缩容的节点从集群中移除。这可以通过
CLUSTER FORGET命令来完成。