
根据新华社研究院中国企业发展研究中心发布的《人工智能大模型体验报告2.0》,参测的8款大模型均来自科技巨头或与权威院所合作开发的正规团队。例如,讯飞星火是由享有“AI国家队”声誉的科大讯飞研发的,而智谱AI-ChatGLM则是由清华大学计算机系转化技术成果的公司打造的。在评测结果中,讯飞星火以总分1013分获得第一名,仅与Benchmark(人类)相差一分。这表明讯飞星火在评测中表现出色,取得了显著的成绩。
主要是审核真的快,五分钟、十分钟就可以预约成功讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞讯飞星火认知大模型,是由科大讯飞推出的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务,提供语言理解、知识问答、逻辑推理、数学题解答、代码理解与编写等多种能力。https://xinghuo.xfyun.cn/?ch=bl_Y95KVn
 讯飞星火在多轮对话、逻辑和数学能力上实现了更高水平的升级,不仅在智商方面表现出色,而且在情商方面同样优秀。通过广泛学习人类常识与知识,讯飞星火更好地理解人类语言和行为,展现了严密的思维推理和强大的分析决策能力。此外,讯飞星火在医疗等专业知识领域积累了深厚的经验和知识,这也是与其他大模型相比的优势之一。
讯飞星火在多轮对话、逻辑和数学能力上实现了更高水平的升级,不仅在智商方面表现出色,而且在情商方面同样优秀。通过广泛学习人类常识与知识,讯飞星火更好地理解人类语言和行为,展现了严密的思维推理和强大的分析决策能力。此外,讯飞星火在医疗等专业知识领域积累了深厚的经验和知识,这也是与其他大模型相比的优势之一。
讯飞星火大模型2.0版本
近期讯飞星火认知大模型升级到了2.0版本,最大的升级在于代码能力和多模态能力的大幅提升,就让博主带你体验一下

多模态功能
2.1什么是多模态?
多模态(Multimodal)是指在一个系统或者一个任务中,同时涉及多种不同的感知模态或信息表达方式。常见的感知模态包括视觉(图像、视频)、听觉(音频)、语言(文本)、触觉等。通过多模态技术,可以将不同模态的数据进行融合和交互,从而获得更加全面和丰富的信息。

讯飞星火大模型可以同时处理多种不同的感知模态,例如图像、语音和文本等。这使得它能够全面地理解和分析多种输入数据,从而得到更全面、准确的信息。
操作了两次,感觉相当不错,完全符合预期,没有槽点

2.2助手中心
助手中心可能是一个集成了多种实用工具和功能的平台,旨在帮助用户更好地使用星火大模型。它可以提供扩写助手、文案大师、python编辑器登功能,以支持用户更好地理解和应用模型。同时,助手中心还可能提供用户反馈和建议的渠道,以便改进和优化模型性能。

文案大师实测 :
简直是媒体人的福利,再也不用担心文案问题

通过角色设定,你可以快速定制一个专属的助手。你还可以自主创建数据集,并将其与助手相关联,以便使用该数据集来提出问题。这意味着你可以训练一个完全属于你自己的助手,根据你的背景、业务和需求进行定制。最终,你将拥有一个独一无二的、只属于你个人的助手。
2.3、代码能力
代码生成:星火大模型能够根据给定的要求和条件生成合理的代码片段

import requests
from bs4 import BeautifulSoup
import xlwt
import re
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl) # 获取数据
savepath = "豆瓣电影Top250.xls"
saveData(datalist, savepath) # 保存数据到Excel文件
def getData(baseurl):
datalist = []
for i in range(0, 10): # 遍历每页
url = baseurl + str(i*25)
html = askURL(url) # 发送请求获取网页内容
soup = BeautifulSoup(html, "html.parser") # 使用BeautifulSoup解析网页
items = soup.find_all('div', class_="item") # 找到电影条目的div标签
for item in items:
data = []
item_link = item.find('a')['href'] # 获取电影详情链接
item_img = item.find('img')['src'] # 获取图片链接
item_title = item.find('span', class_="title").get_text() # 获取影片中文名
item_rating = item.find('span', class_="rating_num").get_text() # 获取评分
item_judge = item.find('span', string=re.compile("人评价")).get_text() # 获取评价数
item_inq = item.find('span', class_="inq") # 获取概况
item_bd = item.find('p', class_="") # 获取相关信息
if item_inq:
item_inq = item_inq.get_text().replace("。", "")
else:
item_inq = ""
if item_bd:
item_bd = item_bd.get_text().strip()
else:
item_bd = ""
data.append(item_link)
data.append(item_img)
data.append(item_title)
data.append(item_rating)
data.append(item_judge)
data.append(item_inq)
data.append(item_bd)
datalist.append(data) # 将电影数据添加到列表中
return datalist
def askURL(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
response = requests.get(url, headers=headers) # 发送请求
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.text # 返回网页内容
except requests.RequestException as e:
print(e)
return ""
def saveData(datalist, savepath):
workbook = xlwt.Workbook(encoding="utf-8") # 创建一个新的Excel文件
worksheet = workbook.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) # 添加工作表
col = ('电影详情链接', '图片链接', '影片中文名', '评分', '评价数', '概况', '相关信息') # 列名
for i in range(len(col)):
worksheet.write(0, i, col[i]) # 写入列名
for i in range(len(datalist)):
print("第%d条:" %(i+1))
data = datalist[i]
for j in range(len(data)):
worksheet.write(i+1, j, data[j]) # 写入数据
workbook.save(savepath) # 保存Excel文件
if __name__ == "__main__":
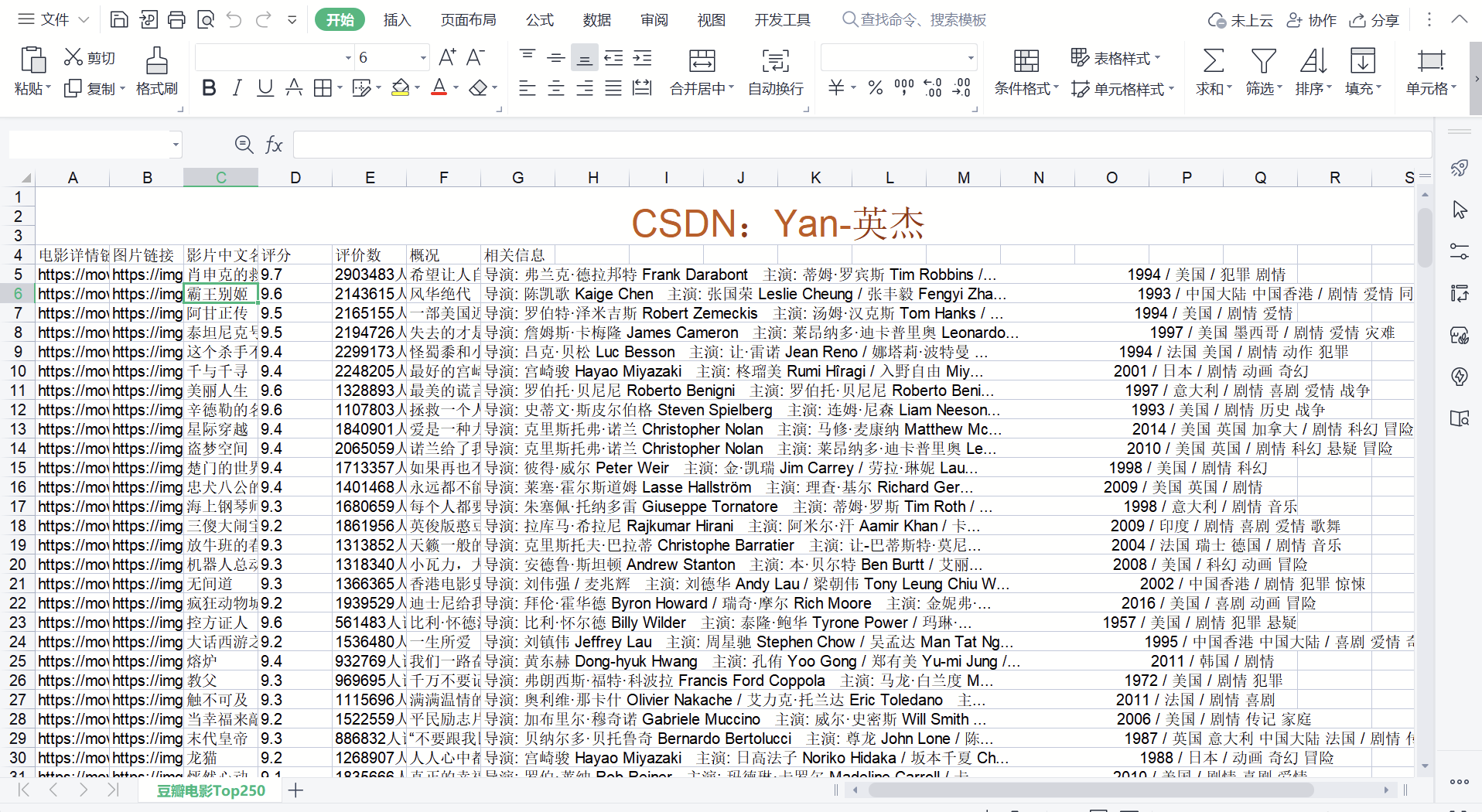
main()我们发现代码确实可用,爬取的内容吻合需求,不难看出其它出色的代码能力
免费体验
星火大模型其强大的代码能力和多模态功能吸引了大量程序员使用,我们如何免费体验
到星火大模型,点击下方链接,讯飞星火认知大模型,进行注册,几分钟内即可注册成功,如果你
是一名开发者,还可以有更高的星火大模型API测试额度,比普通渠道申请多30%,至高可申请
500w Tokens。
