一、引言
关键点:可以使用一个文件来永久保存数据;可以使用异常处理使编写的程序安全可靠且鲁棒性强。
程序中使用的数据都是暂时的,当程序终止时它们就会丢失,除非这些数据被特别地保存起来。为了能够永久地保存程序中创建的数据,需要将它们存储到磁盘或光盘上的文件中。这些文件可以被传送,可以随后被其他程序读取。
二、文本输入和输出
关键点:为了从文件读数据或向文件写数据,需要使用open函数创建一个文件对象并使用这个对象的read和write方法来读写数据。
在文件系统中,每个文件都存放在一个目录下。绝对文件名是由文件名和它的完整路径以及驱动器字母组成。例如: c:\pybook\Scores.txt 是文件Scores.txt在Windows操作系统上的绝对文件名。这里的c:\pybook是指该文件的目录路径。绝对文件名是依赖机器的。
在UNIX平台上,绝对文件名可能会是/home/liang/pybook/Scores.txt,其中/home/liang/pybook是文件Scores.txt的目录路径。相对文件名是相对于文件当前的工作路径而言的。一个相对文件名的完整路径被忽略。例如,Scores.py 是一个相对文件名。如果它当前的工作路径是c:\pybook,那么绝对文件名应该是c:\pybook\Scores.py。
文件可以分为文本文件和二进制文件两类。在Windows系统中能够使用文本编辑器或Notepad处理( 读写和创建)或者在UNIX系统中能够使用vi处理的文件被称为文本文件(text file)。所有其他文件都被称为二进制文件。例如,Python 源程序都被存在文本文件中且可以被文本编辑器处理,但是微软的Word文件是被存储在二进制文件且是用Microsoft Word程序处理的。
尽管在技术上不够严谨正确,但是可以认为一个文本文件是由一系列的字符组成而一个二进制文件是由一系列的比特组成。文本文件中的字符使用像ASCII和Unicode这样的字符编码表来编码。例如:十进制整数199在文本文件中被存为三个字符1、9和9,而同一个整数在二进制文件中就被存为一个字节类型C7,因为十进制199等于十六进制C7( 199=12x 16'+7 )。二进制文件的优势就是它们比文本文件的处理效率更高。
注意:计算机并不会区分二进制文件和文本文件。所有的文件都以二进制格式存储,因此实际上所有的文件都是二进制文件。文本IO(输入和输出)是建立在二进制10的基础上提供一定程度上抽象的字符编码和解码。
2.1、打开一个文件
如何向(从)一个文件写(读)数据?需要创建一个和物理文件相关的文件对象。这被称为打开一个文件。打开一个文件的语法如下。
fileVariable = open(filename, mode) open函数为filename返回一个文件对象。参数mode是一个指定这个文件将被如何使用(只读或只写)的字符串,如下表所示。
例如,下面的语句打开当前目录下一个名为Scores.txt 的文件来进行读操作。
input = open("Scores.txt", "r")2.2、 写入数据
open函数创建了一个文件对象,这是 _io.TextIOWrapper 类的一个实例。这个类包含了读写数据和关闭文件的方法,如下图所示。

当一个文件被打开来进行写数据的操作后,可以使用write方法来将一个字符串写入文件。在下面程序清单中,程序将三个字符串写人文件Presidents.txt。
def main():
outfile = open("Presidents.txt", "w")
# Write data to the file
outfile.write("Bill Clinton\n")
outfile.write("George Bush\n")
outfile.write("Barack Obama")
outfile.c1ose() # Close the output file
main() # Call the main function
这个程序使用w模式打开一个名为Presidents.txt 的文件来写入数据。如果这个文件不存在,那么open函数就会创建一个新文件。如果该文件已经存在,那么这个文件中的内容将会被新的数据覆盖重写。现在,可以向文件中写人数据。
当一个文件被打开来进行写操作或读操作时,一个被称为文件指针的特殊标记将会被放在文件内部。读或写操作在指针位置发生。当一个文件被打开时,文件指针被放在文件的起始位置。当对文件进行读或写操作时,文件指针将会前移。
程序调用文件对象上的write方法写入三个字符串。下图给出每次写操作之后文件指针的位置。

程序最后关闭文件以保证数据被写入文件。当这个程序被执行后,三个姓名被写入文件。可以利用文本编辑器来查看该文件。
注意:当调用print(str)时,函数在显示字符串后将自动插入一个换行字符\n。但是,write函数不会自动插入一个新行字符。你必须显式地给文件写入一个换行字符。
警告:如果打开一个已经存在的文件来进行写操作,那么该文件的原始内容将会被新的文本覆盖或销毁。
2.3、 测试文件的存在性
为了防止已存在文件中的数据被意外消除,应该在打开一个文件进行写操作前检测该文件是否已经存在。os.path 模块中的isfile 函数可以用来判断一个文件是否存在。例如:
import os.path
if os.path.isfile("Presidents.txt") :
print("Presidents.txt exists")在这里,如果文件Presidents.txt文件在当前目录下存在,那么isfile ( "Presidents.txt" )返回True。
2.4、 读数据
当一个文件被打开来进行读操作时,可以使用read方法从该文件中读取特定数目的字符或全部字符并将它们作为字符串返回,readline() 方法读取下一行,而readlines()方法读取所有行并放入一个字符串列表中。
假设Presidents.txt文件包含三行姓名。下面程序清单中的程序从文件读取数据。
def main():
infile = open("Presidents.txt", "r")
print("(1) Using read()): ")
print(infile.read())
infile.close() # Close the input file
# Open file for input
infile = open("Presidents. txt", "r")
print("\n(2) Using read(number): ")
s1 = infile.read(4)
print(s1)
s2 = infile.read(10)
print(repr(s2))
infile.close() # Close the input file
# Open file for input
infile = open("Presidents.txt", "r")
print("\n(3) Using readline(): ")
line1 = infile.readline()
line2 = infile.readline()
line3 = infile.readline()
line4 = infile.readline()
print(repr(line1))
print(repr(line2))
print(repr(line3))
print(repr(line4))
infile.close() # Close the input file
# Open file for input
infile = open("Presidents.txt", "r")
print("\n(4) Using read1 ines(): ")
print(infile.readlines())
infile.close() # Close the input file
main() # Ca11 the main function
输出结果为:
(1) Using read():
Bill Clinton
George Bush
Barack Obama
(2) Using read(number):
Bill
' Clinton\nG'
(3) Using readline():
'Bill Clinton\n'
'George Bush\n'
'Barack Obama'
''
(4) Using readlines():
['Bill Clinton\n', 'George Bush\n', ' Barack Obama ']2.5、 从文件读取所有数据
程序经常需要从一个文件中读取全部数据。这里有两种常用的方法来完成这个任务:
- 1 )使用read()方法来从文件读取所有数据,然后将它作为一个字符串返回。
- 2)使用readlines()方法从文件中读取所有数据,然后将它作为一个字符串列表返回。
这两个方法对于小文件而言是简单且有效的,但是如果文件大到它的内容无法全部存在存储器中时该怎么办?可以编写下面循环每次读取文件的一行,并且持续读取下一行直到文件末端:
line = infile.readline() # Read a line
while line != ''
# Read next line
line = infile.readline() 注意:当程序达到文件的末尾时,readline() 返回 ' '。
Python同样允许你使用for循环来读取文件所有行,如下所示。
for line in infile:
# Process the line here ... 这比使用while循环要简单多了。
下面程序清单编写了一个程序,该程序将一个源文件的数据复制到目标文件,并统计文件的行数和字符数。
import os.path
import sys
def main():
f1 = input("Enter a source file: ").strip()
f2 = input("Enter a target file: ").strip()
# Check if target file exists
if os.path.isfile(f2):
print(f2 + " already exists")
sys.exit()
# Open files for input and output
infile = open(f1, "r")
outfile = open(f2, "w")
# Copy from input file to output file
countLines = countChars = 0
for line in infile:
countLines += 1
countChars += len(line)
outfile.write(line)
print(countLines, "lines and", countChars, "chars copied")
infile.close() # Close the input file
outfile.close() # Close the output file
main() # Call the main function
2.6、 追加数据
可以使用a模式打开一个文件来在一个已经存在的文件末尾添加数据。下面程序清单给出了一个给名为Info.txt的文件追加两行的例子。
def main():
# Open file for appending data
outfile = open("Info.txt", "a")
outfile.write("\nPython is interpreted\n")
outfile.close() # Close the file
main() # Call the main function程序使用a模式打开一个名为Info.txt文件来通过文件对象oufile向文件添加数据。假设已存在的文件中包含有文本数据“Programming is fun”。 下图给出当文件被打开时和每次写人后文件指针的位置。当文件被打开时,文件指针被置于文件末尾。

程序最后关闭文件以确保数据被正确写人文件当中。
三、文件对话框
关键点: tkinter.filedialog 模块中包含有askopenfilename和asksaveasfilename函数来显示文件打开和保存为对话框。
Tkinter提供了带以下两个函数的tkinter.filedialog模块。
# Display a file dialog box for opening an existing file
filename = askopenfilename()
# Display a file dialog box for specifying a file for saving data
filename = asksaveasfilename()这两个函数都会返回一个文件名。如果对话框被用户取消,那么该函数返回None。下面是使用这两个函数的一个 示例。
1 from tkinter.filedialog import askopenfilename
2 from tkinter.filedialog import asksaveasfilename
3
4 filenameforReading = askopenfilename()
5 print("You can read from" + filenameforReading)
6
7 filenameforWriting = asksaveasfilename()
8 print("You can write data to " + filenameforWriting)当运行这段代码时,askopenfilename()函数将显示打开对话框以指明要打开的文件。asksaveasfilename() 函数将显示保存为对话框来指明要保存的文件的名字和路径。
四、从网站上获取数据
关键点: 使用urlopen 函数打开一个统一 资源定位器(URL)并从网站上读取数据。
可以使用Python编写简单的代码来从Web网站上读取数据。所需要做的就是通过使用urlopen函数打开一个URL,如下所示。
infile = urllib.request.urlopen("http: //www.yahoo.com") urlopen函数(在urllib.request模块中定义)像打开一个文件一样打开一个URL资源。
下面是一个从给定的URL读取和显示网站内容的示例。
import urllib.request
infile = urllib.request.urlopen("http://www.yahoo.com/index.html")
print(infile.read().decode())使用infile.read()从URL上读取的数据是比特形式的原始数据。调用decode()方法将原始数据转换为一个字符串。
注意:为了使urlopen函数识别一个有效的URL,URL地址需要有http://前缀。
五、异常处理
关键点: 异常处理使程序能够处理异常然后继续它的正常执行。
当运行上一节的程序时,如果用户输入一个不存在的文件或URL时将会怎样?这个程序将会中断并抛出一个错误。如果运行程序清单的程序时输入一个不存在的文件名,那么程序将会报告这个异常。

这些冗长的错误信息被称为堆栈回溯或回溯。回溯通过追溯到导致这条语句的函数调用来给出导致错误的这条语句的信息。在错误信息中显示函数调用的行号以便跟踪这个错误。
在运行时出现的错误被称为异常。如何处理一个异常以使程序能够捕获这个错误并提示用户输入一个正确的文件名?可以使用Python的异常处理语法来实现。
异常处理语法是将可能产生(抛出)异常的代码包裹在try子句中,如下所示。
try:
<body>
except <ExceptionType> :
<handler>在这里,<body>包含了可能抛出异常的代码。当-一个异常出现时,<body>中剩余代码被跳过。如果该异常匹配一个异常类型,那么该类型下的处理代码将会执行。<handler> 是处理异常的代码。
try/except块按如下方式工作:
- 首先,try和except之间的语句被执行。
- 如果没有异常出现,跳过except子句。在这种情况下,执行break语句退出while循环。
- 如果在执行try子句时出现异常,子句的剩余部分将会被跳过。在这种情况下,如果文件不存在,那么open函数将会抛出一个异常,break 语句被跳过。
- 当一个异常出现时,如果异常类型匹配关键字except之后的异常名,那么这个except子句被执行,然后继续执行try语句之后的语句。
- 如果一个异常出现但是异常类型不匹配except子句中的异常名,那么这个异常被传递给这个函数的调用者;如果没有找到处理该异常的处理器,那么这是一个未处理异常且终止程序显示错误信息。
一个 try语句可以有多个except子句来处理不同的异常。这个语句也可以选择else或finally语句,语法如下所示。
try:
<body>
except <ExceptionType1>:
<handler1>
...
except <ExceptionTypeN> :
<handlerN>
except :
<handlerExcept>
else:
<process_else>
finally:
<process_finally>多个except语句与elif语句类似。当一个异常出现时,它会被顺序检查是否匹配try子句后的except子句中的异常。如果找到一个匹配,那么匹配该异常的处理器将被执行,而except子句的其他部分将会忽略。
注意:在except子句最后的<ExceptionType>可能会被忽略。如果异常在最后一个except子句之前不匹配任何一个异常类型,那么执行最后一个except子句的<handlerExcept>。
一个try语句可以有一个可选择的else子句,如果try块中没有异常抛出,将会执行else块。
一个try语句可以有一个可选择的finally 块,这用来定义收尾动作,无论何种情况都会执行这个块。
六、抛出异常
关键点:异常被包裹在对象中,而对象由类创建。一个函数抛出一个异常。
在之前的小节中已经学习了如何编写处理异常的代码。那么异常是来自哪? 一个异常是如何产生的?附属在异常上的信息包裹在一个对象中。异常产生自一个函数。当函数检测到一个错误时,它将使用下面语法从一个正确的异常类创建一个对象并把这个异常抛给这个函数的调用者。
raise ExceptionClass ("Something is wrong")下面介绍异常是如何工作的。假设程序检测到传递给函数的一个参数与这个函数的合约冲突;例如,这个参数必须是非负的,但是传递的参数是一个负数。这个程序将创建一个RuntimeError类的实例并将它抛出,如下所示。
ex = RuntimeError("Wrong argument")
raise ex或者,如果你更喜欢,可以将前面两条语句合并成一条语句。
raise RuntimeError("Wrong argument")现在你知道了如何抛出和处理异常。那么使用异常处理的好处是什么?使用异常处理能够使函数给它的调用者抛出一个异常。调用者能够处理这个异常。如果没有这种能力,被调用函数必须自己处理这个异常或者终止这个程序。通常被调用函数不知道如何处理一个错误。这对库函数而言是典型情况。库函数可以检测到错误,但是只有调用者知道在错误出现时如何处理它。异常处理的最重要优势就是将错误检测(在被调用丽数中完成)和错误处理 (在调用函数中完成)分隔开来。
许多库函数能抛出多种异常,像ZeroDivisionError、TypeError 和IndexError异常。可以使用try-except语法来捕获和处理这些异常。
函数可能会在一个函数调用链上调用其他函数。考虑多个函数调用的例子。假设main函数调用函数function1,函数function1调用函数function2,函数function2调用函数function3,而函数function3 抛出一个异常,如图所示。考虑下面的方案:
- 如果异常类型是Exception3,那么这个异常将被函数function2中处理这个异常的except块所捕获。statement5 将会被跳过,而statement6将被执行。
- 如果异常类型是Exception2,函数function2被中止,控制权返回给函数function1,而这个异常将被函数functionl中的处理Exception2的except块所捕获。statement3将会被跳过,而statement4将被执行。
- 如果异常类型是Exceptionl, 函数functionl 被中止,控制权返回给main函数,这个异常将被主函数main中处理Exceptionl的except块所捕获。statement1将会被跳过,而statement2将被执行。

七、使用对象处理异常
关键点:在except子句中访问一个异常对象。
如前所述,一个异常被包裹在一个对象中。为了抛出一个异常,需要首先创建一个异常对象,然后使用raise关键字将它抛出。这个异常对象能够从except子句访问吗?答案是肯定的。可以使用下面的语法将exception对象赋给一个变量。
try
<body>
except ExceptionType as ex:
<handler>有了这个语法,当except子句捕获到异常时,这个异常对象就被赋给一个名为ex的变量。现在,可以在处理器中使用这个对象。
八、定义自定制异常类
关键点:可以通过扩展BaseException类或BaseException类的子类来定义一个自定制异常类。
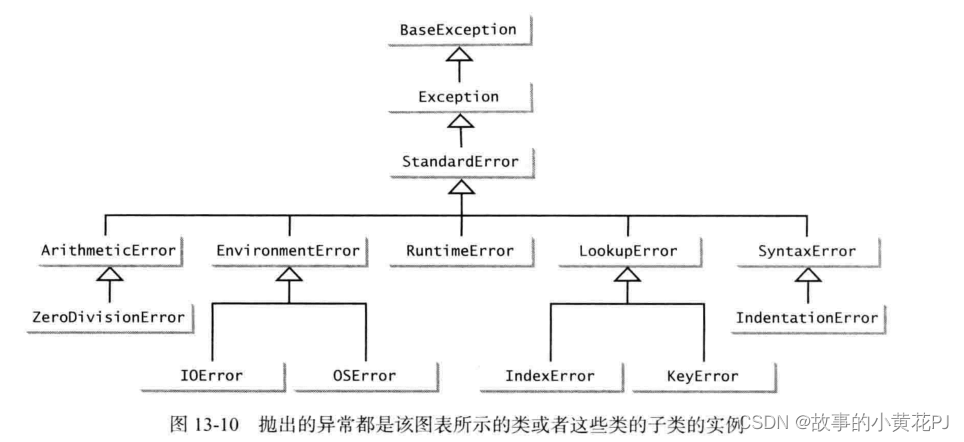
目前为止,我们已经在本章中使用了像ZeroDivisionError、SyntaxError 、RuntimeError和NameError这样的Python内置异常类。还有其他异常类型可以供我们使用吗?答案是肯定的,Python 有许多内置异常。下图给出其中一些 异常。
注意:类名Exception、StandardError 和RuntimeError有点让人迷惑。所有这三种类都是异常,且这些错误都在运行时出现。
BaseException类是所有异常类的父类。所有的Python异常类都直接或间接地继承自BaseException类。正如你所看到的,Python 提供了许多的异常类。也可以定义自己的异常
类,它们都继承自BaseException 类或BaseException 类的子类,例如: RuntimeError。
九、总结
- 可以使用文件对象来从(向)文件读(写)数据。可以打开文件,用r模式进行读取,用w模式进行写入,用a模式进行追加。
- 可以使用os.path.isfile(f)函数来检测一个文件是否存在。
- Python中有一个文件类,该类包含了读写数据和关闭文件的方法。
- 可以使用read()、readline() 和readlines()方法从文件读取数据。
- 可以使用write(s) 方法来将一个字符串写入文件。
- 在文件处理结束后关闭该文件以确保数据被正确保存。
- 可以像从一个文件中读取数据一样从网页上读取资源。
- 使用异常处理来捕获和处理运行时错误。将会抛出异常的代码放在try子句中,在except子句中罗列出异常,并且在except子向中处理异常。
- Python提供有像ZeroDivisionError、SyntaxError 和RuntimeError这样的内置异常类。所有的Python异常类都直接或间接继承自BaseException 类。也可以定义用户自己的异常类,自定义异常类扩展自BaseException 类或它的子类,像RuntimeError。