ConCurrentHashMap的实现原理
其他
2018-06-20 13:52:26
阅读次数: 3
ConCurrentHashMap的实现原理
一、JDK1.6和JDK1.7中的实现
- 设计思路
ConCurrentHashMap采用分段锁的思想,每一个段都有一把锁,从而提高了并发度(即同时操作ConCurrentHashMap而不产生锁竞争的线程最大数)。另外,当设置并发数时,会默认将并发数改为2的幂。
所谓的段,就是segment,他和HashMap的结构很像,都在内部有一个Entry数组,并且继承了重入锁,用于对段的上锁。
- 分段创建
JDK1.6会在一开始就创建所有的segment,而JDK1.7除了第一个segment,其余的segment都是在put时,动态创建的,所以,在每一次查找段的时候,都会判断段是否为空,如果为空则创建。由于ensureSegment方法要在并发场景被调用,所以创建段时,通过CAS算法实现,代码如下:if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
- put方法
与JDK1.6不同的是,JDK1.7在put时,会用tryLock(),其余并无不同。
put时,先通过key找到对应的段,在找到段内的entry,段内操作和HashMap类似。
- get方法和containsKey方法
由于ConCurrentHashMap的get方法和containsKey都是不加锁的,所以很有可能当ConCurrentHashMap遍历过程中有其他的线程对其内容进行更改,导致两方法返回的数据不是最新的数据。
- size方法
size方法也会使用CAS对modcount进行判断,当多次重试后,会对所有的segment上锁。
- ConCurrentHashMap不允许key和value为空
二、JDK1.8的实现
- 设计思路
JDK1.8取消了segment的概念,还是使用的HashMap中数组加链表的数据结构,但是对于每一个数组进行加锁,以调整锁的粒度。同时,为了防止hash冲突造成的链表过长,当链表长度大于8时,会把链表变为红黑二叉树的数据结构,当红黑树的长度小于等于6时,又可以转化为链表。
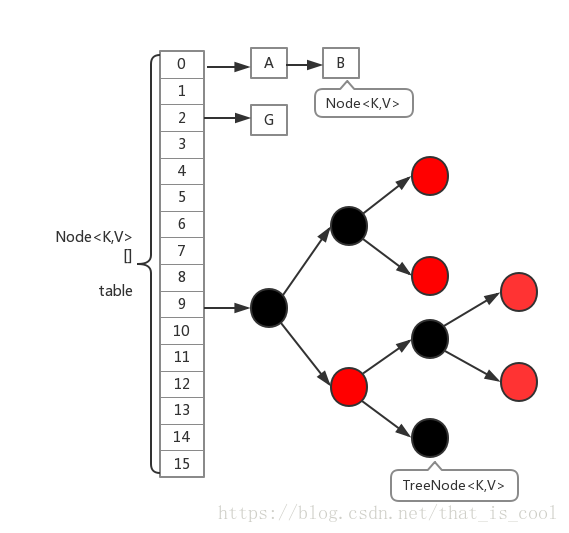
- 使用了synchronized关键字而不是重入锁
可见JDK1.8对synchronized进行了性能优化。
转载自blog.csdn.net/that_is_cool/article/details/80527023