2.0 概述
线程同步是对数据保护的一种机制,被保护的数据是共享数据,共享数据就是多个线程共同访问的一块儿资源,也就是一块儿内存,就是同一块儿内存,假如有两个线程A和B同时去写数据,A写100,B写200,而这时线程C同时去读取这块儿内存,那么读到的是什么数据呢?这个时候肯定会出错,因为三个线程同时去使用这块儿内存,就会导致错误的发生,所以线程同步并不是说让多个线程同时去干某件事儿,而是说在做某件事儿的时候让多个线程依次按顺序去执行,也就是说线程同步并不是让线程并行的执行,而是让线程线性的执行,这样就可以保证数据的安全性。
假设有 4 个线程 A、B、C、D,当前一个线程 A 对内存中的共享资源进行访问的时候,其他线程 B, C, D 都不可以对这块内存进行操作,直到线程 A 对这块内存访问完毕为止,B,C,D 中的一个才能访问这块内存,剩余的两个需要继续阻塞等待,以此类推,直至所有的线程都对这块内存操作完毕。
例子:
#include <iostream>
#include <thread>
//#include <mutex>
//Linux make: g++ -o main main3.c -lpthread
using namespace std;
//static mutex mut;
int i=0;
void thread_1(int n){
while(n--){
//mut.lock();
i++;
//mut.unlock();
}
}
int main(){
//n越大,i在不加锁的情况下出错越大
int n=100000;
thread th1(thread_1,n);
thread th2(thread_1,n);
th1.join();
th2.join();
cout<< i << endl;
return 0;
} 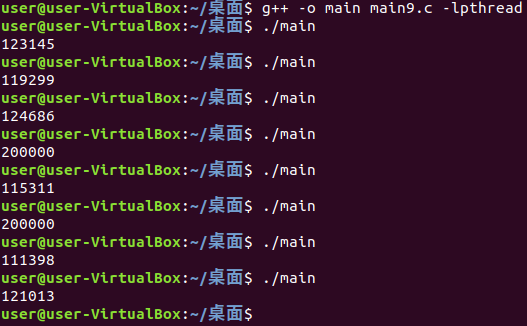
多次运行这个程序,就会发现会输出不同的结果,也就是说中间如果不出错的情况下,他们输出的数据应该是一样的,而现在明显这两个线程对同一块儿内存空间进行同时操作(现在的这个内存空间就是这个全局变量 i ),进而造成了错误的发生。
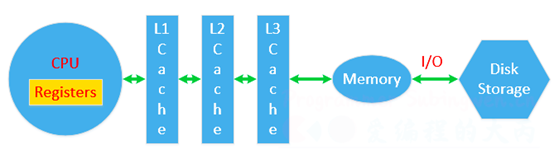
多个线程是分时复用CPU时间片,也就是A版线程需要去抢CPU的时间片,谁抢到谁执行,假如A线程抢到了CPU的时间片,CPU几开始数数了,数到的数据是从哪里来的呢?这个数据是从物理内存里面读取出来的,这个物理内存的数据会被加载到CPU的寄存器里面去,通过寄存器进行处理,一般情况下物理内存和CPU之间还有缓存,一般是三级缓存,数据从物理内存->三级缓存->二级缓存->一级缓存->CPU寄存器,缓存就是为了提高速度,寄存器的处理速度比物理内存的处理速度还要快的多得多,有了这样一个缓存之后就可以提高数据的处理效率。
同步方式
对于多个线程访问共享资源出现数据混乱的问题,需要进行线程同步。常用的线程同步方式有四种:互斥锁、读写锁、条件变量、信号量。所谓的共享资源就是多个线程共同访问的变量,这些变量通常为全局数据区变量或者堆区变量,这些变量对应的共享资源也被称之为临界资源。

被锁住的区域每个线程只能独自运行这块儿区域,不能同时运行,只有当前线程出去解锁之后,其他线程才能够在锁上解除阻塞,假如阻塞了三个,就会去抢这个锁,谁抢到谁解除阻塞,
2.1 多线程的状态及其切换流程分析
线程状态说明:
初始化(Init):该线程正在被创建。(就是创建thread对象并设置好回调函数,该线程就处在初始化状态,初始化线程的内存空间啊等,这部分其实代码干预部分不多,也就是从初始化,到就绪态之间其实是有一个时间消耗的,这就是为什么后面使用线程池来做一个处理,来减少时间消耗,当各种内存准备好之后,就变成就绪态了)
就绪(Ready):不代表立刻就能运行了,该线程在就绪列表中,等待 CPU 调度。
运行(Running):该线程正在运行。被CPU调度到了。
阻塞(Blocked):该线程被阻塞挂起。Blocked 状态包括:pend(锁、 事件、信号量等阻塞)、suspend(主动 pend)、delay(延时阻塞)、 pendtime(因为锁、事件、信号量时间等超时等待)。阻塞态就是,CPU的调度已经不再这里了,放弃CPU的调度,不浪费资源。
退出(Exit):该线程运行结束,等待父线程回收其控制块资源。

2.2 竞争状态和临界区介绍 互斥锁mutex代码
竞争状态(Race Condition): 多线程同时读写共享数据
临界区(Critical Section): 读写共享数据的代码片段
要避免竞争状态策略, 对临界区进行保护,同时只能有一个线程进入临界区。
为了解决2.0概述中的问题:
这时候需要加一个mutex的锁(mutex是一个互斥锁),需要包含头文件:#include <mutex>
static mutex mux; mux叫做互斥变量。资源被上锁后,其他线程相当于是排队等待-阻塞
mux.lock是操作系统层面的锁,mux互斥锁只有这一个,线程主动过来处理的时候必须先抢占锁资源,所以线程它是一边抢占CPU资源一边抢占锁资源。
#include <iostream>
#include <thread>
#include <mutex> //需要包含的头文件
//Linux make: g++ -o main main3.c -lpthread
using namespace std;
static mutex mut; //添加互斥锁变量
int i=0;
void thread_1(int n){
while(n--){
mut.lock(); //获取锁资源,如果没有获得,则阻塞等待
i++;
mut.unlock();//释放锁
}
}
int main(){
//n越大,i在不加锁的情况下出错越大
int n=100000;
thread th1(thread_1,n);
thread th2(thread_1,n);
th1.join();
th2.join();
cout<< i << endl;
return 0;
} 
从多次运行的结果看来不再出现错误了,每次都是一样的输出,线程同步成功。
2.3 互斥锁的坑 线程抢占不到资源原因
理想状态,当一个线程释放锁资源之后,后面的线程会排队获取锁资源,但是实际上有时会出现一个线程始终占领着这个资源,其他线程排队永远获取不到资源的情况。
#include <thread>
#include <iostream>
#include <string>
#include <mutex>
//Linux -lpthread
using namespace std;
static mutex mux;
void ThreadMainMux(int i)
{
for (;;)
{
mux.lock();
cout << i << "[in]" << endl;
this_thread::sleep_for(100ms);
mux.unlock();
}
}
int main(int argc, char* argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadMainMux, i + 1);
th.detach();
}
getchar();
return 0;
} 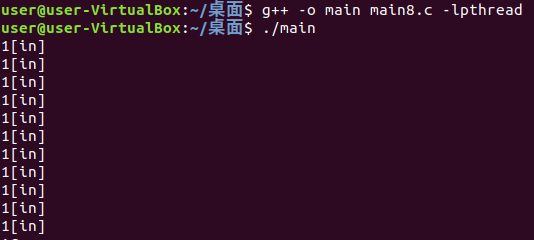
你会发现结果就是一直总是这一个线程进入,而不是理想的所有的线程都能得到展示,并不是我们想要的结果,原因如下:
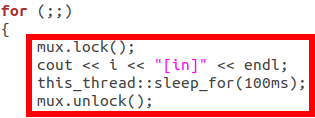
这段代码中,线程1获得锁资源的时候,线程2和线程3处于阻塞态,当线程1解锁的时候,按道理2号3号线程应该有一个立即获得锁资源的,但是对于线程1来说,当它解锁的时候,又重新进入了锁,也就是解锁后自己又重新申请了锁,这个锁是操作系统内核来判断,这个锁资源有没有被占用掉,当线程1解锁后,它的内存资源当然不是立即就被释放的,因为我们的操作系统不是实时操作系统,从解锁再到锁之间可能就是微秒级别的,而CPU调度肯定是过一段时间探测一下这个资源,当线程1解锁后立即又进入了锁,操作系统来不及反应,操作系统会认为是线程1又抢到了锁资源,实际上不是,而是因为线程1的资源还没有来得及释放就又重新进入锁了,所以它没有排队就再次进入了,所以这就是坑的所在,因此在解锁和锁之前要加一个延时,给操作系统做一个释放的时间。
#include <thread>
#include <iostream>
#include <string>
#include <mutex>
//Linux -lpthread
using namespace std;
static mutex mux;
void ThreadMainMux(int i)
{
for (;;)
{
mux.lock();
cout << i << "[in]" << endl;
//std::this_thread::sleep_for和sleep,没啥太大区别,都是表示当前线程休眠一段时间,
//休眠期间不与其他线程竞争CPU,根据函数参数,等待相应时间时间。
//只是一个是C的函数一个是c++的函数分别对应头文件 <unistd.h> 和 < thread >
this_thread::sleep_for(100ms);
mux.unlock();
this_thread::sleep_for(1ms);
}
}
int main(int argc, char* argv[])
{
for (int i = 0; i < 3; i++)
{
thread th(ThreadMainMux, i + 1);
th.detach();
}
getchar();
return 0;
}
2.4 超时锁timed_mutex(避免长时间死锁) 和 递归锁recursive_mutex
mutex默认没有超时的,而有线程占用的情况下,其他线程是一直处于阻塞状态的,这种方式代码简洁,但是为后期的代码调试增加难度,比如说我们不小心在代码当中写了一个死锁,那你在调试当中你怎么去找到这个死锁呢?每次锁之前记录一下日志,看有没有进去,这样的调试成本比较大,不容易发现,只要加了timed就支持超时。
#include <thread>
#include <iostream>
#include <string>
#include <mutex>
//Linux -lpthread
using namespace std;
timed_mutex tmux;
void ThreadMainTime(int i){
for (;;){
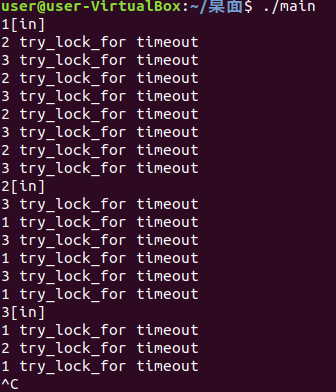
if (!tmux.try_lock_for(chrono::milliseconds(500))){ //等待时间超过500ms就超时了
cout << i << " try_lock_for timeout" << endl;
continue;
}
cout << i << "[in]" << endl;
this_thread::sleep_for(2000ms); //假设要处理的业务的持续时间
tmux.unlock();
this_thread::sleep_for(1ms); //防止某一个线程一直占用这个锁资源
}
}
int main(int argc, char* argv[]){
for (int i = 0; i < 3; i++){
thread th(ThreadMainTime, i+1);
th.detach();
}
getchar();
return 0;
}
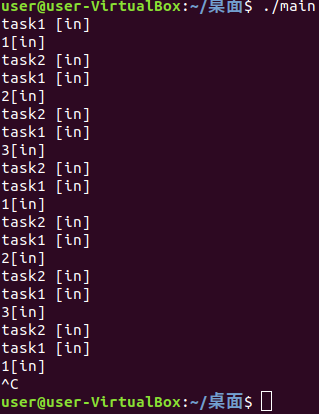
很多业务可能会用到同一个锁,就会出现同一个锁被锁多次的情况,如果是普通的锁的话(mutex锁),第二次锁的时候会抛出异常,若没有捕获异常,那么程序就会崩溃掉,而这个递归锁可以进行多次上锁,他会把当前线程的锁计数加一,还是处于锁的状态不会改变,有多少次lock就会有多少次unlock,直到计数变成零的时候才真正释放,可以避免不必要的死锁。
#include <thread>
#include <iostream>
#include <string>
#include <mutex>
//Linux -lpthread
using namespace std;
recursive_mutex rmux;
void Task1(){
rmux.lock();
cout << "task1 [in]" << endl;
rmux.unlock();
}
void Task2(){
rmux.lock();
cout << "task2 [in]" << endl;
rmux.unlock();
}
void ThreadMainRec(int i){
for(;;){
rmux.lock();
Task1();
cout << i << "[in]" << endl;
this_thread::sleep_for(500ms);
Task2();
rmux.unlock();
this_thread::sleep_for(1ms);
}
}
int main(int argc, char* argv[]){
for (int i = 0; i < 3; i++){
thread th(ThreadMainRec, i + 1);
th.detach();
}
getchar();
return 0;
}
2.5 共享锁shared_mutex解决读写问题
当前线程在写数据的时候需要互斥,就是其他线程既不能写也不能读。当前线程在读的时候,其他线程只能读,不能写。
这里面就涉及到两个锁,一个读的锁,一个写的锁,若这个线程只读的话,那我们就用一个只读的锁就可以了,但是这个线程里面涉及到修改的时候,需要先拿到读的锁,然后再去获得写的锁,然后再修改,修改完之后再释放,用这种方式做一个共享。
共享锁当中包含两个锁,一个是共享锁,一个是互斥锁,只要没有人锁定互斥锁,共享锁都是立即返回的,只要有人锁定了互斥锁,共享锁不能进,其他的互斥锁也不能进。
c++14 共享超时互斥锁 shared_timed_mutex(默认一般值支持到C++14)
c++17 共享互斥 shared_mutex
如果只有写时需要互斥,读取时不需要,用普通的锁的话如何做
按照如下代码,读取只能有一个线程进入,在很多业务场景中,没有充分利用 cpu 资源。
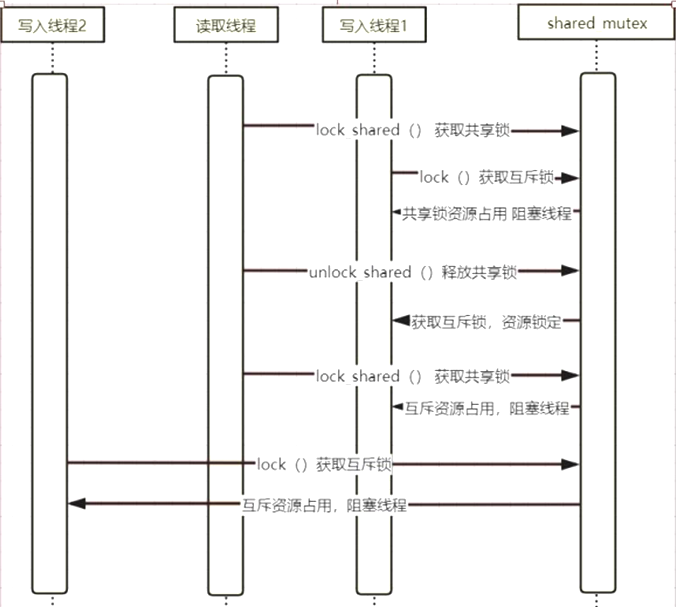
原理是,如果有一个线程在写,其他所有线程既不能读也不能写,如果说有一个线程在读,其他线程都可以读,但不能写,必须等待所有的读线程读完之后才能写,这样就确保了资源不会被多人写而出现错误。
这就是我们要用的共享锁。读取锁一定要先释放,读取锁如果锁住的话,互斥锁也是进不去的。互斥锁一旦进入,其他的所有读取线程都在等待。其他线程的写入锁也在等待,也既同时只能有一个线程在写入。
#include <thread>
#include <iostream>
#include <string>
#include <mutex>
#include <shared_mutex>
//Linux make: g++ -std=c++14 -o main main8.c -lpthread
using namespace std;
//shared_mutex smux; //c++17 共享锁
shared_timed_mutex stmux; //c++14 共享锁
void ThreadRead(int i){
for(;;){
//stmux.lock_shared();共享锁,只要对方没有把互斥锁锁住,共享锁大家都可以进去。
stmux.lock_shared();
cout << i << " Read" << endl;
this_thread::sleep_for(500ms);
stmux.unlock_shared();
this_thread::sleep_for(1ms);
}
}
void ThreadWrite(int i){
for(;;){
stmux.lock_shared();
//读取数据
stmux.unlock_shared();
stmux.lock(); //互斥锁 写入
cout << i << " Write" << endl;
this_thread::sleep_for(300ms);
stmux.unlock();
this_thread::sleep_for(1ms);
}
}
int main(int argc, char* argv[]){
for(int i = 0; i < 3; i++){
thread th(ThreadWrite, i + 1);
th.detach();
}
for(int i = 0; i < 3; i++){
thread th(ThreadRead, i + 1);
th.detach();
}
getchar();
return 0;
}