1.array(数组)
数组是已经确定长度的。已经确定好了所使用的内存,当数组长度不够时,并不会动态的去扩容和自动的申请新的内存。
数组的声明和格式:
//一维数组
var a = [5]int{12, 34, 56, 78, 90}
//也可以这样写
b := [5]int{21, 43, 65}
fmt.Println("a的长度和容量:", len(a), cap(a))
fmt.Println("b的长度和容量:", len(b), cap(b))
fmt.Println("a数组为:", a, "b数组为:", b)
//二维数组
var c = [4][5]int{
{1, 2, 3}, {4, 5, 6}}
//也可以这样写
d := [4][5]int{[5]int{1, 2, 3}, [5]int{4, 5, 6}}
fmt.Println("d的行的长度和容量:", len(d), cap(d))
fmt.Println("d的某行中列的长度和容量", len(d[1]), cap(d[1]))
fmt.Println("c数组为:", c, "d数组为:", d)
output
a的长度和容量: 5 5
b的长度和容量: 5 5
a数组为: [12 34 56 78 90] b数组为: [21 43 65 0 0]
d的行的长度和容量: 4 4
d的某行中列的长度和容量 5 5
c数组为: [[1 2 3 0 0] [4 5 6 0 0] [0 0 0 0 0] [0 0 0 0 0]] d数组为: [[1 2 3 0 0] [4 5 6 0 0] [0 0 0 0 0] [0 0 0 0 0]]
我们可以清晰的看出数组的长度和容量是一致的。数组的特性是声明即定长,无法原地进行扩容,所以Golang中一般来说需要使用到数组的场合都会使用切片来替代。
2. slice(切片)
切片的声明和数组的声明一直,只不过切片可以动态扩容。
slice声明:
var a []int
//也可以
a:=[]int{1,2,3}切片的本质是引用底层数组头指针+当前切片长度+底层数组大小:即array、len和cap:
slice的结构:
type slice struct {
array unsafe.Pointer // 底层数组头指针
len int // 当前切片长度
cap int // 底层数组最大容量
}举例:
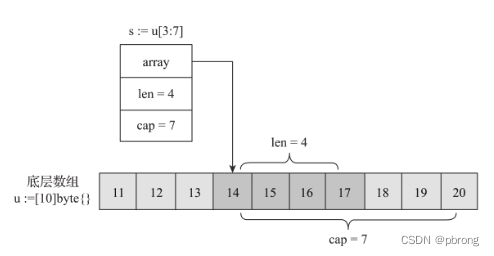
我们设置u为底层数组,s1为第一次切片。
u := [10]byte{11, 12, 13, 14, 15, 16, 17, 18, 19, 20} // 长度为10的数组
s1 := u[3:7] // 从数组的第3个元素至第6个元素建立切片(前闭后开区间)
fmt.Println(len(s1), cap(s1))
fmt.Println("u=", u, "s1=", s1)
output
4 7
u= [11 12 13 14 15 16 17 18 19 20] s1= [14 15 16 17]
2.我们再用该底层数组进行分片,为s2。
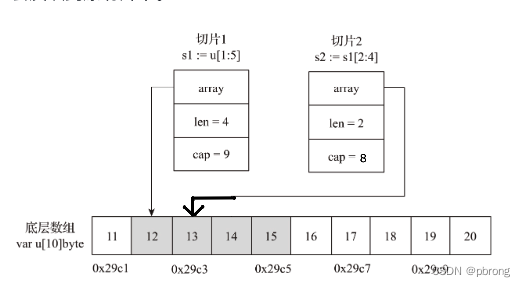
//修改s1的值
s1[0] = 45
s1[3] = 89
s2 := u[2:8]
fmt.Println(len(s2), cap(s2))
fmt.Println("u=", u, "s1=", s1, "s2=", s2)
output
6 8
u= [11 12 13 45 15 16 89 18 19 20] s1= [45 15 16 89] s2= [13 45 15 16 89 18]
通过输出结果我们可以发现,两个切片作用在用一个底层数组上时,是相互影响的。
扩容机制:
看到这里你有没有这样的疑惑,既然在初始化的时候已经指定数据的大小了,那为什么还要指定预留的大小呢?这是因为 make() 使用的是一种动态数组算法,一开始先向操作系统申请一小块内存,这个就是 cap,等 cap 被 len 占用满以后就需要扩容,扩容就是动态数组再去向操作系统申请当前长度的两倍的内存,然后将旧数据复制到新内存空间中。
用代码举例:
var data []int
for i, n := 0, 20; i < n; i++ {
data = append(data, 1)
fmt.Printf("len=%d cap=%d\n", len(data), cap(data))
}
//output
len=1 cap=1 # 第一次扩容
len=2 cap=2 # 第二次扩容
len=3 cap=4 # 第三次扩容
len=4 cap=4
len=5 cap=8 # 第四次扩容
len=6 cap=8
len=7 cap=8
len=8 cap=8
len=9 cap=16 # 第五次扩容
len=10 cap=16
len=11 cap=16
len=12 cap=16
len=13 cap=16
len=14 cap=16
len=15 cap=16
len=16 cap=16
len=17 cap=32 # 第六次扩容
len=18 cap=32
len=19 cap=32
len=20 cap=32
通过上面的结果我们可以发现,当容量大于我们设置的最大容量时,将会以当前最大容量的二倍进行扩展,但是当扩展到一定程度上时,将会少于2倍的扩展。
slice的内置函数
- cap():slice的最大容量,上例中的 Slice_a和Slice_b的cap()值分别为8和5。正式由于Slice_a容量为8,所以给Slice_b的赋值是有效的
- len():slice的长度,上例已有介绍,Slice_a和Slice_b的len()值分别为3和2
- append():向 slice 里面追加一个或者多个元素,然后返回一个和 slice 一样类型的slice
- copy():函数 copy 从源 slice 的 src 中复制元素到目标 dst ,并且返回复制的元素的个数
3. make和new操作
make跟new都可以用于内存分配。
- new用于各种类型的内存分配,本质上跟java的new的功能是一样的。new(T)返回了一个指针,指向新分配的类型 T 的零值。
- make只能用于给slice、map和channel类型的内存分配,并且返回一个有初始值(非零)的 T 类型,而不是指针 T。
make声明为:
make(Type, len, cap)其参数有三个:
- Type:数据类型,必要参数,Type 的值只能是 slice、 map、 channel 这三种数据类型。
- len:数据类型实际占用的内存空间长度,map、 channel 是可选参数,slice 是必要参数。
- cap:为数据类型提前预留的内存空间长度,可选参数。所谓的提前预留是当前为数据类型申请内存空间的时候,提前申请好额外的内存空间,这样可以避免二次分配内存带来的开销,大大提高程序的性能。
扩容存在损耗,所以尽可能在已知数据最长度的情况下声明切片的cap,避免频繁库容切换底层数组带来的性能损耗:
//没有设置cap
func BenchmarkAppendZeroSlice(b *testing.B) {
maxNum := 10000
for i := 0; i < b.N; i++ {
// 空切片
var zeroSlice []int
for j := 0; j < maxNum; j++ {
zeroSlice = append(zeroSlice, j)
}
}
}
//设置了cap
func BenchmarkAppendCapSlice(b *testing.B) {
maxNum := 10000
for i := 0; i < b.N; i++ {
// 声明cap的切片
capSlice := make([]int, 0, maxNum)
for j := 0; j < maxNum; j++ {
capSlice = append(capSlice, j)
}
}
}
其测试速度如下:
PS D:\Project\GoLang\test> go test -bench .
goos: windows
goarch: amd64
pkg: test
cpu: AMD Ryzen 5 5600U with Radeon Graphics
BenchmarkAppendZeroSlice-12 28065 41915 ns/op
BenchmarkAppendCapSlice-12 108114 11399 ns/op
- BenchmarkAppendZeroSlice-12 意思为这个函数用的cpu核数为12,
- 28065 是运行的次数
- 41915 ns/op 是每次平均时间
从结果我们可以看出提前分配好cap运行一次为11399ns,而没有提前设置的话为41915ns,有很大的性能差距。所以我们应该尽量的先设置cap。
4. map
map声明:
a := make(map[string][]int)
a["tom"] = append(a["tom"], 56, 78, 90)
a["jack"] = append(a["jack"], 67, 77, 34)
fmt.Println(a)
output
map[jack:[67 77 34] tom:[56 78 90]]借鉴连接:
Golang原理分析:切片(slice)原理及扩容机制_go语言切片扩容原理_pbrong的博客-CSDN博客
Go语言基础:array、slice、make和new操作、map_go语言array := make_悠悠豆的博客-CSDN博客