Stable Diffusion 原理介绍与源码分析(一) - 知乎前言(与正文无关,可以忽略) Stable Diffusion 是 Stability AI 公司开源的 AI 文生图扩散模型。之前在文章 扩散模型 (Diffusion Model) 简要介绍与源码分析 中介绍了扩散模型的原理与部分算法代码,满足基本的…![]() https://zhuanlan.zhihu.com/p/613337342Stable Diffusion 原理介绍与源码分析(二、DDPM、DDIM、PLMS) - 知乎系列文章Stable Diffusion 原理介绍与源码分析(一、总览)前言(与正文无关,可忽略)发现标题越起越奇怪了... 本文继续介绍 Stable Diffusion 框架的实现。在之前的文章 Stable Diffusion 原理介绍与源码分析(…
https://zhuanlan.zhihu.com/p/613337342Stable Diffusion 原理介绍与源码分析(二、DDPM、DDIM、PLMS) - 知乎系列文章Stable Diffusion 原理介绍与源码分析(一、总览)前言(与正文无关,可忽略)发现标题越起越奇怪了... 本文继续介绍 Stable Diffusion 框架的实现。在之前的文章 Stable Diffusion 原理介绍与源码分析(…![]() https://zhuanlan.zhihu.com/p/615310965结合上面材料和stable-diffusion-webui来看img2img和txt2img的过程,webui是基于stabilty的stable-diffusion写的,stablity都是基于ldm这个库写的,和compvis的stable-diffusion一样,基本没什么区别,controlnet也是,当然webui进行了很多改造,比如负样本以及各种prompt的优化,当然diffusers写的也很好,但是由于本身基于webui去封装api库,所以看一下webui中的实现也是有必要的,diffusers的封装也很到位,基本也看不出来实现细节了。目前主流的基于扩散模型的生成任务代码就两个,一个是ldm,另一个就是diffusers,我建议推理使用ldm,因为基于webui的这块的优化和三方库特别多,训练可以用diffusers,封装的很方便,当然如果不是自己封装接口,那就无所谓了。
https://zhuanlan.zhihu.com/p/615310965结合上面材料和stable-diffusion-webui来看img2img和txt2img的过程,webui是基于stabilty的stable-diffusion写的,stablity都是基于ldm这个库写的,和compvis的stable-diffusion一样,基本没什么区别,controlnet也是,当然webui进行了很多改造,比如负样本以及各种prompt的优化,当然diffusers写的也很好,但是由于本身基于webui去封装api库,所以看一下webui中的实现也是有必要的,diffusers的封装也很到位,基本也看不出来实现细节了。目前主流的基于扩散模型的生成任务代码就两个,一个是ldm,另一个就是diffusers,我建议推理使用ldm,因为基于webui的这块的优化和三方库特别多,训练可以用diffusers,封装的很方便,当然如果不是自己封装接口,那就无所谓了。
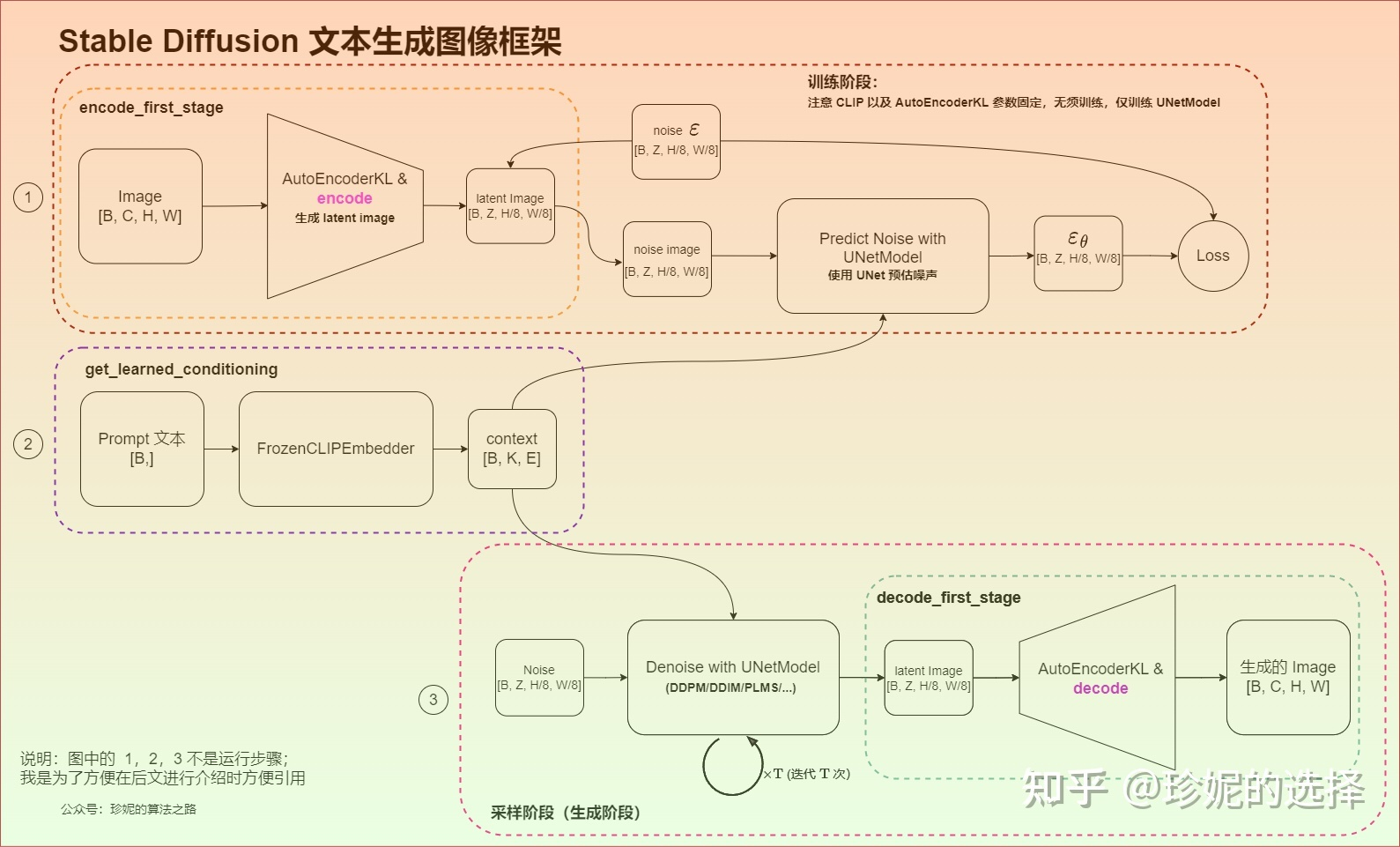

上面写的很好, 核心都在Predict Noise with UNetModel和Denoise with UNetModel中,在DDPM中,注意训练时虽然理论上多次添加噪声并预测,但实际上是只加一次噪声并预测,但在推理中是不断去噪的。
1.UNetModel
sd中的unet是核心,当然unet中也包括了self-attention和cross-attention,sd利用unet来预测噪声,这块代码在stable-diffusion-stability-ai/ldm/modules/diffusionmodules/model.py中,
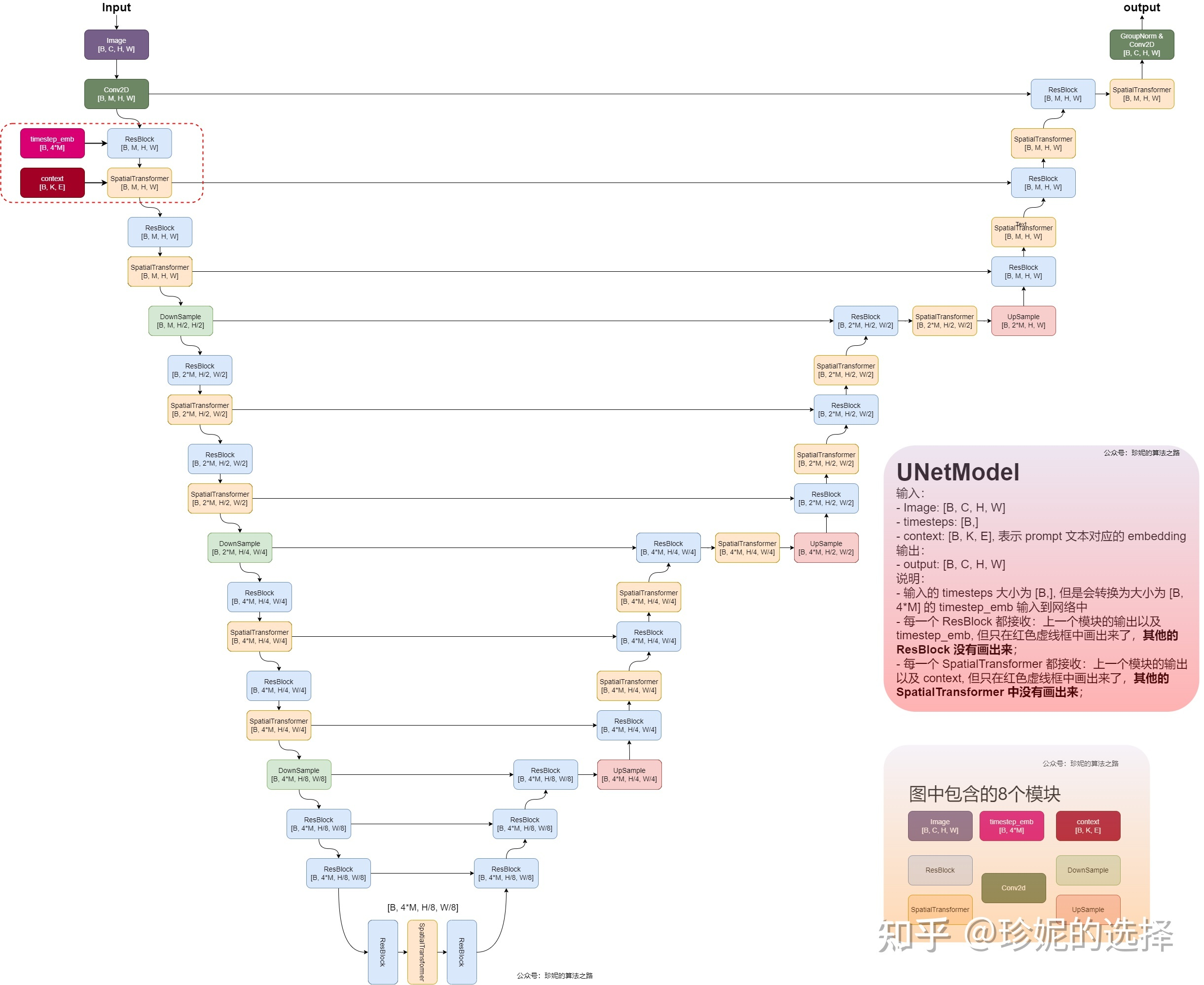

模型使用downsample和upsample来对样本进行下采样和上采样,resblock和spatialTransformer,其中每一个resblock接收来自上一个模块输入以及timesteps对应的embedding,每一个spatialTransformer接收来自上一个模块输入以及context(prompt文本的embedding表示),使用cross attention,以context为condition,学习图像和文本的匹配关系。unet不改变模型的输入输出大小。
1.1 ResBlock

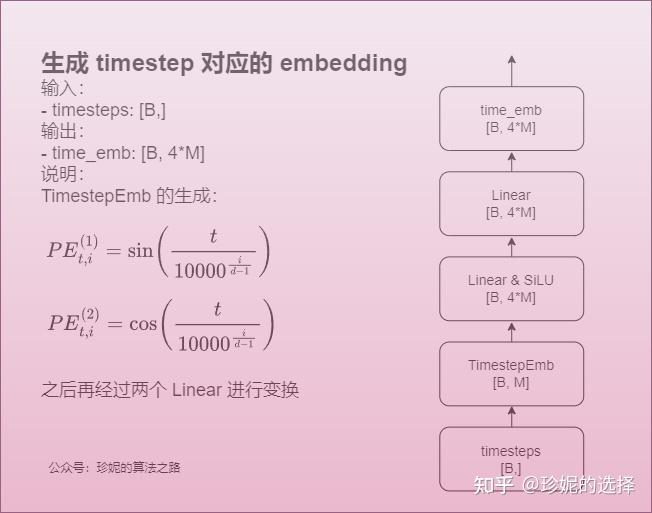
timestep_embedding,在sdxl中在数据输入训练时常用到的方法
prompt文本的embedding实现

spatialTransformer
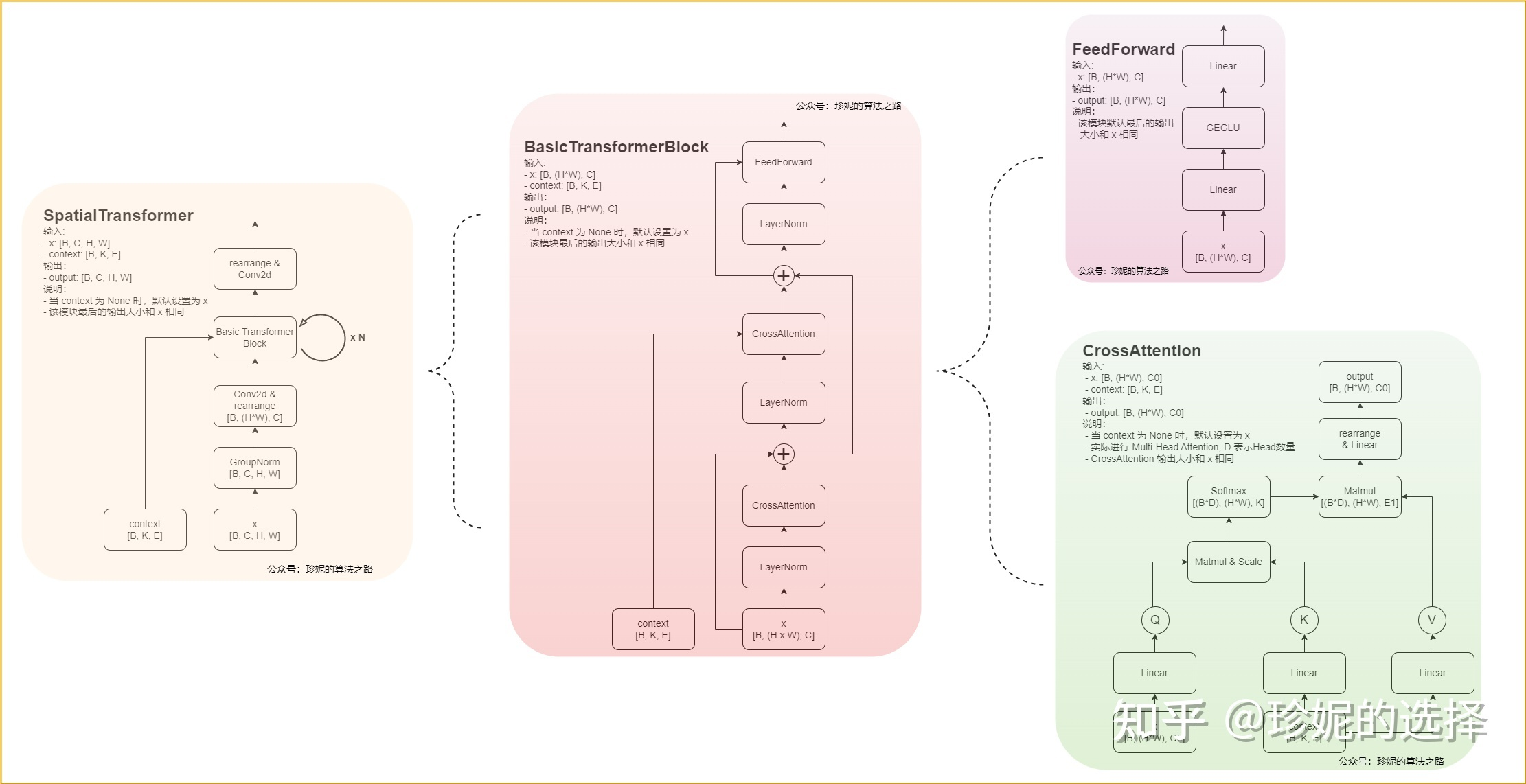
图像信息是query,文本信息是key和value。 注意到basic transformerblock中的第一个cross-attention其实没有文本输入,就是self-attention。
DDPM

ddpm代码在ldm/models/diffusion/ddpm.py中

可见ddpm的加噪是一次性完成的
在推理中:

针对DDPM的改进
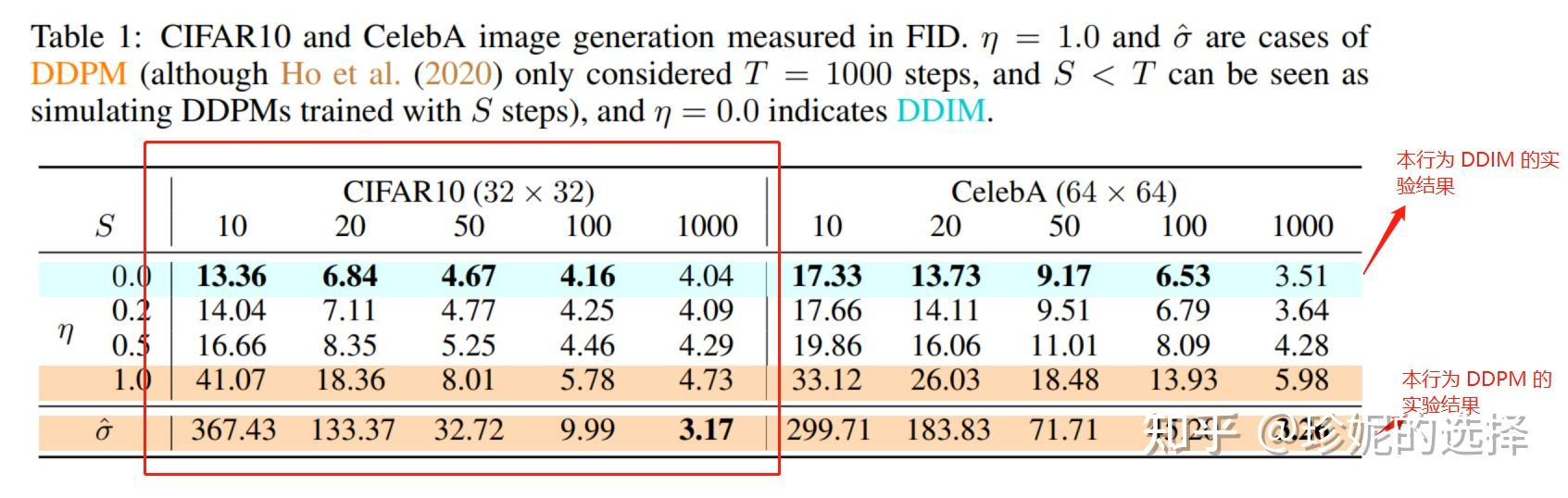
第一行是DDIM,最后一行是DDPM的结果, FID来评价图片质量,S为迭代次数,在相同步数时,DDIM效果要好。
DDIM
将加噪定义为非马尔科夫过程。
后面的采样器基本也是基于DDPM改进的。