文章目录
- MixMatch: A Holistic Approach to Semi-Supervised Learning(2019)
- CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features(2019)
- Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
- U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
- Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
- CBAM: Convolutional Block Attention Module
- FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- Res2Net: A New Multi-scale Backbone Architecture(2019)
- Barlow Twins: Self-Supervised Learning via Redundancy Reduction(2021)
- Emerging Properties in Self-Supervised Vision Transformers(2021)
- MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE,AND MOBILE-FRIENDLY VISION TRANSFORMER(2022)
- Supervised Contrastive Learning(2020)
- RepVGG: Making VGG-style ConvNets Great Again(2021)
- Pay Attention to MLPs(2021)
- Dual Path Networks(2017)
- Visual Attention Network(2022)
- PVT v2: Improved Baselines with Pyramid Vision Transformer(2021)
- Swin Transformer V2: Scaling Up Capacity and Resolution
- MetaFormer Is Actually What You Need for Vision(2022)
- CvT: Introducing Convolutions to Vision Transformers(2021)
MixMatch: A Holistic Approach to Semi-Supervised Learning(2019)
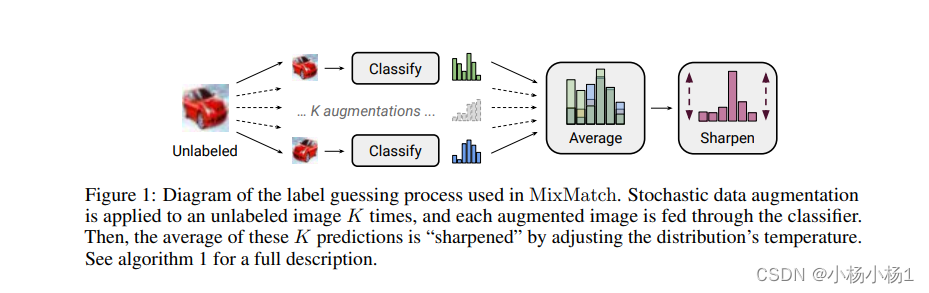

锐化的公式
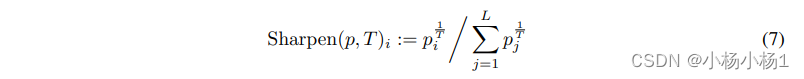
CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features(2019)


图片混合起来
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
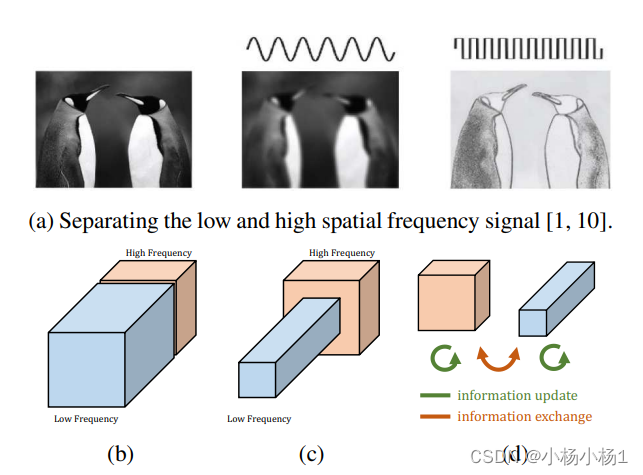
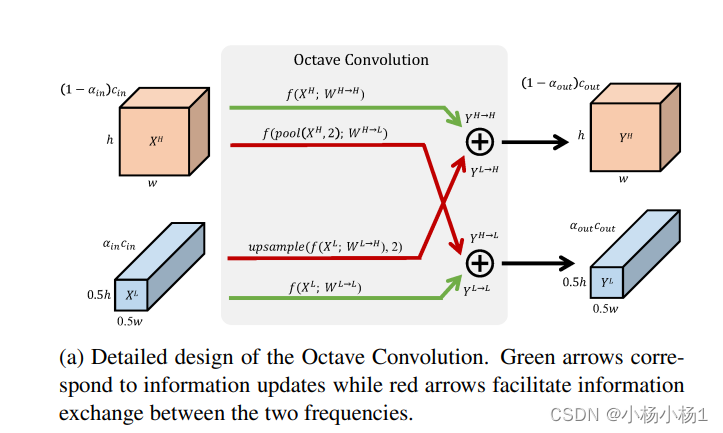
两个低高频信息的更新以及交换
U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
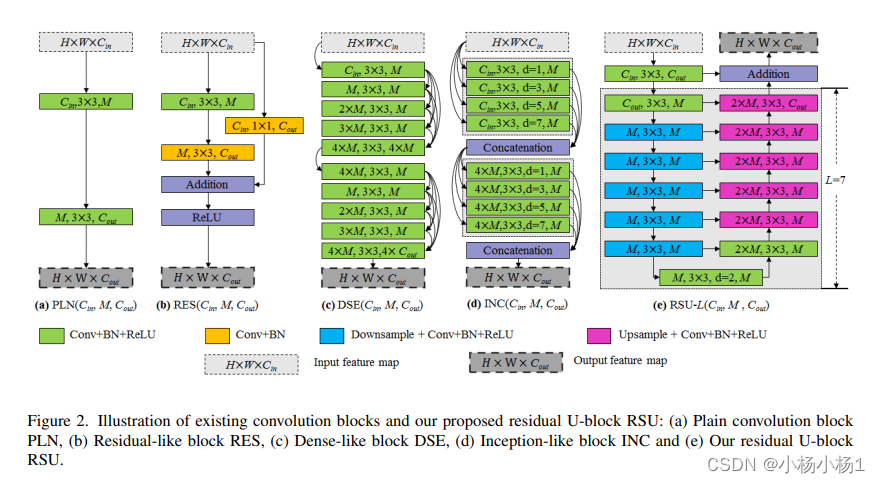
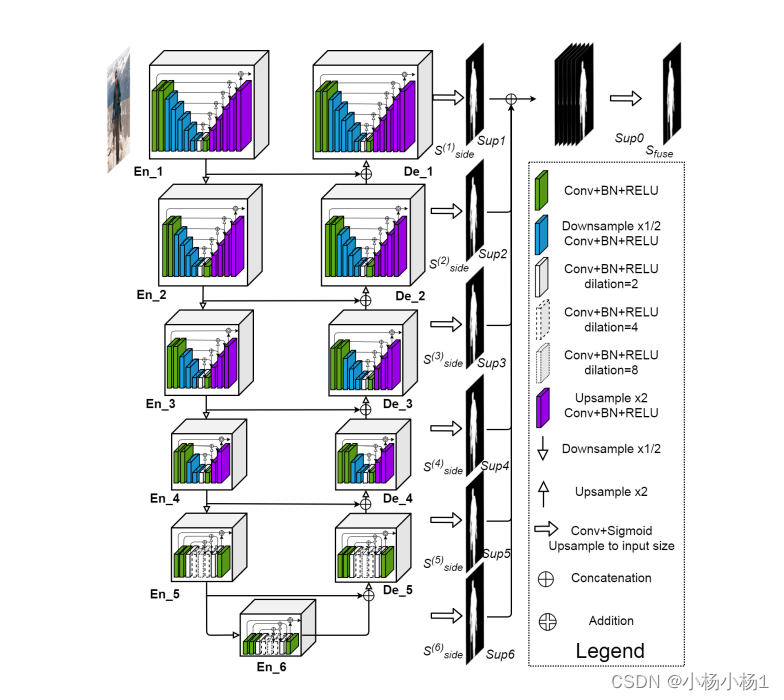
就是嵌套UNet
Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
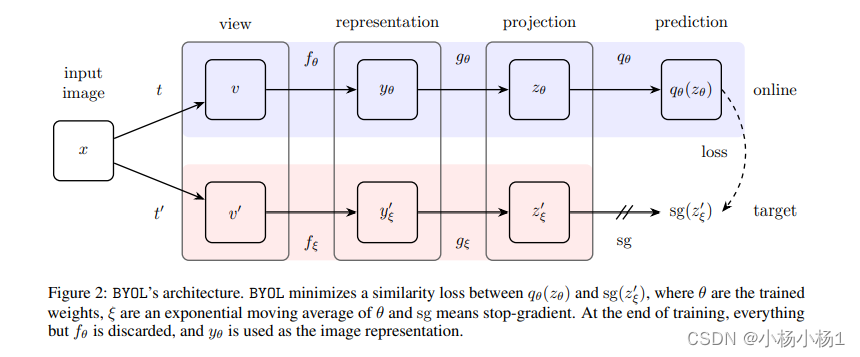
采用平均教师模型来对两个不同输出进行损失
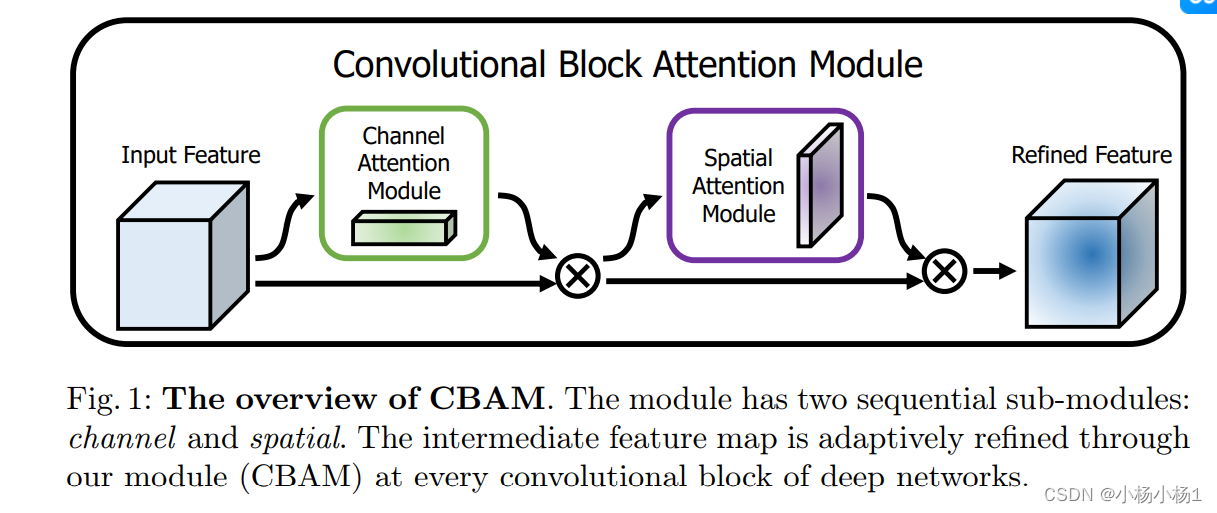
CBAM: Convolutional Block Attention Module

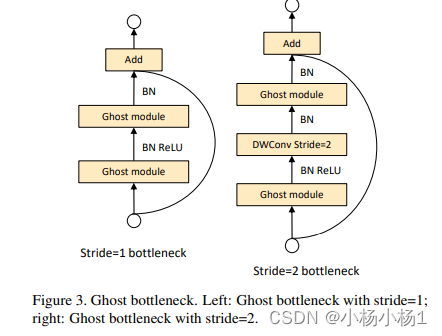
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
可以通过代码就比较好理解了,他这个的本质就是减少卷积的参数
代码地址
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
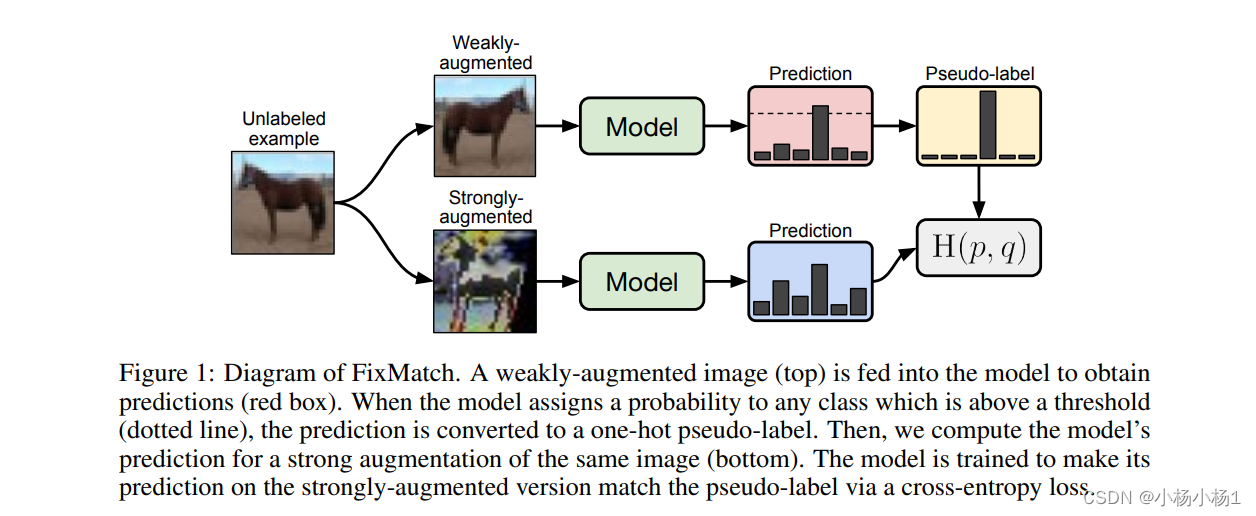
就是不同的增强利用交叉熵计算机他们概率分布的一个损失
Res2Net: A New Multi-scale Backbone Architecture(2019)
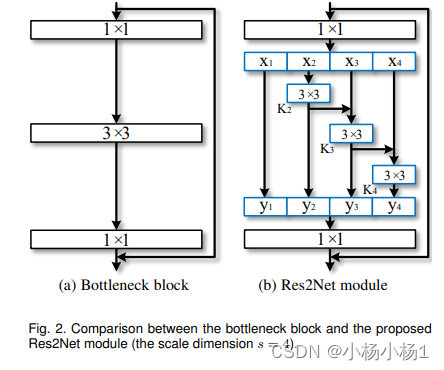
增加多规模
Barlow Twins: Self-Supervised Learning via Redundancy Reduction(2021)
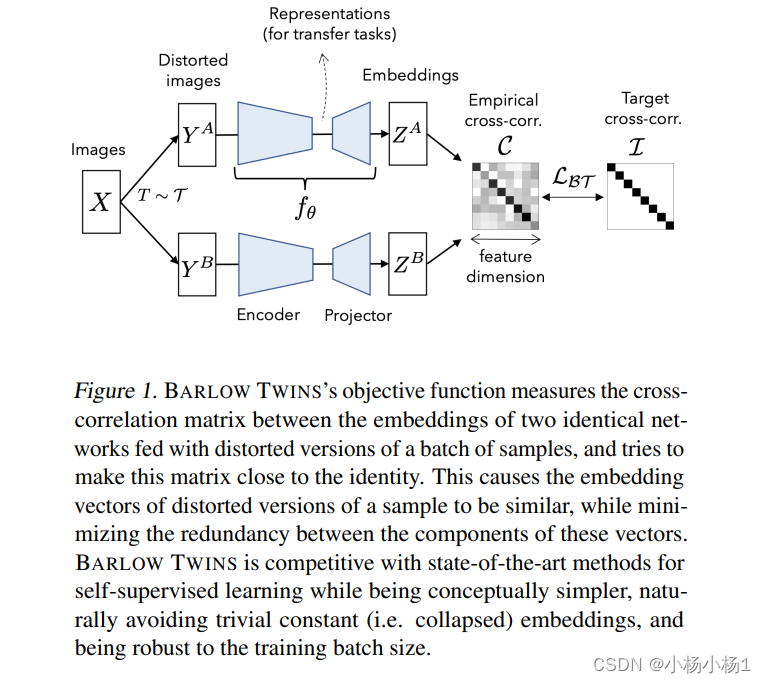
其实是比较简单的,就是同一个图像的不同变换经过相同网络的结果的损失
Emerging Properties in Self-Supervised Vision Transformers(2021)
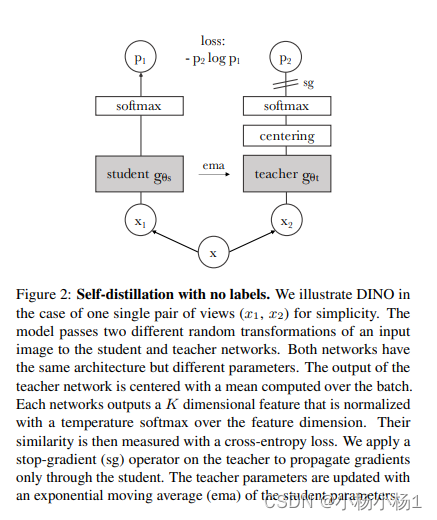

经过不同增强版本,然后平均教师网络计算损失
MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE,AND MOBILE-FRIENDLY VISION TRANSFORMER(2022)
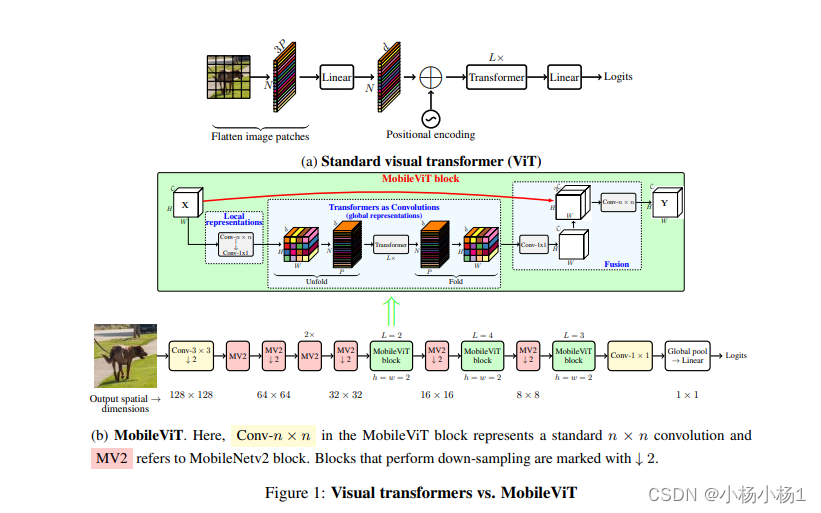
相当于是加入卷积减少参数量
Supervised Contrastive Learning(2020)

大概就是,自监督的对比学习把另一个狗也当成了负例,有监督的解决了这个问题
RepVGG: Making VGG-style ConvNets Great Again(2021)
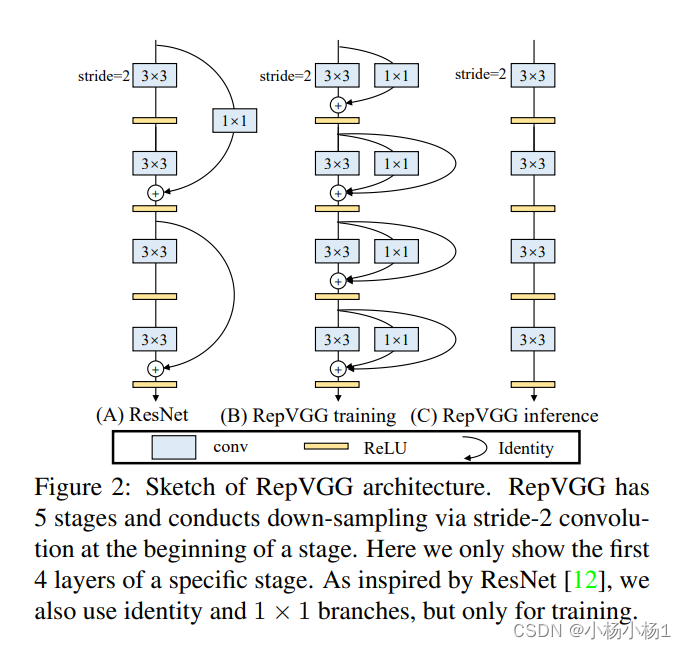
看网络就知道了
Pay Attention to MLPs(2021)
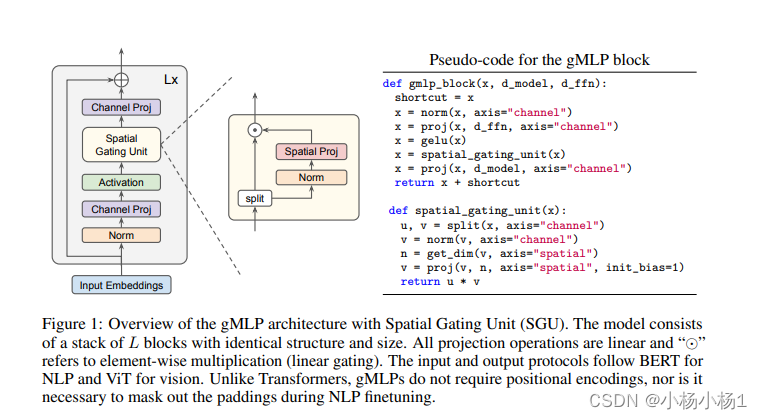
有点像MLP-mixer的思想
Dual Path Networks(2017)

不知道是不是基于通道划分的两个分支
Visual Attention Network(2022)
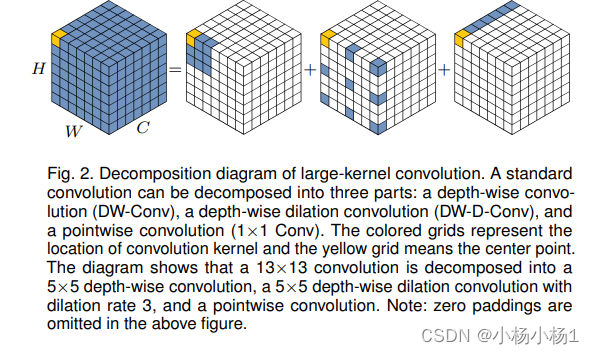
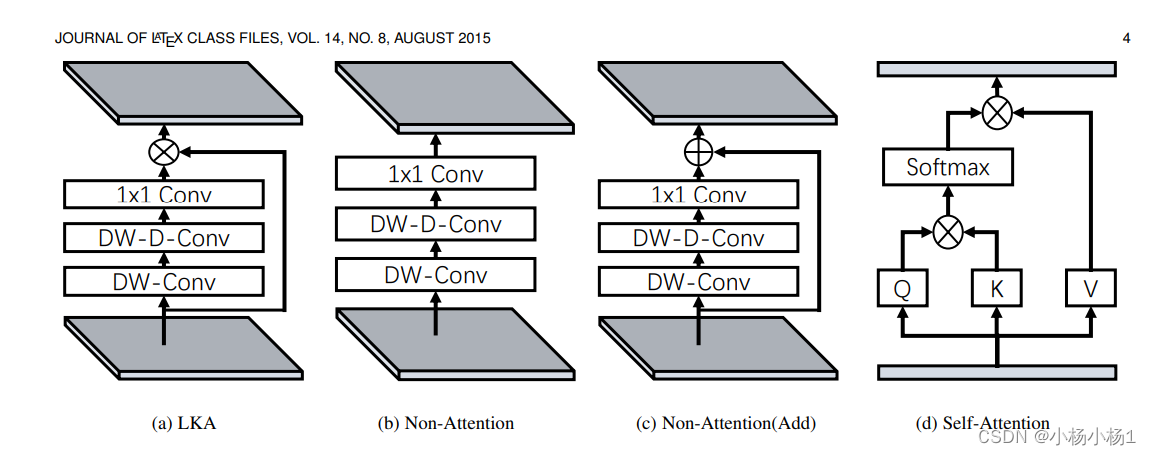
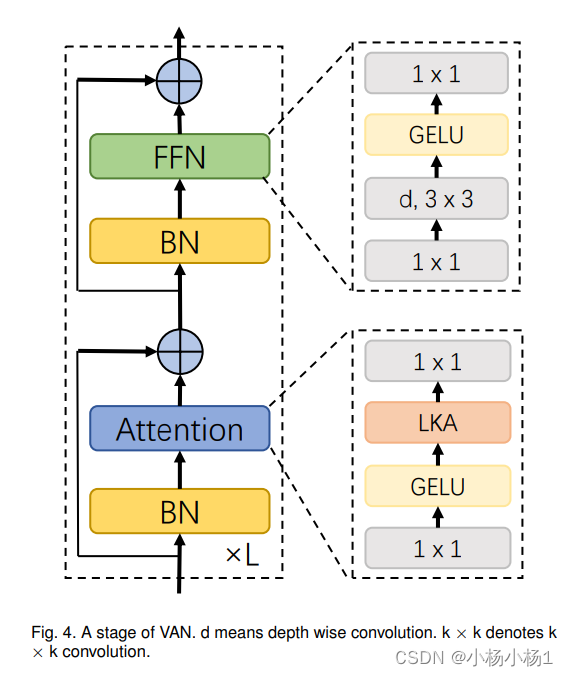
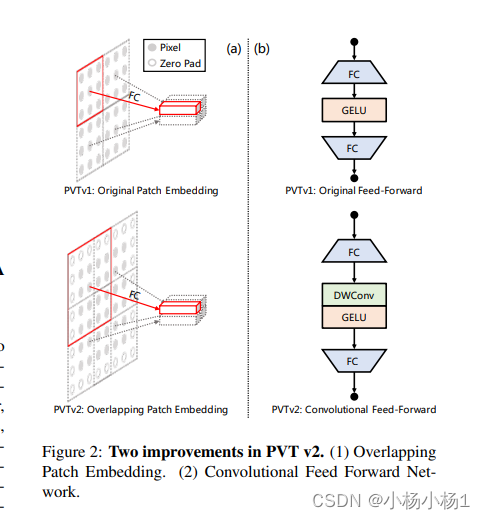
PVT v2: Improved Baselines with Pyramid Vision Transformer(2021)
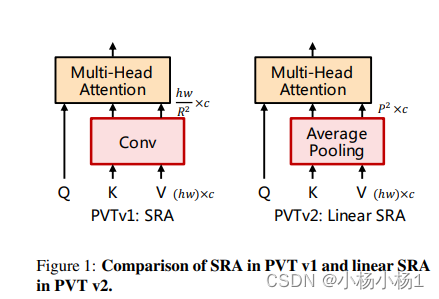
Swin Transformer V2: Scaling Up Capacity and Resolution
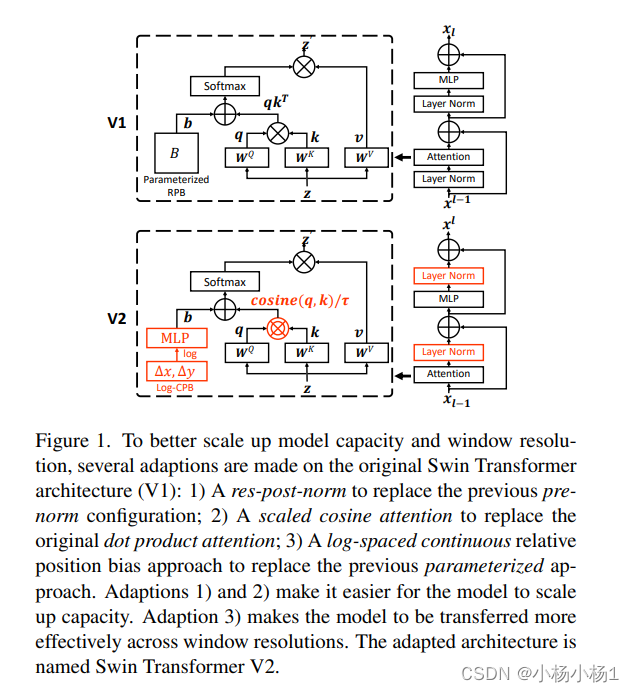
就是qkv的计算方式变了一下
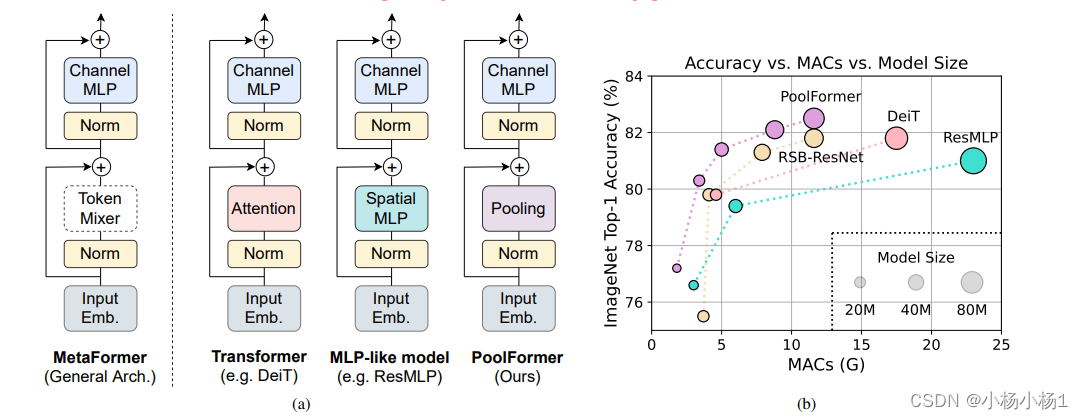
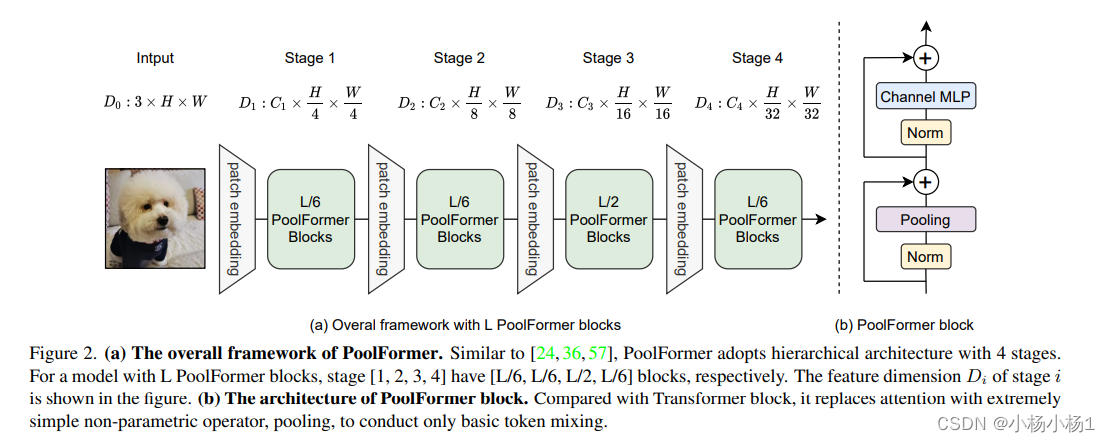
MetaFormer Is Actually What You Need for Vision(2022)
CvT: Introducing Convolutions to Vision Transformers(2021)
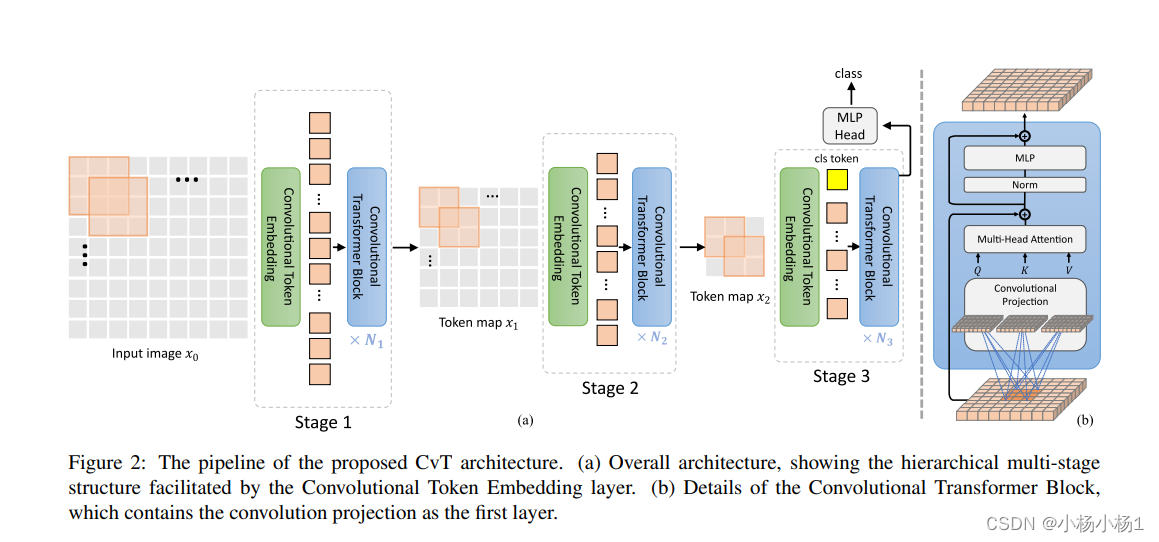
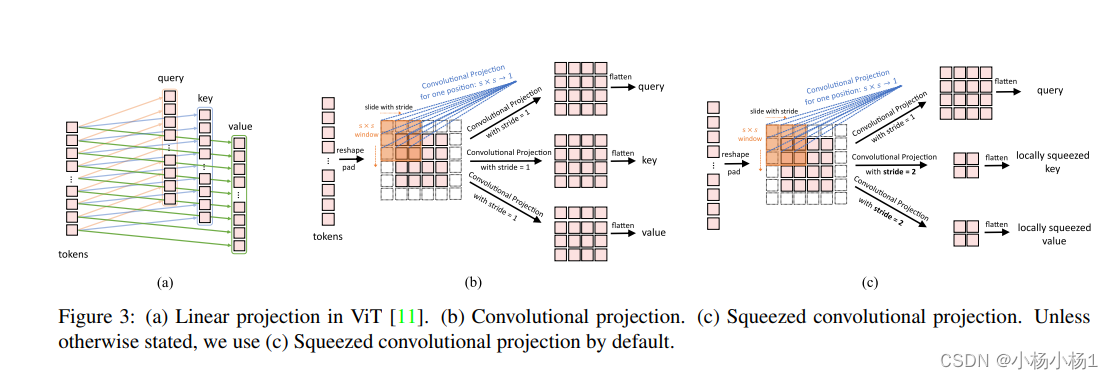
有的使用MLP生成token,有的利用卷积,利用卷积要注意维度变换