什么是MVVM呢?
口通常我们学习一个概念,最好的方式是去看维基百科(对,千万别看成了百度百科)https://zh.wikipedia.org/wiki/MVVM
View层:
视图层
>在我们前端开发中,通常就是DOM层
> 主要的作用是给用户展示各种信息。
Model层:
t>数据层
数据可能是我们固定的死数据,更多的是来自我们服务
器,从网络上请求下来的数据。在我们计数器的案例中,就是后面抽取出来的obj,当Y然,里面的数据可能没有这么简单。
VueModel层:
> 视图模型层
视图模型层是View和Model沟通的桥梁。
一方面它实现了Data Binding,也就是数据绑定,将
Model的改变实时的反应到View中另一方面它实现了DOM Listener,也就是DOM监听,当DOM发生一些事件(点击、滚动、touch等)时,可以监听到,并在需要的情况下改变对应的Data。
DOM树流程:
下载HTML-CSS-JS,下载完之后开始做解析,最主要是解析html和css代码,js代码由js引擎来进行解析,js引擎会帮助我们转成对应的CPU机器代码。js引擎:由Parse解析转成AST抽象语法树-再由Ianation解释器转换成ByteCode(字节码),之后转成对应的CPU代码。里面还有一个TurboFan编译器,可以将字节码编译为CPU可以直接执行的机器码。
V8引擎的架构:
V8引擎本身的源码非常复杂,大概有超过100w行C++代码,通过了解它的架构,我们可以知道它是如何对JavaScript执行的Parse模块会将JavaScript代码转换成AST(抽象语法树)这是因为解释器并不直接认识JavaScript代码;口如果函数没有被调用,那么是不会被转换成AST的
口 Parse的V8官方文档:https://8.dev/blog/scanner
Ignition是一个解释器,会将AST转换成ByteCode(字节码)
口 同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);
口如果函数只调用一次,Ignition会执行解释执行ByteCode;
Inition的V8官方文档:https://v8.dev/blog/ignition-interpreter
TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码:
口 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能口但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是,之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码number类型,后来执行变成了string类型)口 TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit

V8执行的细节
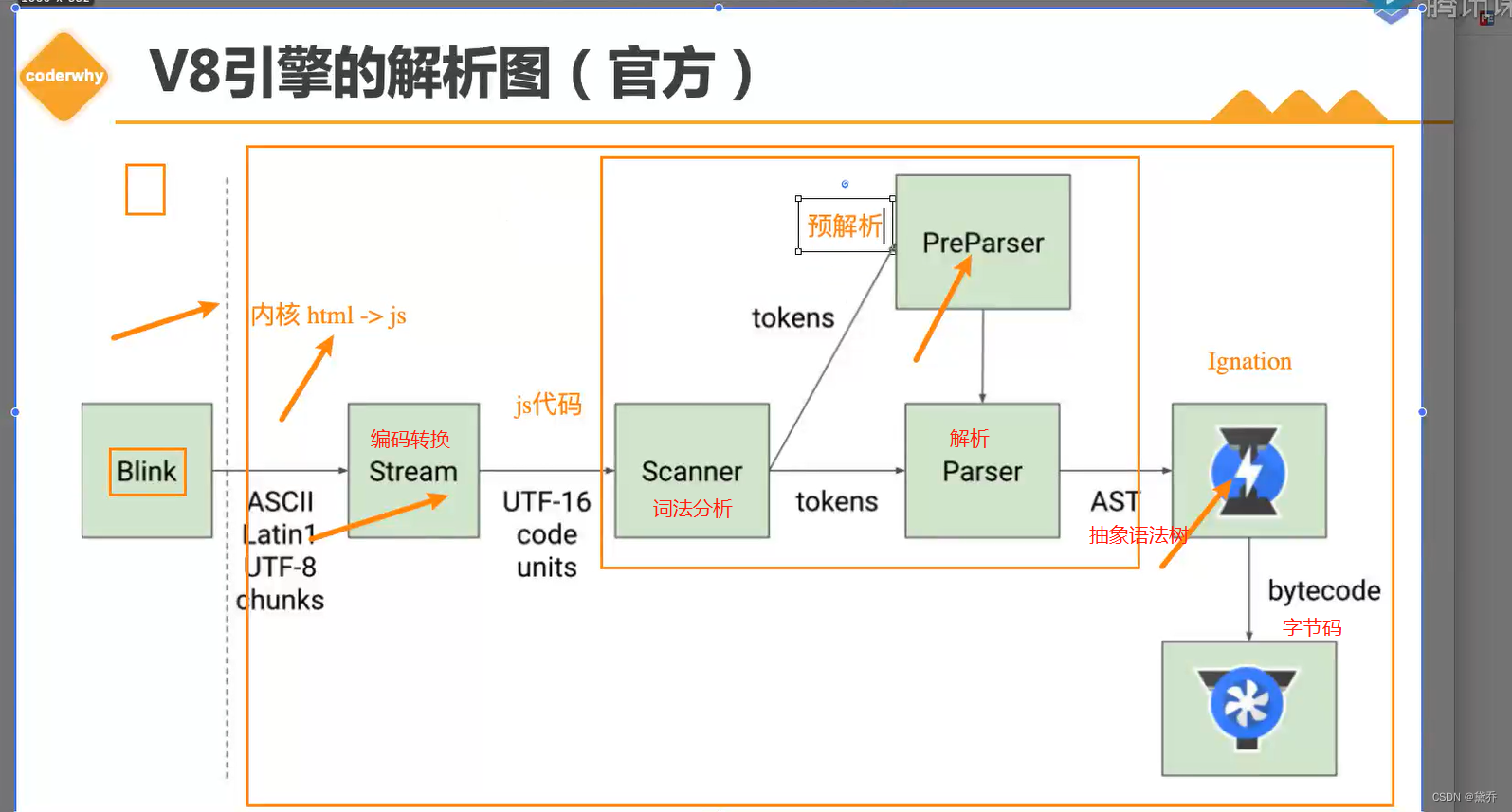
那么我们的JavaScript源码是如何被解析(Parse过程)的呢?
Blink将源码交给V8引擎,Stream获取到源码并且进行编码转换Scanner会进行词法分析(lexicalanalysis),词法分析会将代码转换成tokens;接下来tokens会被转换成AST树,经过Parser和PreParser:
口Parser就是直接将tokens转成AST树架构
口PreParser称之为预解析,为什么需要预解析呢?
√这是因为并不是所有的JavaScript代码,在一开始时就会被执行。那么对所有的JavaScript代码进行解析,必然会影响网页的运行效率;
√所以V8引就实现了Lazy Parsing(延解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析暂时需要的内容,而对函数的全量解析是在函数被调用时才会进行;
比如我们在一个函数outer内部定义了另外一个函数inner,那么inner函数就会进行预解析生成AST树后,会被Ignition转成字节码( bytecode ),之后的过程就是代码的执行过程(后续会详细分析).
感兴趣想学习的可以去关注coderwhy老师,讲课非常细致噢~