nginx(四) nginx+keepalived 实现主备+双主热备模型的高可用负载均衡代理服务
在前面《nginx配置:反向代理 负载均衡 后端健康检查 缓存》等几篇文章中,我们配置了nginx的反向代理负载均衡WEB集群,而在《keepalived 及 keepalived配置LVS高可用集群》进行keepalived配置LVS高可用集群。下面将在前文的一些基础上,用keepalived分别实现主备模型和双主模型的nginx反向代理服务器的高可用。
1、配置环境准备
1-1、模拟环境
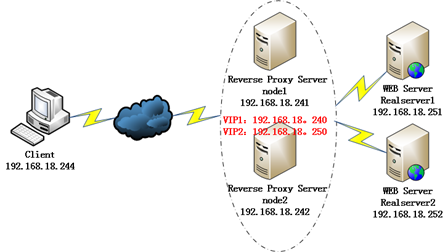
1、各服务器主机系统:CentOS 6.4 x86_64
2、反向代理服务器:
node1: IP:192.168.18.241 (host name:node1.tjiyu.com);
node2: IP:192.168.18.242 (host name:node2.tjiyu.com);
VIP1:192.168.18.240;(主备模型只使用VIP1)
VIP2:192.168.18.250;
service:nginx 1.10.2 提供反向代理、负载均衡服务;
keepalived 为nginx(VIP)提供高可用服务;
3、后端两台realserver:
realserver1: IP:192.168.18.251 (host name:realserver1.tjiyu,com);
realserver2: IP:192.168.18.252 (host name:realserver2.tjiyu.com);
service:nginx 1.10.2 提供WEB服务
1-2、配置前所需要的准备
各主机需要做以下准备:
1、配置IP、关闭防火墙/SELINUX;
2、时间同步;
3、配置节点名称(不是必须的,最好配置上,方便操作)
在前面《heartbeat v2 haresource 配置可用集群》说到的高可用集群已有详细介绍,这里就不再给出了。
2、nginx和keepalived相关准备说明
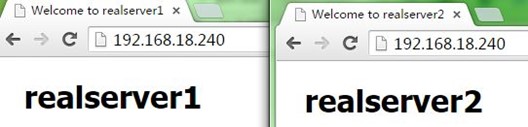
nginx可以参考《nginx配置:反向代理 负载均衡 后端健康检查 缓存》文章,先在配置好两台代理服务器,使得它们都可以实现反向代理和负载均衡(注意。不用配置缓存,影响测试),分别访问它们的IP测试正常,如下:
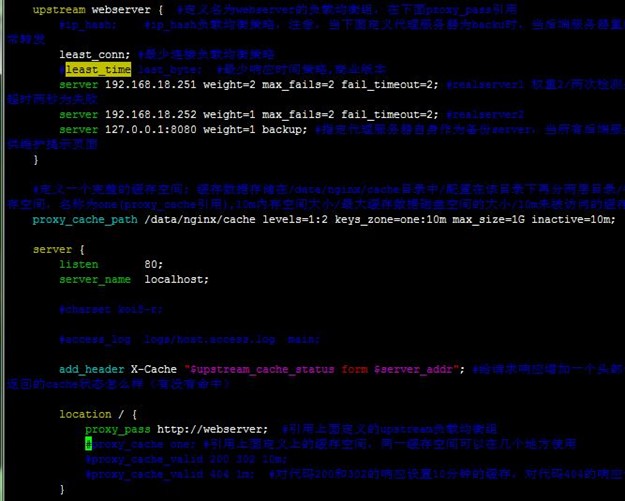
Nginx根据前文配置好后,下面就不会去配置nginx了,主要是对keepalived进行配置,以及相关测试。
Keepalived相关的原理、配置说明,可以参考《keepalived 及 keepalived配置LVS高可用集群》;首先需要在两台代理服务器分别下载安装,yum install -y keepalived就可以了。下面我们用到它里面的一些配置,不过会重新给出并作出说明。
3、配置nginx+keepalived主备模型
我们先来说明配置的一些细节,后面再给出完整的配置文件。一个是对nignx状态进行监测,一个是对nginx进行管理。
3-1、配置keepalived对nignx进行监测
配置/etc/keepalived/keepalived.conf文件使得keepalived可以对nignx进行监测,如下:
- [root@node1 ~]# cd /etc/keepalived/
- [root@node1 keepalived]# cp keepalived.conf keepalived.conf.bak
- [root@node1 keepalived]# vim keepalived.conf
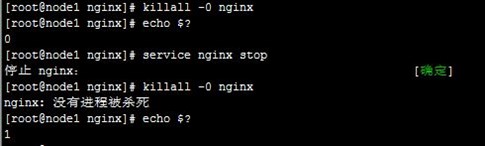
在配置文中增加vrrp_script chk_nginx_health { script "killall -0 nginx"… }块,定义nginx服务状态跟踪脚本,脚本中可以检查nginx的状态,如下:

这里我们直接用"killall -0 nginx"命令,它不会杀死nginx,只会在nginx启动正常时返回0,停止时返回1,如下:
然后在vrrp_instance VI_1 {track_script {… }}中调用上面定义的服务状态跟踪脚本,如下:

3-2、配置keepalived状态转换通知,以及转换时对nignx进行管理
自定义keepalived状态转换状态变化脚本notify.sh,放到/etc/keepalived目录下,如下:
该脚本可以在keepalived状态转换时,发出邮件通知;还可以对nginx服务进行管理,如keepalived成功主节点时,启动nginx,成为备节点时停止nginx(主备时)或重启nginx(双主时),配置到vrrp_instance VI_1 {}块中,如下:

注意,配置的发件人用户得是系统用户,不存在用户发不出邮件,得先在两节点上添加用户,过程如下:
- [root@node1 keepalived]# useradd root_keepalived
3-3、node1上的keepalived配置
配置node1成主节点,优先级较高(抢占式),配置如下:
- ! Configuration File for keepalived
- global_defs { #全局配置,这里额外的静态路由并未添加因为它是非必要的,除非我们在当前或特定的主机上生成特殊的静态路由等
- notification_email { #realserver故障时通知邮件的收件人地址,可以多个
- root@localhost
- }
- notification_email_from root_keepalived #发件人信息(可以随意伪装,因为邮件系统不会验证处理发件人信息)
- smtp_server 127.0.0.1 #发邮件的服务器(一定不可为外部地址)
- smtp_connect_timeout 30 #连接超时时间
- router_id LVS_DEVEL #路由器的标识(可以随便改动)
- }
- vrrp_script chk_nginx_health { # 定义服务状态跟踪脚本,脚本中可以检查高可用服务的状态,返回状态码0表示服务正常;配置调用则在vrrp_instance中的track_script段;这里chk_nginx是定义脚本的名称,可随意取
- script "killall -0 nginx" #判断命令/自己定义好的脚本路径;#这里killall -0 nginx不会杀死nginx,只会在nginx启动正常时返回0,停止时返回1,返回1就会在vrrp实例定义的优先级减去下面的weight值,就表示期望这个节点为备用状态。
- interval 1 #每隔1秒钟执行一次
- weight -2 #上面的命令脚本执行失败,优先级降低2;这个值的绝对值必须大于MASTER减BACKUP定义的优先级
- fall 2 #命令/脚本执行失败多少次才算真的失败
- rise 1 #命令/脚本执行成功多少次才算真的成功
- }
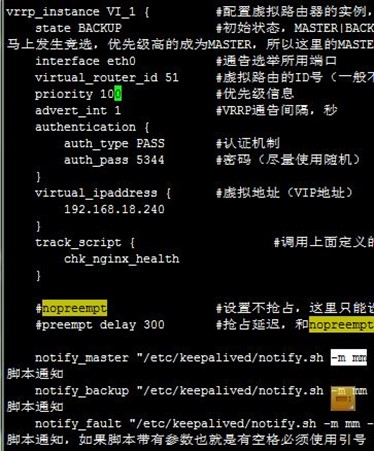
- vrrp_instance VI_1 { #配置虚拟路由器的实例,VI_1是自定义的实例名称
- state MASTER #初始状态,MASTER|BACKUP,当state指定的instance的初始化状态,在两台服务器都启动以后,马上发生竞选,优先级高的成为MASTER,所以这里的MASTER并不是表示此台服务器一直是MASTER
- interface eth0 #通告选举所用端口
- virtual_router_id 51 #虚拟路由的ID号(一般不可大于255)
- priority 101 #优先级信息 #备必须更低
- advert_int 1 #VRRP通告间隔,秒
- authentication {
- auth_type PASS #认证机制
- auth_pass 5344 #密码(尽量使用随机)
- }
- virtual_ipaddress { #虚拟地址(VIP地址)
- 192.168.18.240
- }
- track_script { #调用上面定义的服务状态跟踪脚本
- chk_nginx_health
- }
- #nopreempt #设置不抢占,这里只能设置在state为BACKUP的节点上,而且这个节点的优先级必须别另外的高
- #preempt delay 300 #抢占延迟,和nopreempt一样只能用在BACKUP上,但不能和nopreempt同时使用
- notify_master "/etc/keepalived/notify.sh -m mb -n master -s nginx -a 192.168.18.240" #转换为master状态时使用此脚本通知
- notify_backup "/etc/keepalived/notify.sh -m mb -n backup -s nginx -a 192.168.18.240" #转换为backup状态时使用此脚本通知
- notify_fault "/etc/keepalived/notify.sh -m mb -n fault -s nginx -a 192.168.18.240" #转换为fault状态时使用此脚本通知,如果脚本带有参数也就是有空格必须使用引号
- }
3-4、node2上的keepalived配置
配置node2成为备节点,和node1h配置主要差别有两处,一是state BACKUP,二是priority 100优先级更低,这是在抢占模式下的配置,后面我们再说非抢占式配置,差别不大,本配置如下:
- ! Configuration File for keepalived
- global_defs { #全局配置,这里额外的静态路由并未添加因为它是非必要的,除非我们在当前或特定的主机上生成特殊的静态路由等
- notification_email { #realserver故障时通知邮件的收件人地址,可以多个
- root@localhost
- }
- notification_email_from root_keepalived #发件人信息(可以随意伪装,因为邮件系统不会验证处理发件人信息)
- smtp_server 127.0.0.1 #发邮件的服务器(一定不可为外部地址)
- smtp_connect_timeout 30 #连接超时时间
- router_id LVS_DEVEL #路由器的标识(可以随便改动)
- }
- vrrp_script chk_nginx_health { # 定义服务状态跟踪脚本,脚本中可以检查高可用服务的状态,返回状态码0表示服务正常;配置调用则在vrrp_instance中的track_script段;这里chk_nginx是定义脚本的名称,可随意取
- script "killall -0 nginx" #判断命令/自己定义好的脚本路径;#这里killall -0 nginx不会杀死nginx,只会在nginx启动正常时返回0,停止时返回1,返回1就会在vrrp实例定义的优先级减去下面的weight值,就表示期望这个节点为备用状态。
- interval 1 #每隔1秒钟执行一次
- weight -2 #上面的命令脚本执行失败,优先级降低2;这个值的绝对值必须大于MASTER减BACKUP定义的优先级
- fall 2 #命令/脚本执行失败多少次才算真的失败
- rise 1 #命令/脚本执行成功多少次才算真的成功
- }
- vrrp_instance VI_1 { #配置虚拟路由器的实例,VI_1是自定义的实例名称
- state BACKUP #初始状态,MASTER|BACKUP,当state指定的instance的初始化状态,在两台服务器都启动以后,马上发生竞选,优先级高的成为MASTER,所以这里的MASTER并不是表示此台服务器一直是MASTER
- interface eth0 #通告选举所用端口
- virtual_router_id 51 #虚拟路由的ID号(一般不可大于255)
- priority 100 #优先级信息 #备必须更低
- advert_int 1 #VRRP通告间隔,秒
- authentication {
- auth_type PASS #认证机制
- auth_pass 5344 #密码(尽量使用随机)
- }
- virtual_ipaddress { #虚拟地址(VIP地址)
- 192.168.18.240
- }
- track_script { #调用上面定义的服务状态跟踪脚本
- chk_nginx_health
- }
- #nopreempt #设置不抢占,这里只能设置在state为BACKUP的节点上,而且这个节点的优先级必须别另外的高
- #preempt delay 300 #抢占延迟,和nopreempt一样只能用在BACKUP上,但不能和nopreempt同时使用
- notify_master "/etc/keepalived/notify.sh -m mb -n master -s nginx -a 192.168.18.240" #转换为master状态时使用此脚本通知
- notify_backup "/etc/keepalived/notify.sh -m mb -n backup -s nginx -a 192.168.18.240" #转换为backup状态时使用此脚本通知
- notify_fault "/etc/keepalived/notify.sh -m mb -n fault -s nginx -a 192.168.18.240" #转换为fault状态时使用此脚本通知,如果脚本带有参数也就是有空格必须使用引号
- }
3-5、状态转换通知脚本notify.sh
前面我们说过,自定义keepalived状态转换状态变化脚本notify.sh,放到/etc/keepalived目录下,如下:
- #!/bin/bash
- # description: An example of notify script
- # Usage: notify.sh -m|--mode {mm|mb} -s|--service SERVICE1,... -a|--address VIP -n|--notify {master|backup|falut} -h|--help
- contact='root@localhost'
- helpflag=0
- serviceflag=0
- modeflag=0
- addressflag=0
- notifyflag=0
- Usage() {
- echo "Usage: notify.sh [-m|--mode {mm|mb}] [-s|--service SERVICE1,...] <-a|--address VIP> <-n|--notify {master|backup|falut}>"
- echo "Usage: notify.sh -h|--help"
- }
- ParseOptions() {
- local I=1;
- if [ $# -gt 0 ]; then
- while [ $I -le $# ]; do
- case $1 in
- -s|--service)
- [ $# -lt 2 ] && return 3
- serviceflag=1
- services=(`echo $2|awk -F"," '{for(i=1;i<=NF;i++) print $i}'`)
- shift 2 ;;
- -h|--help)
- helpflag=1
- return 0
- shift
- ;;
- -a|--address)
- [ $# -lt 2 ] && return 3
- addressflag=1
- vip=$2
- shift 2
- ;;
- -m|--mode)
- [ $# -lt 2 ] && return 3
- mode=$2
- shift 2
- ;;
- -n|--notify)
- [ $# -lt 2 ] && return 3
- notifyflag=1
- notify=$2
- shift 2
- ;;
- *)
- echo "Wrong options..."
- Usage
- return 7
- ;;
- esac
- done
- return 0
- fi
- }
- #workspace=$(dirname $0)
- RestartService() {
- if [ ${#@} -gt 0 ]; then
- for I in $@; do
- if [ -x /etc/rc.d/init.d/$I ]; then
- /etc/rc.d/init.d/$I restart
- else
- echo "$I is not a valid service..."
- fi
- done
- fi
- }
- StopService() {
- if [ ${#@} -gt 0 ]; then
- for I in $@; do
- if [ -x /etc/rc.d/init.d/$I ]; then
- /etc/rc.d/init.d/$I stop
- else
- echo "$I is not a valid service..."
- fi
- done
- fi
- }
- Notify() {
- mailsubject="`hostname` to be $1: $vip floating"
- mailbody="`date '+%F %H:%M:%S'`, vrrp transition, `hostname` changed to be $1."
- echo $mailbody | mail -s "$mailsubject" $contact
- }
- # Main Function
- ParseOptions $@
- [ $? -ne 0 ] && Usage && exit 5
- [ $helpflag -eq 1 ] && Usage && exit 0
- if [ $addressflag -ne 1 -o $notifyflag -ne 1 ]; then
- Usage
- exit 2
- fi
- mode=${mode:-mb}
- case $notify in
- 'master')
- if [ $serviceflag -eq 1 ]; then
- RestartService ${services[*]}
- fi
- Notify master
- ;;
- 'backup')
- if [ $serviceflag -eq 1 ]; then
- if [ "$mode" == 'mb' ]; then
- StopService ${services[*]}
- else
- RestartService ${services[*]}
- fi
- fi
- Notify backup
- ;;
- 'fault')
- Notify fault
- ;;
- *)
- Usage
- exit 4
- ;;
- esac
- exit 0
4、测试主备模型
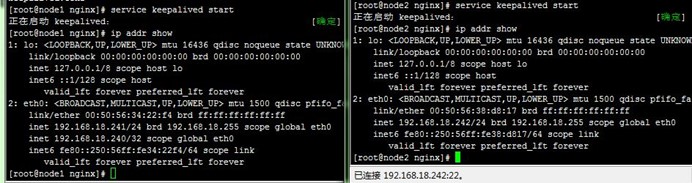
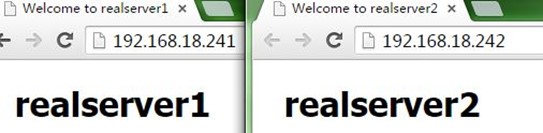
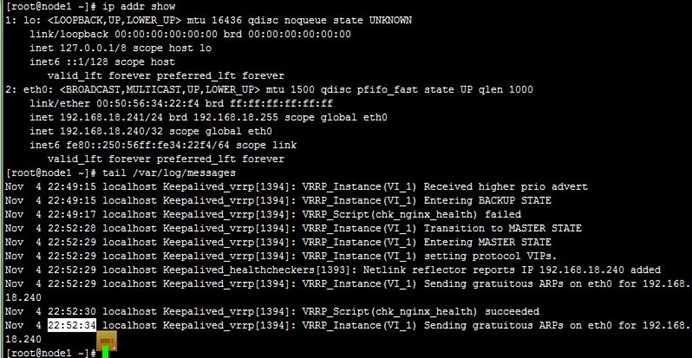
1、在node1和node2上分别启动keepalived,可以看到VIP配置到了node1上,成为了主节点,而访问测试也正常,如下:
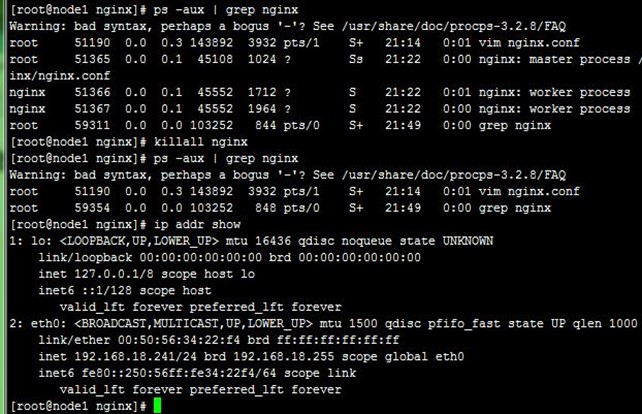
2、当我们killall nginx停止node1上的nginx时,可以看到VIP流转到node2上,即node2成为主节点,而访问正常,如下:
3、而接着当我们killall nginx停止node2的nginx时,可以看到VIP流转回了node1,也即node1重新成为主节点,而访问也正常;注意,我们并没有手动启动node1上前面kil掉的nginx,这是由notify.sh在node1成功主节点时完成的,如下:
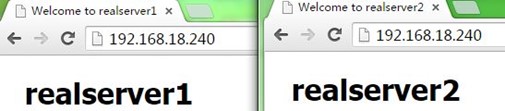
4、当我们killall keepalived停止node1上的keepalived时,可以VIP再次流转到node2,也即node2再次成为主节点,而访问也正常;注意,我们查看node1上的日志可以看到node1上的VIP被移除了,如下:
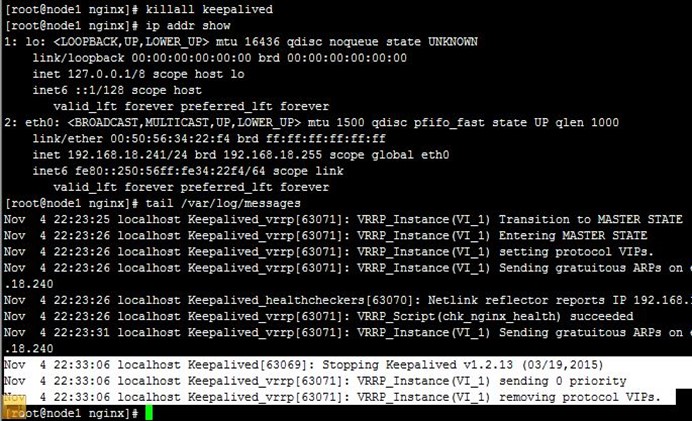
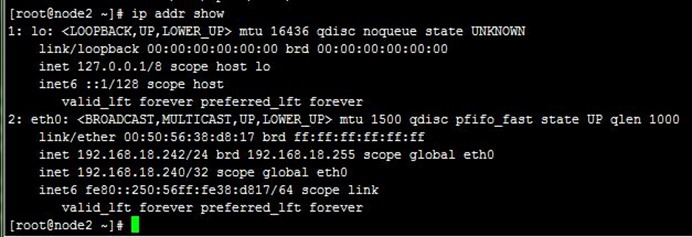
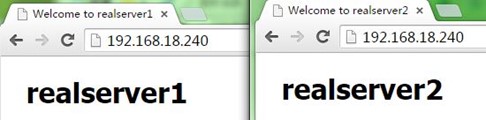
5、接着,我们重启node1上的keepalived,发现VIP流转回node1,即node1成为了主节点,而之前node2作为主节点在正常运行的,这就是抢占式了,node1配置优先级高,恢复正常后抢占了node2的主节点资源,如下:
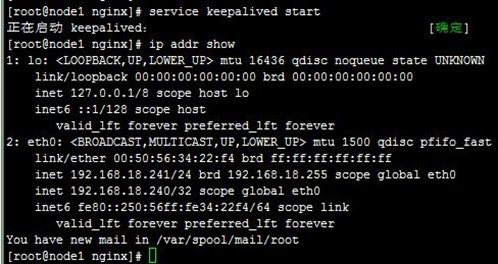
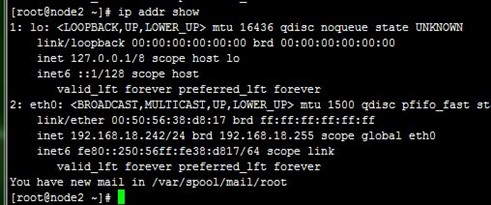
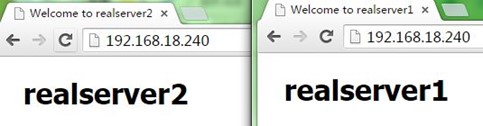
6、配置非抢占式:在配置BACKUP的node2上配置,nopreempt并且优先级比MASTER的node1高,而后我们重启node2上的keepalived,然后停止node1上的keepalived,再次使node2成为主节点,如下:

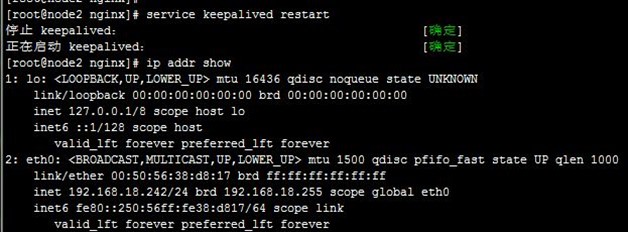
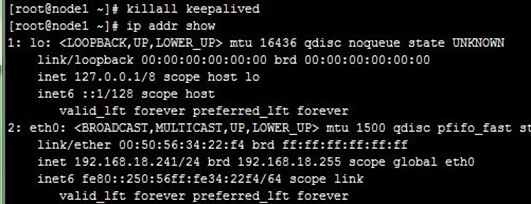
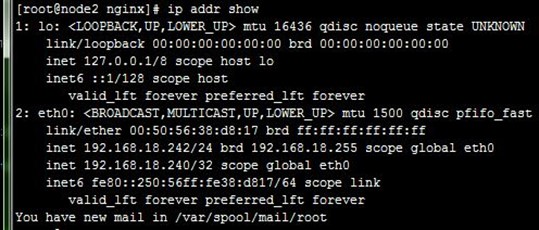
7、接着,如上面第5步,重启node1上的keepalived,VIP依然在node2,即node2还作为主节点在正常运行,这就是非抢占式,如下:
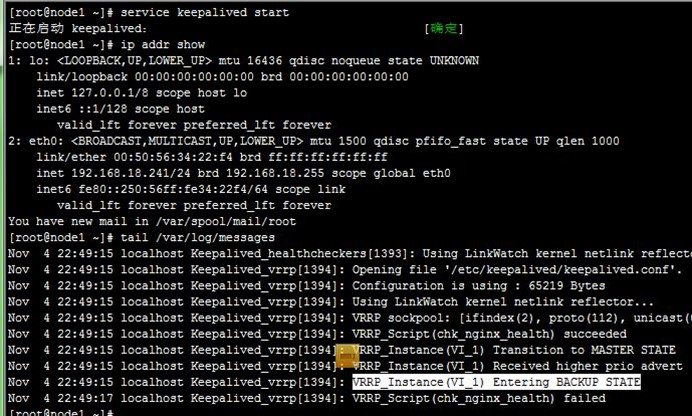
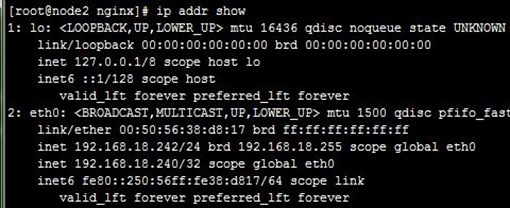
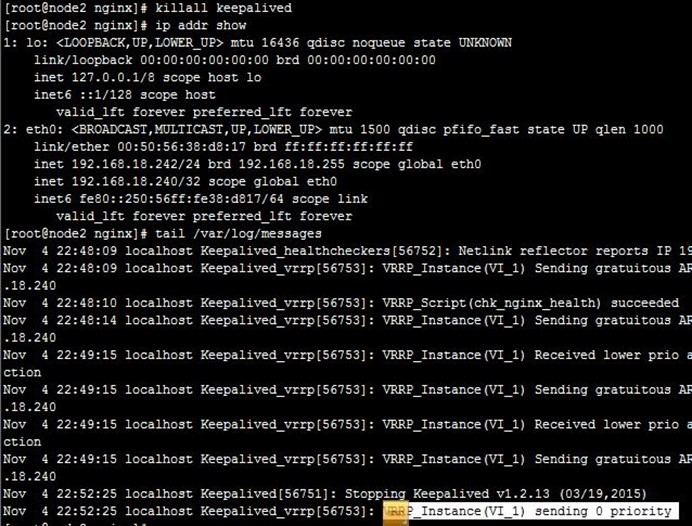
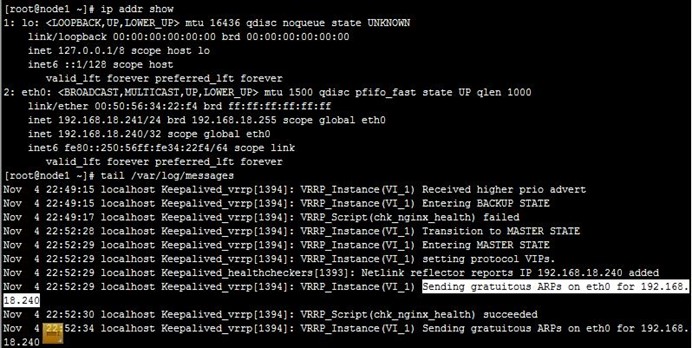
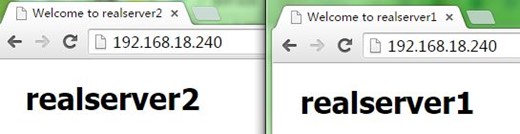
8、接着,我们停止node2上的keepalived,可以看到node1成为主节点,但VIP在node1、node2上都有,即node2没有撤除VIP,keepalived就停止了,不过这也没关,因为node1配置VIP时会自己自动发出ARP,这样报文就能转到node1了,如下:
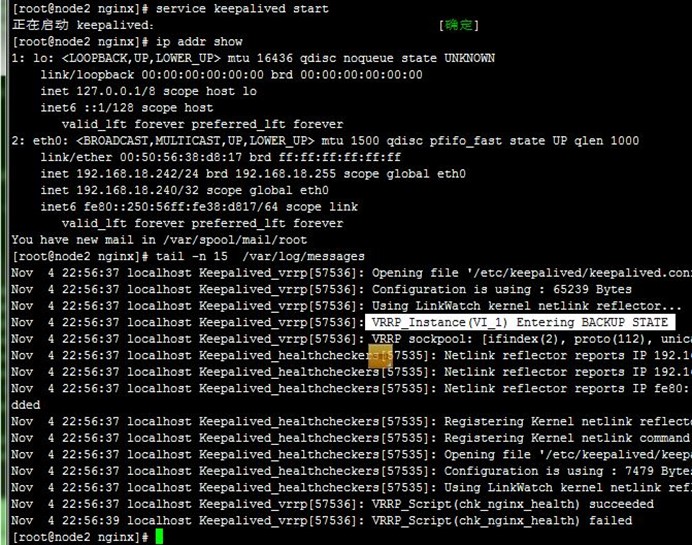
9、接着,我们重启node2上的keepalived,可以看到node2成为备节点,node1依然还是主节点,也没有被抢占,如下:
5、配置nginx+keepalived双主模型
我们在《keepalived 及 keepalived配置LVS高可用集群》中说过,Keepalived工作模型总是一主多备的,而这个双主是指两个VIP分别对应两个VRRP实例(也就是两个主备同时运行),如果两个VIP对应同一个服务,可以在前面再加DNS轮循,对就两条DNS的A记录,这样可以做到scale out 横向扩展,并且充分利用资源。
注意,双主最好不要配置非抢占模式,因为一台故障时另一台运行两个VIP,当恢复时需要把一个VIP抢占流转回来,这样就才能平分流量。
5-1、修改主备配置
我们就在上面主备模型的基础上,增加一个VRRP实例对就VIP2(192.168.18.250),但需要稍微修改前面配置,如记录得改回node2上的抢占模式,还有状态转换通知的脚本配置改"-m mm",如下:
5-2、node1上增加的配置
直接在配置文件后面加上加一个VRRP实例配置,这个实例node1为备节点,如下:
- vrrp_instance VI_2 { #配置虚拟路由器的实例,VI_1是自定义的实例名称
- state BACKUP #初始状态,MASTER|BACKUP,当state指定的instance的初始化状态,在两台服务器都启动以后>,马上发生竞选,优先级高的成为MASTER,所以这里的MASTER并不是表示此台服务器一直是MASTER
- interface eth0 #通告选举所用端口
- virtual_router_id 55 #虚拟路由的ID号(一般不可大于255)
- priority 100 #优先级信息 #备必须更低
- advert_int 1 #VRRP通告间隔,秒
- authentication {
- auth_type PASS #认证机制
- auth_pass 6675 #密码(尽量使用随机)
- }
- virtual_ipaddress { #虚拟地址(VIP地址)
- 192.168.18.250
- }
- track_script { #调用上面定义的服务状态跟踪脚本
- chk_nginx_health
- }
- #nopreempt #设置不抢占,这里只能设置在state为BACKUP的节点上,而且这个节点的优先级必须别另外的高
- #preempt delay 300 #抢占延迟,和nopreempt一样只能用在BACKUP上,但不能和nopreempt同时使用
- notify_master "/etc/keepalived/notify.sh -m mm -n master -s nginx -a 192.168.18.250" #转换为master状态时使用
- 此脚本通知
- notify_backup "/etc/keepalived/notify.sh -m mm -n backup -s nginx -a 192.168.18.250" #转换为backup状态时使用
- 此脚本通知
- notify_fault "/etc/keepalived/notify.sh -m mm -n fault -s nginx -a 192.168.18.250" #转换为fault状态时使用>此脚本通知,如果脚本带有参数也就是有空格必须使用引号
- }
5-3、node2上增加的配置
直接在配置文件后面加上加一个VRRP实例配置,这个实例node2为主节点,如下:
- vrrp_instance VI_2 { #配置虚拟路由器的实例,VI_1是自定义的实例名称
- state MASTER #初始状态,MASTER|BACKUP,当state指定的instance的初始化状态,在两台服务器都启动以后,>马上发生竞选,优先级高的成为MASTER,所以这里的MASTER并不是表示此台服务器一直是MASTER
- interface eth0 #通告选举所用端口
- virtual_router_id 55 #虚拟路由的ID号(一般不可大于255)
- priority 101 #优先级信息 #备必须更低
- advert_int 1 #VRRP通告间隔,秒
- authentication {
- auth_type PASS #认证机制
- auth_pass 6675 #密码(尽量使用随机)
- }
- virtual_ipaddress { #虚拟地址(VIP地址)
- 192.168.18.250
- }
- track_script { #调用上面定义的服务状态跟踪脚本
- chk_nginx_health
- }
- #nopreempt #设置不抢占,这里只能设置在state为BACKUP的节点上,而且这个节点的优先级必须别另外的高
- #preempt delay 300 #抢占延迟,和nopreempt一样只能用在BACKUP上,但不能和nopreempt同时使用
- notify_master "/etc/keepalived/notify.sh -m mm -n master -s nginx -a 192.168.18.240" #转换为master状态时使用此
- 脚本通知
- notify_backup "/etc/keepalived/notify.sh -m mm -n backup -s nginx -a 192.168.18.240" #转换为backup状态时使用此
- 脚本通知
- notify_fault "/etc/keepalived/notify.sh -m mm -n fault -s nginx -a 192.168.18.240" #转换为fault状态时使用此>脚本通知,如果脚本带有参数也就是有空格必须使用引号
- }
6、测试nginx+keepalived双主模型
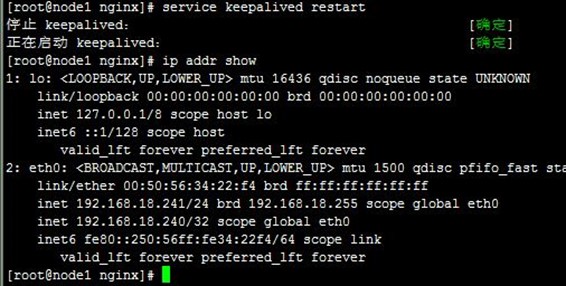
我们分别重启两个节点上keepalived,可以看到VIP1(192.168.18.240)配置到node1上,而VIP2(192.168.18.250)配置到node2上,说明node1成为VRRP实例1的主节点,node2成为VRRP实例2的主节点;而访问VIP1和VIP2都能正常,如下
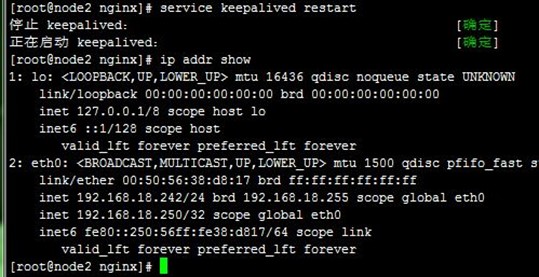
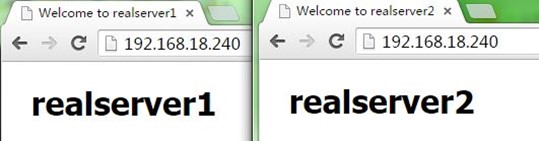
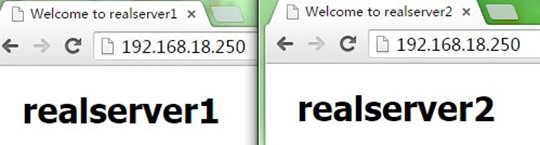
到这里,我们完成了用keepalived分别实现主备模型和双主模型的nginx反向代理负载均衡服务器的高可用,后面有时间将会在本文件的基础上进行nginx+tomcat的动静分离配置……
【参考资料】
1、nginx官网文档:http://nginx.org/en/docs/
2、keepalived官网文档:http://www.keepalived.org/documentation.html
3、keepalived 及 keepalived配置LVS高可用集群:http://blog.csdn.net/tjiyu/article/details/52891835
4、nginx详解:http://blog.csdn.net/tjiyu/article/details/53027619
5、nginx配置:反向代理 负载均衡 后端健康检查 缓存:http://blog.csdn.net/tjiyu/article/details/53028026