承接上文:Ceph分布式存储系列(二):ceph-deploy方式部署三节点ceph集群
通常情况下,因业务等一系列问题,导致集群扩容是一种常见且难以避免的事情,所以这次还是基于上一篇部署的三节点Ceph集群再来做一次新增节点扩容的试验,并加以梳理总结!
一般情况下,集群扩容分两种情况:
- 新增服务器节点进行集群扩容
- 给原有服务器新增硬盘(OSD)进行集群扩容
个人理解:其实这两种扩容方式大体上都是以增加OSD为目的的,只是如果原本的服务器没有多余的硬盘位放置新硬盘,那么就只能选择新增服务器的方式进行集群扩容。
下面就根据这两种扩容情况进行一系列测试及讲解!
新增服务器实现扩容
一、服务器准备
在集群状态OK的情况下,进行集群扩容。
这次因环境限制,新增一台服务器,也就是新增一个节点,服务器版本依旧使用Centos7.8.2003
环境信息:
| IP地址 | 主机名 | 附加磁盘(OSD) | 集群角色 |
|---|---|---|---|
| 192.168.56.125 | ceph-node1 | 一块10G磁盘(/dev/sdb) | mon,mgr,osd0(主节点) |
| 192.168.56.126 | ceph-node2 | 一块10G磁盘(/dev/sdb) | osd1 |
| 192.168.56.127 | ceph-node3 | 一块10G磁盘(/dev/sdb) | osd2 |
192.168.56.128 |
ceph-node4 |
一块5G磁盘(/dev/sdb) |
osd3 (新增节点) |
扩容节点的准备工作和整个集群部署时各节点的准备操作基本一致
一些部署准备细节提示这里就不再赘述,详细的准备工作还请看Ceph分布式存储系列(二):ceph-deploy方式部署三节点ceph集群
1、关闭防火墙和selinux(扩容节点执行)
sed -i "s/SELINUX=enforcing/SELINUX=permissive/g" /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
2、配置hosts文件(集群所有节点都需执行)
保证集群内所有主机名与ip解析正常
[root@ceph-node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.125 ceph-node1
192.168.56.126 ceph-node2
192.168.56.127 ceph-node3
192.168.56.128 ceph-node4
[ceph-admin@ceph-node1 cluster]$ ping ceph-node4
PING ceph-node4 (192.168.56.128) 56(84) bytes of data.
64 bytes from ceph-node4 (192.168.56.128): icmp_seq=1 ttl=64 time=0.475 ms
…………
3、创建部署用户及配置sudo权限
这里因集群中其他节点都已经有了部署用户,且集群在正常运行,所以只在新增节点上执行即可
$ useradd ceph-admin
$ echo "123456" | passwd --stdin ceph-admin
$ echo "ceph-admin ALL = NOPASSWD:ALL" | tee /etc/sudoers.d/ceph-admin
$ chmod 0440 /etc/sudoers.d/ceph-admin
4、配置无密码访问(在主节点node1执行)
[root@ceph-node1 ~]# su - ceph-admin
[ceph-admin@ceph-node1 ~]$ ssh-copy-id ceph-admin@ceph-node1
5、配置ntp同步(新增节点执行)
$ yum -y install ntp #安装ntp,如果已安装,那就忽略这条命令
$ vim /etc/ntp.conf
注释掉默认的server配置项:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
添加配置项:
server 192.168.56.125 #node1-ntp服务器
重启ntp服务
$ systemctl restart ntpd
$ systemctl enable ntpd
查看ntp连接情况和状态
[root@ceph-node4 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*ceph-node1 120.25.115.20 3 u 6 64 1 0.325 -173.07 0.000
6、新增节点配置yum源
a.添加阿里云的base源和epel源
备份系统原本的源
$ mkdir /mnt/repo_bak
$ mv /etc/yum.repos.d/* /mnt/repo_bak
添加新源
$ wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
$ wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
b.添加ceph的yum源
vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph
baseurl=http://download.ceph.com/rpm-nautilus/el7/x86_64
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
更新yum缓存及系统软件
yum makecache
yum -y update
二、开始扩容
1、安装Ceph包至新增节点(在主节点node1操作)
(其中 --no-adjust-repos 参数含义:使用本地配置的源,不更改源。以防出现问题)
[ceph-admin@ceph-node1 ~]$ su - ceph-admin
[ceph-admin@ceph-node1 cluster]$ cd cluster
[ceph-admin@ceph-node1 cluster]$ ceph-deploy install --no-adjust-repos ceph-node4
如果集群之前不是用ceph-deploy安装的,没有ceph-deploy命令,那么手动安装也可以
yum -y install ceph ceph-radosgw
2、使用ceph-deploy添加OSD
如果是里边有数据的磁盘,还需先清除数据:(详细可查看 ceph-depoy disk zap --help)
列出所有节点上所有可用的磁盘
[ceph-admin@ceph-node1 cluster]$ ceph-deploy disk list ceph-node4
清除数据
sudo ceph-deploy disk zap {
osd-server-name} {
disk-name}
eg:ceph-deploy disk zap ceph-node2 /dev/sdb
添加前可以查看下集群OSD状态
[ceph-admin@ceph-node1 cluster]$ ceph osd stat
3 osds: 3 up (since 22h), 3 in (since 22h); epoch: e37
如果是干净的磁盘,可忽略上边清除数据的操作,直接添加OSD即可
(我这里是新添加的/dev/sdb磁盘)
[ceph-admin@ceph-node1 cluster]$ ceph-deploy osd create --data /dev/sdb ceph-node4
执行上述添加命令后可查看OSD状态
[ceph-admin@ceph-node1 cluster]$ ceph osd stat
4 osds: 4 up (since 7s), 4 in (since 7s); epoch: e41
[ceph-admin@ceph-node1 cluster]$ ceph -s
cluster:
id: 130b5ac0-938a-4fd2-ba6f-3d37e1a4e908
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-node1 (age 45h)
mgr: ceph-node1(active, since 45h)
osd: 4 osds: 4 up (since 47s), 4 in (since 47s)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 4.0 GiB used, 31 GiB / 35 GiB avail
pgs:
新增节点查看
[root@ceph-node4 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sdb ceph-e734e119-37de-484b-861e-030f6adb8c29 lvm2 a-- <5.00g 0
[root@ceph-node4 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 487120 0 487120 0% /dev
tmpfs 497840 0 497840 0% /dev/shm
tmpfs 497840 7860 489980 2% /run
tmpfs 497840 0 497840 0% /sys/fs/cgroup
/dev/sda3 8377344 1784808 6592536 22% /
/dev/sda1 1038336 162708 875628 16% /boot
tmpfs 99572 0 99572 0% /run/user/0
tmpfs 497840 52 497788 1% /var/lib/ceph/osd/ceph-3
以上,完成了新加服务器扩容集群的操作
新增硬盘实现扩容
一、添加硬盘
默认只有重启服务器才能识别新添加硬盘,但是一般情况下我们都是在集群运行的时候去扩容集群,所以为了不影响集群,要保证服务器在开机状态下识别到新加硬盘
如何添加硬盘这个应该就不用多说了吧,直接到如何让服务器在线识别吧
识别硬盘前服务器状态:
[root@ceph-node2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
├─sda2 8:2 0 2G 0 part [SWAP]
└─sda3 8:3 0 17G 0 part /
sdb 8:16 0 10G 0 disk
└─ceph--fab2d4ae--c169--4fcf--8a71--594251496f6d-osd--block--c2613e3c--a71c--4176--a5d6--f016a1e36bd4 253:0 0 10G 0 lvm
sr0 11:0 1 1G 0 rom
执行下列命令,以此来重刷设备信息:
echo "- - -" > /sys/class/scsi_host/host0/scan
如果 /sys/class/scsi_host/ 下有多个host文件,那么每个都需要修改
可以直接执行此命令(亲测可用)
for i in `ls /sys/class/scsi_host/`; do echo "- - -" > /sys/class/scsi_host/$i/scan; done
贴一张之前的图做一下验证
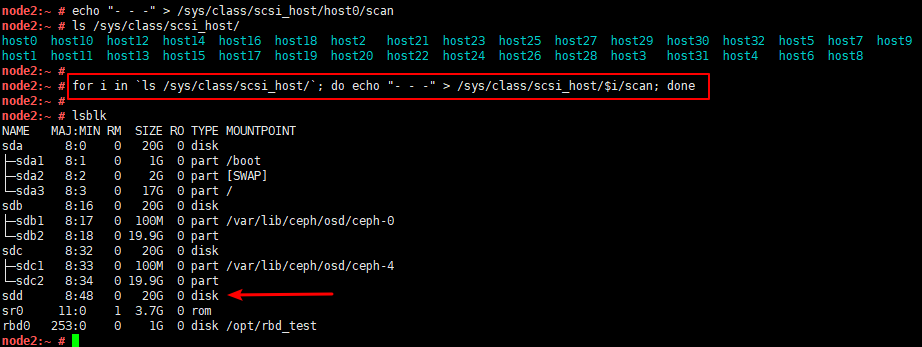
二、添加OSD至集群
其实添加OSD的方式有多种,可以手动初始化OSD去添加,也可以还是用ceph-deploy的方式去快速添加。
这里就还是以ceph-deploy为例,手动添加的方式后边会以扩展内容的方式展示。
ceph-deploy添加硬盘的方式和和上边新增节点之后的添加OSD方式也基本一样,这里就再赘述一遍吧。
主节点node1执行(安装有ceph-deploy的节点)
首先查看新增OSD所在的服务器可用磁盘(重点看最后一行输出)
[ceph-admin@ceph-node1 cluster]$ ceph-deploy disk list ceph-node2
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/ceph-admin/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy disk list ceph-node2
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : list
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fdc07b20488>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : ['ceph-node2']
[ceph_deploy.cli][INFO ] func : <function disk at 0x7fdc07d6c938>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph-node2][DEBUG ] connection detected need for sudo
[ceph-node2][DEBUG ] connected to host: ceph-node2
[ceph-node2][DEBUG ] detect platform information from remote host
[ceph-node2][DEBUG ] detect machine type
[ceph-node2][DEBUG ] find the location of an executable
[ceph-node2][INFO ] Running command: sudo fdisk -l
[ceph-node2][INFO ] Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors
[ceph-node2][INFO ] Disk /dev/sdb: 10.7 GB, 10737418240 bytes, 20971520 sectors
[ceph-node2][INFO ] Disk /dev/mapper/ceph--fab2d4ae--c169--4fcf--8a71--594251496f6d-osd--block--c2613e3c--a71c--4176--a5d6--f016a1e36bd4: 10.7 GB, 10733223936 bytes, 20963328 sectors
[ceph-node2][INFO ] Disk /dev/sdc: 5368 MB, 5368709120 bytes, 10485760 sectors
清除数据
[ceph-admin@ceph-node1 cluster]$ ceph-deploy disk zap ceph-node2 /dev/sdc
………………
[ceph-node2][WARNIN] Running command: /bin/dd if=/dev/zero of=/dev/sdc bs=1M count=10 conv=fsync
[ceph-node2][WARNIN] --> Zapping successful for: <Raw Device: /dev/sdc>
添加OSD
[ceph-admin@ceph-node1 cluster]$ ceph-deploy osd create --data /dev/sdc ceph-node2
查看集群状态
[ceph-admin@ceph-node1 cluster]$ ceph osd stat
4 osds: 4 up (since 59s), 4 in (since 59s); epoch: e59
扩展内容
一、OSD手动添加
这种一般用于不是使用ceph-deploy部署的集群中,相对来说比较繁杂,不过也浅浅的了解一下
简单归纳为下列命令
ceph osd create 创建osd id
mkfs.xfs -f /dev/sdd 格式化新加硬盘
mkdir /var/lib/ceph/osd/ceph-6/
mount /dev/sdd /var/lib/ceph/osd/ceph-6/ 创建数据存储目录及挂载
ceph-osd -i 6 --mkfs --mkkey 初始化数据
ceph auth add osd.6 mgr "allow profile osd" mon "allow profile osd" osd "allow *" -i /var/lib/ceph/osd/ceph-6/keyring 注册验证密钥
ceph osd crush add osd.6 0.01939 root=default host=node1 将新增osd添加至crush中
ceph-osd -i 6 启动
1、创建OSD-ID
主节点node1执行
这里的 create 后可以跟ID号,不过还是让集群自己给出ID号最好,避免跳过一些ID
node1:/etc # ceph osd create
7
node1:/etc # ceph osd stat
8 osds: 7 up, 7 in
2、创建数据存储目录及挂载
因为新增硬盘是在node2上边,硬盘也是要挂载在node2上,所以这里在node2上执行
node2:~ # ls /var/lib/ceph/osd/
ceph-0 ceph-4
node2:~ # mkdir /var/lib/ceph/osd/ceph-7
node2:~ # mount /dev/sdd /var/lib/ceph/osd/ceph-7/
3、初始化osd存储数据
node2:~ # ceph-osd -i 7 --mkfs --mkkey
2020-07-22 15:28:00.109102 7f23e503cd00 -1 auth: error reading file: /var/lib/ceph/osd/ceph-7/keyring: can't open /var/lib/ceph/osd/ceph-7/keyring: (2) No such file or directory
2020-07-22 15:28:00.146961 7f23e503cd00 -1 created new key in keyring /var/lib/ceph/osd/ceph-7/keyring
2020-07-22 15:28:00.284581 7f23e503cd00 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway
2020-07-22 15:28:00.352819 7f23e503cd00 -1 journal FileJournal::_open: disabling aio for non-block journal. Use journal_force_aio to force use of aio anyway
2020-07-22 15:28:00.354151 7f23e503cd00 -1 journal do_read_entry(4096): bad header magic
2020-07-22 15:28:00.354189 7f23e503cd00 -1 journal do_read_entry(4096): bad header magic
2020-07-22 15:28:00.357097 7f23e503cd00 -1 read_settings error reading settings: (2) No such file or directory
2020-07-22 15:28:00.402933 7f23e503cd00 -1 created object store /var/lib/ceph/osd/ceph-7 for osd.7 fsid e78f0997-b26d-3f1d-b235-b5f1d68fc169
命令解析:
ceph-osd -i [osd-ID]--mkfs --mkkey
参数:
- –id/-i ID set ID portion of my name(设置osd的ID号,即osd编号)
- –mkfs create a [new] data directory(创建一个新的数据目录)
- –mkkey generate a new secret key(生成一个新的密钥)
4、注册验证密钥,配置其他组件访问osd的权限
查看其他已配置osd的注册配置信息
node1:/var/lib/ceph/osd # ceph auth list
installed auth entries:
osd.0
key: AQAUpw5f3AhkAhAASxBAgXJznrQ8Cv3TgkirSg==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQAVpw5fBdo8MBAAxBm7V8n3j09wO3TedyLfJA==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
·················
根据已配置osd配置信息配置新添加的osd
根据各自环境osd配置信息添加osd即可
node2:~ # ceph auth add osd.7 mgr "allow profile osd" mon "allow profile osd" osd "allow *" -i /var/lib/ceph/osd/ceph-7/keyring
added key for osd.7
5、将新增osd添加至crush图中
node2:~ # ceph osd tree #查看osd权重(即weight值)
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.13574 root default
-7 0.05817 host node1
2 hdd 0.01939 osd.2 up 1.00000 1.00000
5 hdd 0.01939 osd.5 up 1.00000 1.00000
6 hdd 0.01939 osd.6 up 1.00000 1.00000
-3 0.03879 host node2
0 hdd 0.01939 osd.0 up 1.00000 1.00000
4 hdd 0.01939 osd.4 up 1.00000 1.00000
-5 0.03879 host node3
1 hdd 0.01939 osd.1 up 1.00000 1.00000
3 hdd 0.01939 osd.3 up 1.00000 1.00000
7 0 osd.7 down 0 1.00000
node2:~ # ceph osd crush add osd.7 0.01939 root=default host=node2
add item id 7 name 'osd.7' weight 0.01939 at location {
host=node2,root=default} to crush map
6、启动OSD
node2:~ # ceph-osd -i 7
starting osd.7 at - osd_data /var/lib/ceph/osd/ceph-7 /var/lib/ceph/osd/ceph-7/journal
node2:~ # ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.15512 root default
-7 0.05817 host node1
2 hdd 0.01939 osd.2 up 1.00000 1.00000
5 hdd 0.01939 osd.5 up 1.00000 1.00000
6 hdd 0.01938 osd.6 up 0.01939 1.00000
-3 0.05817 host node2
0 hdd 0.01939 osd.0 up 1.00000 1.00000
4 hdd 0.01939 osd.4 up 1.00000 1.00000
7 hdd 0.01938 osd.7 up 1.00000 1.00000
-5 0.03879 host node3
1 hdd 0.01939 osd.1 up 1.00000 1.00000
3 hdd 0.01939 osd.3 up 1.00000 1.00000
二、删除OSD
1:将osd down掉
ceph osd down osd.0
(这样停止的话,osd会被集群自动启动起来,所以保险起见还是在osd所在服务器将osd所属服务给停掉 systemctl stop ceph-osd@0)
2:将osd从集群中退出
ceph osd out osd.0
3:从crush中移除节点
ceph osd crush remove osd.0
4:删除节点
ceph osd rm osd.0
5:删除OSD节点认证(不删除编号会占住)
ceph auth del osd.0
6:删除crush map中对应OSD条目
ceph crush remove osd.0
这里多提一句 ceph-deploy 部署的ceph集群
osd的服务操作命令为:systemctl start/stop/status ceph-osd@3这个3代表的是OSD的ID号
ERROR处理
服务器中LVM格式的OSD遗留删除不掉,如下
[root@ceph-node4 ~]# lsblk
……
sdb
└─ceph--29357d7b--f5da--44f8--b4f7--e81d6eb4113d-osd--block--05e52761--2aa1--461b--9dd0--ac5b807f8a25 253:0 0 5G 0 lvm
……
删除lvm遗留信息
[root@ceph-node4 ~]# dmsetup ls
ceph--29357d7b--f5da--44f8--b4f7--e81d6eb4113d-osd--block--05e52761--2aa1--461b--9dd0--ac5b807f8a25 (253:0)
[root@ceph-node4 ~]# dmsetup remove ceph--29357d7b--f5da--44f8--b4f7--e81d6eb4113d-osd--block--05e52761--2aa1--461b--9dd0--ac5b807f8a25
需要格式化
[root@ceph-node4 ~]# mkfs.xfs -f /dev/sdb
meta-data=/dev/sdb isize=512 agcount=4, agsize=327680 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=1310720, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
如果不删除LVM遗留信息,则会报类似error:
RuntimeError: command returned non-zero exit status: 1
Failed to execute command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdb
GenericError: Failed to create 1 OSDs
End……