1.flink集群搭建
不废话直接上代码,都是基于官网的,在此记录一下 Kubernetes | Apache Flink
flink-configuration-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: flink-config
labels:
app: flink
data:
flink-conf.yaml: |+
jobmanager.rpc.address: flink-jobmanager
taskmanager.numberOfTaskSlots: 2
blob.server.port: 6124
jobmanager.rpc.port: 6123
taskmanager.rpc.port: 6122
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
parallelism.default: 2
log4j-console.properties: |+
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.pekko.name = org.apache.pekko
logger.pekko.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF jobmanager-service.yaml Optional service, which is only necessary for non-HA mode.
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
spec:
type: ClusterIP
ports:
- name: rpc
port: 6123
- name: blob-server
port: 6124
- name: webui
port: 8081
selector:
app: flink
component: jobmanagerSession cluster resource definitions #
jobmanager-session-deployment-non-ha.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-jobmanager
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: jobmanager
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
containers:
- name: jobmanager
image: apache/flink:latest
args: ["jobmanager"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob-server
- containerPort: 8081
name: webui
livenessProbe:
tcpSocket:
port: 6123
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.propertiestaskmanager-session-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
spec:
replicas: 2
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
containers:
- name: taskmanager
image: apache/flink:latest
args: ["taskmanager"]
ports:
- containerPort: 6122
name: rpc
livenessProbe:
tcpSocket:
port: 6122
initialDelaySeconds: 30
periodSeconds: 60
volumeMounts:
- name: flink-config-volume
mountPath: /opt/flink/conf/
securityContext:
runAsUser: 9999 # refers to user _flink_ from official flink image, change if necessary
volumes:
- name: flink-config-volume
configMap:
name: flink-config
items:
- key: flink-conf.yaml
path: flink-conf.yaml
- key: log4j-console.properties
path: log4j-console.propertieskubectl apply -f xxx.yaml 或者 kubectl apply -f ./flink flink为文件夹,存放的是以上这几个.yaml文件

为flink的ui界面添加nodeport即可外部访问
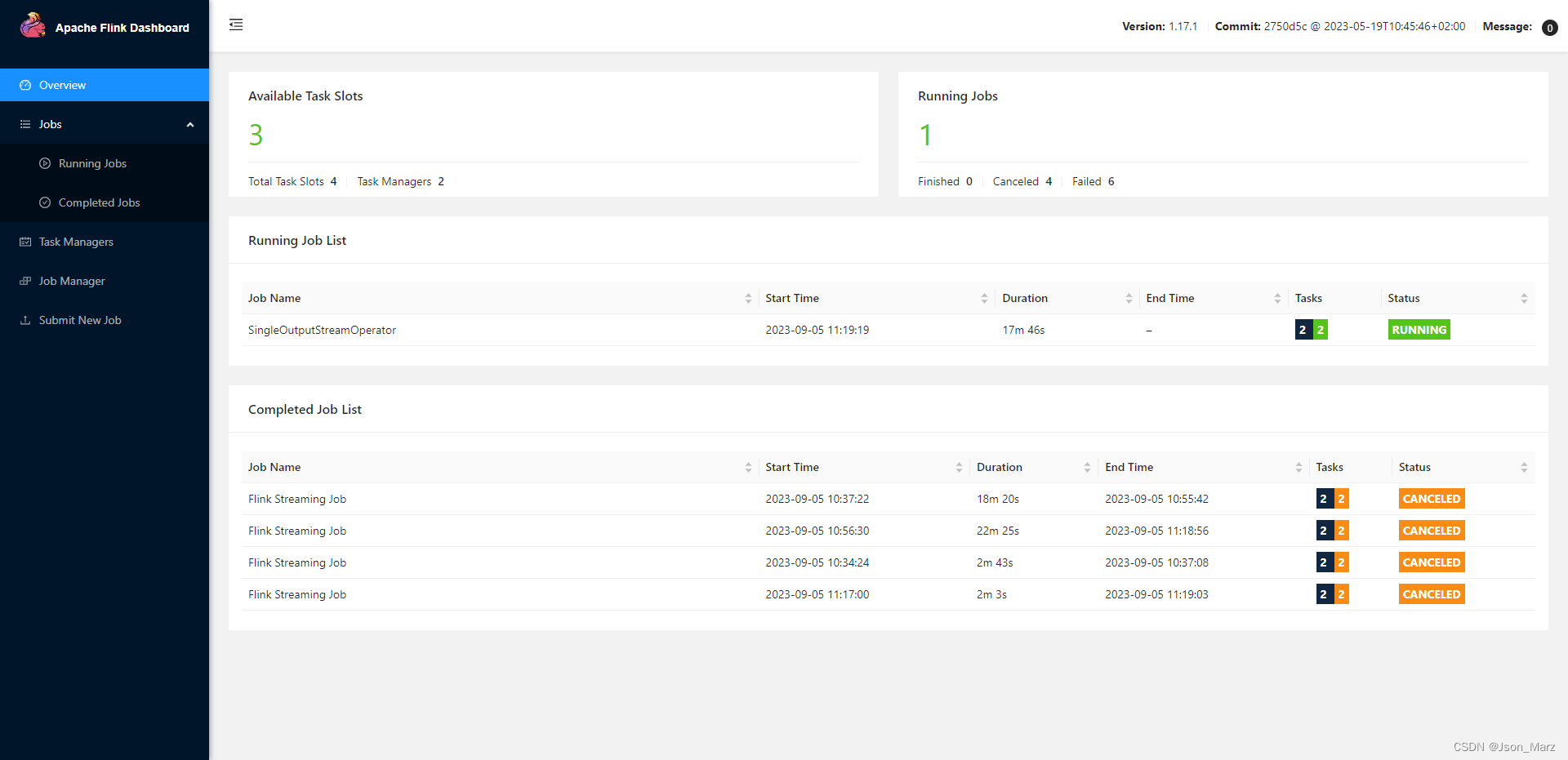
2. demo代码测试
创建一个maven工程,pom.xml引入依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>test-platform</artifactId>
<groupId>com.test</groupId>
<version>2.0.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>flink-demo</artifactId>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.17.0</flink.version>
<log4j.version>2.20.0</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<scope>compile</scope>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<scope>compile</scope>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<scope>compile</scope>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</project>log4j2.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration monitorInterval="5">
<Properties>
<property name="LOG_PATTERN" value="%date{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n" />
<!-- LOG_LEVEL 配置你需要的日志输出级别 -->
<property name="LOG_LEVEL" value="INFO" />
</Properties>
<appenders>
<console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="${LOG_PATTERN}"/>
<ThresholdFilter level="${LOG_LEVEL}" onMatch="ACCEPT" onMismatch="DENY"/>
</console>
</appenders>
<loggers>
<root level="${LOG_LEVEL}">
<appender-ref ref="Console"/>
</root>
</loggers>
</configuration>
计数代码:
package com.test.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountUnboundStreamDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
// 3, // 尝试重启的次数
// Time.of(10, TimeUnit.SECONDS) // 间隔
// ));
// TODO 2.读取数据
DataStreamSource<String> lineDS = env.socketTextStream("192.168.0.28", 7777);
// TODO 3.处理数据: 切分、转换、分组、聚合
// TODO 3.1 切分、转换
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = lineDS //<输入类型, 输出类型>
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 按照 空格 切分
String[] words = value.split(" ");
for (String word : words) {
// 转换成 二元组 (word,1)
Tuple2<String, Integer> wordsAndOne = Tuple2.of(word, 1);
// 通过 采集器 向下游发送数据
out.collect(wordsAndOne);
}
}
});
// TODO 3.2 分组
KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOneDS.keyBy(
new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}
);
// TODO 3.3 聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKS.sum(1);
// TODO 4.输出数据
sumDS.print("接收到的数据=======").setParallelism(1);
// TODO 5.执行:类似 sparkstreaming最后 ssc.start()
env.execute(sumDS.getClass().getSimpleName());
}
}
打成jar包导入flink dashboard:
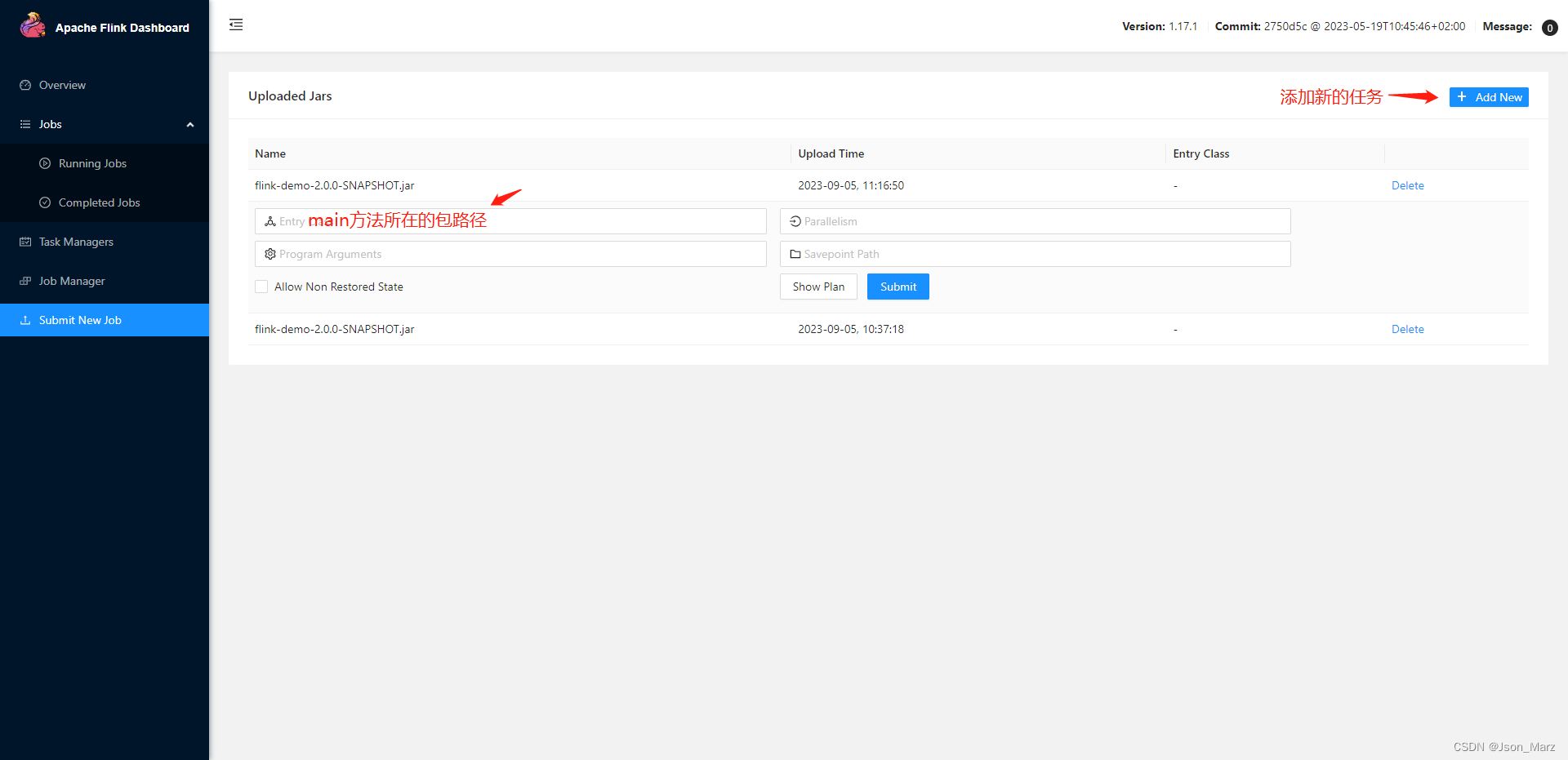
在另一台机器上运行 nc -lk -p 7777,如果出现连接拒绝,查看是否放开端口号

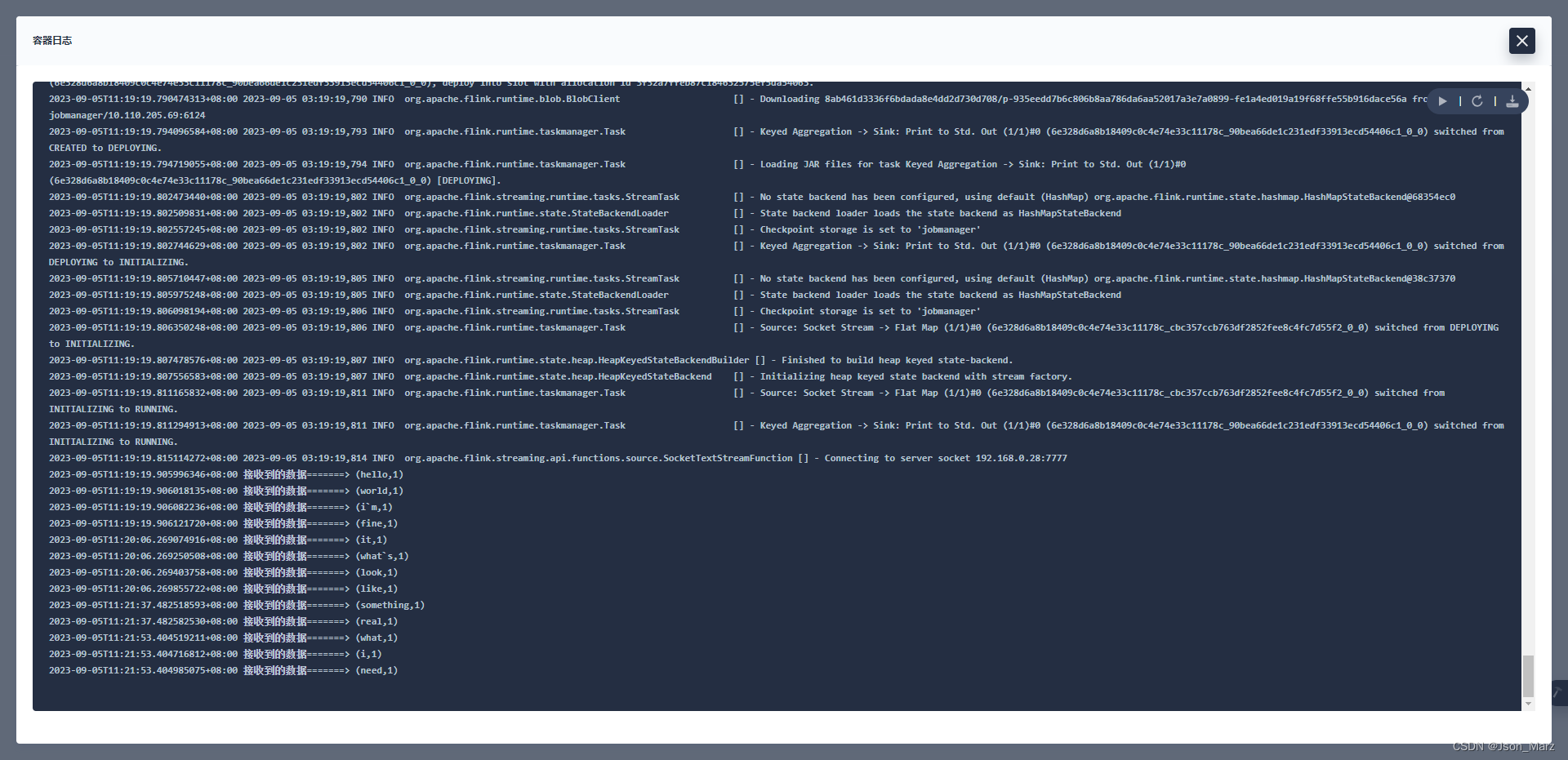
k8s查看读取到的数据