一.线性表
1.在数据结构中,数据的逻辑结构分为线性结构和非线性结构
2.线性结构:n个数据元素的有序(次序)集合。其特征如下:
- 集合中必存在唯一的一个"第一个元素"
- 集合中必存在唯一的一个"最后的元素"
- 除最后元素之外,其它数据元素均有唯一的"后继"
- 除第一元素之外,其它数据元素均有唯一的"前驱"
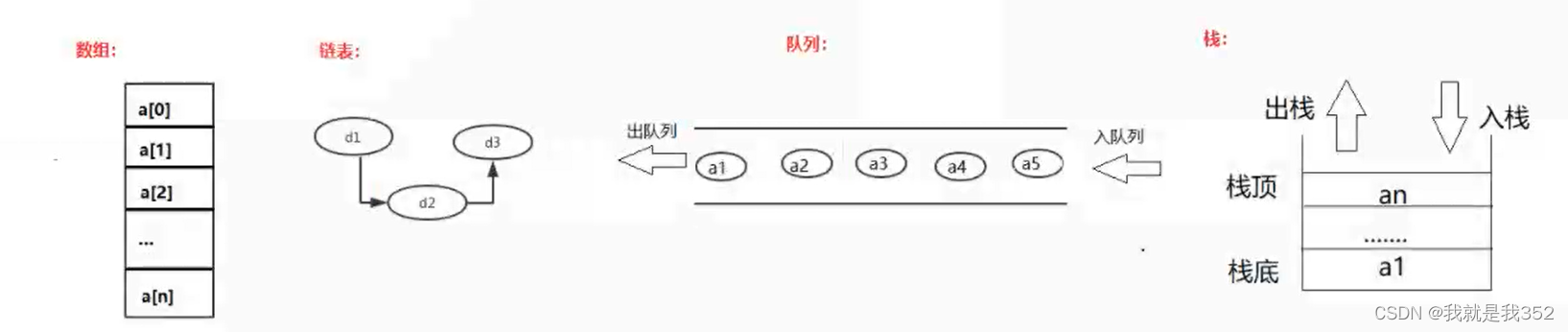
3.数据结构中线性结构指的是数据元素之间存在着“一对一”的线性关系的数据结构。当然这个线性并不是说一定是直线,常见的线性数据结构有:数组(一维),链表,栈,队列;它们也是我们后续学习其他数据结构的基础,表现形式如下:
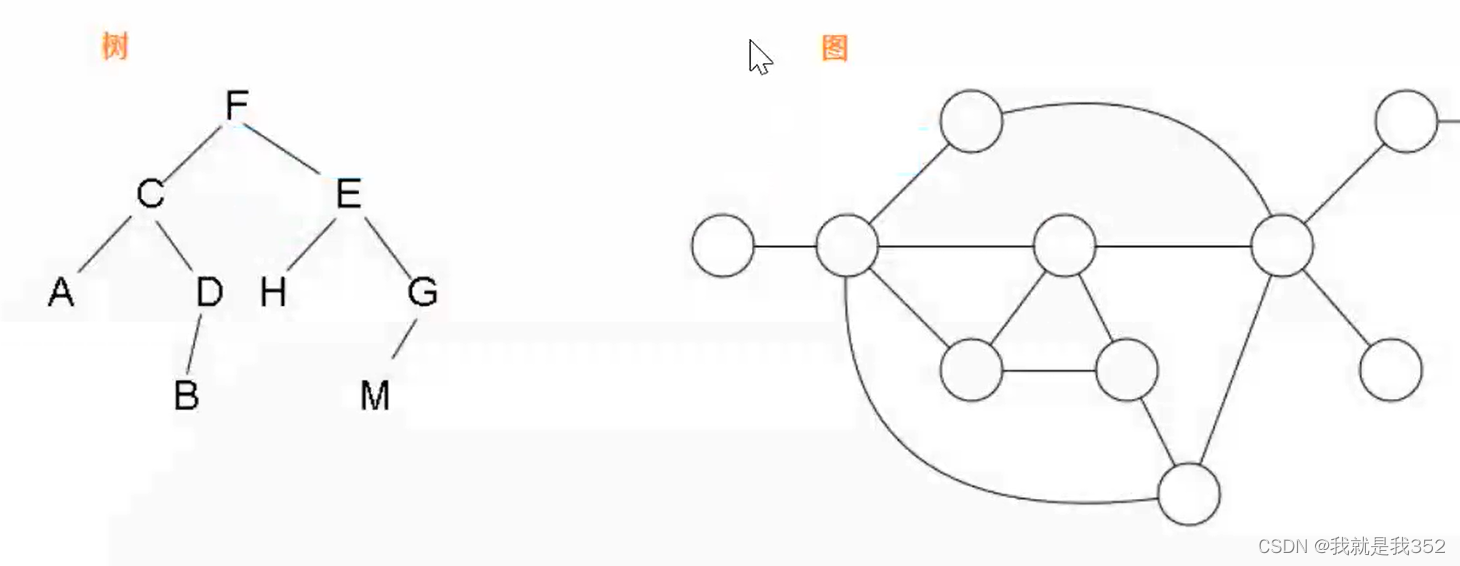
4.相对应于线性结构,非线性结构的逻辑特征是一个结点元素可能对应多个直接前驱和多个后继,比如后续要讲解的:树,图,堆等,如下图:
二.数组
1.概念和结构
1.数组(Array)是一种用连续的内存空间存储相同数据类型数据的线性数据结构
int[] array = new int[]{
10,20,30};
int[] array = new int[6];
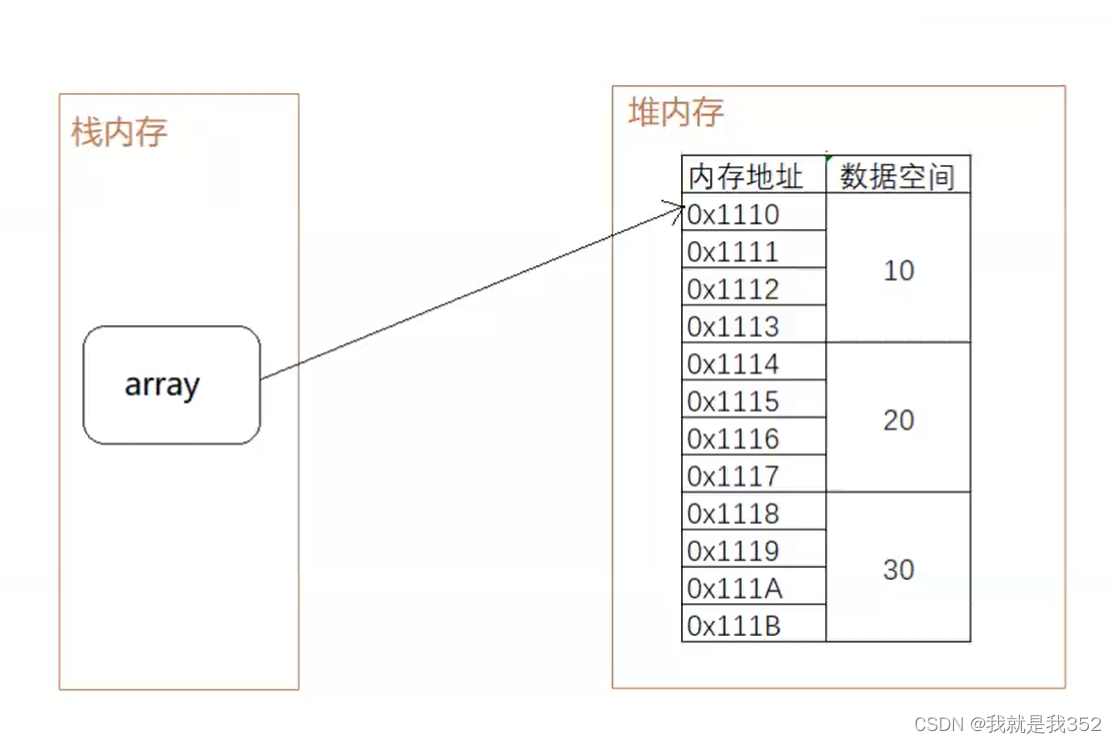
2.内存中表示形式:
3.数组的表示方式:使用下标来获取数组元素数据
- 假设有一个字符数组a,元素个数是n
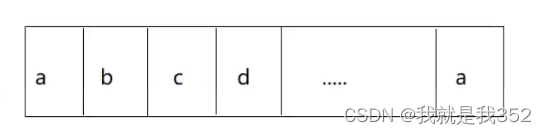
- 如何表示或者说获取数组中的元素呢?通过下标来表示获取,数组下标从0开始,到数组长度-1
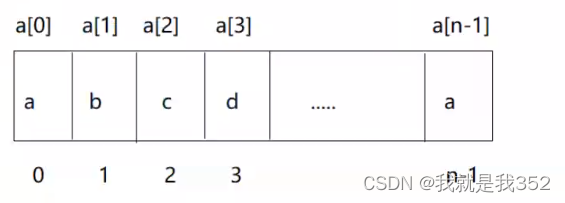
4.思考一下操作平台是如何根据下标来找到对应元素的内存地址的呢
- 我们拿一个长度为10的数组来举例,int [] a= new int[10],在下面的图中,计算机给数组分配了一块连续的空间,100-139,其中内存的起始地址为baseAddress=100
我们知道,计算机给每个内存单元都分配了一个地址,通过地址来访问其数据,因此要访问数组中的某个元素时,首先要经过一个寻址公式计算要访问的元素在内存中的地址:a[i] = baseAddress + i * dataTypeSize
- 其中dataTypeSize代表数组中元素类型的大小,在这个例子中,存储的是int型的数据,因此dataTypeSize=4个字节
- 下标为什么从0开始而不是1呢?
- 从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 array 来表示数组的首地址,array[0] 就是偏移为 0 的位置,也就是首地址,array[k] 就表示偏移 k 个type_size 的位置,所以计算 array[k] 的内存地址只需要用这个公式:
array[k]_address = base_address + k * type_size但是如果下标从1开始,那么计算array[k]的内存地址会变成:
array[k]_address = base_address + (k‐1)*type_size对比两个公式,不难发现从数组下标从1开始如果根据下标去访问数组元素,对于CPU来说,就多了一次减法指令。

2.数组的特点
1.查询O(1):数组元素的访问是通过下标来访问的,计算机通过数组的首地址和寻址公式能够很快速的找到想要访问的元素
public int test01(int[] a,int i){
return a[i];
}
代码的执行次数并不会随着数组的数据规模大小变化而变化,是常数级的,所以查询数据操作的时间复杂度是O(1)
2.插入删除O(n):数组是一段连续的内存空间,因此为了保证数组的连续性会使得数组的插入和删除的效率变的很低
- 数据插入:假设数组的长度为 n,现在如果我们需要将一个数据插入到数组中的第 k 个位置。为了把第 k 个位置腾出来给新来的数据,我们需要将第 k~n 这部分的元素都顺序地往后挪一位。如下图所示
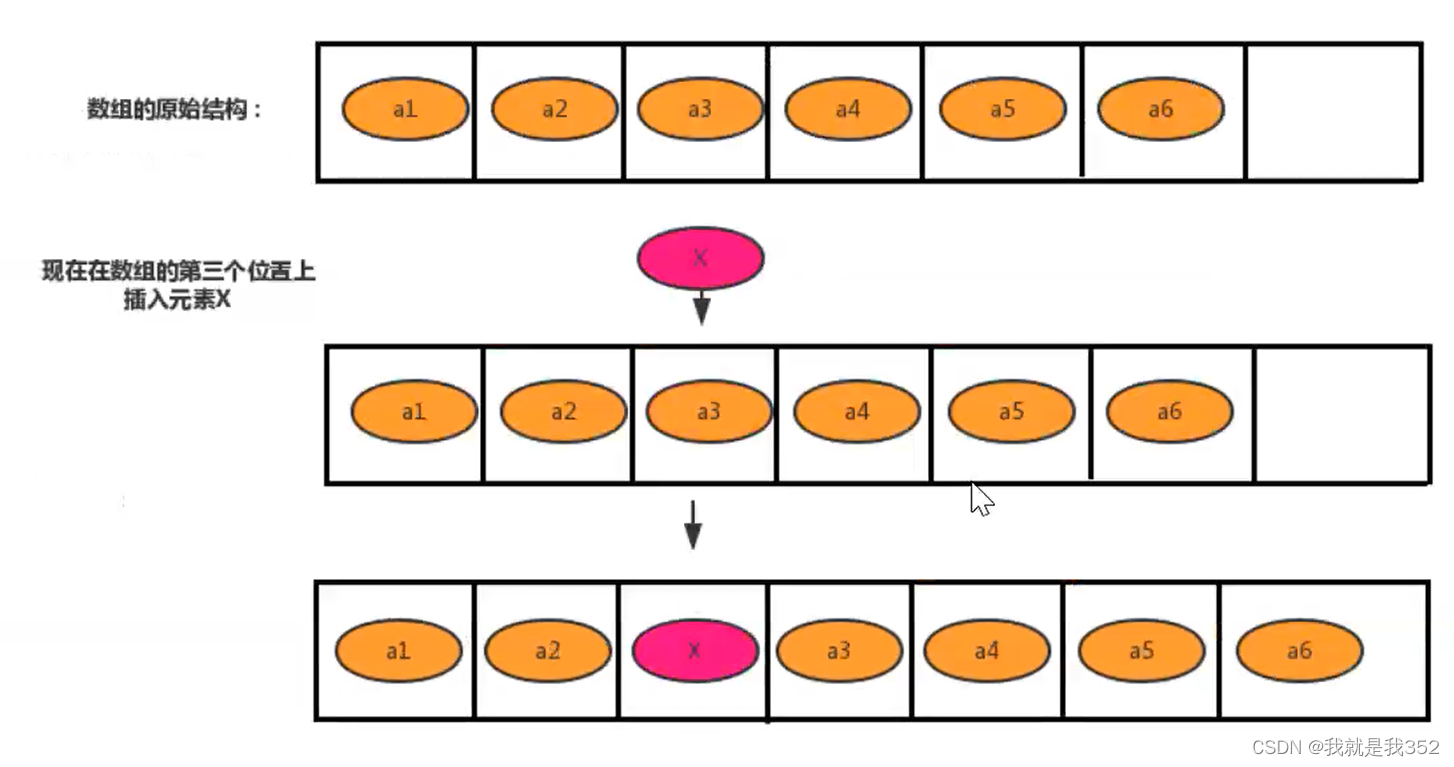
插入操作对应的时间复杂度是:最好情况下是O(1)的,最坏情况下是O(n)的,平均情况下的时间复杂度是O(n)
- 数据删除:同理可得:如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了,时间复杂度仍然是O(n)
3.在什么场景下用什么办法能提高数据删除的效率
- 实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多呢?
来一个栗子: 数组 a[6] 中存储了 6 个元素:a1,a2,a3,a4,a5,a6。现在,我们要依次删除 a1,a2 这两个元素- 为了避免 a3,a4,a5,a6这几个数据会被搬移两次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移
- 对于这种思想,就是 JVM 标记清除垃圾回收算法的核心思想