只需一人物脸部照片,即可让照片3D化,并让嘴型和歌曲基本吻合。到底是怎么做到的呢?
它就是SadTalker,那个这个技术原理到底是什么呢,老规矩,我们还是让AI来帮我们读这篇CVPR 2023的论文 SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
基本原理简单表述如下:
1、先从图片中分析出一个3D人脸模型,这个模型包括了脸的形状、表情等信息。
2、然后设计两个网络,第一个网络可以从语音中分析出口型运动的信息,第二个网络可以从语音中分析出头部转动的信息。
3、最后根据这两个网络生成的口形运动和头部转动信息,控制3D人脸模型进行相应的运动,渲染出说话的视频。这样分别学习口型运动和头部运动,比整体一起学习会更准确更自然。另外,这个方法提出了一个新颖的人脸渲染方法,可以非常逼真地把3D模型变成视频。
文中也提到了两个网络,
一个网络是ExpNet,用来学习音频映射到表情的系数,主要原理是:1、首先用一个预训练好的网络只从语音中分析出嘴巴的动作,也就是口形运动。然后ExpNet网络会同时看语音信号和嘴巴运动,学习生成整个脸的其他表情运动,比如眨眼。
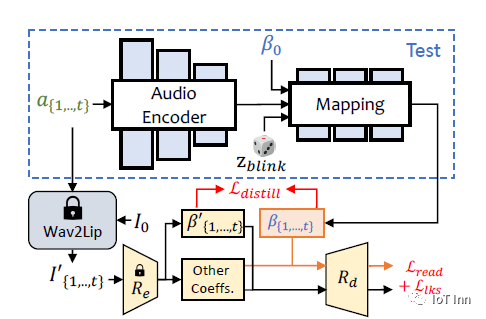
为了让ExpNet网络学习到正确的表情,这个方法采用了两个技巧:
a、给ExpNet提供一开始脸部的表情信息,这样可以减少身份的不确定性,知道生成的是谁。b、在生成的3D脸模型上计算眼睛和嘴巴的外形,和真实视频比较,让生成的表情更准确。这样ExpNet就可以只关注学习除了嘴巴之外的其他表情运动,并且生成逼真的表情结果
另外一个网络是PoseVAE,用来学习从语音中分析出头部的转动姿态。
PoseVAE使用一种叫变分自动编码器(VAE)的结构。简单来说,它包含一个编码器和一个解码器。编码器可以把头部转动的姿态编码成一个向量,解码器可以从这个向量再解码出原来的头部姿态。
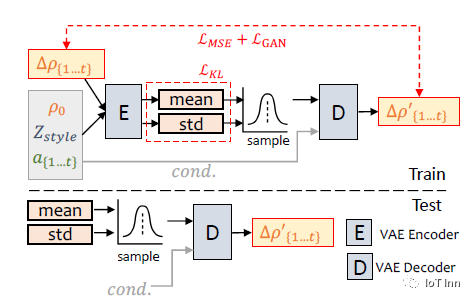
训练的时候,PoseVAE网络输入真实视频的头部姿态序列,学习提取语音特征与头部运动的关系。预测时,只需要输入语音,PoseVAE就可以输出自然的头部转动序列。
为了生成不同风格的头部运动,这个网络还输入了一个风格信息。这样同样的语音可以对应不同风格的头部动作。
然后作者也开源了整个项目的源码OpenTalker/SadTalker: [CVPR 2023] SadTalker:Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation (github.com),并且也可以在stable-diffusion webui里当做插件来使用,只需要在sd webui扩展里面,直接搜索sadtalker,点击安装即可。需要注意的是,sd webui并不会直接帮你下载模型,需要手动下载。具体打开git仓库即可以看到具体模型的下载方式
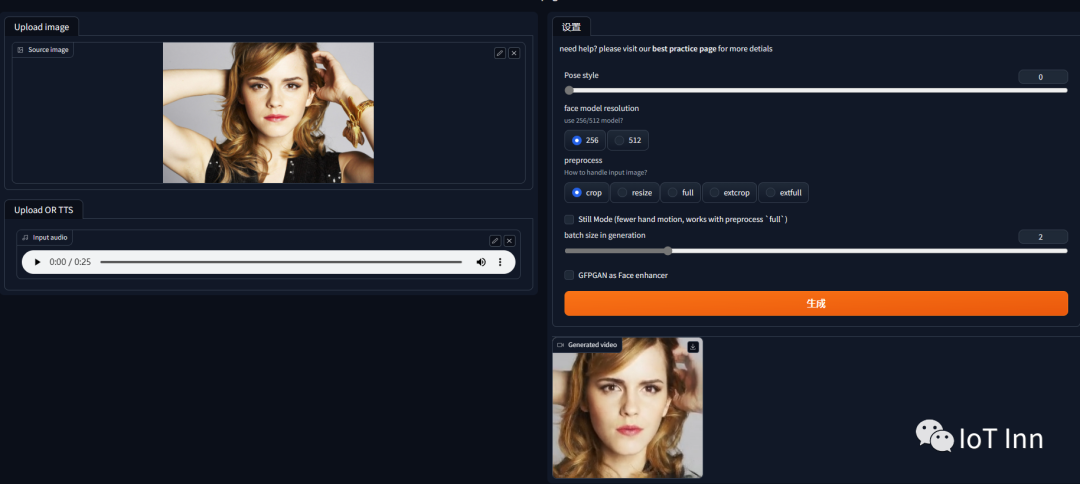
下载完成的模型,可以直接放在extension下的sadtalker文件中checkpoints目录下,如果没有这个目录,可以自己创建一个。启动webui,然后打开sadtalker标签即可使用,我们上传赫敏的照片,然后再上传一段音频,由于电脑显存不够,所以只生成了上面的25秒视频
各位看官觉得如何了,想尝试的赶紧点一波关注吧