我们在工作中肯定写过sql语句,也会进行一下sql语句的优化,在优化sql语句里看过相应的explain 在进行sql语句优化的时候,理解执行计划中各个参数的意思,弄明白执行的顺序,对sql优化有很大的帮助。
1、通过 Explain 命令查看执行计划

2、通过Navicat查看执行计划
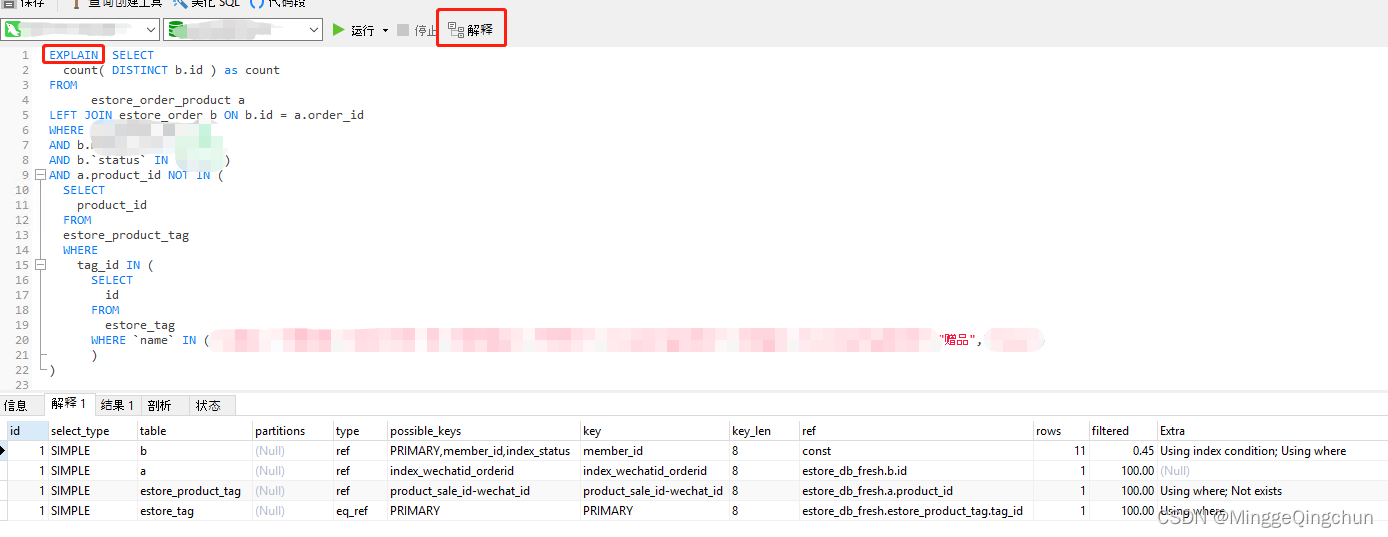
在Navicat中执行完相应的sql语句,然后点击【解释】,其实执行计划就是解释怎么执行的sql语句,有的版本的“解释”按钮在上面,有的版本的“解释”按钮在下面,视版本不同而定
MySQL5.7官网解释
MySQL :: MySQL 5.7 Reference Manual :: 8.8.2 EXPLAIN Output Format
Table 8.1 EXPLAIN Output Columns
| Column | JSON Name | Meaning |
|---|---|---|
| id | select_id |
The SELECT identifier |
| select_type | None | The SELECT type |
| table | table_name |
The table for the output row |
| partitions | partitions |
The matching partitions |
| type | access_type |
The join type |
| possible_keys | possible_keys |
The possible indexes to choose |
| key | key |
The index actually chosen |
| key_len | key_length |
The length of the chosen key |
| ref | ref |
The columns compared to the index |
| rows | rows |
Estimate of rows to be examined |
| filtered | filtered |
Percentage of rows filtered by table condition |
| Extra | None | Additional information |
Note
JSON properties which are NULL are not displayed in JSON-formatted EXPLAIN output.
-
The SELECT identifier. This is the sequential number of the SELECT within the query. The value can be
NULLif the row refers to the union result of other rows. In this case, thetablecolumn shows a value like<unionto indicate that the row refers to the union of the rows withM,N>idvalues ofMandN. -
The type of SELECT, which can be any of those shown in the following table. A JSON-formatted
EXPLAINexposes theSELECTtype as a property of aquery_block, unless it isSIMPLEorPRIMARY. The JSON names (where applicable) are also shown in the table.select_typeValueJSON Name Meaning SIMPLENone Simple SELECT (not using UNION or subqueries) PRIMARYNone Outermost SELECT UNION None Second or later SELECT statement in a UNION DEPENDENT UNIONdependent(true)Second or later SELECT statement in a UNION, dependent on outer query UNION RESULTunion_resultResult of a UNION. SUBQUERY None First SELECT in subquery DEPENDENT SUBQUERYdependent(true)First SELECT in subquery, dependent on outer query DERIVEDNone Derived table MATERIALIZEDmaterialized_from_subqueryMaterialized subquery UNCACHEABLE SUBQUERYcacheable(false)A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query UNCACHEABLE UNIONcacheable(false)The second or later select in a UNION that belongs to an uncacheable subquery (see UNCACHEABLE SUBQUERY)DEPENDENTtypically signifies the use of a correlated subquery. See Section 13.2.10.7, “Correlated Subqueries”.DEPENDENT SUBQUERYevaluation differs fromUNCACHEABLE SUBQUERYevaluation. ForDEPENDENT SUBQUERY, the subquery is re-evaluated only once for each set of different values of the variables from its outer context. ForUNCACHEABLE SUBQUERY, the subquery is re-evaluated for each row of the outer context.Cacheability of subqueries differs from caching of query results in the query cache (which is described in Section 8.10.3.1, “How the Query Cache Operates”). Subquery caching occurs during query execution, whereas the query cache is used to store results only after query execution finishes.
When you specify
FORMAT=JSONwithEXPLAIN, the output has no single property directly equivalent toselect_type; thequery_blockproperty corresponds to a givenSELECT. Properties equivalent to most of theSELECTsubquery types just shown are available (an example beingmaterialized_from_subqueryforMATERIALIZED), and are displayed when appropriate. There are no JSON equivalents forSIMPLEorPRIMARY.The
select_typevalue for non-SELECT statements displays the statement type for affected tables. For example,select_typeisDELETEfor DELETE statements. -
The name of the table to which the row of output refers. This can also be one of the following values:
-
<union: The row refers to the union of the rows withM,N>idvalues ofMandN. -
<derived: The row refers to the derived table result for the row with anN>idvalue ofN. A derived table may result, for example, from a subquery in theFROMclause. -
<subquery: The row refers to the result of a materialized subquery for the row with anN>idvalue ofN. See Section 8.2.2.2, “Optimizing Subqueries with Materialization”.
-
-
partitions(JSON name:partitions)The partitions from which records would be matched by the query. The value is
NULLfor nonpartitioned tables. See Section 22.3.5, “Obtaining Information About Partitions”. -
The join type. For descriptions of the different types, see EXPLAIN Join Types.
-
possible_keys(JSON name:possible_keys)The
possible_keyscolumn indicates the indexes from which MySQL can choose to find the rows in this table. Note that this column is totally independent of the order of the tables as displayed in the output from EXPLAIN. That means that some of the keys inpossible_keysmight not be usable in practice with the generated table order.If this column is
NULL(or undefined in JSON-formatted output), there are no relevant indexes. In this case, you may be able to improve the performance of your query by examining theWHEREclause to check whether it refers to some column or columns that would be suitable for indexing. If so, create an appropriate index and check the query with EXPLAIN again. See Section 13.1.8, “ALTER TABLE Statement”.To see what indexes a table has, use
SHOW INDEX FROM.tbl_name -
The
keycolumn indicates the key (index) that MySQL actually decided to use. If MySQL decides to use one of thepossible_keysindexes to look up rows, that index is listed as the key value.It is possible for
keyto name an index that is not present in thepossible_keysvalue. This can happen if none of thepossible_keysindexes are suitable for looking up rows, but all the columns selected by the query are columns of some other index. That is, the named index covers the selected columns, so although it is not used to determine which rows to retrieve, an index scan is more efficient than a data row scan.For
InnoDB, a secondary index might cover the selected columns even if the query also selects the primary key becauseInnoDBstores the primary key value with each secondary index. IfkeyisNULL, MySQL found no index to use for executing the query more efficiently.To force MySQL to use or ignore an index listed in the
possible_keyscolumn, useFORCE INDEX,USE INDEX, orIGNORE INDEXin your query. See Section 8.9.4, “Index Hints”.For
MyISAMtables, running ANALYZE TABLE helps the optimizer choose better indexes. ForMyISAMtables, myisamchk --analyze does the same. See Section 13.7.2.1, “ANALYZE TABLE Statement”, and Section 7.6, “MyISAM Table Maintenance and Crash Recovery”. -
key_len(JSON name:key_length)The
key_lencolumn indicates the length of the key that MySQL decided to use. The value ofkey_lenenables you to determine how many parts of a multiple-part key MySQL actually uses. If thekeycolumn saysNULL, thekey_lencolumn also saysNULL.Due to the key storage format, the key length is one greater for a column that can be
NULLthan for aNOT NULLcolumn. -
The
refcolumn shows which columns or constants are compared to the index named in thekeycolumn to select rows from the table.If the value is
func, the value used is the result of some function. To see which function, use SHOW WARNINGS following EXPLAIN to see the extended EXPLAIN output. The function might actually be an operator such as an arithmetic operator. -
The
rowscolumn indicates the number of rows MySQL believes it must examine to execute the query.For InnoDB tables, this number is an estimate, and may not always be exact.
-
filtered(JSON name:filtered)The
filteredcolumn indicates an estimated percentage of table rows filtered by the table condition. The maximum value is 100, which means no filtering of rows occurred. Values decreasing from 100 indicate increasing amounts of filtering.rowsshows the estimated number of rows examined androws×filteredshows the number of rows joined with the following table. For example, ifrowsis 1000 andfilteredis 50.00 (50%), the number of rows to be joined with the following table is 1000 × 50% = 500. -
This column contains additional information about how MySQL resolves the query. For descriptions of the different values, see EXPLAIN Extra Information.
There is no single JSON property corresponding to the
Extracolumn; however, values that can occur in this column are exposed as JSON properties, or as the text of themessageproperty.
The type column of EXPLAIN output describes how tables are joined. In JSON-formatted output, these are found as values of the access_type property. The following list describes the join types, ordered from the best type to the worst:
-
The table has only one row (= system table). This is a special case of the const join type.
-
The table has at most one matching row, which is read at the start of the query. Because there is only one row, values from the column in this row can be regarded as constants by the rest of the optimizer. const tables are very fast because they are read only once.
const is used when you compare all parts of a
PRIMARY KEYorUNIQUEindex to constant values. In the following queries,tbl_namecan be used as a const table:SELECT * FROM tbl_name WHERE primary_key=1; SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2; -
One row is read from this table for each combination of rows from the previous tables. Other than the system and const types, this is the best possible join type. It is used when all parts of an index are used by the join and the index is a
PRIMARY KEYorUNIQUE NOT NULLindex.eq_ref can be used for indexed columns that are compared using the
=operator. The comparison value can be a constant or an expression that uses columns from tables that are read before this table. In the following examples, MySQL can use an eq_ref join to processref_table:SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1; -
All rows with matching index values are read from this table for each combination of rows from the previous tables. ref is used if the join uses only a leftmost prefix of the key or if the key is not a
PRIMARY KEYorUNIQUEindex (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.ref can be used for indexed columns that are compared using the
=or<=>operator. In the following examples, MySQL can use a ref join to processref_table:SELECT * FROM ref_table WHERE key_column=expr; SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1; -
The join is performed using a
FULLTEXTindex. -
This join type is like ref, but with the addition that MySQL does an extra search for rows that contain
NULLvalues. This join type optimization is used most often in resolving subqueries. In the following examples, MySQL can use a ref_or_null join to processref_table:SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL; -
This join type indicates that the Index Merge optimization is used. In this case, the
keycolumn in the output row contains a list of indexes used, andkey_lencontains a list of the longest key parts for the indexes used. For more information, see Section 8.2.1.3, “Index Merge Optimization”. -
This type replaces eq_ref for some
INsubqueries of the following form:value IN (SELECT primary_key FROM single_table WHERE some_expr)unique_subquery is just an index lookup function that replaces the subquery completely for better efficiency.
-
This join type is similar to unique_subquery. It replaces
INsubqueries, but it works for nonunique indexes in subqueries of the following form:value IN (SELECT key_column FROM single_table WHERE some_expr) -
Only rows that are in a given range are retrieved, using an index to select the rows. The
keycolumn in the output row indicates which index is used. Thekey_lencontains the longest key part that was used. Therefcolumn isNULLfor this type.range can be used when a key column is compared to a constant using any of the =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN() operators:
SELECT * FROM tbl_name WHERE key_column = 10; SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20; SELECT * FROM tbl_name WHERE key_column IN (10,20,30); SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30); -
The
indexjoin type is the same as ALL, except that the index tree is scanned. This occurs two ways:-
If the index is a covering index for the queries and can be used to satisfy all data required from the table, only the index tree is scanned. In this case, the
Extracolumn saysUsing index. An index-only scan usually is faster than ALL because the size of the index usually is smaller than the table data. -
A full table scan is performed using reads from the index to look up data rows in index order.
Uses indexdoes not appear in theExtracolumn.
MySQL can use this join type when the query uses only columns that are part of a single index.
-
-
A full table scan is done for each combination of rows from the previous tables. This is normally not good if the table is the first table not marked const, and usually very bad in all other cases. Normally, you can avoid ALL by adding indexes that enable row retrieval from the table based on constant values or column values from earlier tables.
1、id:执行顺序
分为三种情况:id一样;id不一样;id既存在一样的,又存在不一样的
【1】id一样的,执行顺序从上到下
【2】id不一样的,id越大,等级越高,执行顺序约先;
【3】id既存在相同又存在不同的,相同id的为一组,不同id的为不同组,不同组之间id越大,等级越高,越先执行,同组之间,执行顺序从上到下
2、select_type:子查询的种类
1、SIMPLE:简单的select查询,查询中不包含子查询或者union
2、PRIMARY:查询中包含任何复杂的子部分,最外层查询则被标记为primary
3、SUBQUERY:在select 或 where列表中包含了子查询
4、DERIVED:在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在临时表里
5、UNION:若第二个select出现在union之后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为derived
6、UNION RESULT:从union表获取结果的select
3、table:表名
4、type:查询的类型
自上而下,由差到最好,一般来说,好的sql查询至少达到range级别,最好能达到ref
all:全表扫描
index:遍历索引树,index与ALL区别为index类型只遍历索引树,Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取
range:索引范围扫描,只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、<、>、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引
ref:非唯一性索引扫描,返回匹配某个单独值的所有行
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配
const,system:常量转换
NULL:分解语句,执行时甚至不用访问表或索引
5、possible_keys
查询涉及到字段上的索引,则该索引将被列出,但不一定被查询实际使用
6、key
SQL语句实际用到的索引
7、key_len
使用的索引的字节数,表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。key_len是根据表定义计算而得的,不是通过表内检索出的
8、ref
哪些列或常量被用于查找索引列上的值
9、rows
得到数据所需要读取的行数
10、filtered
MySql5.7官方文档中描述如下:
Thefilteredcolumn indicates an estimated percentage of table rows filtered by the table condition. The maximum value is 100, which means no filtering of rows occurred. Values decreasing from 100 indicate increasing amounts of filtering.rowsshows the estimated number of rows examined androws×filteredshows the number of rows joined with the following table. For example, ifrowsis 1000 andfilteredis 50.00 (50%), the number of rows to be joined with the following table is 1000 × 50% = 500.
这段文字不是很好理解,举例来说,有如下三个查询语句的explain结果,针对b和c表的显示filtered是100,而针对a表的显示是18。
+-------------+-------+--------+---------+---------+------+----------+
| select_type | table | type | key | key_len | rows | filtered |
+-------------+-------+--------+---------+---------+------+----------+
| PRIMARY | a | range | search | 4 | 174 | 18.00 |
| PRIMARY | b | eq_ref | PRIMARY | 4 | 1 | 100.00 |
| PRIMARY | c | ALL | PRIMARY | 4 | 1 | 100.00 |我们可以怎么理解filtered的值呢?从filtered的值中得出什么结论呢?到底是100更好还是18更好?
首先,这里的filtered表示通过查询条件获取的最终记录行数占通过type字段指明的搜索方式搜索出来的记录行数的百分比。
以上图的第一条语句为例,MySQL首先使用索引(这里的type是range)扫描表a,预计会得到174条记录,也就是rows列展示的记录数。接下来MySql会使用额外的查询条件对这174行记录做二次过滤,最终得到符合查询语句的32条记录,也就是174条记录的18%。而18%就是filtered的值。
更完美的情况下,应该是使用某个索引,直接搜索出32条记录并且过滤掉另外82%的记录。
因此一个比较低filtered值表示需要有一个更好的索引,假如type=all,表示以全表扫描的方式得到1000条记录,且filtered=0.1%,表示只有1条记录是符合搜索条件的。此时如果加一个索引可以直接搜出来1条数据,那么filtered就可以提升到100%。
由此可见,filtered=100%确实是要比18%要好。
当然,filtered不是万能的,关注执行计划结果中其他列的值并优化查询更重要。比如为了避免出现filesort(使用可以满足order by的索引),即使filtered的值比较低也没问题。再比如上面filtered=0.1%的场景,我们更应该关注的是添加一个索引提高查询性能,而不是看filtered的值
11、Extra
其他重要信息