大家好呀,从昨天发布赛题一直到现在,总算完成了华数杯数学建模C题完整的成品论文。
本论文可以保证原创,保证高质量。绝不是随便引用一大堆模型和代码复制粘贴进来完全没有应用糊弄人的垃圾半成品论文。

C题论文共72页,一些修改说明7页,正文54页,附录11页。
这道题出得还算不错,逻辑非常连贯。从昨天通宵到现在,我尽量还是想把这道题工作量堆上去,第一问我把婴儿四个指标分成了定类定量两类,分别做差异性分析和相关性分析,其实都是为了看p值。第二问无脑随机森林分类,给出权重后,测试集精度我换了很多模型改了很多参数,最终合格。第三问就是给治疗方案然后按照第二问分类预测看能不能达到中等安静,这个确定完治疗方式后一直试方案无脑预测就完事了。第四问先是RSR算得分和分档,之后就是随机森林回归了,实际预测一下得分即可。最后一问则是基于第四问的回归模型一直试各种方案得分看能不能达到优。
之所以篇幅这么长,是因为:
我论文很多的篇幅需要用来解释我为什么要这么做,基本就是手把手教你怎么做,并且我还要照顾每个人的水平,所有会有些地方需要写得很繁琐,一些中间过程展现得事无巨细,并且表格很多,你们自己放到附录即可
实在精力有限,没力气打太多字做文字版讲解了,可能讲得不够详细,可以看我视频讲解哈:
2023华数杯数学建模C题母亲对婴儿影响手把手保姆级教学!_哔哩哔哩_bilibili
本文很长,大家一口气看不完别忘了点赞收藏一下防止迷路哈。
OK,这里是我的
目录:

摘要:

问题一:
1. 许多研究表明,母亲的身体指标和心理指标对婴儿的行为特征和睡眠质量有影响,请问是否存在这样的规律,根据附件中的数据对此进行研究。
婴儿的指标我分成了两类,一类是定类的,一类是定量的。定类的做差异性分析,定量的相关性分析,但最终本质上都是看显著性p值大小,如果存在显著差异,那么就说明存在影响。



问题二:
2. 婴儿行为问卷是一个用于评估婴儿行为特征的量表,其中包含了一些关 于婴儿情绪和反应的问题。我们将婴儿的行为特征分为三种类型:安静型、中等 型、矛盾型。请你建立婴儿的行为特征与母亲的身体指标与心理指标的关系模型。 数据表中最后有20组(编号391-410号)婴儿的行为特征信息被删除,请你判断他们是属于什么类型。
做一个分类预测的机器学习模型即可:


问题三:
3. 对母亲焦虑的干预有助于提高母亲的心理健康水平,还可以改善母婴交 互质量,促进婴儿的认知、情感和社交发展。CBTS、EPDS、HADS的治疗费用相对 于患病程度的变化率均与治疗费用呈正比,经调研,给出了两个分数对应的治疗 费用,详见表1。现有一个行为特征为矛盾型的婴儿,编号为238。请你建立模型,分析最少需要花费多少治疗费用,能够使婴儿的行为特征从矛盾型变为中等型?若要使其行为特征变为安静型,治疗方案需要如何调整?
给出各种治疗方案,按照问题二的分类预测模型,看一下到底什么时候能降到中等和安静就可以。
而对于治疗费用到底如何计算,又该怎么定义治疗,这些大家可以看文末的视频讲解,就不多赘述了。

第四问:
4. 婴儿的睡眠质量指标包含整晚睡眠时间、睡醒次数、入睡方式。请你对 婴儿的睡眠质量进行优、良、中、差四分类综合评判,并建立婴儿综合睡眠质量 与母亲的身体指标、心理指标的关联模型,预测最后20组(编号391-410号)婴儿的综合睡眠质量。
先做综合评价算得分并划分等级,之后做预测得分的机器学习模型就可以:
再放一点代码吧,注意只是随机森林的模板代码,不是我自己实际求解使用的哈:
function [tree,discrete_dim] = train_C4_5(S, inc_node, Nu, discrete_dim)
% Classify using Quinlan's C4.5 algorithm
% Inputs:
% training_patterns - Train patterns 训练样本 每一列代表一个样本 每一行代表一个特征
% training_targets - Train targets 1×训练样本个数 每个训练样本对应的判别值
% test_patterns - Test patterns 测试样本,每一列代表一个样本
% inc_node - Percentage of incorrectly assigned samples at a node 一个节点上未正确分配的样本的百分比
% inc_node为防止过拟合,表示样本数小于一定阈值结束递归,可设置为5-10
% 注意inc_node设置太大的话会导致分类准确率下降,太小的话可能会导致过拟合
% Nu is to determine whether the variable is discrete or continuous (the value is always set to 10)
% Nu用于确定变量是离散还是连续(该值始终设置为10)
% 这里用10作为一个阈值,如果某个特征的无重复的特征值的数目比这个阈值还小,就认为这个特征是离散的
% Outputs
% test_targets - Predicted targets 1×测试样本个数 得到每个测试样本对应的判别值
% 也就是输出所有测试样本最终的判别情况
%NOTE: In this implementation it is assumed that a pattern vector with fewer than 10 unique values (the parameter Nu)
%is discrete, and will be treated as such. Other vectors will be treated as continuous
% 在该实现中,假设具有少于10个无重复值的特征向量(参数Nu)是离散的。 其他向量将被视为连续的
train_patterns = S(:,1:end-1)';
train_targets = S(:,end)';
[Ni, M] = size(train_patterns); %M是训练样本数,Ni是训练样本维数,即是特征数目
inc_node = inc_node*M/100; % 5*训练样本数目/100
if isempty(discrete_dim)
%Find which of the input patterns are discrete, and discretisize the corresponding dimension on the test patterns
%查找哪些输入模式(特征)是离散的,并离散测试模式上的相应维
discrete_dim = zeros(1,Ni); %用于记录每一个特征是否是离散特征,初始化都记为0,代表都是连续特征,
%如果后面更改,则意味着是离散特征,这个值会更改为这个离散特征的无重复特征值的数目
for i = 1:Ni %遍历每个特征
Ub = unique(train_patterns(i,:)); %取每个特征的不重复的特征值构成的向量
Nb = length(Ub); %得到无重复的特征值的数目
if (Nb <= Nu) %如果这个特征的无重复的特征值的数目比这个阈值还小,就认为这个特征是离散的
%This is a discrete pattern
discrete_dim(i) = Nb; %得到训练样本中,这个特征的无重复的特征值的数目 存放在discrete_dim(i)中,i表示第i个特征

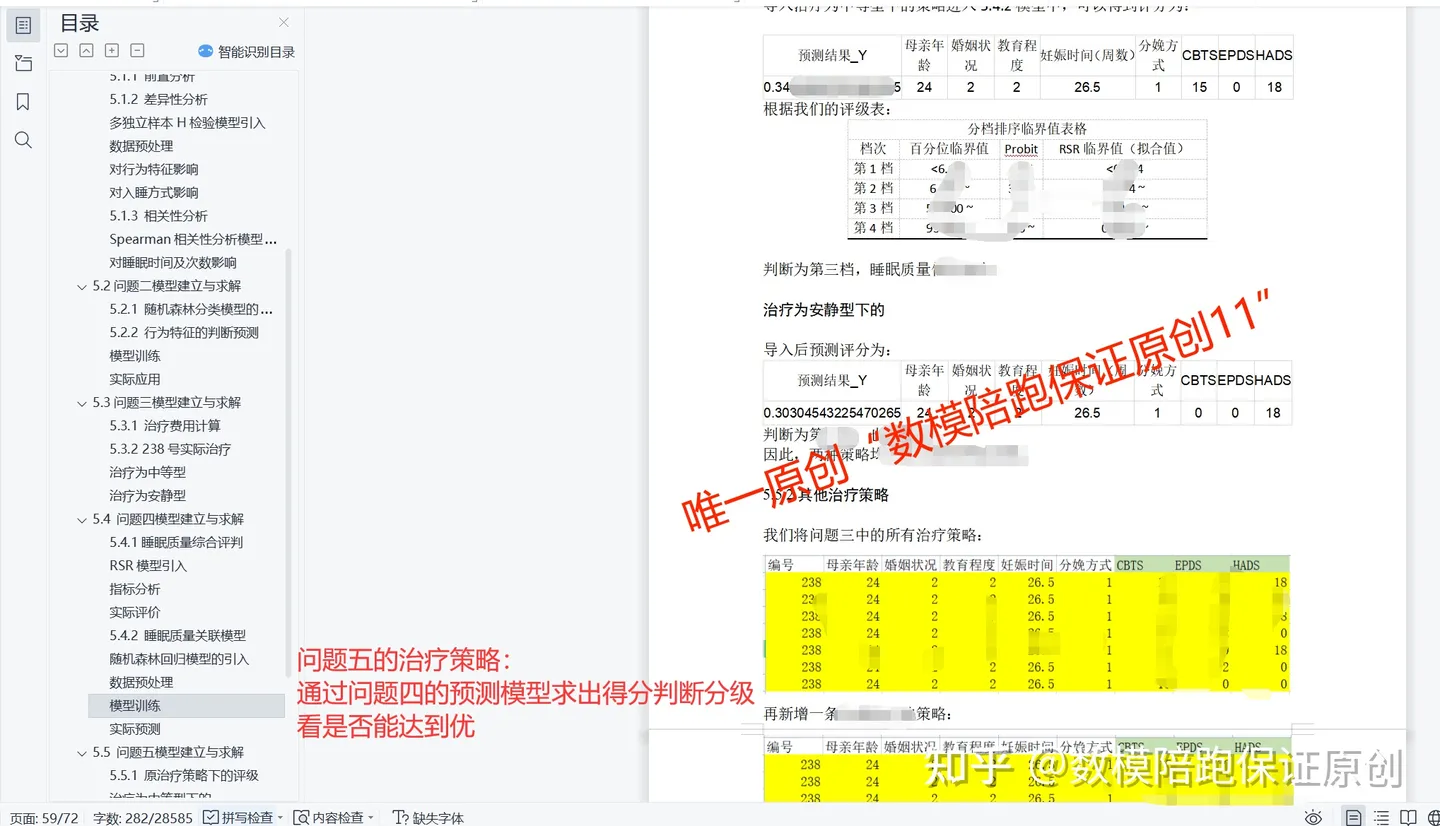
第五问:
5.在问题三的基础上,若需要让238号婴儿的睡眠质量评级为优,请问问题 三的治疗策略是否需要调整?如何调整?
改换各种治疗方案算得分判断分级即可:
OK以上只是比较简略的图文版讲解,视频版讲解及完整成品可以点击下方我的个人卡片查看哈↓: