文章目录
Kudu客户端API编程
客户端API核心类
Kudu提供了主流语言客户端API,核心类、方法是一致的,我们首先简要盘点下核心的这些类以便于我们写代码。
(1)Kudu client
- AsyncKuduClient:完全异步且线程安全的Kudu客户端。该类应该只实例化一次,同时访问很多表。只有操纵多个不同集群才需要实例化多次。不会阻塞操作,可以关联回调函数用于操作完成时的动作。Builder模式创建。
- KuduClient:对AsyncKuduClient的封装,同步执行、线程安全的Kudu客户端,Builder模式创建。
(2)Schema
表示表结构,主要是column的集合。该类提供了一些工具方法用于查询操作。
(3)ColumnSchema
表示一column,使用builder构建。
(4)CreateTableOptions
Builder模式类,用于创建表。
(5)KuduTable

表示集群上的一张表。含有当前表结构信息,隶属于特定AsyncKuduClient。
(6)Session
- AsyncKuduSession:隶属于特定KuduClient,代表一个上下文环境,所有写操作都会在该上下文中进行。在一个session中,可以对多个操作按批处理方式执行,以获得较好的性能。每个session都可以设置超时、优先级以及跟踪id等信息。 session和KuduClient是独立的,主要是在多线程环境下,不同线程需要并发执行事务,事务的边界是基于每 个session的BeginTransaction和commit之间的过程。 来自于不同session的写操作不会组织到一个RPC请求batch中,意味着延迟敏感的客户端(低延迟)和面向吞吐量的客户端(高延迟)使用同一KuduClient,每个Session中可以设置特定的超时和优先级。
- KuduSession:对AsyncKuduSession封装,同步执行,但非线程安全
(7)Insert/Update/Delete/Upsert
表示插入/更新/删除/插入或者更新操作,对象不可复用。
(8)PartialRow
表示一行的部分列。
(9)KuduScanner
扫描对象,用于条件查询及迭代获取结果集。
Java编程接口
环境准备
接下来我们只需要在pom.xml中导入相关依赖即可:
<properties>
<kudu.version>1.10.0</kudu.version>
<junit.version>4.12</junit.version>
</properties>
<dependencies>
<!-- Kudu client -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>${kudu.version}</version>
</dependency>
<!-- Log -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.12</version>
</dependency>
<!-- Unit test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<!-- 指定具体仓库 -->
<repositories>
<repository>
<id>cdh.repo</id>
<name>Cloudera Repositories</name>
<url>https://repository.cloudera.com/content/repositories/releases</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
代码骨架:
public class TestKudu {
public static void main(String[] args) {
System.out.println("hello kudu!");
}
}
定义一个常量KUDU_MASTERS存放Kudu master的连接信息(根据自己的实际情况改为你的IP或者主机名):
private static final String KUDU_MASTERS = "node01:7051,node02:7051,node03:7051";
创建表
执行结果:
@Test
public void testCreateTable() throws KuduException {
//1、创建Schema
List<ColumnSchema> columns = new ArrayList<>(2);
columns.add(new ColumnSchema.ColumnSchemaBuilder("uid", Type.INT8)
.key(true)
.build());
columns.add(new ColumnSchema.ColumnSchemaBuilder("name",
Type.STRING).nullable(true)
.build());
columns.add(new ColumnSchema.ColumnSchemaBuilder("age", Type.INT8).build());
Schema schema = new Schema(columns);
//2、指定表选项
//2.1 建表选项
CreateTableOptions tableOptions = new CreateTableOptions();
//2.2 创建分区字段列表(必须是主键列)
List<String> hashCls = new ArrayList<String>();
hashCls.add("uid");
int numBuckets = 6;
//2.3 分区策略
tableOptions.addHashPartitions(hashCls,numBuckets)
.setNumReplicas(1);
//3、创建KuduClient
KuduClient client=null;
try {
client=new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
//4、创建表
if(!client.tableExists("users")){
client.createTable("users", schema, tableOptions);
System.out.println(".........create table success.........");
}else{
System.out.println(".........the table already exists .........");
}
}finally {
//5、关闭资源
if(null!=client){
client.shutdown();
}
}
}
插入数据
@Test
public void testInsert() throws KuduException {
//1、获得kudu客户端
KuduClient client = null;
//2、打开表
KuduTable table = null;
//3、创建会话
KuduSession session = null;
try{
client = new KuduClient
.KuduClientBuilder(KUDU_MASTERS)
.build();
table = client.openTable("users") ;
session = client.newSession();
session.setFlushMode(SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND);
session.setFlushInterval(2000);
//4、循环插入10行记录
for(int i = 0 ; i < 100 ; i ++){
//新建Insert对象
Insert insert = table.newInsert() ;
PartialRow row = insert.getRow() ;
row.addByte("uid" , Byte.parseByte(i+""));
//i是偶数
if(i % 2 == 0){
row.setNull("name");
}
else{
row.addString("name" , "name " + i);
}
row.addByte("age",Byte.parseByte(i+""));
//加入session
session.apply(insert) ;
}
//5、关闭session
session.close() ;
//判断错误数
if(session.countPendingErrors() != 0){
//获得操作结果
RowErrorsAndOverflowStatus result = session.getPendingErrors() ;
if(result.isOverflowed()){
System.out.println("............buffer溢出!.................");
}
RowError[] errs = result.getRowErrors() ;
for(RowError er : errs){
System.out.println(er);
}
}
}finally {
if(null!=client){
client.shutdown();
}
}
}
查询数据
@Test
public void testSelect() throws KuduException {
//1、获得kudu客户端
KuduClient client = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
//2、打开表
KuduTable table = client.openTable("users") ;
//3、扫描器
KuduScanner scanner = null;
try {
//4、获取表结构
Schema schema = table.getSchema() ;
//5、指定查询条件
List<String> projectColumns = new ArrayList<String>(2);
projectColumns.add("uid");
projectColumns.add("name");
projectColumns.add("age");
//age >= 0
int lowerBound = 0;
KuduPredicate lowerPred =
KuduPredicate.newComparisonPredicate(schema.getColumn("age"),
KuduPredicate.ComparisonOp.GREATER_EQUAL, lowerBound);
//age < 10
int upperBound = 10;
KuduPredicate upperPred =
KuduPredicate.newComparisonPredicate(schema.getColumn("age"),
KuduPredicate.ComparisonOp.LESS, upperBound);
scanner = client.newScannerBuilder(table)
.setProjectedColumnNames(projectColumns)
.addPredicate(lowerPred)
.addPredicate(upperPred)
.build();
int resultCount = 0;
while (scanner.hasMoreRows()) {
RowResultIterator results = scanner.nextRows();
while (results.hasNext()) {
RowResult result = results.next();
byte uid = result.getByte("uid");
String name = null ;
if (result.isNull("name")) {
name = "不存在" ;
}
else{
name = result.getString("name") ;
}
byte age = result.getByte("age");
System.out.printf("uid=%d, name=%s, age=%drn" , uid
,name,age);
resultCount++;
}
}
System.out.println("-----------------------"+resultCount);
scanner.close() ;
}finally {
if(null!=client){
client.shutdown();
}
}
}
修改表结构
@Test
public void testAlterTable() throws Exception {
//1、获得kudu客户端
KuduClient client = null;
try {
//2、修改表选项
AlterTableOptions ato = new AlterTableOptions() ;
ato.addColumn("wage" , Type.DOUBLE , 10000.000) ;
//3、修改表结构
client = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
if(client.tableExists("users")){
client.alterTable("users" , ato) ;
System.out.println("........alterTable success..........");
}
}finally {
//4、关闭资源
if(null!=client){
client.shutdown();
}
}
}
修改完再次查询:
@Test
public void testSelect2() throws KuduException {
//1、获得kudu客户端
KuduClient client = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
//2、打开表
KuduTable table = client.openTable("users") ;
//3、扫描器
KuduScanner scanner = null;
try {
//4、获取表结构
Schema schema = table.getSchema() ;
//5、指定查询条件
List<String> projectColumns = new ArrayList<String>(2);
projectColumns.add("uid");
projectColumns.add("name");
projectColumns.add("age");
projectColumns.add("wage");
//age >= 0
int lowerBound = 0;
KuduPredicate lowerPred =
KuduPredicate.newComparisonPredicate(schema.getColumn("age"),
KuduPredicate.ComparisonOp.GREATER_EQUAL, lowerBound);
//age < 10
int upperBound = 10;
KuduPredicate upperPred =
KuduPredicate.newComparisonPredicate(schema.getColumn("age"),
KuduPredicate.ComparisonOp.LESS, upperBound);
scanner = client.newScannerBuilder(table)
.setProjectedColumnNames(projectColumns)
.addPredicate(lowerPred)
.addPredicate(upperPred)
.build();
int resultCount = 0;
while (scanner.hasMoreRows()) {
RowResultIterator results = scanner.nextRows();
while (results.hasNext()) {
RowResult result = results.next();
byte uid = result.getByte("uid");
String name = null ;
if (result.isNull("name")) {
name = "不存在" ;
}
else{
name = result.getString("name") ;
}
byte age = result.getByte("age");
double wage = result.getDouble("wage");
System.out.printf("uid=%d, name=%s, age=%d, wage=%frn" , uid
,name,age,wage);
resultCount++;
}
}
System.out.println("-----------------------"+resultCount);
scanner.close() ;
}finally {
if(null!=client){
client.shutdown();
}
}
}
更新数据
@Test
public void testUpdate() throws Exception {
//1、获得kudu客户端
KuduClient client = null;
//2、打开表
KuduTable table = null;
//3、会话
KuduSession session = null;
try {
client = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
table = client.openTable("users");
session = client.newSession();
//4、创建并执行update操作
Update update = table.newUpdate();
PartialRow row = update.getRow();
row.addByte("uid", Byte.parseByte("1"+""));
row.addDouble("wage", 20000.000);
session.apply(update);
session.close();
}finally {
//5、关闭资源
if(null!=client){
client.shutdown();
}
}
}
删除数据
@Test
public void testDelete() throws Exception {
//1、获得kudu客户端
KuduClient client = null;
//2、打开表
KuduTable table = null;
//3、会话
KuduSession session = null;
try {
client = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
table = client.openTable("users");
session = client.newSession();
//4、新建并执行Delete操作
Delete delete = table.newDelete();
//得到row
PartialRow row = delete.getRow();
//where key = 0
row.addByte("uid", Byte.parseByte(3+""));
session.apply(delete);
session.close();
}finally {
//5、关闭资源
if(null!=client){
client.shutdown();
}
}
}
更新和插入
@Test
public void testUpsert() throws Exception {
//1、获得kudu客户端
KuduClient client = null;
//2、打开表
KuduTable table = null;
//3、会话
KuduSession session = null;
try {
client = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
table = client.openTable("users");
session = client.newSession();
//4、upsert
Upsert upsert = table.newUpsert();
PartialRow row = upsert.getRow();
row.addByte("uid", Byte.parseByte(3+""));
row.addString("name", "tomasLee");
row.addByte("age", Byte.parseByte(35+""));
row.addDouble("wage", 18000.000);
session.apply(upsert);
Upsert upsert1 = table.newUpsert();
PartialRow row1 = upsert1.getRow();
row1.addByte("uid", Byte.parseByte(1+""));
row1.addByte("age", Byte.parseByte(8+""));
row1.addDouble("wage", 15000.000);
session.apply(upsert1);
session.close();
}finally {
//5、关闭资源
if(null!=client){
client.shutdown();
}
}
}
注意:Upsert主键一样则更新,否则为新增,不能为空的字段必须提供值,否则不执行。
删除表
@Test
public void testDeleteTable() throws KuduException {
//1、创建KuduClient
KuduClient client = null;
try {
client = new KuduClient.KuduClientBuilder(KUDU_MASTERS).build();
//2、删除表
if(client.tableExists("users")){
client.deleteTable("users");
System.out.println("........delete table success..........");
}
}finally {
//3、关闭资源
if(null!=client){
client.shutdown();
}
}
}
其他语言编程接口
请参看官方exaples:https://github.com/apache/kudu/tree/master/examples
Hadoop生态整合
整合概述
Kudu除了支持高吞吐离线分析(类似HDFS)和高并发随机读写(类似HBase),还可以整合主流分布式计算框架进行离线运算和即系查询,常见整合方案如下:
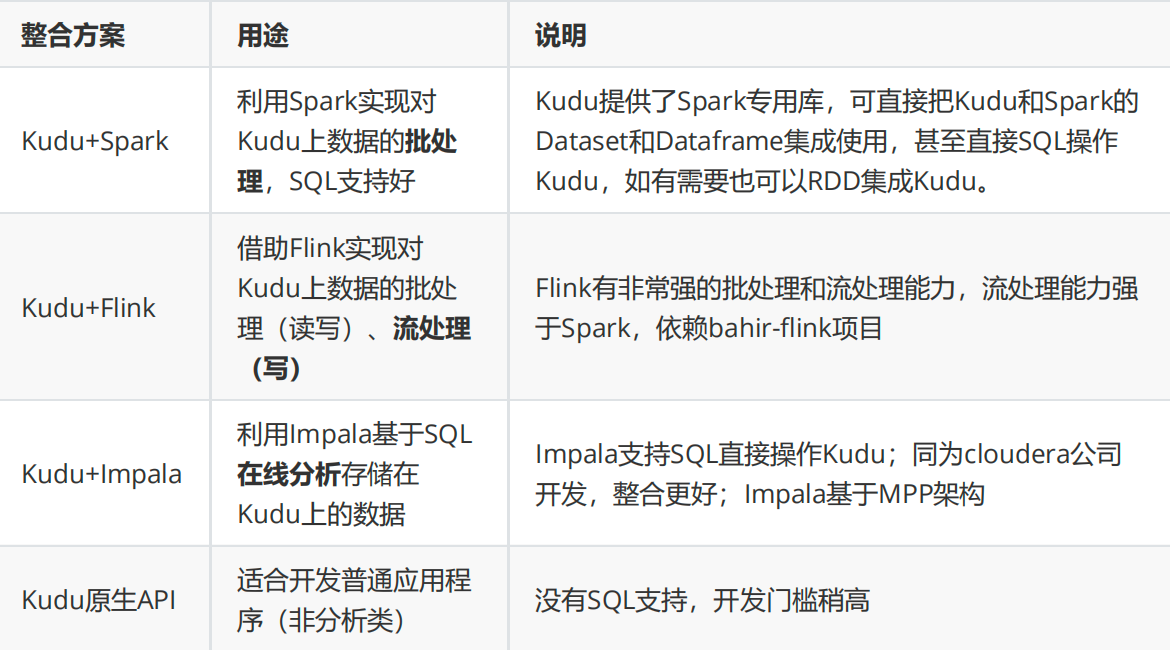
根据上表的总结,大家可以结合自己业务实际情况去选择整合方式,没有好坏之分。
集成Spark
Spark shell中操作Kudu
在Spark shell中可以轻松操作Kudu,不过这种方式不常用,参考链接如下:
https://kudu.apache.org/releases/1.10.0/docs/developing.html#_kudu_integration_with_spark
代码整合Kudu+Spark-项目准备
(1)修改pom.xml,最中内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.djt</groupId>
<artifactId>kudu_tutorial</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<kudu.version>1.10.0</kudu.version>
<junit.version>4.12</junit.version>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.3</spark.version>
</properties>
<dependencies>
<!-- Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- kudu-spark -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_2.11</artifactId>
<version>${kudu.version}</version>
</dependency>
<!-- Kudu client -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>${kudu.version}</version>
</dependency>
<!-- Log -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.12</version>
</dependency>
<!-- Unit test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<!-- 指定具体仓库 -->
<repositories>
<repository>
<id>cdh.repo</id>
<name>Cloudera Repositories</name>
<url>https://repository.cloudera.com/content/repositories/releases</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>
(2)准备数据文件
在项目根目录创建目录dataset,并把数据文件students100k放进去:
(3)准备代码骨架
跟java目录平行创建一个目录scala:
将scala目录设置为sources root:
创建Scala类com.djt.kudu.spark.KuduSparkDemo:
package com.djt.kudu.spark
import org.junit.Test
class KuduSparkDemo {
@Test
def test(): Unit = {
println("hello kudu spark!")
}
}
直接运行能正常输出,项目就准备好了。
DDL
首先,我们定义一个常量KUDU_MASTERS存放Kudu master的连接信息:
//master连接信息
val KUDU_MASTERS = "node01:7051,node02:7051,node03:7051"
接下来,我们创建case class Student,它的字段信息必须跟我们前面数据文件students100k相匹配:
case class Student(sid: Int, name: String, gender: String, age: Int, height: Float, weight: Float)
@Test
def ddl(): Unit = {
// 1. SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("KuduSparkDemo")
.getOrCreate()
//2 创建 KuduContext
val kuduContext = new KuduContext(KUDU_MASTERS, spark.sparkContext)
//3、判断表是否存在, 如果存在则删除表
val TABLE_NAME = "students"
if (kuduContext.tableExists(TABLE_NAME)) {
kuduContext.deleteTable(TABLE_NAME)
}
//4. 定义一张Kudu表:students
//4.1 定义字段信息
val schema = StructType(
List(
StructField("sid", IntegerType, nullable = false),
StructField("name", StringType, nullable = false),
StructField("gender", StringType, nullable = false),
StructField("age", IntegerType, nullable = false),
StructField("height", FloatType, nullable = false),
StructField("weight", FloatType, nullable = false)
)
)
//4.2 定义主键(rowkey)
val keys = Seq("sid")
//4.3 定义分区信息
import scala.collection.JavaConverters._
val numBuckets = 6
val options = new CreateTableOptions()
.addHashPartitions(List("sid").asJava,numBuckets)
.setNumReplicas(1)
//5. 创建一张Kudu表:students
kuduContext.createTable(tableName = TABLE_NAME,
schema = schema,
keys = keys,
options = options)
//6、关闭资源
spark.close()
}
CUD
@Test
def cud(): Unit = {
// 1、SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("KuduSparkDemo")
.getOrCreate()
//2、创建 KuduContext
val kuduContext = new KuduContext(KUDU_MASTERS, spark.sparkContext)
// 3. 增加
import spark.implicits._
val df = Seq(Student(8, "王荣", "F", 19, 164.4f, 116.5f), Student(9, "李晓",
"F", 18, 174.4f, 126.5f)).toDF()
val TABLE_NAME = "students"
kuduContext.insertRows(df, TABLE_NAME)
// 4. 删除
kuduContext.deleteRows(df.select($"sid"), TABLE_NAME)
// 5. 增或改
kuduContext.upsertRows(df, TABLE_NAME)
// 6. 修改
kuduContext.updateRows(df, TABLE_NAME)
//7、关闭资源
spark.close()
}
用如下命令以验证结果(换成自己的主机名或者IP):
kudu table scan node01:7051,node02:7051,node03:7051 students
批处理读写Kudu
1)批量写
@Test
def batchWrite(): Unit = {
// 1.SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("KuduSparkDemo")
.getOrCreate()
// 2.定义数据schema
val schema = StructType(
List(
StructField("sid", IntegerType, nullable = false),
StructField("name", StringType, nullable = false),
StructField("gender", StringType, nullable = false),
StructField("age", IntegerType, nullable = false),
StructField("height", FloatType, nullable = false),
StructField("weight", FloatType, nullable = false)
)
)
// 3.从csv读取数据
val studentsDF = spark.read
.option("header", value = true)
.option("delimiter", value = "t")
.schema(schema)
.csv("dataset/students100k")
// 4.写入Kudu
val TABLE_NAME = "students"
studentsDF.write
.option("kudu.table", TABLE_NAME)
.option("kudu.master", KUDU_MASTERS)
.mode(SaveMode.Append)
.format("kudu")
.save()
//5.回收资源
spark.close()
}
2)SQL分析(批量读)
@Test
def batchRead(): Unit = {
// 1.SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("KuduSparkDemo")
.getOrCreate()
// 2.从kudu表读取数据到DataFrame
val TABLE_NAME = "students"
val studentsDF = spark.read
.option("kudu.table", TABLE_NAME)
.option("kudu.master", KUDU_MASTERS)
.format("kudu")
.load()
// 3.直接使用Spark API查询
//studentsDF.select("sid","name", "gender", "age").filter("sid >= 5 and sid<=10").show()
// 3.基于DataFrame创建临时视图(临时表)
studentsDF.createOrReplaceTempView("students")
// 4.执行sql查询
//val projectDF = spark.sql("select sid, name, gender, age from students where age <= 19 and height > 180")
val projectDF = spark.sql("select gender, count(), max(height) ,min(height), avg(height) from students where age <= 19 and height > 180 group by gender")
//5.打印结果
projectDF.show()
//6.关闭资源
spark.close()
}
特别注意
-
每个集群避免多KuduClient
常见错误就是创建了多个KuduClient对象。在kudu-spark中,KuduClient对象由KuduContext所持有。对于同一kudu集群,不应该创建多个KuduClient对象,而是应该通过KuduContext访问KuduClient,方法为KuduContext.syncClient。
-
存在问题和限制
- Spark2.2+需要Java8支持,尽管Kudu Spark2.x兼容Java 7。Spark 2.2 默认依赖Kudu1.5.0。
- Kudu表如果包含大写或非ascii字符的话,注册临时表时需要指定其他的名字。
- 列名如果含有大写或非ascii字符的,不能在Spark SQL中使用,否则必须重命名。
- <>或or操作不会推送到kudu执行,而是最终由Spark的task来计算。只有以通配结尾的like运算才会推送到kudu执行,比如like foo%,但是like foo%bar则不会推送给Kudu。
- 并不是Spark SQL中的每种类型Kudu都支持,Date和Complex类型就不支持。
- Kudu表在Spark SQL中只能注册成临时表,不能使用HiveContext访问。
集成Flink
集成说明
在Spark和Flink先后崛起之后,开始与Hadoop生态中的各个组件整合(官方或者第三方)。Apache Bahir就是一个第三方项目,它对Spark和Flink进行扩展以便于它们整合其他组件(主要针对流处理)。
以下是Apache Bahir的官网:
http://bahir.apache.org/
Apache Bahir对Flink的支持以子项目bahir-flflink的方式提供,以下是它的github主页:
https://github.com/apache/bahir-flflink
我们就基于bahir-flflink来整合Kudu+Flink,目前支持:
- 批处理读和写
- 流处理写(流处理读一般只针对消息队列,对于存储流处理读意义不大)
编译bahir-flflink
bahir-flflink目前1.0版还没正式发布,刚到1.0-rc5,且不支持Kudu。1.1版开始支持Kudu,目前还在1.1-SNAPSHOT版(Kudu1.10.0和Flink1.9.0),因此我们需要自己编译,且一定要在Linux或者MacOS下编译:
编译并安装到maven本地仓库:
git clone https://github.com/apache/bahir-flink.git
cd bahir-flink/
mvn -DskipTests -Drat.skip=true clean install
执行完之后,我们去maven本地仓库查看:

如果有些依赖包实在下载不下来导致编译不过的话,可以使用老师提供的编译好的包直接安装到maven本地仓库即可:
mvn install:install-file -DgroupId=org.apache.bahir -DartifactId=flink-connector-kudu_2.11 -Dversion=1.1-SNAPSHOT -Dpackaging=jar -Dfile=./flink-connector-kudu_2.11-1.1-SNAPSHOT.jar
项目准备
修改pom.xml,最终内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.djt</groupId>
<artifactId>kudu-tutorial</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<kudu.version>1.10.0</kudu.version>
<junit.version>4.12</junit.version>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.3</spark.version>
<flink.version>1.9.0</flink.version>
<flink-connector.version>1.1-SNAPSHOT</flink-connector.version>
</properties>
<dependencies>
<!-- bahir-flink -->
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-kudu_2.11</artifactId>
<version>${flink-connector.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- kudu-spark -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_2.11</artifactId>
<version>${kudu.version}</version>
</dependency>
<!-- Kudu client -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>${kudu.version}</version>
</dependency>
<!-- Log -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.12</version>
</dependency>
<!-- Unit test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<!-- 指定具体仓库 -->
<repositories>
<repository>
<id>cdh.repo</id>
<name>Cloudera Repositories</name>
<url>https://repository.cloudera.com/content/repositories/releases</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>
骨架代码:
package com.djt.kudu.flink;
public class KuduFlinkDemo {
public static void main(String[] args) {
System.out.println("hello kudu flink!");
}
}
运行能正常输出就OK了。
批处理读写
(1)批处理读
批处理读需要开启Kudu安全,这里就不做演示了。
批处理读使用KuduInputFormat,代码如下:
@Test
public void testBatchRead() throws Exception {
//1、初始化执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//2、构建数据处理逻辑(输入-->处理--输出)
//2.1 输入(读取kudu的students表)
//a、创建KuduReaderConfig
KuduReaderConfig kuduReaderConfig = KuduReaderConfig.Builder
.setMasters(KUDU_MASTERS)
.build();
//b、创建KuduTableInfo
KuduTableInfo tableInfo = KuduTableInfo.Builder
.create("students")
.replicas(1)
.addColumn(KuduColumnInfo.Builder.create("sid",
Type.INT32).key(true).hashKey(true).build())
.addColumn(KuduColumnInfo.Builder.create("name", Type.STRING).build())
.addColumn(KuduColumnInfo.Builder.create("gender", Type.STRING).build())
.addColumn(KuduColumnInfo.Builder.create("age", Type.INT32).build())
.addColumn(KuduColumnInfo.Builder.create("height", Type.FLOAT).build())
.addColumn(KuduColumnInfo.Builder.create("weight", Type.FLOAT).build())
.build();
//c、创建反序列化器KuduDeserialization
KuduDeserialization serDe = new PojoSerDe(Student.class);
//d、组装过滤条件
List<KuduFilterInfo> tableFilters = new ArrayList<>();
tableFilters.add(KuduFilterInfo.Builder.create("age").greaterThan(18).build());
tableFilters.add(KuduFilterInfo.Builder.create("age").lessThan(20).build());
//e、指定要返回的列
List<String> tableProjections = Arrays.asList("sid", "age");
//f、组装KuduInputFormat
DataSet<Student> result = env.createInput(new KuduInputFormat(kuduReaderConfig, tableInfo, serDe, new ArrayList<>(), tableProjections), TypeInformation.of(Student.class));
//2.2 处理(包含输出)
result.count();
//3、执行job(延迟执行)
env.execute();
}
(2)批处理写
@Test
public void testBatchWrite() throws Exception {
//1、初始化执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//2、构建数据处理逻辑(输入-->处理--输出)
//2.1 输入
DataSet<Student> originData= env.readCsvFile("dataset/students100k")
.fieldDelimiter("t")
.ignoreFirstLine()
.ignoreInvalidLines()
.pojoType(Student.class,"sid","name","gender","age","height","weight");
//2.2 处理(咱们不处理)
//2.3 输出(kudu 表)
//a、创建KuduWriterConfig
KuduWriterConfig writerConfig=KuduWriterConfig.Builder
.setMasters(KUDU_MASTERS)
.setWriteMode(KuduWriterMode.UPSERT)
.setConsistency(SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND)
.build();
//b、创建KuduTableInfo
KuduTableInfo tableInfo = KuduTableInfo.Builder
.create("students1")
.replicas(1)
.addColumn(KuduColumnInfo.Builder.create("sid",
Type.INT32).key(true).hashKey(true).build())
.addColumn(KuduColumnInfo.Builder.create("name", Type.STRING).build())
.addColumn(KuduColumnInfo.Builder.create("gender", Type.STRING).build())
.addColumn(KuduColumnInfo.Builder.create("age", Type.INT32).build())
.addColumn(KuduColumnInfo.Builder.create("height", Type.FLOAT).build())
.addColumn(KuduColumnInfo.Builder.create("weight", Type.FLOAT).build())
.build();
//c、创建KuduSerialization
KuduSerialization serDe=new PojoSerDe(Student.class);
//d、装配KuduOutputFormat
originData.output(new KuduOutputFormat(writerConfig, tableInfo, serDe));
//3、执行job(延迟执行)
env.execute();
}
流处理写
直接使用KuduSink:
@Test
public void testKuduSink() throws Exception {
List<Student> list = Arrays.asList(
new Student(1, "张三", "F", 19, 176.3f, 134.4f),
new Student(2, "李四", "F", 20, 186.3f, 154.8f)
);
//1、初始化执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//2、构建数据处理逻辑(输入-->处理--输出)
//2.1 输入
DataStream<Student> originData = env.fromCollection(list);
//2.2 处理(咱们不处理)
//2.3 输出(kudu 表)
//a、创建KuduWriterConfig
KuduWriterConfig writerConfig=KuduWriterConfig.Builder
.setMasters(KUDU_MASTERS)
.setWriteMode(KuduWriterMode.UPSERT)
.setConsistency(SessionConfiguration.FlushMode.AUTO_FLUSH_BACKGROUND)
.build();
//b、创建KuduTableInfo
KuduTableInfo tableInfo = KuduTableInfo.Builder
.create("students1")
.replicas(1)
.addColumn(KuduColumnInfo.Builder.create("sid",
Type.INT32).key(true).hashKey(true).build())
.addColumn(KuduColumnInfo.Builder.create("name", Type.STRING).build())
.addColumn(KuduColumnInfo.Builder.create("gender", Type.STRING).build())
.addColumn(KuduColumnInfo.Builder.create("age", Type.INT32).build())
.addColumn(KuduColumnInfo.Builder.create("height", Type.FLOAT).build())
.addColumn(KuduColumnInfo.Builder.create("weight", Type.FLOAT).build())
.build();
//c、创建KuduSerialization
KuduSerialization serDe=new PojoSerDe(Student.class);
//d、装配KuduSink
originData.addSink(new KuduSink(writerConfig,tableInfo,serDe));
//3、执行job(延迟执行)
env.execute();
}
集成Impala
各组件之间的关系
Kudu整合Impala依赖很多组件,这里有一张组件关系图如下:
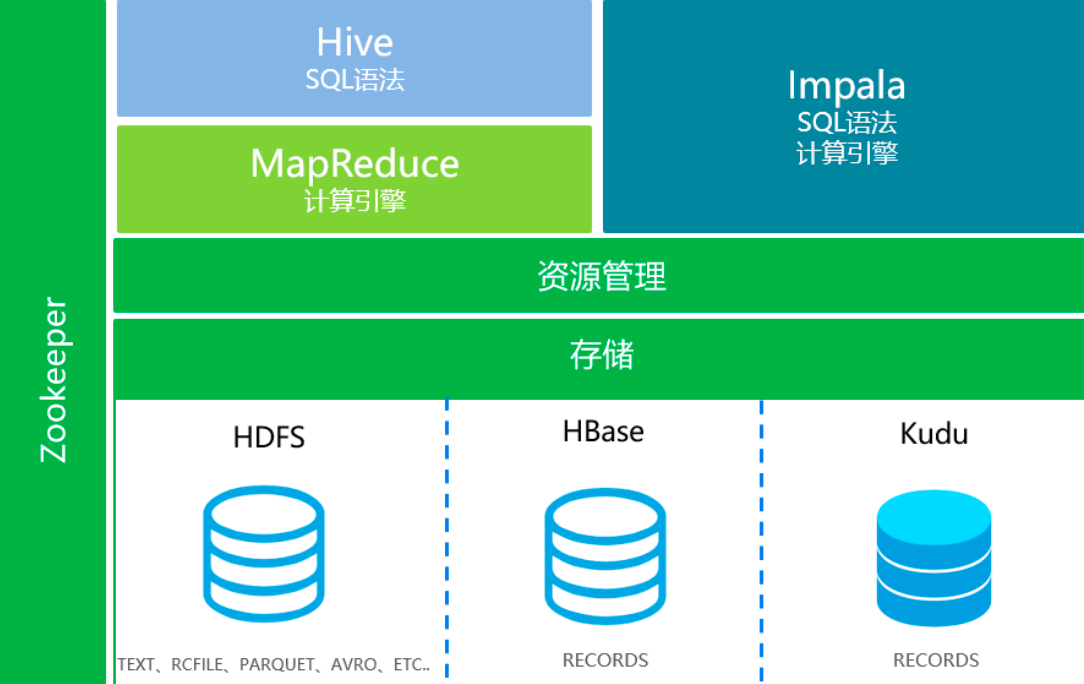
通过上图我们分析结论如下:
- impala依赖Hive
- Hive依赖Hadoop
- Hive依赖MySQL存储元数据
- Hadoop依赖Zookeeper
- 基本都离不开JDK
因此,相关组件我们需要先安装。
环境准备
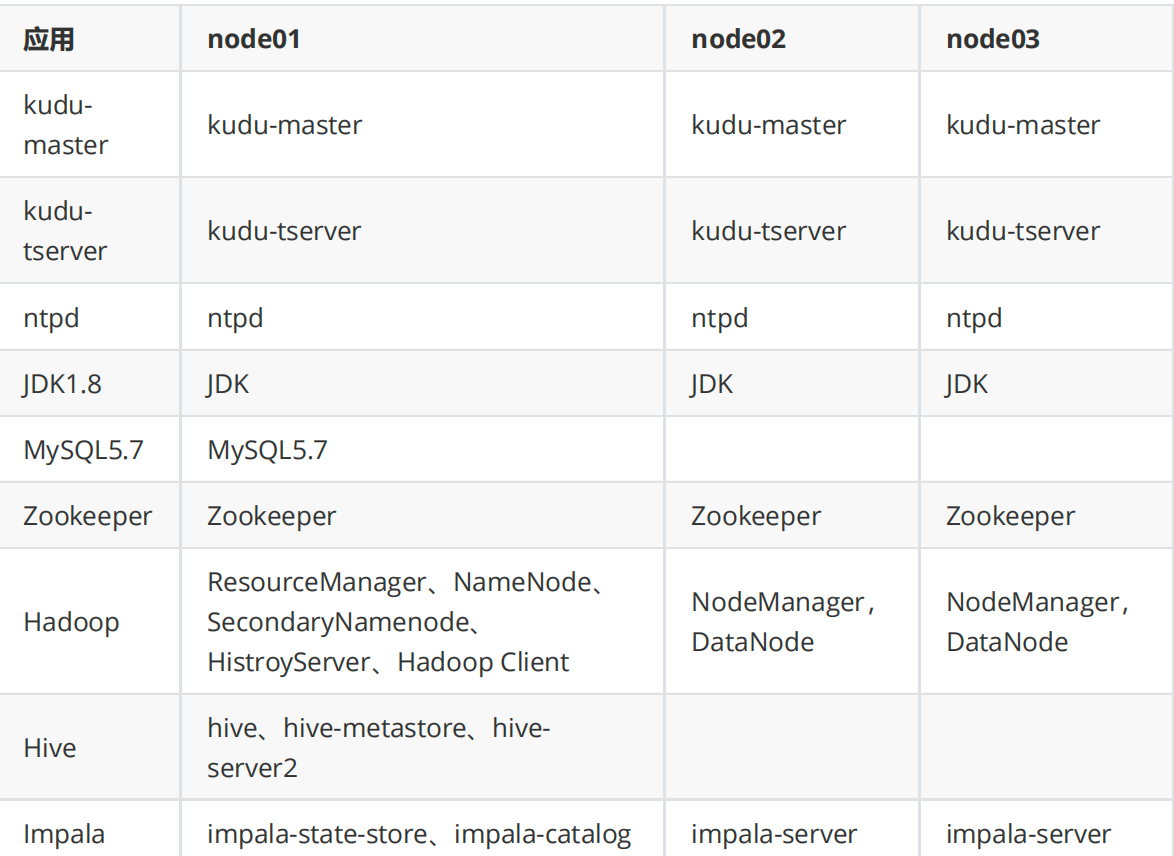
部署规划方案是:
具体安装省略。
为什么整合Kudu+Impala
Kudu作为高性能的分布式存储同时兼具HDFS和HBase的能力确实能够解决很多业务问题,但是Kudu没有SQL语法支持限制它的使用门槛,因此 Cloudra官方专门把Impala和Kudu做了整合,因此他们的分工是:
- Kudu负责存储
- Impala负责计算(用SQL语法分析存储在Kudu表里的数据)
Impala对外支持两种场景:
- 基于Impala替代Kudu API开发上层应用(可以但不推荐)
- Impala作为中间层提供JDBC/ODBC跟上层BI或者其他框架整合(推荐)
怎么整合Kudu+Impala
何为整合?让Impala认识并能操作Kudu中的表(内部表/外部表均可):

Kudu跟Impala的整合非常简单,可总结为两点:
-
Kudu这边什么配置都不用改,它就等着Impala来访问
-
Impala那边有两种方式来访问Kudu
方式一:每次在Impala中建内部表/外部表时指定Kudu Master(不推荐)
例如:
CREATE EXTERNAL TABLE `users` STORED AS KUDU TBLPROPERTIES( 'kudu.table_name' = 'users', 'kudu.master_addresses' = 'node01:7051,node02:7051,node03:7051')方式二:在Impal的默认配置中指定Kudu Master+内部表/外部表:
在/etc/default/impala中指定:
--kudu_master_hosts=<master1>[:port],<master2>[:port],<master3>[:port]
整合Kudu+Impala
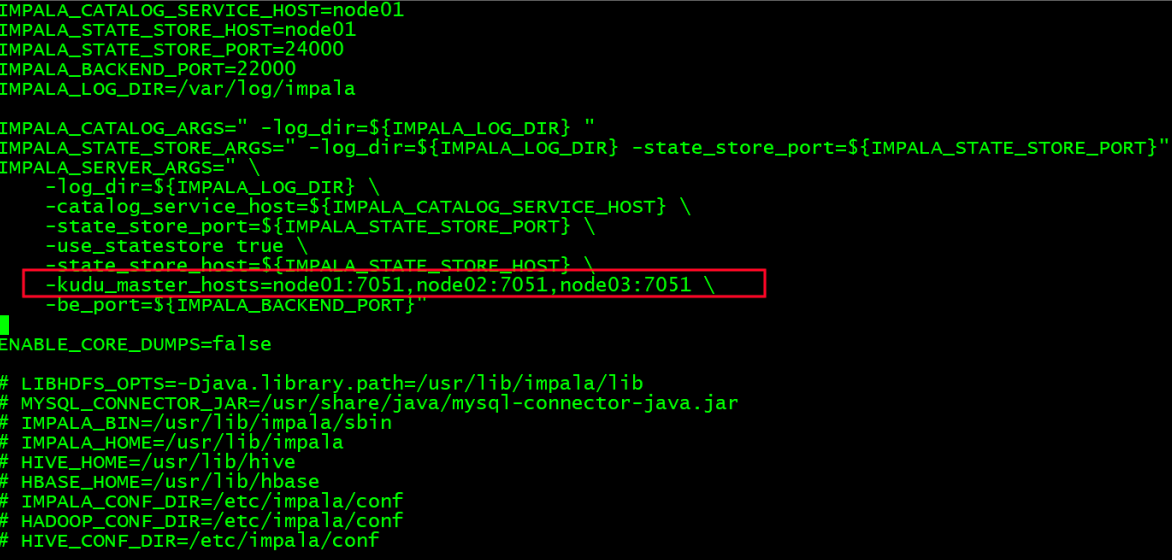
(1)配置Kudu Master地址
在Impala中配置Kudu Master地址(所有节点):
sudo vi /etc/default/impala
在 IMPALA_SERVER_ARGS 下添加如下配置:
--kudu_master_hosts=<master1>[:port],<master2>[:port],<master3>[:port]
(2)重启所有Impala服务
node01重启state-store和catalog:
sudo service impala-state-store restart
sudo service impala-catalog restart
node02和node03上重启impala-server:
sudo service impala-server restart
Impala Shell中操作Kudu
(1)登录Impala-shell
我们在node01上安装了impala-shell,因此在node01上执行如下命令:
impala-shell -i node02:21000
这时就进入了impala-shell:
(2)表映射
Impala可以操作很多表:
- Kudu表
- HBase表
- Hive表(各种存储格式:Text、ORC、Parquet等等)
- 等等
Impala要想操作Kudu表,有两种方式:
-
外部表
所谓外部表是指Kudu那边已经建好表了,我们把Kudu表映射为一张Impal表即可,删除表时只删映射关系,Kudu那边的表还在。以前面创建的表students1为例,只需要在impala-shell中创建一个外部表即可:
CREATE EXTERNAL TABLE `students1` STORED AS KUDU TBLPROPERTIES( 'kudu.table_name' = 'students1');或者在指定数据库下创建外表:
CREATE DATABASE IF NOT EXISTS test; CREATE EXTERNAL TABLE test.users STORED AS KUDU TBLPROPERTIES( 'kudu.table_name' = 'users'); -
内部表
所谓内部表,它跟外部表正好相反,是指在Impala中创建一张表存储为Kudu格式,例如:
CREATE TABLE my_first_table ( id BIGINT, name STRING, PRIMARY KEY(id) ) PARTITION BY HASH PARTITIONS 16 STORED AS KUDU TBLPROPERTIES ('kudu.num_tablet_replicas' = '1');这时他会自动在Kudu中也创建一个表:
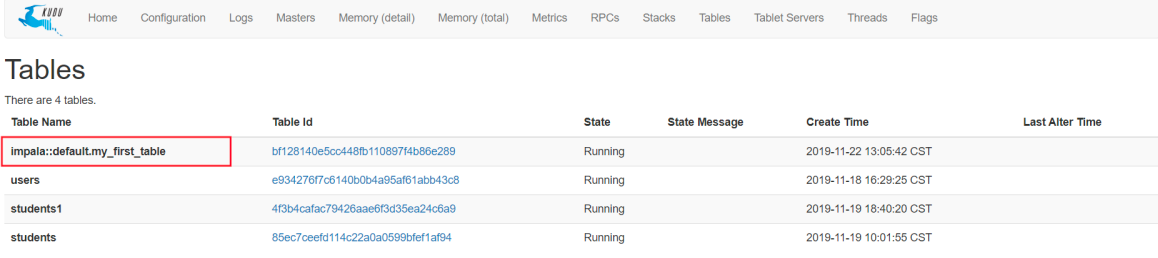
注意:删除内部表,Kudu中的表是会删除的。
(3)查询
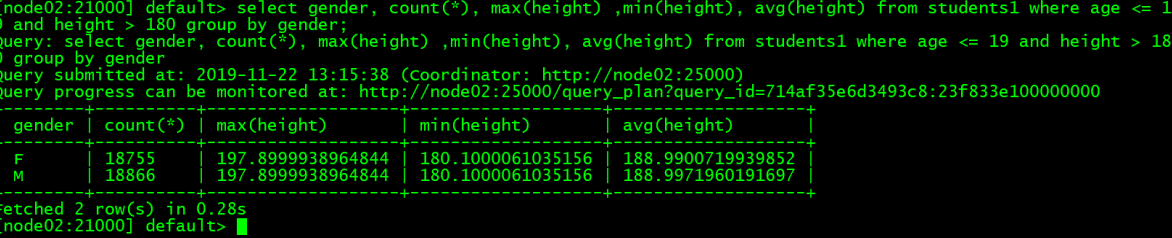
查询就是SQL语法,大家可以自行尝试,例如:
select gender, count(), max(height) ,min(height), avg(height) from students1 where age <= 19 and height > 180 group by gender;
查询结果:
(4)DML
插入数据:
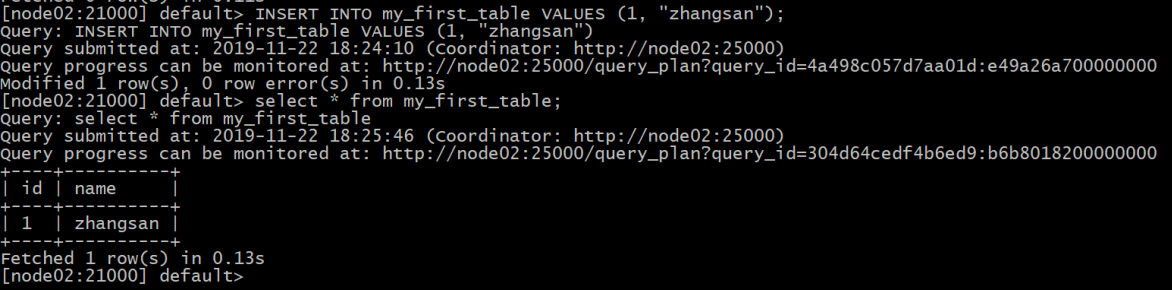
#单行插入
INSERT INTO my_first_table VALUES (1, "zhangsan");
select from my_first_table;
#多行插入
INSERT INTO my_first_table VALUES (2, "lisi"), (3, "wangwu"), (4, "zhaoliu");
select from my_first_table;
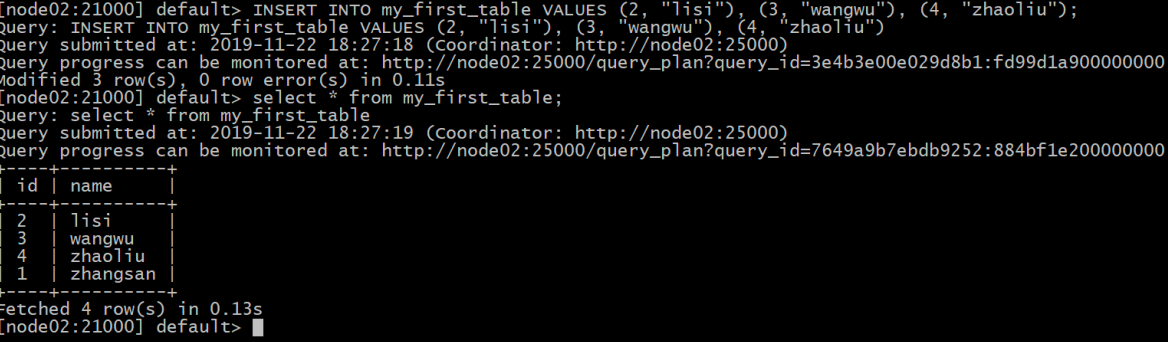
CREATE TABLE test2
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 6
STORED AS KUDU
TBLPROPERTIES ('kudu.num_tablet_replicas' = '1');
select from test2;
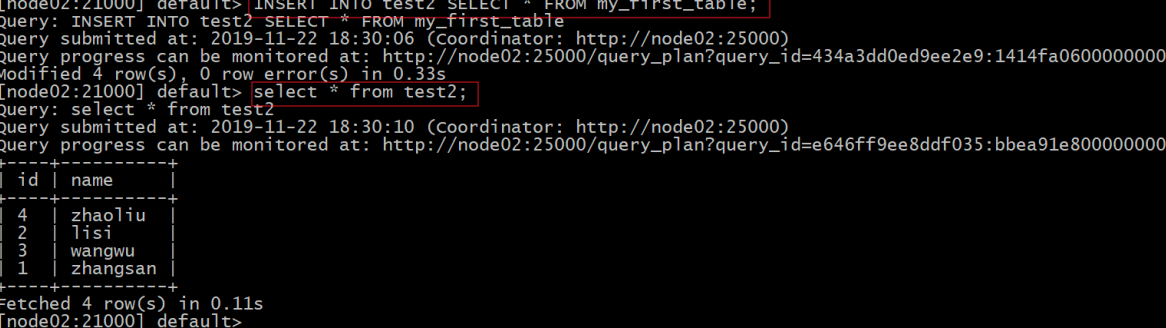
#从其它表批量导入
INSERT INTO test2 SELECT FROM my_first_table;
select from my_first_table;
更新数据:
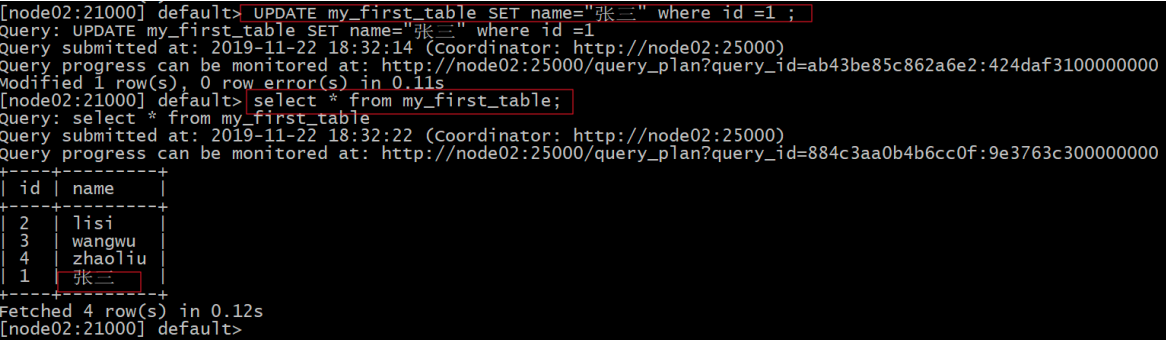
#更新
UPDATE my_first_table SET name="张三" where id =1 ;
select from my_first_table;
删除数据:
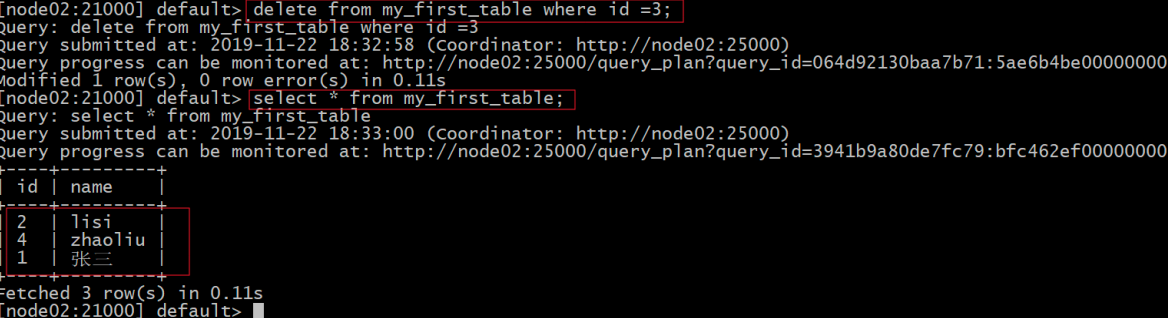
delete from my_first_table where id =3;
select from my_first_table;
(5)更改表属性
1)重命名impala内部表:
ALTER TABLE my_first_table RENAME TO person;
show tables;
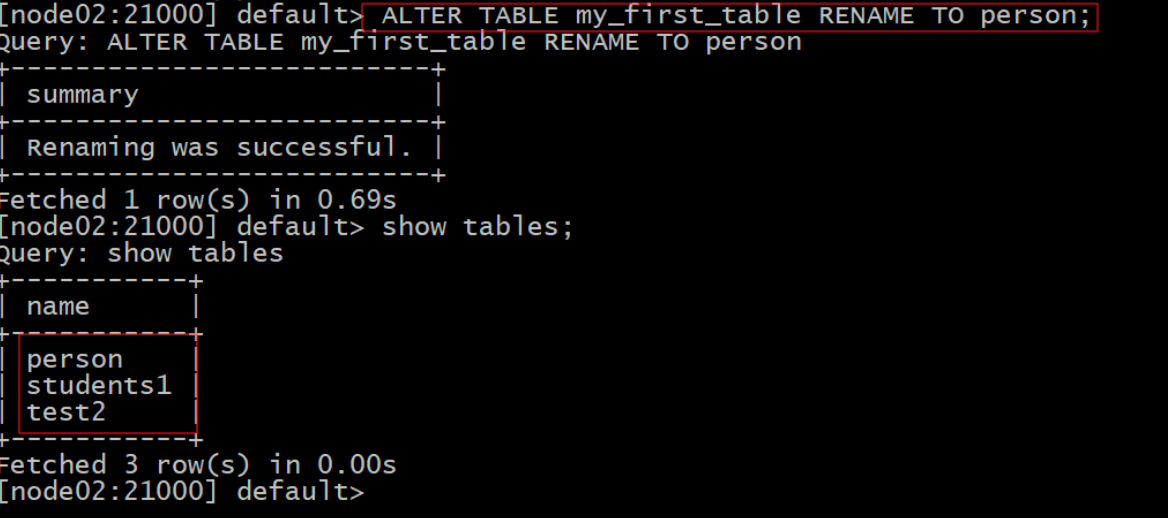
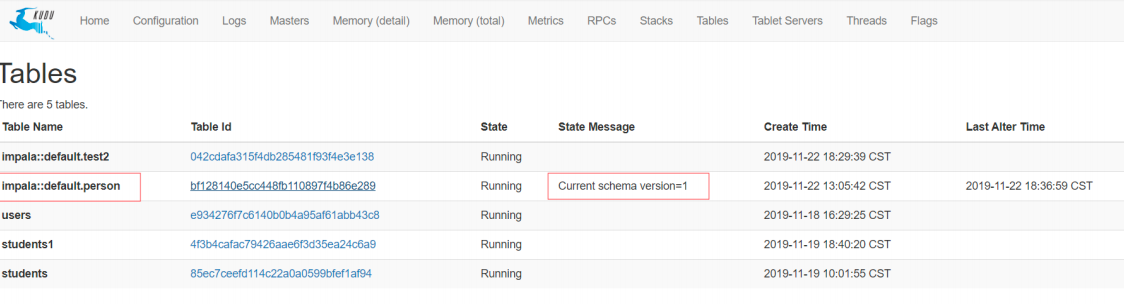
Kudu那边的表也跟着改名了:
2)重命名impala外部表:
ALTER TABLE students1 RENAME TO stus;
show tables;
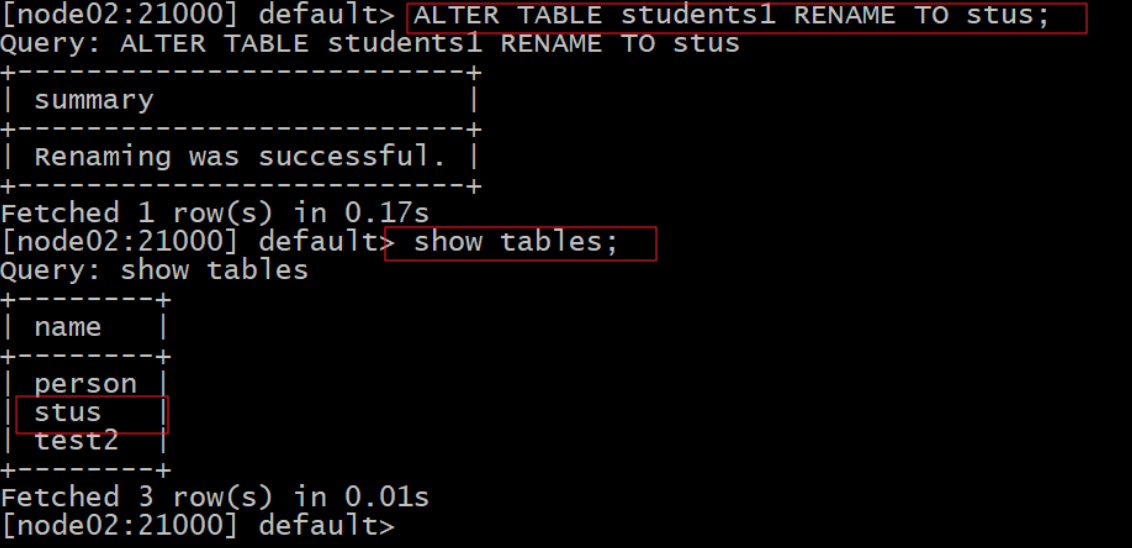
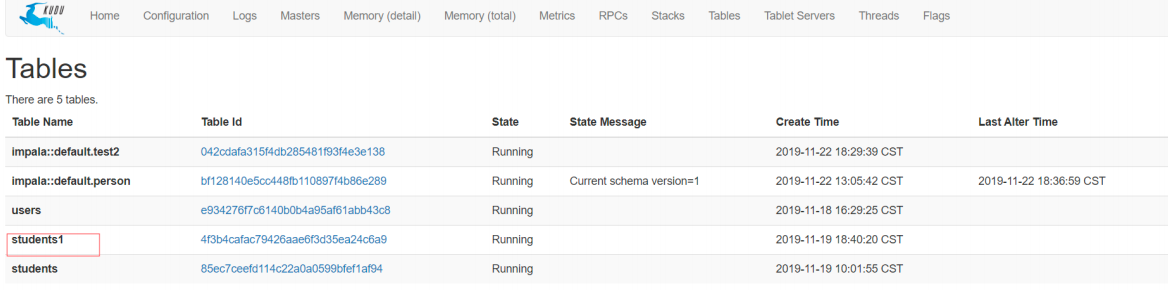
Kudu那边的表名不会跟着改变(只是改了映射):
3)将外部表重新映射kudu表
ALTER TABLE external_table
SET TBLPROPERTIES('kudu.table_name' = 'xxx')
4)将内部表改为外部表
ALTER TABLE my_table SET TBLPROPERTIES('EXTERNAL' = 'TRUE');
谓词下推
所谓谓词简单理解就是SQL的where字句中的条件判断,Impala的原理就是读取Kudu表的数据然后进行计算,如果谓词能够下推到Kudu中去执行则返回给Impala的数据将会很小,性能将大幅提升。目前:
- 支持下推的谓词: = , <= , < , > , >= , BETWEEN , IN
- 不支持下推的谓词: != , LIKE , 或者Impala中的其他谓词