1、Java语言有哪些特点?❀
(1)【面向对象】Java是一种面向对象的语言,支持封装、继承和多态等面向对象的特性。Java特别强调类和对象的关系,要求所有代码都必须位于类中。和Java一样很流行的Python也是面向对象的语言,但它对面向对象的支持更灵活、更自由,并不要求所有的代码都必须在类中
(2)【编译型】Java是一种编译型语言,需要先将源代码编译成字节码,再由Java虚拟机执行,Java虚拟机(JVM)也是Java跨平台的关键。Python则是一种解释型语言,不需要事先编译,代码逐行解释执行
(3)【健壮性】Java的强类型检查、异常处理机制和垃圾回收机制都是Java健壮性的体现。Java内置了安全性机制,如沙箱安全模型和安全类库,可以防止恶意代码的执行
(4)【大型生态系统】Java拥有丰富的类库和框架,如Java SE、Java EE和JavaFX(用于构建丰富用户界面的框架),可以支持各种不同类型的应用开发。Python也有丰富的生态系统,尤其在数据分析和科学计算领域有很高的应用价值
(5)【应用场景】Java主要被用于构建高性能的企业级应用、移动应用、Web应用等。Python则更适合用于快速开发、原型验证、数据分析、人工智能等
2、面向对象和面向过程的区别?❀
(1)面向过程是分析解决问题的步骤后,用函数把这些步骤一步一步实现,解决问题的时候依次调用这些函数。面向过程性能较高,常用于单片机、嵌入式开发。
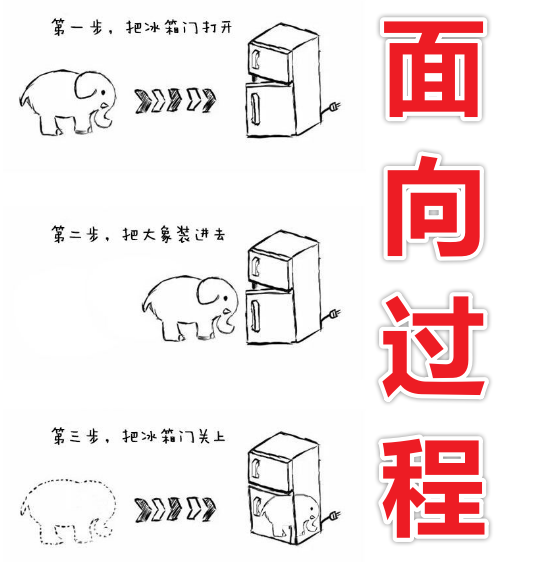
(2)面向对象是把构成问题的事务分解成各个对象,而建立对象的目的也不是为了完成一个个步骤,而是为了描述某个事物在解决整个问题的过程中所发生的行为。面向对象有封装、继承、多态等特点。所以易维护、易复用、易扩展。 但是性能上来说,比面向过程要低。
3、说一下Redis缓存的穿透、雪崩和击穿❀
【第一】穿透:客户端请求的数据在缓存中和数据库中都没有;缓存永远不生效,这些请求都到达了数据库。解决方案有:(1) 缓存空对象(优点:实现简单,维护方便;缺点:额外的内存消耗;可能造成数据短期不一致);(2) 布隆过滤,提前判断数据是否存在后才查询Redis(优点:内存占用较少,Redis 中没有多余的 key;缺点:实现复杂;存在误判可能)
【第二】雪崩:同一时段大量的缓存 key 同时失效或者 Redis 服务宕机,导致大量请求到达数据库。解决方案有:(1) 给不同的 Key 设置不同的过期时间(随机值),这样就不会同时过期了;(2) 利用 Redis 集群提高服务的高可用性(降低了服务器宕机的可能);(3) 给缓存业务添加降级限流策略(不会有很多请求到达服务器);(4) 给业务添加多级缓存
【第三】击穿(热点 key 问题):缓存击穿问题也叫热点 Key 问题;,一个被高并发访问并且缓存重建业务较复杂的 key 突然失效,无数的请求瞬间到达数据库;解决方案:(1) 互斥锁(优点:没有额外的内存消耗,保证了数据一致性,实现简单;缺点:线程需要等待,性能受影响,可能产生死锁);(2) 逻辑过期(优点:线程无需等待,性能较好;缺点:不保证数据一致性,有额外内存消耗,实现复杂)
4、为什么Java中的String是不可变的?❀
(1、每当把String对象作为方法的参数时,都会复制一份引用,而该引用所指的对象其实一直待在单一的物理位置上,从未动过。
(2)Java8中,String的字符串数据底层是通过final关键字修饰的char数组进行存储的,而被final关键字修饰的成员变量(或者说引用)是不能重新指向其他对象的。因此当用String对象进行大量拼接的时候,会有大量需要垃圾回收的中间字符串对象产生,效率极低
(3)在实际开发的时候,当要进行大量字符串的拼接操作时,一般都是使用StringBuilder,该类提供了丰富而全面的方法,包括insert()、append()、delete()、replace()、substring()、toString()
(4)String对象是不可变的。查看JDK文档你就会发现,String类中每一个看起来会修改String值的方法,实际上都是创建了一个全新的String对象,以包含修改后的字符串内容。而最初的String对象丝毫未动
(5)对于一个方法而言,参数是为该方法提供信息的,而不是想让该方法改变自己的
5、关于抽象类,你知道什么?❀
(1)抽象方法是被abstract关键字修饰的方法,它只有方法声明,没有方法实现(参数列表后面不是大括号,而是分号);抽象方法只能被定义在抽象类或接口中,抽象类就是被abstract关键字修饰的类;抽象方法不能被private关键字修饰(因为抽象方法要被子类实现,被private修饰后子类就无法实现了);抽象方法不能被static关键字修饰(因为static关键字修饰的方法是类方法,类方法是可以通过类名来调用的。但是抽象方法没有具体实现,通过类名调用抽象方法毫无意义);抽象方法不能被final关键字修饰(因为被final关键字修饰的方法是不能被子类继承的,而抽象方法必须被子类继承并实现)
(2)抽象类是被abstract关键字修饰的类,不能被final关键字修饰,不能被定义为私有的(private)。抽象类中除了可以定义抽象方法外,还可以像非抽象类一样定义成员变量、常量、嵌套类型、初始化块、非抽象方法等。抽象类不能被实例化,但可以自定义构造方法(抽象类的构造方法是让子类去调用的)。子类必须实现抽象父类的所有抽象方法,除非子类也是抽象类。
(3)抽象类的使用场景:抽取子类的公共实现到抽象父类中,必须子类单独实现的部分定义成抽象方法
6、关于接口,你知道什么?❀
(1)Java中的接口是一系列方法声明的集合,用于定义规范、定义标准;一个非抽象类通过extends关键字继承一个抽象类后,必须实现该抽象类中的所有抽象方法;一个非抽象类通过implements关键字实现一个接口后,必须实现该接口中的所有抽象方法
(2)接口中可以定义抽象方法、常量(static final)、嵌套类型;从Java8开始还可以定义默认方法、静态方法;接口中定义的内容默认就是public级别的,在接口中定义的内容可省略public【Java8的接口中定义的内容必须都是public的,Java9开始可以定义private方法】
(3)接口中不能定义成员变量,定义的都是常量,且默认就是 static final;接口中定义的方法默认就是抽象方法
(4)接口中没有构造方法,不能定义初始化块和静态初始化块,接口不能实例化
(5)接口名称可在任何使用类型的地方使用;一个类可通过implements关键字实现一个或多个接口;实现接口的类必须实现接口中定义的所有抽象方法,除非它是抽象类;如果一个类实现的多个接口中有相同的抽象方法,只需要实现此抽象方法一次;extends和implements一起使用的时候,extends写在implements的前面
(6)当父类和接口中的方法的方法签名一样的时候,子类实现接口中的抽象方法的返回值类型也必须一样
(7)一个接口可以通过extends关键字继承一个或多个接口【当多个父接口中的方法签名一样时,返回值类型也必须一样】
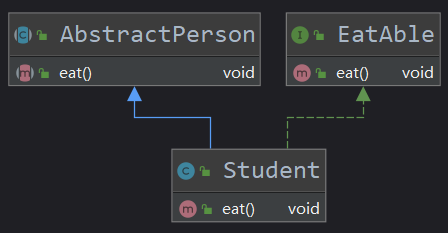
(8)接口中的default方法可实现接口的平静升级,实现类可以不实现default方法(因为default方法就是抽象方法的默认实现)
(9)默认方法只能定义在接口中,用default关键字修饰(实现类可以重写默认方法)【当一个类实现的接口中有默认方法时,该类可以:A.啥也不干,沿用接口的默认实现;B.重写默认方法的实现;C.将该类声明为抽象类,然后默认方法声明为抽象方法】【当一个接口继承的接口中有默认方法时,该接口可以:A.啥也不干,沿用接口的默认实现;B.重写默认方法的实现;C.将该默认方法声明为抽象方法】
(10)若父类定义的非抽象方法与接口的默认方法相同,最终会调用父类的方法
(11)如果抽象父类定义的抽象方法与接口的默认方法相同,要求子类必须重写此默认方法【可通过 super 调用接口的默认方法】
(12)如果父接口定义的默认方法与其他父接口定义的默认方法相同,要求子类必须重写此默认方法
(13)接口中定义的静态方法只能通过接口名调用,不能被继承
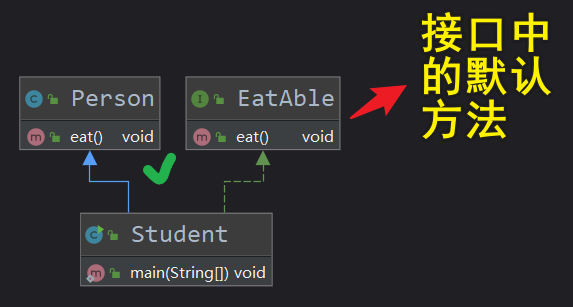
public interface Eatable {
default void eat() {
System.out.println("默认方法可以有方法实现");
}
static void eat(String food) {
System.out.println("静态方法可以有方法实现");
}
}
7、抽象类和接口的区别 ❀
(1)抽象类通常用于在紧密相关的类之间抽取公共代码【接口并没有抽取代码的功能,Java8中的接口只能定义抽象方法,没有方法的具体实现,接口中的默认方法只是抽象方法的默认实现】
(2)抽象类表达的是一种 is 关系,A extends B(A 是 B)【接口表达的是一种 have 关系,A implements B(A 有 B 中的能力)】
(3)抽象类可以有除了public之外的访问权限【接口中定义的抽象方法默认就是public权限、接口中只能定义public static final的常量、接口中定义的嵌套类也默认是public级别的】
(4)抽象类中可以定义实例变量、非final的静态变量【接口中不能定义变量、接口中定义的默认就是public static final的常量】
(5)不相关的类实现相同的方法的时候可通过接口定义规范
(7)接口可实现多重继承【抽象类只能是单继承】
(8)接口只是定义行为,不关心具体是谁实现这些行为【就像MySQL官方提供了一些连接数据库的接口,接口中有一些行为,开发者可实现MySQL的这个接口,实现了该接口就可以连接MySQL数据库】
8、为什么InnoDB存储引擎中选择使用B+树索引结构
(1)相对于二叉树或红黑树来说:顺序插入的时候,会形成链表,查询效率大大降低。大数据量情况下,层级很深,检索速度慢
(2)相对于B树(平衡二叉搜索树)来说:叶子节点和非叶子节点都会保存数据(这样会导致一页中存储的键值减少,进而指针跟着减少),要保存大量数据的时候,只能增加树的高度,会导致性能降低【B+树结构只在叶子节点存储数据,叶子节点形成单链表】
(3)相对哈希结构来说:Hash索引只能用于对等比较,不支持范围查询【MySQL加强了B+树的叶子节点,让叶子节点形成双链表,进而可进行范围查询】
9、聊一聊MySQL的索引
(1)索引是帮助MySQL高效获取数据的数据结构,可提高表数据的查询效率
(2)根据索引的底层实现,可把索引分为B+树索引、Hash索引、空间索引和全文索引。其中B+树索引在InnoDB、MyISAM、Memory等存储引擎中都支持,是最常用的索引结构
(3)根据索引的创建类型可把索引分为主键索引、唯一索引、常规索引和全文索引。主键索引是针对表中的主键约束创建的索引,假如表中有主键,主键索引会自动创建且只有一个; 唯一索引是通过表中的UNIQUE约束自动创建的索引,可以避免同一张表中某列中的值重复,一张表中可以有多个唯一索引;常规索引可以快速定位特定数据;全文索引查找的是文本中的关键字,而不是比较索引中的值,创建全文索引的关键字是FULLTEXT
B+树索引是最常见的索引结构,大部分存储引擎都支持B+树索引结构
Hash索引的底层是通过哈希表实现,,不支持范围查询【Memory存储引擎支持】
R-Tree(空间索引):空间索引是MyISAM存储引擎的一个特殊索引类型,主要用于地理空间数据结构
Full-Text(全文索引):全文索引是一种通过建立倒排索引快速匹配文档的方式(类似于ElasticSearch、Solr)【InnoDB5.6之后的版本和MyISAM存储引擎支持】
10、索引的语法
(1)查看索引
show index from 表名
(2)创建索引
create UNIQUE 或 FULLTEXT index 索引名 on 表名 (列名)
(3)删除索引
drop index 索引名 on 表名
11、索引的使用原则
(1)最左前缀法则:该法则是对联合索引来说的,创建联合索引的时候会对每个索引进行编号(如:name编号是1,score编号是2,money编号是3);查询的时候编号为1的字段(name)必须存在,否则该联合索引不会被使用(索引全部失效);假如通过name和money两个字段进行查询,name的编号是1,money的编号是3,其中跳过了编号为2的score字段,此时索引会部分失效(只有name使用了索引,money没有使用索引)
(2)范围查询右侧的列索引部分失效:在使用联合索引的时候,业务允许的情况下,使用 >= 或 <= 等操作符。不要使用 > 或 <(会导致索引部分失效)
(3)不要在索引列上进行运算操作,否则索引失效
(4)索引列是字符串类型的时候,必须使用引号包裹,否则索引失效
(5)尾部模糊查询索引不会失效,头部模糊查询索引会失效【%写在后面不会失效,写在前面会失效】
(6)or关键字组装条件的时候,必须每个字段都有索引,否则索引全部失效
(7)尽量使用覆盖索引(查询使用了索引,且需要返回的列在该索引中可以全部找到),减少使用 select *(容易回表查询)
(8)前缀索引:只用大量字符串的一部分创建索引(比如只用文章内容的前20个字符创建索引)
12、聊一聊索引的设计原则?
(1)针对于数据量较大,且查询比较频繁的表建立索引
(2)针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
(3)尽量选择区分度高的列作为索引(手机号、身份证号),尽量建立唯一索引(区分度越高,使用索引的效率越高)
(4)如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引
(5)尽量使用联合索引,减少单列索引。联合索引很多时候可以覆盖索引(查询使用了索引,且需要返回的列在该索引中可以全部找到)。联合索引可以避免回表
(6)要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率
(7)如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询
13、请描述一下IoC容器中bean的生命周期
(1) 构造方法
(2) set 方法【属性设置】
(3) BeanNameAware的setBeanName()方法【可通过该生命周期知道当前bean在IoC容器中的id】
(4) ApplicationContextAware的setApplicationContext()方法【可通过该生命周期知道当前bean存在于哪个IoC容器】
(5) BeanPostProcessor的postProcessBeforeInitialization(Object bean, String beanName)方法【可通过该生命周期统一处理所有的Bean对象(初始化方法调用之前调用)】
(6) InitializingBean的afterPropertiesSet()方法【在bean的构造方法和set方法调用完毕后调用,可初始化或加载资源】
(7) 配置文件bean标签的init-method属性【在bean的构造方法和set方法调用完毕后调用,可初始化或加载资源】
(8) BeanPostProcessor的postProcessAfterInitialization(Object bean, String beanName)方法【可通过该生命周期统一处理所有的Bean对象(初始化方法调用之后调用)】
(9) 业务方法
(10) DisposableBean的destory()方法【bean对象销毁之前调用】
(11) 配置文件bean标签的destroy-method属性【bean对象销毁之前调用】
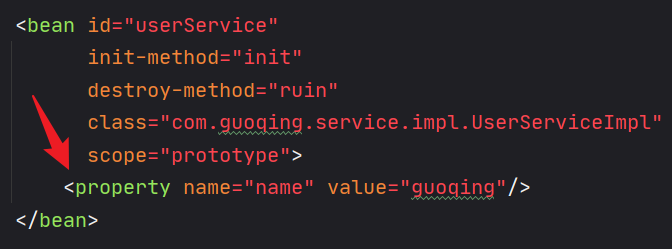
假如bean标签的scope属性值为singleton,则该bean对象受到IoC容器管理(IoC容器创建,Bean对象创建;IoC容器销毁,Bean对象销毁)。如果配置文件bean标签的scope属性值为prototype,则该bean对象不受IoC容器管理,该bean对象是被垃圾回收机制管理。当bean标签的scope属性值为singleton的时候配置文件bean标签的destroy-method属性和DisposableBean的destory()方法才有可能被调用【第10和第11个生命周期不一定会执行,除非配置文件bean标签的属性值是singleton】。
14、代理设计模式
在不修改目标类的目标方法代码的前提下,为目标方法增加额外功能。
代理类中必须也有同样的目标方法:
(1)代理类实现跟目标类同样的接口;
(2)若目标类没有实现接口,代理类继承目标类。
15、代理的实现方案
(1)静态代理(Static Proxy):开发人员手动编写代理类(创建对应的java 文件);基本上每一个目标类就要编写一个代理类
(2)动态代理(Dynamic Proxy):程序运行过程中动态生成代理类的字节码
16、动态代理的实现方案
(1)JDK自带的(代理类实现跟目标类一样的接口)
(2)开源项目CGLib(Code Generation Library):代理类继承目标类;Spring已经集成了CGLib
17、微信小程序的登录流程
首先进行微信小程序登录需要获取到小程序的appid(小程序的唯一标识)和appsecret(开发者秘钥),向微信公众平台申请的小程序后台管理中可获取到这两个参数。
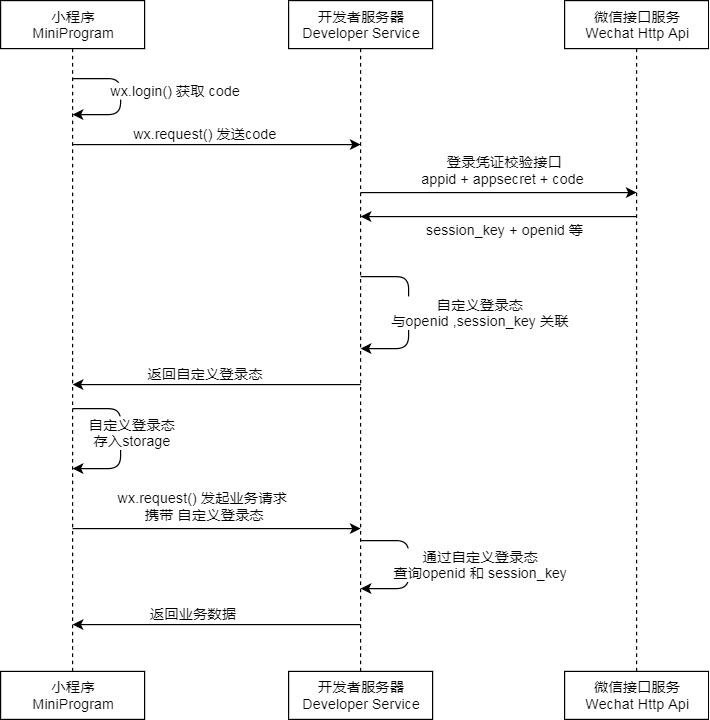
微信小程序的登录涉及到三端,分别是小程序客户端、开发者服务器端(也就是Java端)、微信接口服务端。大致流程是:第一,通过微信小程序的wx.login()函数获取code,这个code是临时登录凭证(只能使用一次);第二,通过wx.request()携带code发送请求到开发者服务端的登录接口上(该接口需要接收临时登录凭证code作为参数)。第三、开发者服务器端的接口中(Controller中)需要通过appid、appsecret和code三个参数向微信接口服务发送请求,微信接口服务会返回openid、session_key等信息(openid是每个用户的唯一凭证,session_key是对用户数据进行 加密签名 的密钥。为了应用自身的数据安全,开发者服务器不应该把会话密钥下发到小程序,也不应该对外提供这个密钥。 )。第四、通过Ehcache缓存框架或Redis缓存数据库把openid和session_key缓存到开发者服务器(通过key-value的形式把登录凭证openid和session_key缓存起来),并把key返回给小程序端。第五、在小程序端,把之前调用开发者服务器接口返回的登录凭证key 缓存到storage中。第六、之后的每次wx.request()发起业务请求都必须携带key(自定义登录态)。第七、在开发者服务器中,通过自定义登录态key从缓存中查询openid和session_key,并执行相关业务。
微信服务号授权登录的方式和微信小程序类似。只是微信服务号获取临时登录凭证不是通过wx.login()函数,而是访问某个微信提供的链接,访问该链接需要提供服务号的appid和redirect_uri,微信接口服务会回调redirect_uri的接口(该接口是Java Controller)并把code传递给该接口。