一、获取缺失值。
二、剔除缺失值。
三、缺失值补全。
四、重复值剔除(按照行和列)。
五、数值转换。
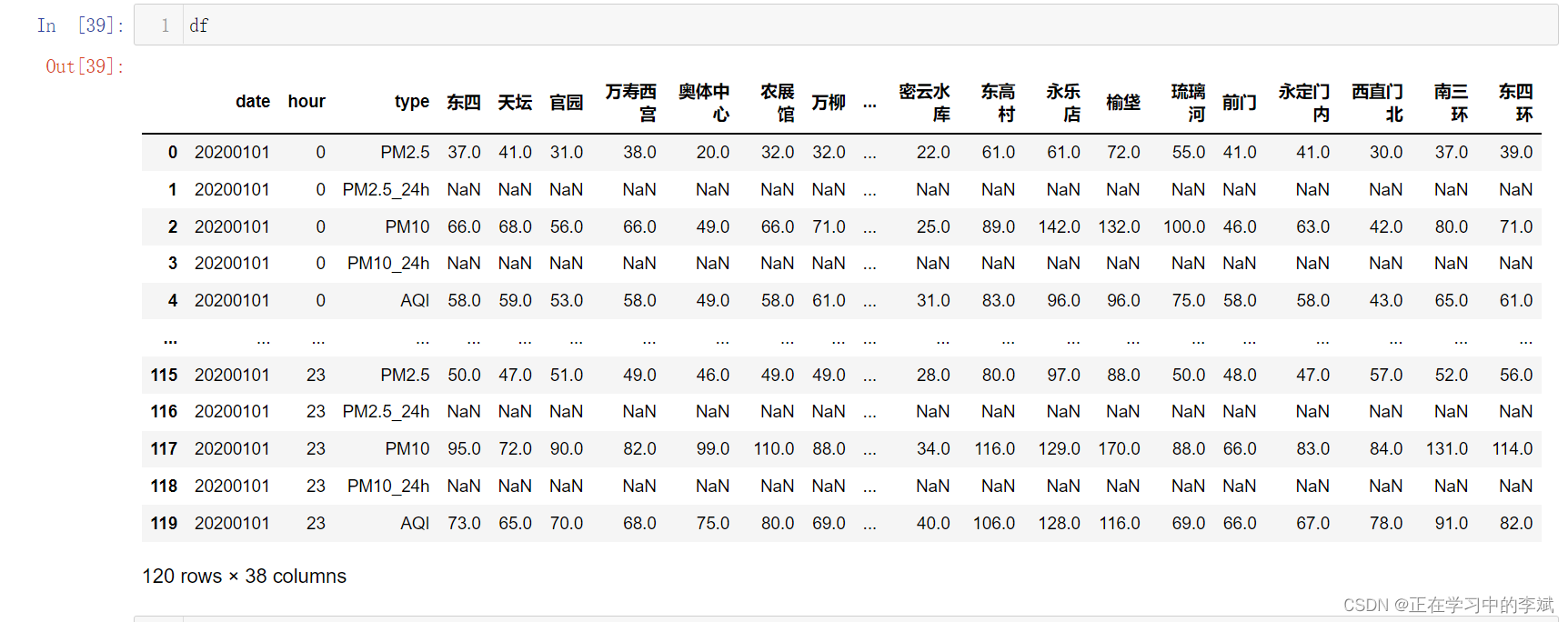
原始数据展示。数据下载链接 https://download.csdn.net/download/qq_35240689/86723500?spm=1001.2014.3001.5503
一、获取缺失值。

1. 获取所有的缺失值.
获取所有的缺失值,返回一个 true 和 false 的表
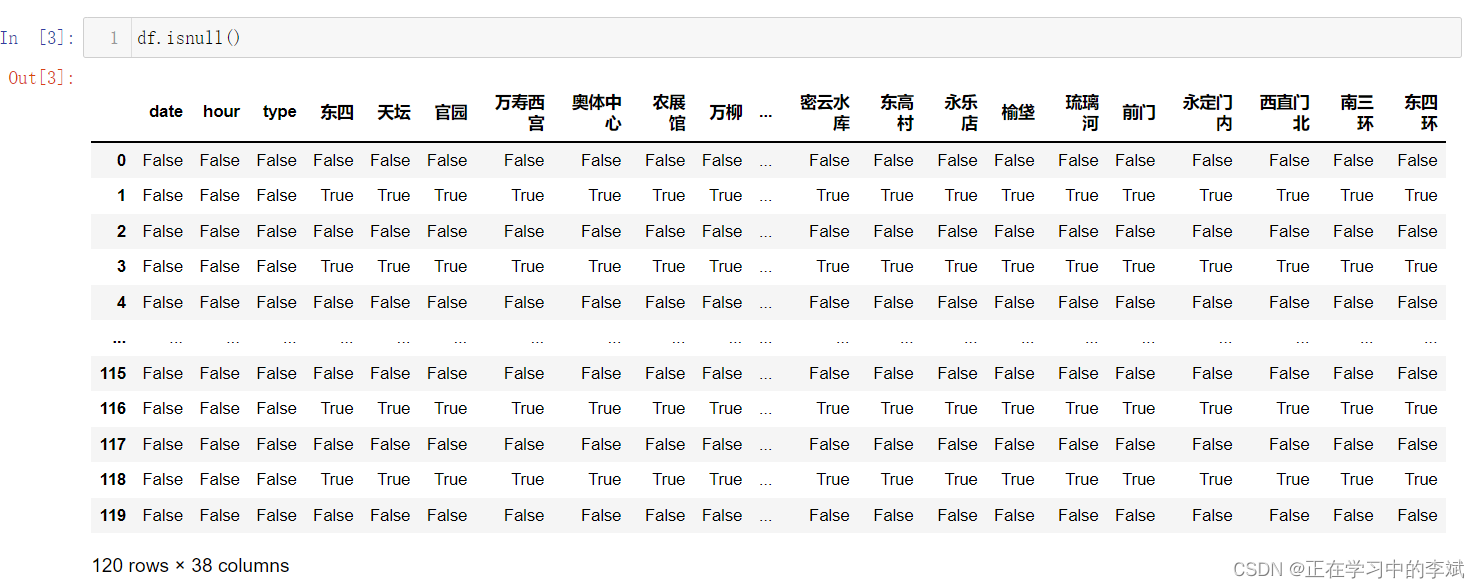
df.isnull()
2. 统计缺失值,按照每一列统计

df.isnull().sum()
3. 统计缺失值 按行
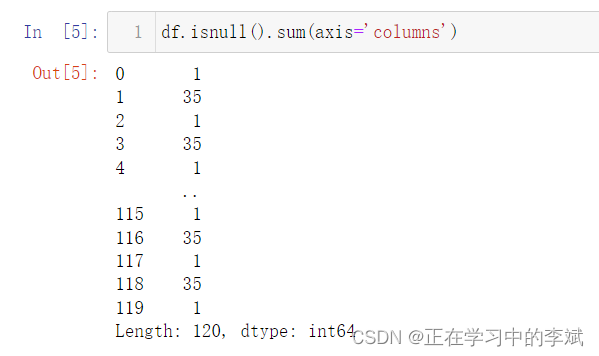
df.isnull().sum(axis='columns')
4. 查看列 是否全部缺失

df.isnull().all()
二、 剔除缺失值
1. 剔除 植物园 这一列缺失值的 2种方式
df1 = df.drop(columns='植物园')
df1 = df.drop('植物园', axis=1)
2.通过数据索引的方式来剔除掉缺测数据。 列
df1 = df.loc[:, ~(df.isnull().all())]
3. 删除所有 有缺失的行
df1[~(df1.isnull().any('columns'))]
这种方式看起来明显比drop()的方式要复杂一点,那么是不是意味着我们就学drop()就行了,不用再去记住索引方式。
当然不是!drop()看起来简单只是因为刚好只有一列需要剔除,加入我们需要剔除很多数据,那使用drop()就不足以完成任务,还是要配合索引的方式。
下面我们来看一下剔除行里的缺测值,上面的数据有很多行都有缺测值,如果在drop函数中一个一个填是很不现实的,那么我们看一下合理的解决方案应该是什么样的。
4. 以上两种方法都还是有一些复杂,这是因为其实pandas还内置了更方便的函数供我们调用,那就是dropna()
inplace 表示是否替换原数据
剔除列的缺失值; how=‘all’ 所有值为空才删除
df.dropna(axis='columns', how='all', inplace=True)
剔除行的缺失值;只要有一个值为空就删除
df.dropna(axis='index', how='any', inplace=True)
三、缺失值补全。
用前一行的数据填充
df.fillna(method='ffill')
用后一行的数据填充
df.fillna(method='bfill')
四、重复值剔除(按照行和列)。

返回的是 True 和 False 的 列表
df.duplicated()

剔除重复行
df.drop_duplicates()
返回的是 True 和 False 的 列表
df.duplicated(subset=['天坛'], keep=False)
剔除 天坛 这列里面的所有重复值
df.drop_duplicates(subset=['天坛'], keep=False)
五、数值转换
1. replace
单值转换,将Nan 替换成 -9999
df.replace(np.nan, -9999)
多值转化,将想替换的元素放在一个 [ ] 里就行
df.replace([np.nan, 0], -9999)
2. apply
replace可以进行简单的数据替换,但如果想进行更为复杂的操作replace是无法完成的。
然而对DataFrame而言,apply是非常重要的数据处理方法,它可以接收各种各样的函数(Python内置的或自定义的),处理方式很灵活,完成各种复杂的需求。他的实际作用是将函数作为一个对象,通过apply的调用对DataFrame里的数组元素应用这个函数。
只关注和设置这个规则,循环这种事情交给编程语言去处理
def aqi_level(aqi):
if aqi>0 and aqi<=50:
level = '优'
elif aqi>50 and aqi<=100:
level = '良'
elif aqi>100 and aqi<=150:
level = '轻度污染'
elif aqi>150 and aqi<=200:
level = '中度污染'
elif aqi>200 and aqi<=300:
level = '重度污染'
else:
level = '严重污染'
return level
# 数据预处理一下 将所有的类型都转为 AQI
aqi = df[df['type']=='AQI']
aqi['东四'].apply(aqi_level)
- applymap
apply() 可以实现对某一行或某一列的函数应用,如果想对 DataFrame中 的全部数值都使用这个函数来进行转化我们就需要用到 applymap()
#~aqi.columns.isin(['date', 'hour', 'type']) 取非这三列的所有列
aqi.loc[:, ~aqi.columns.isin(['date', 'hour', 'type'])].apply(np.mean, axis=0)
aqi.loc[:, ~aqi.columns.isin(['date', 'hour', 'type'])].applymap(aqi_level)