keras卷积层
1 卷积中的输出shape
官方api注释,来自: https://keras.io/zh/layers/convolutional/
'参数如下'
keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
我的示例运行代码
from numpy import random
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
'新建一个图像数据'
'TensorFlow 的图像表示为 [图像数目,长,宽,色彩通道数] 的四维张量'
'这里我们的输入图像 image 的张量形状为 [1, 7, 7, 3]'
image = random.randint(100, size=(7, 7, 3)) # 这里的dtype不能直接设置为float32,只能在生成array之后再作转换
image.astype(np.float32)
print(image.shape)
# (7, 7, 3)
image = np.expand_dims(image, axis=0) # 仿照通常keras中数据准备的步骤,增加batch_size维度
print(image.shape)
# (1, 7, 7, 3)
'设定kernel_size=3, padding='valid' '
model = Sequential()
model.add(Conv2D(filters=1, kernel_size=3, input_shape=(7, 7, 3)))
# model.summary()
output = model(image)
print(output.shape)
# (1, 5, 5, 1)
'设定kernel_size=3, padding='same''
model = Sequential()
model.add(Conv2D(filters=1, kernel_size=3, padding='same', input_shape=(7, 7, 3)))
# model.summary()
output = model(image)
print(output.shape)
# (1, 7, 7, 1)
'设定kernel_size=3, strides=2, padding='same''
model = Sequential()
model.add(Conv2D(filters=1, kernel_size=3, strides=2, padding='same', input_shape=(7, 7, 3)))
# model.summary()
output = model(image)
print(output.shape)
# (1, 4, 4, 1)
总结 : 卷积的结果的shape由卷积的kernel_size,strides,padding三者共同决定.
具体为 : keras中卷积有两种padding方式,一种是SAME,一种是VALID。SAME是在进行卷积前,在图像的周围补一圈0,而用VALID则不对输入图像进行填充。因此,这两种的padding方式得到的输出是不同的,假设n为新得到kernel的尺寸,m为原来kernel的尺寸,k为filters的大小,s为步长,除不尽时向下取整(Pooling操作向上取整)。
padding = ‘VALID’ 的filters尺寸计算公式:n = (m-k+1)/s
padding = ‘SAME’的filters尺寸计算公式:n = m/s
pooling的设计算公式是:n = (m-k)/s+1
注意:在pytorch中,卷积核的计算方式不同,pytorch中padding方式只有’valid’,并且padding补0的层数可以自己定义,因此pytorch的卷积核计算方式有些不同:out = (in-kernel+2*padding)/stride+1
keras之padding=same具体实现的理解,参考:https://blog.csdn.net/zyl681327/article/details/95587655
注意这里如何新建一个包含卷积层的model:必须定义input_shape,input_shape一般是在模型的开始时候就定义,如果没有在开始时候就定义,则必须在模型的开始层中定义。
'input_shape在模型的开始时候就定义'
model = keras.Sequential(
[keras.Input(shape=(7, 7, 3)),
keras.layers.Conv2D(1, 3, strides=1),])
model.summary()
'input_shape在模型的开始层中定义'
model = keras.models.Sequential([
keras.layers.Conv2D(filters=1,kernel_size=[3, 3],input_shape=(7, 7, 3))
])
# 或者
model = Sequential()
model.add(Conv2D(filters=1, kernel_size=3, input_shape=(7, 7, 3)))
model.summary()
2 以一个模型为例来说明
模型来自论文 3d fully convolutional neural networks with intersection over union loss for crop mapping from multi-temporal satellite images
模型图示如下:
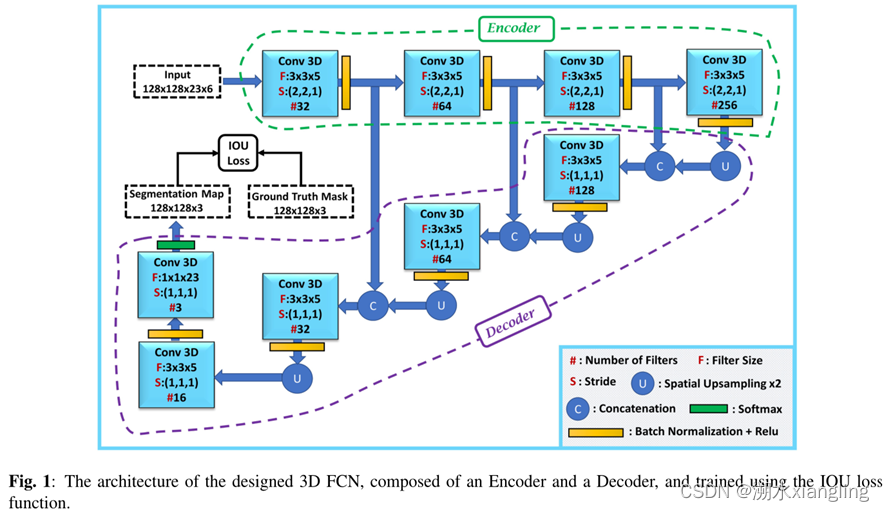
建立模型的方式是keras的Functional API 模式,关于Keras Sequential/Functional API 模式建立模型的更详细的说明,参考: tensorflow官方(https://tensorflow.google.cn/guide/keras/functional, https://tensorflow.google.cn/guide/keras/sequential_model)或者简单粗暴TensorFlow 2(https://tf.wiki/zh_hans/basic/models.html#keras-sequential-functional-api)
from tensorflow.keras.models import Model
from tensorflow.keras.layers import BatchNormalization, Activation, Input, Conv3D, Concatenate, UpSampling3D, Lambda
def FCN_3D():
inputlayer = Input(shape=(128,128,23,6)) # shape=(长,宽,时间维度,通道数),batchsize不用在这里定义
conv1 = Conv3D(32, kernel_size=(3,3,5), strides=(2,2,1), padding='same')(inputlayer)
# 根据padding='SAME'的filters尺寸计算公式:n = m/s,且除不尽时向下取整(Pooling操作向上取整),可知,输出shape为(64,64,23,32)
conv1 = BatchNormalization()(conv1)
conv1 = Activation('relu')(conv1)
conv2 = Conv3D(64, kernel_size=(3,3,5), strides=(2,2,1), padding='same')(conv1)
# 输出shape为(32,32,23,64)
conv2 = BatchNormalization()(conv2)
conv2 = Activation('relu')(conv2)
conv3 = Conv3D(128, kernel_size=(3,3,5), strides=(2,2,1), padding='same')(conv2)
# 输出shape为(16,16,23,128)
conv3 = BatchNormalization()(conv3)
conv3 = Activation('relu')(conv3)
conv4 = Conv3D(256, kernel_size=(3,3,5), strides=(2,2,1), padding='same')(conv3)
# 输出shape为(8,8,23,256)
conv4 = BatchNormalization()(conv4)
conv4 = Activation('relu')(conv4)
conv4U = UpSampling3D(size=(2, 2, 1))(conv4)
# width和height 维度 上采样2倍,frame保持不变,输出shape为(16,16,23,256)
conv4Uconv3 = Concatenate()([conv4U,conv3])
# tf.keras.layers.Concatenate(axis=-1, **kwargs),默认axis=-1,即最后一个维度
# 将conv4U,conv3在最后一个维度连接起来,输出shape为(16,16,23,384)
conv5 = Conv3D(128, kernel_size=(3,3,5), strides=(1,1,1), padding='same')(conv4Uconv3)
# 输出shape为(16,16,23,128)
conv5 = BatchNormalization()(conv5)
conv5 = Activation('relu')(conv5)
conv5U = UpSampling3D(size=(2, 2, 1))(conv5)
# width和height维度 上采样2倍,frame保持不变,输出shape为(32,32,23,128)
conv5Uconv2 = Concatenate()([conv5U,conv2])
# 将conv5U,conv2在最后一个维度连接起来,输出shape为(32,32,23,192)
conv6 = Conv3D(64, kernel_size=(3,3,5), strides=(1,1,1), padding='same')(conv5Uconv2)
# 输出shape为(32,32,23,64)
conv6 = BatchNormalization()(conv6)
conv6 = Activation('relu')(conv6)
conv6U = UpSampling3D(size=(2, 2, 1))(conv6)
# width和height维度 上采样2倍,frame保持不变,输出shape为(64,64,23,128)
conv6Uconv1 = Concatenate()([conv6U,conv1])
conv7 = Conv3D(32, kernel_size=(3,3,5), strides=(1,1,1), padding='same')(conv6Uconv1)
# 输出shape为(64,64,23,32)
conv7 = BatchNormalization()(conv7)
conv7 = Activation('relu')(conv7)
conv7U = UpSampling3D(size=(2, 2, 1))(conv7)
# width和height维度 上采样2倍,frame保持不变,输出shape为(128,128,23,128)
conv8 = Conv3D(16, kernel_size=(3,3,5), strides=(1,1,1), padding='same')(conv7U)
# 输出shape为(128,128,23,16)
conv8 = BatchNormalization()(conv8)
conv8 = Activation('relu')(conv8)
conv9 = Conv3D(3, kernel_size=(1,1,23), strides=(1,1,1))(conv8)
# 输出shape为(128,128,1,3)
squeezed = Lambda(lambda x: K.squeeze(x, 3))(conv9)
# 如果加上batch_size,这里的输出shape应为(batch_size,128,128,1,3).因而在第三个维度squeeze,输出shape为(batch_size,128,128,3)
out = Activation('softmax')(squeezed)
model = Model(inputlayer,out)
return model
实际运行代码来说明上面定义的model:
import numpy as np
from numpy import random
import tensorflow.keras.backend as K
from tensorflow.keras.layers import Conv3D, Concatenate, UpSampling3D
image = random.randint(100, size=(1,8,8,23,256))
image_1 = random.randint(100, size=(1,8,8,23,20))
image_2 = random.randint(100, size=(1,8,8,10,30))
print(image.shape) # (1, 8, 8, 23, 256)
print(image_1.shape) # (1, 8, 8, 23, 20)
print(image_2.shape) # (1, 8, 8, 10, 30)
image_tensor = K.variable(image) # 必须转成tensor,才能直接输入到tensorflow中
# (1, 8, 8, 23, 256)
image_1_tensor = K.variable(image_1) # (1, 8, 8, 23, 20)
image_2_tensor = K.variable(image_2) # (1, 8, 8, 10, 30)
print(image_tensor.shape)
print(image_1_tensor.shape)
print(image_2_tensor.shape)
conv1 = Conv3D(32, kernel_size=(3,3,5), strides=(2,2,1), padding='same')(image_tensor)
print(conv1.shape) # (1, 4, 4, 23, 32)
tensor_U = UpSampling3D(size=(2, 2, 1))(image_tensor)
print(tensor_U.shape) # (1, 16, 16, 23, 256)
tensor_C = Concatenate()([image_tensor,image_1_tensor])
print(tensor_C.shape) # (1, 8, 8, 23, 276)
tensor_C = Concatenate()([image_tensor,image_2_tensor])
# ValueError: A `Concatenate` layer requires inputs with matching shapes except for the concat axis. Got inputs shapes: [(1, 8, 8, 23, 256), (1, 8, 8, 10, 30)]
# Concatenate()要求,除了要concat的那个维度可以不同,其他维度必须相同.