1、哈希的引入和简单使用
我们看下面一个关于查找的例子:
#include <stdio.h>
int find_key(int a[], int n, int key)
{
int i;
for (i = 0; i < n; i++) {
if (key == a[i]) {
return 1;
}
}
return 0;
}
int main()
{
int a[] = {7, 17, 5, 8, 2, 9, 20, 3, 2, 5};
// 查找1-10是否在a当中
for (int i = 1; i <=10; i++) {
if (find_key(a, 10, i)) {
printf("%d is in array");
} else {
printf("%d is not in array");
}
}
return 0;
}查询一个的时间复杂度为O(n);如果说查询次数为n,那么整体的复杂度就是O(n^2);
而通过哈希表就可以将整体的效率优化到线性的O(n);
看一个哈希表的特例情况,假如数据的范围是0-99并且类型是整形并且类型是整数,这种情况可以直接使用数组下标来记录元素是否出现。这个就是最简单的哈希思想。
哈希查找:
#include <stdio.h>
#define MAX_TABLE_LEN 100 // 哈希表的最大长度
// 哈希表的创建函数
void create_hash(int a[], int n, int table[])
{
for (int i = 0; i <n; i++) {
table[a[i]]++;
}
}
int find_key(int table[], int key) {
return table[key]!=0;
}
int main()
{
int a[]={7, 17, 5, 8, 2, 9, 20, 3, 2, 5};
// 初始化一个长度为100的数组table,初始化所有的元素为0
int table[MAX_TABLE_LEN] = {0};
create_hash(a, 10, table);
printf("in hash table:\n");
for (int i=0; i <MAX_TABLE_LEN; i++) {
if (table[i] > 0) {
printf("%d appear %d times.\n", i, tale[i]);
}
}
printf("test\n");
for (int i = 0; i <= 10; i++) {
if (find_key(table, i)) {
printf("%d is in array.\n", i);
} else {
printf("%d is not in array.\n", i);
}
}
return 0;
}我们通过上述的方法不仅可以用来查找还可以用来排序,如果说数组a当中有n个元素。n很大,但是a中元素的范围非常小,比如0-99,那么通过0-99长度的table,记录a中每个元素出现的次数,由于table[i]代表了数据 i 出现的次数,在排序的时候,从0-MAX_TABLE_LEN循环i,再将table[i]个i添加到a中就可以了。
计数排序(运用hash的思想)
#include <stdio.h>
#define MAX_TABLE_LEN 100 // 哈希表的最大长度
void sort(int a[], int n)
{
int table[MAX_TABLE_LEN] = {0};
for (int i = 0; i <n; i++) {
table[a[i]]++; // 记录a中每个元素出现的次数
}
int k = 0;
for (int i = 0; i <MAX_TABLE_LEN; i++) {
for (int j = 0; j < table[i]; j++) {
a[k++] = i; // table[i]代表了数据i出现的次数, 将table[i]个i添加到a中
}
}
}
int main()
{
int a[] = {7, 17, 5, 8, 2, 9, 20, 3, 2, 5};
sort (a, 10);
for (int i = 0; i < 10; i++) {
printf("%d", a[i]);
}
return 0;
}当n远大于表长的时候,计数排序算法的时间复杂度就是O(n),优于一般排序算法的平均时间复杂度为O(nlogn)。
2、哈希表与哈希冲突
哈希表也称为散列表,hashtable,它是可以根据关键字的值直接进行查询和访问的数据结构,我们通常映射函数将关键字直接对应到表中的某个位置,从而加快查找速度,这个映射函数就是哈希函数,存放记录的数组就叫做哈希表,例如下面的例子:
哈希函数:H(key) = key % 12
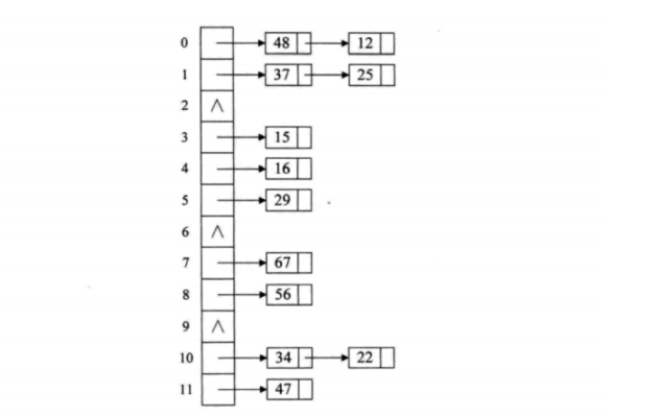
如果上图,哈希函数是对12取余,在哈希表中a[0]中可能存有48、12等多个数值,即哈希表可能会把两个或两个以上的不同关键字映射到同一个地址,这时就会产生哈希冲突。
解决哈希冲突的几种方法:
1)线性探测法,冲突发生,顺序查看表中的下一个元素,直到找出一个空闲单元
2)平方探测法:设发生冲突的地址为d,平方探测法得到的新的地址序列为:d+1^2,d-1^2,d+2^2,d-2^2,,,
3)拉链法
对于不同的关键字可能会通过哈希函数映射到同一地址,为了避免非同义词发生冲突,可以将所有的同义词存储到一个线性链表中,这个线性链表由散列地址唯一标识。拉链法适用于经常进行插入和删除的情况。上图所表示的就是拉链法。
一些概念:
装填因子:哈希表用装填因子表示一个表的装满程度。等于 表中记录数m/哈希表程度m。
3、拉链法
下面使用一个demo来设计一个拉链法的使用:
Hashlink.h
#include <iostream>
#include <cmath>
#include <stdlib.h>
#include <math.h>
using namespace std;
#define NUM 15
int key_num = 0;
typedef struct Node {
int key;
Node *next;
} Node, *linklist;
typedef struct hash{
Node linknum[NUM];
int key_num;
} hash;
int hash_create(hash *H);
int hash_insert(hash *H, int key);
int hash_calculate(int key);
int link_insert(Node *node_first, int key);
int hash_delete(hash *H, int key);
int hash_search(hash *H, int key);
int hash_print(hash *H);
int hash_destroy(hash *H);Hashlink.cpp
#include "Hashlink.h"
int hash_calculate(int key)
{
return key % NUM;
}
int link_insert(Node *node_first, int key)
{
Node *temp = node_first;
Node *node = new Node;
node->key = key;
node->next = NULL;
if (temp->next == NULL) {
temp->next = node;
return 1;
} else {
while (1) {
if (temp->next->key < key && temp->next->next == NULL) {
temp->next->next = node;
break;
}
if (temp->next->key > key) {
node->next = temp->next;
temp->next = node;
break;
}
if (temp ->next->key < key && temp->next->next->key > key) {
node->next = temp->next->next;
temp->next->next = node;
break;
}
temp = temp->next;
}
}
return 0;
}
int hash_create(hash *H)
{
for (int i = 0; i < NUM; i++) {
H->linknum[i].key = 0;
H->linknum[i].next = NULL;
}
H->key_num = 0;
cout << "hash_create success." << endl;
return 0;
}
int hash_insert(hash *H, int key)
{
int value = hash_calculate(key);
link_insert(&H->linknum[value], key);
H->key_num++;
cout << "hash_insert " << key << " success." << endl;
return 0;
}
int hash_print(hash *H)
{
cout << endl << "----hash H have " << H->key_num << " elem----" << endl;
for (int i = 0; i < NUM; i++) {
cout << i << " : ";
Node *temp = &H->linknum[i];
while (temp -> next != NULL)
{
cout << temp->next->key << " ";
temp = temp->next;
}
cout << endl;
}
cout << "--------------------------" << endl;
return 0;
}
int hash_search(hash *H, int key)
{
int mod = key % NUM;
int space = 0;
Node *temp = &H->linknum[mod];
if (temp->next == NULL) {
cout << "hash_search---hashtable no [ " << key << " ]" << endl;
return -1;
}
while (temp->next != NULL) {
space ++;
if (temp->next->key == key) {
cout << "hash_search---[ " << key << " ] in (" << mod << ", " << space << ")" << endl;
return 0;
}
temp = temp->next;
}
cout << "hash_search---hashtable no [ " << key << " ]" << endl;
return 0;
}
int hash_destroy(hash *H)
{
for(int i = 0; i < NUM; i++) {
Node *temp = &H->linknum[i];
Node *delete_node = NULL;
while (temp->next != NULL) {
delete_node = temp->next;
temp = temp->next;
delete delete_node;
}
}
cout << "hash_destroy success." << endl;
return 0;
}
int hash_delete(hash *H, int key)
{
int mod = key % NUM;
Node *delete_node = &H->linknum[mod];
if (delete_node->next == NULL) {
cout << "hashtable have no " << key << "." << endl;
return -1;
}
while (delete_node->next->key != key)
{
delete_node = delete_node->next;
if (delete_node->next == NULL) {
cout << "hashtable have no " << key << "." << endl;
return -1;
}
}
Node *del = delete_node->next;
delete_node->next = delete_node->next->next;
delete del;
H->key_num--;
cout << "hash_delete " << key << " success." << endl;
return 0;
}
int main()
{
hash H;
hash_create(&H);
hash_insert(&H, 1);
hash_insert(&H, 2);
hash_insert(&H, 3);
hash_insert(&H, 4);
hash_insert(&H, 0);
hash_insert(&H, 100);
hash_insert(&H, 5);
hash_insert(&H, 200);
hash_insert(&H, 300);
hash_insert(&H, 800);
hash_insert(&H, 30);
hash_insert(&H, 40);
hash_insert(&H, 50);
hash_insert(&H, 1000);
hash_insert(&H, 80000);
hash_insert(&H, 6);
hash_insert(&H, 56);
hash_insert(&H, 66);
hash_insert(&H, 76);
hash_insert(&H, 78);
hash_insert(&H, 86);
hash_insert(&H, 48);
hash_insert(&H, 39);
hash_insert(&H, 19);
hash_search(&H, 100);
hash_search(&H, 990);
hash_print(&H);
hash_delete(&H, 100);
hash_delete(&H, 886);
hash_delete(&H, 0);
hash_delete(&H, 1);
hash_delete(&H, 67);
hash_delete(&H, 80000);
hash_print(&H);
hash_destroy(&H);
}执行结果如下:
hash_create success.
hash_insert 1 success.
hash_insert 2 success.
hash_insert 3 success.
hash_insert 4 success.
hash_insert 0 success.
hash_insert 100 success.
hash_insert 5 success.
hash_insert 200 success.
hash_insert 300 success.
hash_insert 800 success.
hash_insert 30 success.
hash_insert 40 success.
hash_insert 50 success.
hash_insert 1000 success.
hash_insert 80000 success.
hash_insert 6 success.
hash_insert 56 success.
hash_insert 66 success.
hash_insert 76 success.
hash_insert 78 success.
hash_insert 86 success.
hash_insert 48 success.
hash_insert 39 success.
hash_insert 19 success.
hash_search---[ 100 ] in (10, 2)
hash_search---hashtable no [ 990 ]
----hash H have 24 elem----
0 : 0 30 300
1 : 1 76
2 : 2
3 : 3 48 78
4 : 4 19
5 : 5 50 200 800 80000
6 : 6 66
7 :
8 :
9 : 39
10 : 40 100 1000
11 : 56 86
12 :
13 :
14 :
--------------------------
hash_delete 100 success.
hashtable have no 886.
hash_delete 0 success.
hash_delete 1 success.
hashtable have no 67.
hash_delete 80000 success.
----hash H have 20 elem----
0 : 30 300
1 : 76
2 : 2
3 : 3 48 78
4 : 4 19
5 : 5 50 200 800
6 : 6 66
7 :
8 :
9 : 39
10 : 40 1000
11 : 56 86
12 :
13 :
14 :
--------------------------
hash_destroy success.