-------------前言
浑浑噩噩就看完了一遍《高级c/c++编译技术》,我知道看完一遍是不行,而且光是看也是不行的,先写下这篇博文也权当是记录下我的一些猜想,当然是未经过验证的,经过验证就不是猜想了。最终,在下有什么说得不对的,请各位大侠指正,不断学习不断进步!
-------------正文
先说一下这本书。这本书是由Milan Stevanovic大佬写的,卢誉声所译。结构内容是硬件基础,程序的生命周期,生命周期中的各个阶段的介绍,各类问题的解决。
貌似已经结束了,但是其实还是遗留了一些问题,为什么会分成编译和链接两个步骤呢?一次性就把它弄成一个可执行文件不行吗?
也许回答是,链接太难了,它需要计算出地址和集合所有节,那很难。理由可不仅仅是这个,那是有更高的需求,那就是重用概念。
什么是重用?
那就是一次编写多次(多地)调用,所以就有了我们的许多库。因为我们的链接器,它把所有的目标文件地址都归零了,然后再链接到一个二进制文件中,也就是说,我们在不同的源文件中它都可以这么做!那就是重用!我们一直都在使用!就是因为链接器,所以这就天然地由了重用的机制。
衍生
这就衍生出了,静态库和动态库这两种为了重用而生的库!
静态库
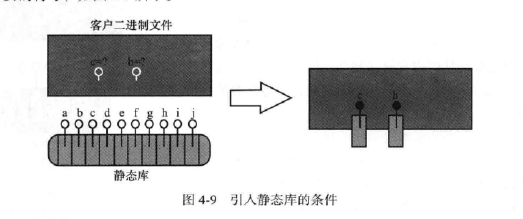
当编译器将编译半圆集合(即源代码文件)转换成二进制目标文件后,如果你希望这些目标文件用于今后的其他项目当中,在连接时可以将其与属于其他项目的目标文件拼接在一起。这就会很麻烦,而如果我们把以上目标文件橙装成一个库,以便我们“查阅“使用,这封装起来的生成一个二进制文件便是静态库。
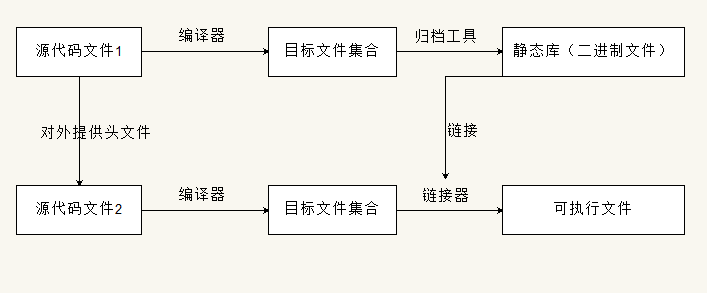
从图可以看出,别的项目文件想引用静态库,需要提供静态库的头文件,给项目文件提供该变量或者函数的声明,但是此时项目文件还不知道该函数或变量存不存在,存在的话再哪里,只是头文件说它在,可以找得到。然后编译就可以通过了,前面说编译的时候说,因为编译期间完成的事情是预处理,语言分析,汇编,目标文件生成,这些过程是只涉及相对地址的,也即只知道在一个目标文件下的地址。然后就到了所有的目标文件链接到一个二进制文件中,此时,静态库文件和目标文件集合一起链接成要给二进制文件,至此完成整个引用静态库的二进制文件生成过程。
ok,以上是静态库的基本思想和原理,具体的使用细节和规范这里就不列出来了,因为我也不太记得住,暂时也没用得到,到时候有用到的时候知道有这么一回事,知道该往哪查,查什么就ok了,至于大伙想了解的话emmmmmmmm那就不好意思了,只能去别的地方了解了。(逃-_-。。。
动态库
动态库概念的提出与多任务操作系统的出现密不可分。因为是多任务嘛,我们要清楚,无论多少并行任务,特定的系统资源总是唯一的,必须被所有的任务共享。比如说,在桌面系统上,典型的共享资源包括键盘,鼠标,显卡,声卡,网卡等,这些都是要形成一个共享库的,用静态库?那么想想一两个被共享还好说,如果很多的话,将不可想象。就好比在一个有限资源的地方,你家需要一个清洁工(比如说),好,从总部clone一个过去,然后清洁工 是刚需的话,每家每户都需要的话,都clone一份,你想想得多少人啊?资源就会被占用。
动态库就是为了应对多任务操作系统而产生的一种措施。它不需要链接重复的目标文件,取而代之的是运行时的共享机制。ok,那么我们如何做到运行时的共享呢?
第一套解决方案是 装载时重定(LTR)
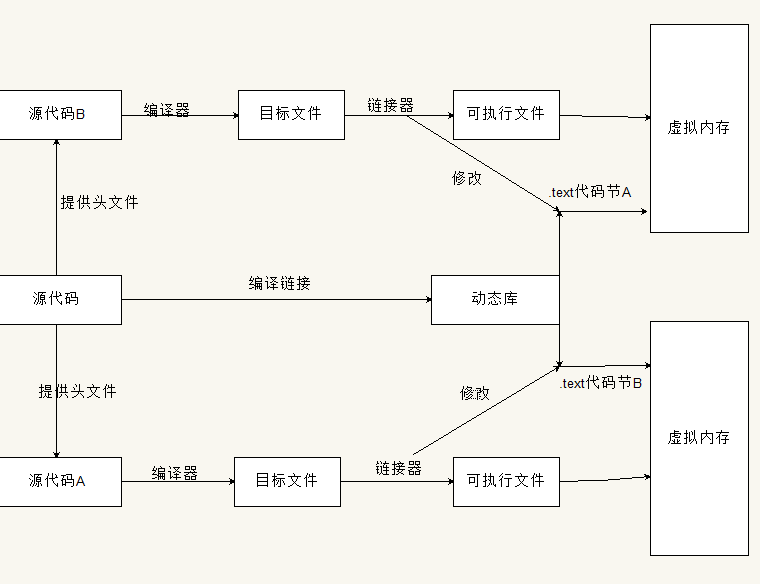
看图可以知道,动态库没有把文件加载进可执行文件当中,而是修改了动态库的.text节的符号,以适应该项目文件的寻址,这样就可以解决了复制的问题。但是,我们会发现,在多个项目中使用该动态库时,该动态的.text节(代码节)已经被修改了,所以为了我们能够重用多份,但是我们也看到了在内存当中存在了内容相同,地址不同的动态库,这会对我们的内存产生很大的负担。
解决方案二:位置无关代码(PIC)
这个概念是为了解决LTR所遗留的问题,我需要,仅需要加载一次(无论哪一个程序先加载它都ok),其他程序再使用的时候就不用加载了,直接访问该动态库的内容。那么这里有个问题,那就是进程之间他们的数据会不会混乱呢?我们的数据节是不共享的,只是共享代码节,所以不会产生混乱,就是共用一套操作,操作这个人的和材料都不同。如何做到这个的呢?
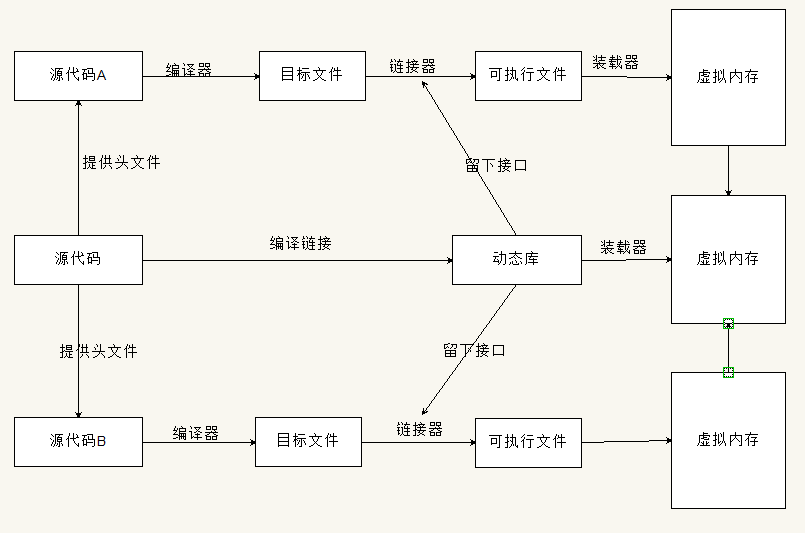
书上的图也非常形象。
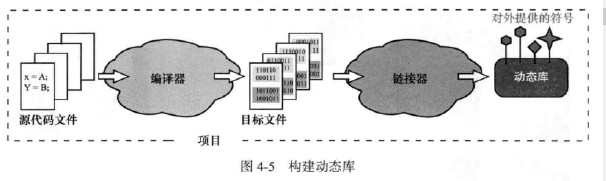
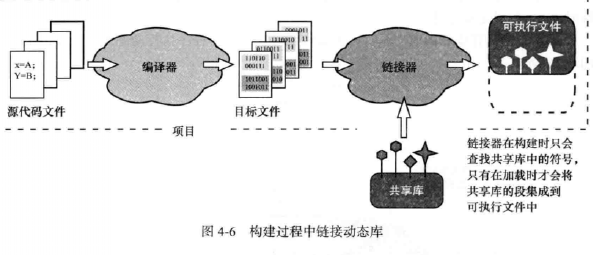
从图可以看出,我们虽然在项目中已经使用了动态库的东西,但是至此我们要使用的东西到底在哪还是未知的,我们需要链接器在这个阶段认为“所有的符号都能够被正确解析",然后链接器会检查二进制文件中所需的符号在动态库中是否存在,这是最起码的,绑票还要告诉对方你的人还活着 的信息,也就是最起码的信任。一旦确认完毕,链接器就会完成任务并创建可执行文件了。在执行的时候才会去通过蛛丝马迹去寻找对方在哪。
静态库和动态库的一些对比
1.静态库是把目标文件和项目的目标文件一起链接成可执行文件的,这也就是说你的可执行文件生成后可能会很大(空间占用)。
2.动态库是在运行时才能体现它的代码量的多少,也即看实际的内存占用,而且使用动态库会把动态库完全把整个动态库链接进二进制文件中(符号)。
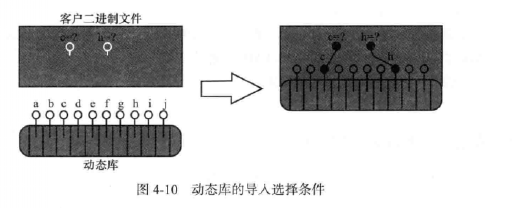
而静态库则是用到了什么就链接进去什么。
至此,我学到的c/c++编译原理已经总结结束。至于怎么使用和创建静态库和动态库,emmmm我这里就不说了,大家只能去查查别的资料了。ok,谢谢大家。
//补充:忘记了,我之前有做过一个总结,就是一些工具的使用
file可以查看几乎任何类型文件的详细信息。
size可以快速获取ELF节的字节长度信息
ldd显示出二进制启动时需要静态加载的动态库的完整列表(注意时静态加载而不是动态加载)
其运行机制为:
ldd会找出所有嵌入再客户二进制文件中的动态库文件名,并尝试根据运行时库文件搜索整个文件,定位这些动态库所对应的实际二进制文件。当完成对直接依赖项的定位之后,ldd会继续该递归过程,查找直接依赖项的依赖项。对于间接依赖项ldd也会继续递归查找。
需要注意的是,在一些环境下的某些版本的ldd会尝试执行程序来获取依赖信息,这对于不受信任的文件进行执行操作这很危险!
这时我们可以采取一下措施进行替代:
objdump -p /path/program |grep NEEDED
readelf -d /path/progream |grep NEEDED
这两个得到的结果不及ldd,因为他不递归查找,所以你得自己进行递归查找操作。
nm工具可以列出二进制文件的符号列表。该工具可以输出符号及输出符号的类型。如果是c++代码默认会输出经过名称修饰的符号名。
例:
nm /path/program_name
列出二进制文件的所有符号。如果对于共享库,不仅会列出导出库,所有的库都会显示,除非你使用strip命令,那么就不会显示
nm -D /path/programname
只列出动态节中的符号(即导出符)
nm -C /path/programname
列出未经名称修饰的格式
nm -DA /path/*
列出当前目录下的所有二进制文件的搜索结果
objdump工具
优势:不仅支持ELF格式,还支持大概50种其他格式,其反汇编的功能亦非常强大
ELF头信息中包含有目标文件、静态库、动态库和可执行文件/入口信息(.text节的起点)
1.objdump -f /path/programname
解析ELF头信息
2.objdump -h /path/programname
列出并查看节信息
3.objdump -t /path/programname 与nm /path/program_name完全相同
列出所有符号
4.objdump -T /path/programname nm -D /path/programname
只列出动态符号
5.objdump -p /path/programname
查看动态节
6.objdump -R /path/programname
查看重定位节
7.objdump -s-j .got /path/programname //查看.got节的数据
查看某一节中的数据
8.列出查看段
9.反汇编,但是只有在构建的时候使用了调试才可以使用,也就是gcc -g 。。。。进行调试
objdump -d -M intel libxxxx.so |grep -A 10 ml_(带ml_的函数)
objdump -d -M intel 执行文件 |grep -A 10 "<main>"(带main的函数)
readelf与objdump的作用相似,区别在于readelf只能读elf格式的,因为更专一,所以读elf更专业
部署阶段的工具
1.用于解决在你构建的时候出现的一些的问题
chrpath、patchelf、strip、ldconfig
2.运行时分析工具
strace可以跟踪由进程产生的系统调用与程序接收的信号。这将有利于查看运行时的所需依赖项
addr2line可以将运行时地址转换成地址所对应的源代码文件信息和行号。
当且仅当使用调试模式构建二进制文件(通过传递 -g -O0编译器选项)时,使用该工具有助于分析程序奔溃信息,其中奔溃处的程序计数器地址会打印到终端屏幕上。
gdb调试器,必须使用再有调试信息下的二进制可执行文件,即gcc -g,才可以使用,具体怎么使用再查吧。
静态库分析工具:
ar工具具体用到再说吧,我现在已经没有耐心了。。。。好菜啊。
EXEC(可执行文件)
DYN(共享目标文件)
REL(可重定位文件)