
在日常的研发流程当中,单元测试一般是由研发来编写,随着大模型的出现,作为测开可以考虑利用代码分析技术以及AI来智能生成单测case,降低研发成本投入,缩短整个产品交付周期
单元测试往往处于代码编写阶段,相比于测试阶段,能低成本、发现更多的问题,随着测试左移的呼声越来越大,完善、有效,覆盖率高且全面的单元测试用例还是非常有价值的,下面一起来了解一下单测是什么
为什么要写测试
时代在要求我们写测试
程序员的职责范围一点点在拓展,关键原因就是,软件开发正在变得越来越复杂。
测试可以让我们在越来越复杂的软件开发中能够稳步前行。一方面,在编写新功能时,测试可以让我们的代码正确性得到验证,让我们拥有一个个稳定的模块。另一方面,测试可以帮助我们在长期的过程中不断回归,让每一步走得更稳。
流传着一个关于测试的段子:每个程序员在修改代码时都希望有测试,而在写代码时,都不想写测试。
写测试收益很大
XML之父Tim Bray最近在博客里有个好玩的说法:“代码不写测试就像上了厕所不洗手……单元测试是对软件未来的一项必不可少的投资。”具体来说,单元测试有哪些收益呢?
-
它是最容易保证代码覆盖率达到100%的测试。
-
可以⼤幅降低上线时的紧张指数。
-
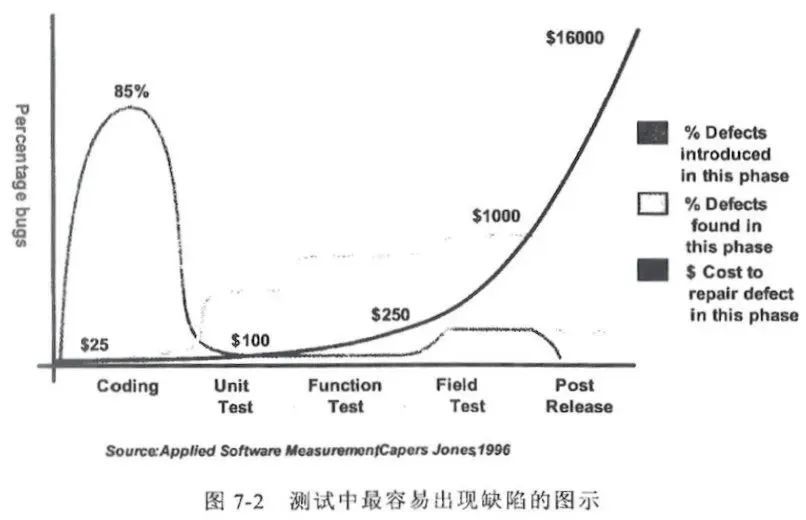
单元测试能更快地发现问题(见下图左)。
-
单元测试的性价比最高,因为错误发现的越晚,修复它的成本就越高,而且难度呈指数式增长,所以我们要尽早地进行测试(见下图右)。
-
编码人员,一般也是单元测试的主要执行者,是唯一能够做到生产出无缺陷程序的人,其他任何人都无法做到这一点。
-
有助于源码的优化,使之更加规范,快速反馈,可以放心进行重构。
|
|
|
|---|---|
| 这张图来自微软的统计数据:Bug在单元测试阶段被发现,平均耗时3.25小时,如果漏到系统测试阶段,要花费11.5小时。 | 这张图,旨在说明两个问题:85%的缺陷都在代码设计阶段产生,而发现Bug的阶段越靠后,耗费成本就越高,指数级别的增高。 |

尽管单元测试有如此的收益,但在我们日常的工作中,仍然存在不少项目它们的单元测试要么是不完整要么是缺失的。常见的原因总结如下:代码逻辑过于复杂;写单元测试时耗费的时间较长;任务重、工期紧,或者干脆就不写了。
基于以上问题,相较于传统的JUnit单元测试,今天为大家推荐一款名为Spock的测试框架。目前,美团优选物流技术团队绝大部分后端服务已经采用了Spock作为测试框架,在开发效率、可读性和维护性方面取得了不错的收益。
不过网上Spock资料比较简单,甚至包括官网的Demo,无法解决我们项目中复杂业务场景面临的问题,通过深入学习和实践之后,本文会将一些经验分享出来,希望能够帮助大家提高开发测试的效率。
什么是测试
从自测到自动化测试框架
测试框架广泛流行起来,要归功于自动化测试框架 JUnit,它的作者是 Kent Beck 和 Erich Gamma。Kent Beck 是极限编程的创始人,在软件工程领域大名鼎鼎,而 Erich Gamma 则是著名的《设计模式》一书的作者,很多人熟悉的 Visual Studio Code 也有他的重大贡献。
有一次,Kent Beck 和 Erich Gamma一起从苏黎世飞往亚特兰大参加 OOPLSA(Object-Oriented Programming, Systems, Languages & Applications)大会,在航班上两个人结对编程写出了 JUnit
测试框架简介
Junit教程:https://www.baeldung.com/junit
我们理解测试框架有两个关键点,一是要去理解测试组织的结构,一是要去理解断言。掌握了这两点,就足够应付日常的大多数情况了。
测试结构
JUnit 怎么表示测试用例大家应该都很熟悉了
@Test
public should_work() {
...
}
比如,同样的初始化代码反复在写,由于测试的特殊性,这些初始化的代码需要在每个测试之前都去执行。为了解决这个问题,JUnit 引入了 setUp 去做初始化的工作。
@BeforeEach
void setUp() {
...
}
-
@TestFactory – denotes a method that's a test factory for dynamic tests
-
@DisplayName – defines a custom display name for a test class or a test method
-
@Nested – denotes that the annotated class is a nested, non-static test class
-
@Tag – declares tags for filtering tests
-
@ExtendWith – registers custom extensions
-
@BeforeEach – denotes that the annotated method will be executed before each test method (previously @Before)
-
@AfterEach – denotes that the annotated method will be executed after each test method (previously @After)
-
@BeforeAll – denotes that the annotated method will be executed before all test methods in the current class (previously @BeforeClass)
-
@AfterAll – denotes that the annotated method will be executed after all test methods in the current class (previously @AfterClass)
-
@Disable – disables a test class or method (previously @Ignore)
断言
我们接下来看理解测试框架的第二个关键点,断言。测试结构保证了测试用例能够按照预期的方式执行,而断言则保证了我们的测试需要有一个目标,也就是我们到底要测什么。
断言,说白了就是拿执行的结果和预期的结果进行比较。如果执行一个测试连预期都没有,那它到底要测什么?所以,我们可以说,没有断言的测试不是好测试。
几乎每个测试框架都有自己内建的断言机制,比如下面这个。
assertEquals(2, calculator.add(1, 1));
这个 assertEquals 是最典型的一个断言,也几乎是使用最多的断言,很多其它语言的测试框架也把它原封不动地搬了过去。但这个断言有一个严重的问题,你如果不看 API,根本记不住哪个应该是预期值,哪个应该是你函数返回的实际值。这就是典型的 API 设计问题,让人很难用好。
所以,社区中涌现了大量的第三方断言程序库,比如,Hamcrest、AssertJ、Truth。其中,Hamcrest 是一个函数组合风格的断言库,一度被内建到 JUnit 4 里面,但出于对社区竞争的鼓励,JUnit 5 又把它挪了出来,下面是一段使用了 Harmcrest 的代码。
assertThat(calculator.subtract(4, 1), is(equalTo(3)));
AssertJ 是一种流畅风格的程序库,扩展性也非常不错,它也是我们在前面实战部分选择的程序库,下面是一段使用了 AssertJ 的代码。
assertThat(frodo.getName()).startsWith("Fro")
.endsWith("do")
.isEqualToIgnoringCase("frodo");
Truth 是 Google 开源的一个断言库,和 AssertJ 很类似,它对 Android 程序支持得比较好,我也放了一段代码,风格上和 AssertJ 如出一辙。
assertThat(projectsByTeam())
.valuesForKey("corelibs")
.containsExactly("guava", "dagger", "truth", "auto", "caliper");
断言,不仅仅包括有返回值的处理,还包括其它的特殊情况,比如,抛出异常也可进行断言,这是 JUnit 5 内建的异常断言,你可以参考一下。
Assertions.assertThrows(IllegalArgumentException.class, () -> {
Integer.parseInt("One");
});
具体有哪些情况可以进行断言,你可以查阅所使用断言库的 API 文档。
最后还有一种不在这些断言库里的断言,那就是 Mock 框架提供的一种断言:verify。
关于 Mock 框架,后面我们还会讲到,这里只是简单地提一下,verify 的作用就是验证一个函数有没有得到调用。在某些测试里面,函数既没有返回值,也不会抛出异常。比如拿保存一个对象来说,我们唯一能够判断保存动作是否正确执行的办法,就是利用 verify 去验证保存的函数是否得到调用,就像下面这样。
verify(repository).save(obj);
测试的规范
测试的正确性如何保证?
既然给测试写测试不是一个行得通的做法,那唯一可行的方案就是,把测试写简单,简单到一目了然,不需要证明它的正确性。由此,我们可以知道,一个复杂的测试肯定不是一个好的测试。
简单的测试应该长什么样呢?我们一起来看一个例子,这就是我们在实战环节中给出的第一个测试。
@Test
public void should_add_todo_item() {
// 准备
TodoItemRepository repository = mock(TodoItemRepository.class);
when(repository.save(any())).then(returnsFirstArg());
TodoItemService service = new TodoItemService(repository);
// 执行
TodoItem item = service.addTodoItem(new TodoParameter("foo"));
// 断言
assertThat(item.getContent()).isEqualTo("foo");
// 清理(可选)
}
我把这个测试分成了四段,分别是准备、执行、断言和清理,这也是一般测试都会具备的四个阶段,我们分别来看一下。
准备。这个阶段是为了测试所做的一些准备,比如启动外部依赖的服务,存储一些预置的数据。在我们这个例子里面就是设置所需组件的行为,然后将这些组件组装了起来。
执行。这个阶段是整个测试中最核心的部分,触发被测目标的行为。通常来说,它就是一个测试点,在大多数情况下,执行应该就是一个函数调用。如果是测试外部系统,就是发出一个请求。在我们这段代码里,它就是调用了一个函数。
断言。断言是我们的预期,它负责验证执行的结果是否正确。比如,被测系统是否返回了正确的应答。在这个例子,我们验证的是 Todo 项的内容是否是我们添加进去的内容。
清理。清理是一个可能会有的部分。如果在测试中使到了外部资源,在这个部分要及时地释放掉,保证测试环境被还原到一个最初的状态,就像什么都没发生过一样。比如,我们在测试过程中向数据库插入了数据,执行之后,要删除测试过程中插入的数据。一些测试框架对一些通用的情况已经提供支持,比如之前我们用到的临时文件。
如果准备和清理的部分是在几个测试用例间通用的,它们就有可能被放到 setUp 和 tearDown 里去完成。
这四个阶段中,必须存在的是执行和断言。想想也是,不执行,目标都没有,还测什么?不断言,预期都没有,跑了也是白跑。如果不涉及到一些资源释放,清理部分很可能就没有了。而对一些简单的测试来说,也不需要做特别的准备。
一段旅程(A-TRIP)
有了对测试结构的基本认知,我们再进一步,看看如何衡量一个测试有没有做好?有人把好测试的特点总结成一个说法:A-TRIP。这其实是五个单词的缩写,分别是:
-
Automatic,自动化;
-
Thorough,全面的;
-
Repeatable,可重复的;
-
Independent,独立的;
-
Professional,专业的。
这是什么意思呢?我们分别来解释一下。
Automatic,自动化。经过上一讲的讲解,这一点你应该已经很容易理解了。自动化测试相比传统测试,核心增强就在自动化上。这也是为什么测试一定要有断言,因为只有在有断言的情况下,机器才能够帮我们判断测试是否成功。
Thorough,全面的。这一点其实是测试的要求,应该尽可能用测试覆盖各种场景。不管什么样的自动化测试,它的本质还是测试,前面我们讲了向测试人员学习,关键点就在于这有助于我们写出更全面的测试。理解全面还有一个角度,就是测试覆盖率。我们在实战环节中已经见识了如何通过测试覆盖率工具,帮我们去发现代码中测试中没有覆盖到地方。
Repeatable,可重复的。它要求测试能够反复运行,并且结果都应该是一样的。这是保证测试简单可靠的前提。需要保证单元测试的幂等性。
在内存中执行的测试一般都是可重复的。影响一个测试可重复性的主要因素是外部资源,常见的外部资源包括文件、数据库、中间件、第三方服务等等。如果在测试中遇到这些外部资源,我们就要想办法让这些资源在测试结束后,恢复原来的样子。你在实战中已经见识过如何处理文件,在后面的应用篇,我们还会讲到如何处理数据库。简单说就是在测试执行之后,能够把数据回滚掉。
理解可重复性还有一个角度,那就是一批测试也要可重复。这就需要测试之间彼此没有依赖,这也是我们接下来要讨论的测试的另外一个特点。
Independent,独立的。****测试和测试之间不应该有任何依赖。什么叫有依赖?就是一个测试要依赖于另外一个测试运行的结果。比如两个测试都要依赖于数据库,第一个测试运行时往数据库里写了一些数据,而第二个测试在执行时要用到这些数据。也就是说,第二个测试必须在第一个测试执行之后再执行,这就叫做有依赖。
可重复性和独立性关联非常紧密。因为我们通常认为,可重复是测试按照随机的顺序执行,其结果也是一样的,这就要依赖于测试是独立的。而一旦测试不独立,有了依赖,从单个测试上来看,它也违反了可重复性。
Professional,专业的。这一点是很多人观念中缺失的,测试代码也是代码,也要按照代码的标准去维护。这就意味着你的测试代码也要写得清晰,比如良好的命名、把函数写小、要重构甚至要抽象出测试的基础库、测试的模式。
如何写出可测试的代码
如果建楼用的每块材料都不敢保证质量,你敢要求最终建出来的大楼质量很高吗?
这就是很多团队面临的尴尬场景:每个模块都没有验证过,只知道系统集成起来能够工作。所以,一旦一个系统可以工作了,最好的办法就是不去动它。然而,还有一大堆新需求排在后面。
相应地,对一个可测试性好的系统而言,应该每个模块都可以进行独立的测试
提升软件的可测试性,关键是改善软件的设计,编写可测试的代码。
编写可组合的代码。从这个路标出发,我们得出了两个推论:
-
不要在组件内部创建对象;
static class A { private AdCampaignStateMachineTest b=new AdCampaignStateMachineTest(); // public A(AdCampaignStateMachineTest b) { // this.b = b; // } public static void main(String[] args) { //推荐 // A a = new A(new AdCampaignStateMachineTest()); // a.xx(); //不推荐 // A a = new A(); // ReflectUtil.setFieldValue(a, "b", new AdCampaignStateMachineTest()); // a.xx() } } -
不要编写 static 方法。
Mockito 无法mock static方法的。使用对象方法的好处是方便Spring DI。
由不编写 static 方法,我们可以推导出:
-
不要使用全局状态;
-
不要使用 Singleton 模式。
在实际工作中,除了要编写业务代码,还会遇到第三方集成的情况:
-
对于调用程序库的情况,我们可以定义接口,然后给出调用第三方程序库的实现,以此实现代码隔离;
-
如果我们的代码由框架调用,那么回调代码只做薄薄的一层,负责从框架代码转发到业务代码。
Mock框架
测试不好测,关键是软件设计问题。一个好的设计可以把很多实现细节从业务代码中隔离出去(比如使用DDD)。
之所以要隔离出去,一个重要的原因就是这些实现细节不那么可控。比如,如果我们依赖了数据库,就需要保证这个数据库环境同时只有一个测试在用。理论上这样不是不可能,但成本会非常高。再比如,如果依赖了第三方服务,那么我们就没法控制它给我们返回预期的值。这样一来,很多出错的场景,我们可能都没法测试。
Mock 框架的基本逻辑很简单,创建一个模拟对象并设置它的行为,主要就是用什么样的参数调用时,给出怎样的反馈。虽然 Mock 框架本身的逻辑很简单,但前期也经过了很长一段时间的发展,什么东西可以 Mock 以及怎样去表现 Mock,不同的 Mock 框架给出了不同的答案。
今天我们的讨论就以 Mockito 这个框架作为我们讨论的基础,这也是目前 Java 社区最常用的 Mock 框架。
要学习 Mock 框架,必须要掌握它最核心的两个点:****设置模拟对象与校验对象行为。
设置 Mock 对象
要设置一个模拟对象,首先要创建一个模拟对象。在实战中,我们已经见识过了。
TodoItemRepository repository = mock(TodoItemRepository.class);
接下来就是设置它的行为,下面是从实战中摘取的两个例子。
when(repository.findAll()).thenReturn(of(new TodoItem("foo")));
when(repository.save(any())).then(returnsFirstArg());
一个好程序库其 API 要有很强的表达性,像前面这两段代码,即便我不解释,看语句本身也知道它做了些什么。
模拟对象的设置核心就是两点:参数是什么样的以及对应的处理是什么样的。
参数设置其实是一个参数匹配的过程,核心要回答的问题就是判断给出的实参是否满足这里设置的条件。像上面代码中,save 的写法表示任意参数都可以,我们也可以设置它是特定的值,比如像下面这样。
when(repository.findByIndex(1)).thenReturn(new TodoItem("foo"));
其实它也是一个参数匹配的过程,只不过这里做了些省略,完整的写法应该是下面这样。
when(repository.findByIndex(eq(1))).thenReturn(new TodoItem("foo"));
如果你有更复杂的参数匹配过程,甚至可以自己去实现一个匹配过程。但我强烈建议你不要这么做,因为测试应该是简单的。一般来说,相等和任意参数这两种用法在大多数情况下已经够用了。
设置完参数,接下来,就是对应的处理。能够设置相应的处理,这是体现模拟对象可控的关键。前面的例子我们看到了如何设置相应的返回值,我们也可以抛出异常,模拟异常场景。
when(repository.save(any())).thenThrow(IllegalArgumentException.class);
同设置参数类似,相应的处理也可以写得很复杂,但我同样建议你不要这么做,原因也是一样的,测试要简单。知道怎样设置返回值,怎样抛出异常,已经足够大多数情况下使用了。
校验对象行为
模拟对象的另外一个重要行为是校验对象行为,就是知道一个方法有没有按照预期的方式调用。比如,我们可以预期 save 函数在执行过程中得到了调用。
verify(repository).save(any());
这只是校验了 save 方法得到了调用,我们还可以校验这个方法调用了多少次。
verify(repository, atLeast(3)).save(any());
同样,校验也有很多可以设置的参数,但我同样不建议你把它用得太复杂了,就连verify 本身我都建议你不要用得太多。
verify 用起来会给人一种安全感,所以,会让人有一种多用的倾向,但这是一种错觉。我在讲测试框架时说过,verify 其实是一种断言。断言意味着这是一个函数应该具备的行为,是一种行为上的约定。
一旦设置了 verify,实际上也就约束了函数的实现。但 verify 约束的对象又是底层的组件,是一种实现细节。换言之,过度使用 verify 造成的结果就是把一个函数的实现细节约定死了。
过度使用 verify,在写代码的时候,你会有一种成就感。但是,一旦涉及代码修改,整个人就不好了。因为实现细节被 verify 锁定死,一旦修改代码,这些 verify 就很容易造成测试无法通过。
测试应该测试的是接口行为,而不是内部实现。所以,verify 虽好,还是建议少用。如果有一些场景不用 verify 就没有什么可断言的了,那该用 verify 还是要用。
如果按照测试模式来说,设置 Mock 对象的行为应该算是 Stub,而校验对象行为的做法,才是 Mock。如果按照模式的说法,我们应该常用 Stub,少用 Mock。
单元测试应该怎么写
I’m not a great programmer; I’m just a good programmer with great habits.
我不是一个伟大的程序员,只是一个有着好习惯的优秀程序员。
—— Kent Beck
很多团队由于多方面的原因(比如设计做得不好),导致单元测试写得少。但为了提高代码质量以及更准确地定位问题,我们应该多写单元测试。
单元测试最好是和实现代码一起写,以便减少后续补测试的痛苦。想写好测试,关键要做好任务分解,否则,面对一个巨大的需求,没有人知道如何去给它写单元测试。
编写单元测试的过程,实际上就是一个任务开发的过程。一个任务代码的完成,不仅仅是写了实现代码,还要通过相应的测试。一般而言,任务开发要先设计相应的接口,确定其行为,然后根据这个接口设计相应的测试用例,最后,把这些用例实例化成一个个具体的单元测试。
单元测试常见的一个问题是代码一重构,单元测试就崩溃。这很大程度上是由于测试对实现细节的依赖过于紧密。一般来说,单元测试最好是面向接口行为来设计,因为这是一个更宽泛的要求。其实,在测试中的很多细节也可以考虑设置得宽泛一些,比如模拟对象的设置、模拟服务器的设置等等。
测试覆盖率
测试覆盖率是一种度量指标,指的是在运行一个测试集合时,代码被执行的比例。它的一个主要作用就是告诉我们有多少代码测试到了。其实更严格地说,测试覆盖率应该叫代码覆盖率,只不过大多数情况它都是被用在测试的场景下,所以在很多人的讨论中,并不进行严格的区分。
既然测试覆盖率是度量指标,我们就需要知道有哪些具体的指标,常见的测试覆盖率指标有下面这几种:
-
函数覆盖率(Function coverage):代码中定义的函数有多少得到了调用;
-
语句覆盖率(Statement coverage):代码中有多少语句得到了执行;
-
分支覆盖率(Branches coverage):控制结构中的分支有多少得到了执行(比如 if 语句中的条件);
-
条件覆盖率(Condition coverage):每个布尔表达式的子表达式是否都检查过 true 和 false 的不同情况;
-
行覆盖率(Line coverage):代码中有多少行得到了测试。
以函数覆盖率为例,如果我们在代码中定义了 100 个函数,运行测试之后只执行 80 个,那它的函数覆盖率就是 80/100=0.8,也就是 80%。
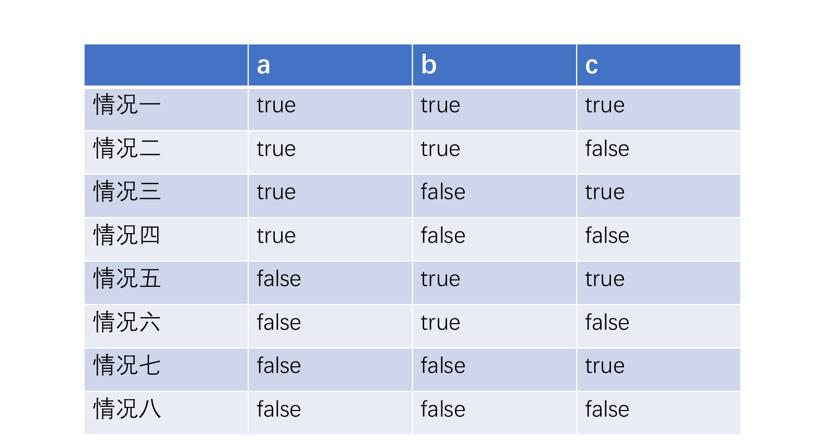
这几个指标基本上看一眼就知道是怎么回事,唯一稍微复杂一点就是条件覆盖率,因为它要测试的是在一个布尔表达式中每个子表达式所有真假值的情况,我们来看看下面这个代码。
if ((a || b) && c) {
...
}
就是这么一个看上去很简单的情况,因为它牵扯到 a、b、c 三个子表达式,又要把每个子表达式的真假值都要测试到,所以,就需要有 8 种情况。
05d61b4eedb1d0fe5d1a04e6e4bf1fc4-1662966759_副本
在这么一个条件比较简单的情况下,其实条件覆盖率已经是很复杂了。如果条件进一步增多,复杂度会进一步提升,想要在测试里对条件进行全覆盖也不是一件容易的事。这也给了我们一个编码上的提示:尽可能减少条件。事实上,在真实的项目中,很多条件都是不必要的复杂,可以通过提前返回将一些复杂的条件做一个拆分。
JaCoCo:一个 Java 的测试覆盖率工具
下面我就以 Jacoco 为例,讲讲如何实际地使用一个测试覆盖率工具。
JaCoCo 是 Java 社区常用的一个测试覆盖率工具,这个名字一看就是 Java Code Coverage 的缩写。开发它的团队原本是开发一个叫 EclEmma 的 Eclipse 插件,这个插件本身就是用来做测试覆盖率的。只不过,后来团队发现开源社区虽然有不少测试覆盖率的实现,但大多绑定在特定工具上,于是,他们决定启动 JaCoCo 这个项目,把它当做一个不绑定在特定工具上的独立实现,让它成为 JVM 环境中的标准技术。
我们已经知道了测试覆盖率有好多不同的指标,学习一个具体的测试覆盖率工具,主要就是把指标做一个对应,知道如何设置相应的指标。
在 JaCoCo 里,指标对应的概念是 counter。我们要在覆盖率中使用哪些指标,也就是要指定哪些不同的 counter。
每个 counter 提供了不同的配置,比如覆盖的数量(COVEREDCOUNT),没有覆盖的数量(MISSEDCOUNT)等等,但我们最关心的只有一件事:覆盖率(COVEREDRATIO)。
有了 counter,选定了配置,接下来,要确定的就是取值的范围,也就是最大值(maximum)和最小值(minimum)是多少。比如,我们这里关注的就是覆盖率的值应该是多少,一般就是配置它的最小值(minimum)是多少。
覆盖率是一个比例,所以,它的取值范围就是从 0 到 1。我们可以根据自己项目的需要来进行配置。根据上面的介绍,如果我们要求行覆盖率达到 80%,我们就可以这样配置。
counter: "LINE", value: "COVEREDRATIO", minimum: "0.8"
好,你现在已经有了对于 JaCoCo 的基本了解。但通常在项目中,我们很少会直接使用它,而是会把它与我们项目的自动化过程结合起来。
在项目中使用测试覆盖率
这就是自动化检查的价值。一般情况下,只要你工作做得好,它就默默地在下面工作,并不会影响到你,而一旦你因为一些疏忽忘记了一些事情,它就会跳出来提醒你。
无论是 Ant,还是 Maven,抑或是 Gradle,Java 社区主流的自动化工具都提供了对于 JaCoCo 的支持,我们可以根据自己选用的工具进行配置。大部分情况下,配置一次,全团队的人就都可以使用了。
Maven jacoco配置
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>${jacoco.version}</version>
<executions>
<execution>
<id>default-prepare-agent</id>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<id>default-report</id>
<phase>test</phase>
<goals>
<goal>report</goal>
</goals>
</execution>
<!-- <execution>-->
<!-- <id>default-check</id>-->
<!-- <goals>-->
<!-- <goal>check</goal>-->
<!-- </goals>-->
<!-- <configuration>-->
<!-- <rules>-->
<!-- <rule>-->
<!-- <element>BUNDLE</element>-->
<!-- <limits>-->
<!-- <limit>-->
<!-- <counter>INSTRUCTION</counter>-->
<!-- <value>COVEREDRATIO</value>-->
<!-- <minimum>0.8</minimum>-->
<!-- </limit>-->
<!-- <limit>-->
<!-- <counter>BRANCH</counter>-->
<!-- <value>COVEREDRATIO</value>-->
<!-- <minimum>0.8</minimum>-->
<!-- </limit>-->
<!-- <limit>-->
<!-- <counter>COMPLEXITY</counter>-->
<!-- <value>COVEREDRATIO</value>-->
<!-- <minimum>0.8</minimum>-->
<!-- </limit>-->
<!-- <limit>-->
<!-- <counter>LINE</counter>-->
<!-- <value>COVEREDRATIO</value>-->
<!-- <minimum>0.8</minimum>-->
<!-- </limit>-->
<!-- <limit>-->
<!-- <counter>METHOD</counter>-->
<!-- <value>COVEREDRATIO</value>-->
<!-- <minimum>0.8</minimum>-->
<!-- </limit>-->
<!-- </limits>-->
<!-- </rule>-->
<!-- </rules>-->
<!-- </configuration>-->
<!-- </execution>-->
</executions>
</plugin>
这里面的关键点在于,把测试覆盖率与提交过程联系起来。我们在实战中,提交之前要运行检查过程,测试覆盖率检查就在这个过程里。这样,就保证了它不是一个独立的存在,不仅在我们开发过程中起作用,更进一步,在持续集成的过程中也能够起到作用。
在日常开发中,真正与我们经常打交道的是测试覆盖率不通过的时候,比如,在我们的实战中,运行脚本对代码进行检查时,如果测试覆盖率不够,我们就会得到下面这样的提示。
Rule violated for package com.github.dreamhead.todo.cli.file: lines covered ratio is 0.9, but expected minimum is 1.0
这里会有哪些报错,取决于我们配置了多少个 counter。按照我通常的习惯,我会把所有的 counter 都配置上去,这样就可以发现更多的问题了。
不过,这个提示只是告诉我们测试覆盖率不够,但具体哪不够,我们还需要查看测试覆盖率的报告。一般来说,测试覆盖率的报告是我们在与工具集成的时候配置好的。JaCoCo 可以提供好多种报告类型:XML、CSV、HTML 等等。按照一般使用习惯来说,我会优选使用 HTML 的报告,这样就可以直接用浏览器打开看了。如果你有工具需要其它格式的报告,也可以配置不同的格式。
生成报告的位置也是可以配置的,我在实战项目中,把它配置在 buildDir/reports/jacoco 这个目录下,这里的 $buildDir 指的是每个模块构建生成物的目录,一般来说,就是 build 目录。所以,每次当我看到因为测试覆盖率造成构建失败,就要就可以打开这个目录下的 index.html 文件,它会给你所有这个模块测试覆盖情况的总览。

img
在实战项目中,我们配置的覆盖率要求是 100%,所以,我们很容易就发现没有覆盖到的地方在哪里,就是那个有红色的地方。然后我们可以一路追踪进去,找到具体类,再找到具体的方法,最终定位到具体的语句,下面就是我们在实战中定位到的问题。

img
找到了具体的测试覆盖不足的地方,接下来,就是想办法提高测试率。一般来说,在简单的情况里通过增加或调整几个测试,就可以把这些场景覆盖到。但也有一些不是那么容易覆盖的,比如在实战中,我们看到 Jackson API 中抛出的 IOException。
不过,具体如何解决这个问题,对不同的同学来说,会有各自的解决方案。这个地方真正容易引起争议的地方是为什么测试覆盖率要设置成 100%。
在真实的项目中,很多不愿意写测试的人巴不得这个数字越低越好,但实际上我们也很清楚,这个数字设置得很低就没有任何意义了。
集成测试
相对于单元测试只关注单元行为,集成测试关注的多个组件协同工作的表现。一种是代码之间的集成,一种是代码与外部组件的集成。
对代码之间的集成来说,一方面要考虑我们自己编写的各个单元如何协作;
另一方面,在使用各种框架的情况下,要考虑与框架的集成。如果我们有了单元测试,这种集成主要是关心链路的通畅,所以一般来说我们只要沿着一条执行路径,把相关的代码组装到一起进行测试就可以了。
如果涉及框架,最好是能够把框架集成一起做了,设计得比较好的框架是对于测试的支持比较好的(比如像 Spring Boot),可以让我们很方便地进行测试。
对于外部组件的集成而言,难点在于如何控制外部组件的状态。数据库在这方面相对已经有比较成熟的解决方案:使用单独的数据库,以及在测试结束之后进行回滚。
但大部分系统没有这么好的解决方案,尤其是第三方的服务。这时候,我们就要看有没有合适的替代方案。对于大多数 REST API,我们可以采用模拟服务器对服务进行模拟。
有些代码由于基础设施的问题是不容易在自动化场景覆盖的,这也是我们为什么要强调与框架结合的代码一定要薄,让这种代码的影响尽可能少。这也是在减少用上层测试覆盖的工作量。
在Spring项目中如何进行单元测试
不过在 Spring Boot 出现之前,正是因为无法摆脱打包部署的这样的模式,基于这条路走下去开发难度依然不小,可以说并没有从根本上改变问题。但 Spring 的轻量级开发理念是支撑它一路向前的动力,既然那个时候 Web 服务器不能舍弃,索性 Spring 就选择了另外一条路:从测试支持入手。
所以 Spring 提供了一条测试之路,让我们在最终打包之前,能够让自己编写的代码在本地得到完整验证。你在实战环节中已经见识过如何使用 Spring 做测试了。简单来说就是使用单元测试构建稳定的业务核心,使用 Spring 提供的基础设施进行集成测试。
严格地说,构建稳定的业务核心其实并不依赖于 Spring,但 Spring 提供了一个将组件组装到一起基础设施,也就是依赖注入(Dependency Injection,简称 DI)容器。通常我们会利用 DI 容器完成我们的工作,也正是因为 DI 容器用起来很容易,所以常常会造成 DI 容器的误用,反而会阻碍测试。
所以,在一个使用 Spring 项目进行单元测试的关键就是,****保证代码可以组合的,也就是通过依赖注入的。你可能会说,我们都用了 Spring,那代码肯定是组合的。这还真不一定,有些错误的做法就会造成对依赖注入的破坏,进而造成单元测试的困难。
不使用基于字段的注入
有一种典型的错误就是基于字段的注入,比如像下面这样。使用set注入Mock属性时必然要使用反射
@Service
public class TodoItemService {
@Autowired
private TodoItemRepository repository;
}
@Autowired 是一个很好用的特性,它会告诉 Spring 自动帮我们注入相应的组件。在字段上加Autowired 是一个容易写的代码,但它对单元测试却很不友好,因为你需要很繁琐地去设置这个字段的值,比如通过反射。
如果不使用基于字段的注入该怎么做呢?其实很简单,提供一个构造函数就好,把@Autowired 放在构造函数上,像下面这样子。
@Service
public class TodoItemService {
private final TodoItemRepository repository;
@Autowired
public TodoItemService(final TodoItemRepository repository) {
this.repository = repository;
}
...
}
这样一来,编写测试的时候我们只要像普通对象一样去测试就好了,具体的做法你要是记不清了,可以去回顾一下实战环节。
这种构造函数一般我们都可以利用 IDE 的快捷键生成,所以这段代码对我们来说也不是很重的负担。如果你还嫌弃这种代码的冗余,也可以用 Lombok(Lombok 是一个帮助我们生成代码的程序库)的 Annotation 来简化代码,像下面这样。
@Service
@RequiredArgsConstructor
public class TodoItemService {
private final TodoItemRepository repository;
private @NotNull Bean1 bean1;
...
}
不依赖于 ApplicationContext
使用 Spring 还有一种典型的错误,就是通过 ApplicationContext 获取依赖的对象,比如像下面这样。
@Service
public class TodoItemService {
@Autowired
private ApplicationContext context;
private TodoItemRepository repository;
public TodoItemService() {
this.repository = context.getBean(TodoItemRepository.class);
}
...
}
在业务核心代码中出现 ApplicationContext 是一种完全错误的做法。一方面,它打破了 DI 容器原本的设计,另一方面,还让业务核心代码对第三方代码(也就是 ApplicationContext)产生了依赖。
我们再从设计的角度看一下,AppliationContext 的出现使得我们在测试这段代码时,必须引入 ApplicationContext。要想在代码里获取到相应的组件,需要在测试中向 ApplicationContext 里添加相应的组件,这会让一个原本很简单的测试变得复杂起来。
你看,一个正常的测试是如此简单,但正是因为引入了 Spring,许多人反而会做错。Spring 最大的优点是可以在代码层面上不依赖于 Spring,而错误的做法反而是深深地依赖于 Spring。
Spring项目如何进行集成测试
数据库的测试
今天数据库几乎成了所有商业项目的标配,所以,Spring 也提供了对于数据库测试很好的支持。我们之前说过,一个好的测试要有可重复性,这句话放到数据库上就是要保证测试之前的数据库和测试之后的数据库是一样的。怎么做到这一点呢?
测试配置
通常有两种做法,一种是采用嵌入式内存数据库,也就是在测试执行之后,内存中的数据一次丢掉。另一种做法就是采用真实的数据库,为了保证测试前后数据库是一致的,我们会采用事务回滚的方式,并不把数据真正地提交进数据库里。
我们做测试的一个关键点就是不能随意修改代码,切记,不能为了测试的需要而修改代码。如果真的要修改,也许应该修改的是设计,而不仅仅是代码。
虽然不能修改代码,但我们可以提供不同的配置。只要我们给应用提供不同的数据库连接信息,它就会连到不同的数据库上。Spring 就给了我们一个提供不同配置的机会,只要我们在测试中声明一个不同的属性配置即可,下面就是一个例子。
@ExtendWith(SpringExtension.class)
@DataJpaTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
@TestPropertySource("classpath:test.properties")
public class TodoItemRepositoryTest {
...
}
在这段代码里,我们提供了一个测试用的配置,也就是 @TestPropertySource 给出的一个配置。这是在用 classpath 上的 test.properties 这个文件中的配置,去替换掉我们缺省的配置(也就是我们真实的数据库)。
嵌入式内存数据库
正如我们前面所说,我们要保证数据库的可重复性有两种做法:嵌入式内存数据库和事务回滚。要想使用嵌入式内存数据库,我们需要提供一个嵌入式内存数据库的配置。在 Java 世界中,常见的嵌入式内存数据库有 H2、HSQLDB、Apache 的 Derby 等。我们配置一个测试的依赖就好,以 H2 为例,像下面这样。
testImplementation "com.h2database:h2:$h2Version"
然后,再提供一个相应的配置,像下面这样。
jdbc.driverClassName=org.h2.Driver
jdbc.url=jdbc:h2:mem:todo;DB_CLOSE_DELAY=-1
hibernate.dialect=org.hibernate.dialect.H2Dialect
hibernate.hbm2ddl.auto=create
如果运气好的话,你的测试就可以顺利地运行了。是的,运气好的话。
之所以把软件开发这么严肃认真的事归结到运气,这就不得不说说使用嵌入式内存数据库的问题了。
所以,嵌入式内存数据库这种技术看上去很美,但我在实际的项目中用得并不多,我更多会采用事务回滚的方式。
事务回滚
在事务回滚的方式中,我们的配置几乎与标准的应用配置是一样的,下面是我们在实战中所采用的配置。
spring.datasource.url=jdbc:mysql://localhost:3306/todo_test?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowPublicKeyRetrieval=true
spring.datasource.username=todo
spring.datasource.password=geektime
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
通常来说,为了不让测试过程和开发过程造成数据冲突,我们会创建两个不同的数据库,在 MySQL 中,这就是两条 SQL 语句。
create database todo_dev;
create database todo_test;
这样,一个用来做手工测试用,另外一个交由自动化测试使用,你从数据库后缀名上就可以看出二者的差异。顺便说一下,这种做法在业界的普遍流行是源自 Ruby on Rails(一个 Ruby 的 Web 开发框架),当年它在软件开发实践上给整个行业带来了极大的颠覆。
采用这种做法,我们的代码面对的是同样的数据库引擎,也就不必担心 SQL 不兼容的问题了。
我们所说的事务回滚体现在 @DataJpaTest 上,它把数据库回滚做成缺省的配置,所以我们什么都不用做,就可以获得这样的能力。
与大多数测试一样,测试与数据库的集成时,我们也要做一些准备。需要准备的往往是一些数据,提前插入到数据库里。我们可以使用 Spring 给我们准备的基础设施(TestEntityManager)向数据库中完成这个工作,下面是一个例子。
@ExtendWith(SpringExtension.class)
@DataJpaTest
public class ExampleRepositoryTests {
@Autowired
private TestEntityManager entityManager;
@Test
public void should_work() throws Exception {
this.entityManager.persist(new User("sboot", "1234"));
...
}
}
如果你用的不是 JPA 而是其它的数据访问方式,Spring 也给我们提供了 @JdbcTest,这相当于是一个更基础的配置,因为只要有 DataSource, 它就可以很好地工作起来,这适用于绝大多数的测试情况。相应地,数据工作也更加地直接,采用 SQL 就可以,下面是一个例子。
@JdbcTest
@Sql({"test-data.sql"})
class EmployeeDAOIntegrationTest {
@Autowired
private DataSource dataSource;
...
}
Web 接口测试
除了数据库,另外一个几乎成了今天标配的就是 Web。Spring 对于 Web 测试也提供了非常好的支持。
如果按照我在实战中的方式工作,你会发现到了编写 Web 接口这步,我们基本上完成了几乎所有的工作,只差给外界一个接口让它和我们的系统连接起来。在前面的实战中,我们采用整体集成的方式对系统进行测试,这里的关键点就是@SpringBootTest,它把所有的组件都连接了起来。
@SpringBootTest
@AutoConfigureMockMvc
@Transactional
public class TodoItemResourceTest {
...
}
在讲集成测试的时候我曾经说过,集成测试分为两种,一种把所有代码都集成起来的测试,另外一种是针对外部组件的集成。从代码上来看,后一种测试只是针对一个单元在测试,所以它兼具单元测试和集成测试的特点。其实,测试 Web 接口也有一种类似于单元测试的集成方式,它采用的 @WebMvcTest。
@WebMvcTest(TodoItemResource.class)
public class TodoItemResourceTest {
...
}
正如你在这段代码中看见的那样,这里我们指定了要测试的组件 TodoItemResource。在这个测试里,它不会集成所有的组件,只会集成与 TodoItemResource 相关的部分,但整个 Web 处理过程是完整的。
如果把它视为单元测试,服务层后面的代码都是外部的,我们可以采用模拟对象把它控制在可控范围内,这个时候 MockBean 就开始发挥作用了。
@WebMvcTest(TodoItemResource.class)
public class TodoItemResourceTest {
@MockBean
private TodoItemService service;
@Test
public void should_add_item() throws Exception {
when(service.addTodoItem(TodoParameter.of("foo"))).thenReturn(new TodoItem("foo"));
...
}
}
在这里,@MockBean 标记的 TodoItemService 模拟对象会参与到组件组装的过程中,成为 TodoItemResource 的组成部分,我们就可以设置它的行为。如果 Web 接口同服务层有比较复杂的交互,那这种做法就能够很好的处理。当然,正如我们一直在说的,我不建议这里做得过于复杂。
@WebMvcTest 这种偏向于单元测试的做法,执行速度相对于@SpringBootTest 这种集成了所有组件的做法而言要快一些。所以如果测试的量大起来,采用@WebMvcTest 会有一定的优势。
理解 Web 接口测试还有一个关键点。正如我在之前内容中说过,当年 Spring 摆脱了大部分对于应用服务器的依赖,但是 Web 却是它一直没有摆脱的。所以,怎么更好地不依赖于 Web 服务器进行测试,就是摆在 Spring 面前的问题。答案是 Spring 提供了模拟的 Web 环境。
具体到我们的测试上,它就是 MockMvc 对象发挥的作用。我们用下面的代码回顾一下它的用法。
@SpringBootTest
@AutoConfigureMockMvc
@Transactional
public class TodoItemResourceTest {
@Autowired
private MockMvc mockMvc;
...
@Test
public void should_add_item() throws Exception {
String todoItem = "{ " +
"\"content\": \"foo\"" +
"}";
mockMvc.perform(MockMvcRequestBuilders.post("/todo-items")
.contentType(MediaType.APPLICATION_JSON)
.content(todoItem))
.andExpect(status().isCreated());
assertThat(repository.findAll()).anyMatch(item -> item.getContent().equals("foo"));
}
}
这里的关键是 @AutoConfigureMockMvc,它为我们配置好了 MockMvc,剩下的就是我们使用这个配置好的环境进行访问。
从实现的角度理解,它就是那个模拟的 Web 环境。所谓模拟的环境,是因为它根本没有启动真正的Web服务器,而是直接去调用了我们的代码,省略了请求在网络上走一遭的过程。但请求进到服务器之后的主要处理都在,所以相应的处理都在(无论是各种 Filter 的处理,还是从请求体到请求对象的转换)。现在你应该明白了,MockMvc 是 Spring 轻量级开发的一个重要的组成部分。
Spring 在支持轻量级开发上做了很大的努力,所以,在把整个系统集成起来之前,绝大部分内容我们都已经验证过了。我在这里介绍的只是其中最为典型的用法,Spring 的测试绝对是一个值得挖掘的宝藏,你可以阅读它的文档去发掘更多有趣的用法。
现在我们对怎样在真实项目中做好单元测试和集成测试已经有了一个基本的理解,但在实际的项目中,不同类型的测试该怎么配比呢?这就是我们下一讲要讨论的内容。
各种测试配比
测试的特点

6ae19b91c63bb20ae0b16d5f0db3d411-1662966760_副本
好,到这里,你已经对常见的测试特点有了一个了解,接下来,我们就来看看不同的测试配比模型。
测试配比模型
所谓不同的测试配比,其实就是什么样的测试多写一些。而决定什么样的测试多写一些,主要是不同人的不同出发点。有人认为一个测试应该尽可能覆盖面广一些,所以,要多写系统测试,有人认为测试应该考虑速度和成本,所以,要多写单元测试。
正是有不同的出发点,行业中有两种典型的测试配比模型,一种是冰淇淋蛋卷模型,一种是测试金字塔模型。
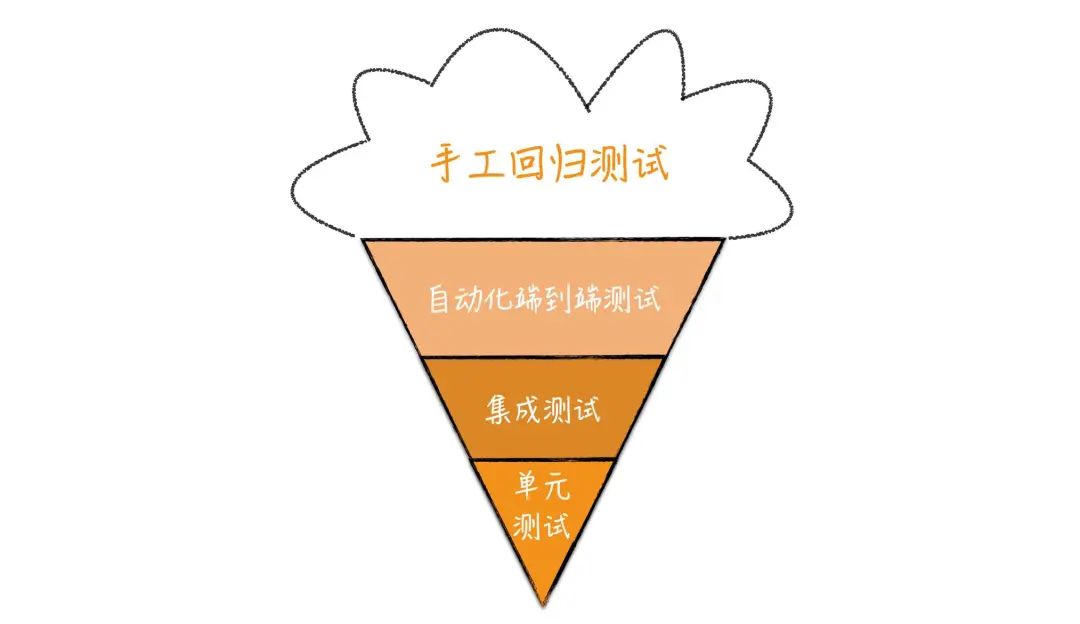
我们先来看冰淇淋蛋卷模型,如下图所示。
img
在这个图里,单元测试在最下面,表示它是底层的;然后层次逐渐升高,系统测试,也就是图上的端到端测试就是高层测试,在最上面。所有自动化测试形成了蛋卷部分,而外面的冰淇淋部分则是手工的测试。
这里面每一层的宽窄表示了测试数量的多少。从图中我们不难看出,它对测试配比的预期:少量的单元测试,大量的系统测试。
冰淇淋蛋卷的出发点就是从单个测试的覆盖面考虑的,只要一些系统测试,就足以覆盖系统的大部分情况。当然,对于那些系统测试无法覆盖的场景就需要有低层的测试配合,比如,集成测试和单元测试。在冰淇淋蛋卷模型里,主力就是高层测试,低层测试只是作为高层测试的补充。
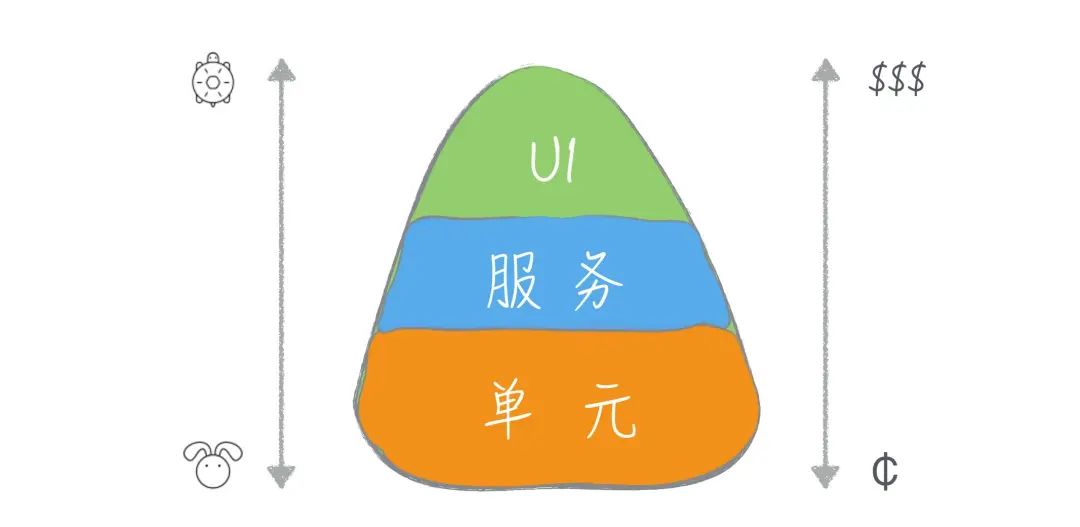
了解了冰淇淋蛋卷模型,我们再来看测试金字塔,下面这张图表示的就是测试金字塔。
img
在表现形式上测试金字塔和冰淇淋蛋卷模型是一致的,都是下面表示低层测试,越往上测试的层次越高,而每一层的宽窄表示了测试数量的多少。
Martin Fowler 的测试金字塔文章文章。从图的整体形状我们不难看出,测试金字塔同冰淇淋蛋卷正相反,它的重点是多写单元测试,而上层的测试数量则逐层递减。
测试金字塔的出发点是低层测试成本低、速度快、整体覆盖面广,所以要多写。因为低层测试覆盖了几乎所有的情况,高层的测试就可以只做一些大面上的覆盖,保证不同组件之间的协作是没有问题的。在这个模型里,主力是单元测试,而高层的测试则是作为补充。
好,有了对于测试配比模型的理解,接下来我们要回答的问题就是怎样使用这两个模型。
从行业的最佳实践角度看,测试金字塔已经是行业中的最佳实践。测试金字塔以单元测试为基础,因为成本低、速度快等特点,单元测试可以让我们在开发过程中迅速得到反馈。对于一个想要编写测试的团队而言,测试金字塔模型也是更容易坚持做到的。
实际上,我们在实战环节中采用的就是测试金字塔模型,也就是以单元测试为主,附以少量的集成测试或系统测试。所以,如果你准备开始一个新项目,最好采用测试金字塔模型,而具体的做法我们在实战环节中已经见识过了,那就是一层一层地写测试。每完成一个功能,代码和测试总是同步写出来的,代码总是得到验证的,这样我们就可以稳步向前。
既然测试金字塔都成为了行业的最佳实践,那我们为什么还要了解冰淇淋蛋卷模型呢?因为不是所有项目都是新项目。
因为各种历史原因,很多遗留项目是没有测试的。当项目发展了一段时间之后,团队开始关注产品质量,于是大家开始补测试。
在这种情况下,补测试是希望能够快速地建立起安全网,那必然是从系统测试入手来得快。只要写上一些高层测试,就能够覆盖到系统的大部分功能,属于“投资少见效快”的做法。这也是很多人喜欢冰淇淋蛋卷模型的重要原因。
但是,我们必须知道一点,在补测试的情况下,这么做是没问题的。如果我们把它当作开发的常态,那就有问题了。这就像治病和健身的关系一样,虽然去医院能在短时间内快速解决一定问题,但你不能没事就去医院,只有日常多运动,才能减少去医院的次数。
所以,对于冰淇淋蛋卷模型,它是遗留项目写测试的起点。在有了一个安全网的底线之后,我们还是要向测试金字塔方向前进,以单元测试作为整体的基础。新写的代码都是要按照测试金字塔的方式来组织测试,这才是一个可以持续的方向。具体如何在遗留系统上写测试,这是我们下一讲要讨论的主题。
最佳实践
Junit+Mockito
Junit教程:https://www.baeldung.com/junit
Mockito:https://www.baeldung.com/mockito-series
Groovy+Spock
groovy教程:https://www.baeldung.com/groovy-language
Spock教程:https://www.baeldung.com/groovy-spock https://zhuanlan.zhihu.com/p/399510995
Spock-Spring教程:https://www.baeldung.com/spring-spock-testing
SonarQube
SonarQube是一个开源的代码质量管理平台,它能够帮助开发团队监控和管理代码质量,从而改善软件质量。以下是SonarQube能够做的一些事情:
-
代码静态分析:SonarQube能够通过对代码进行静态分析,找出代码中的潜在缺陷、漏洞、重复代码等问题。静态分析是在编译时分析代码,而不需要实际运行代码。
-
代码质量评估:SonarQube能够根据一组标准,评估代码的质量。这些标准包括代码复杂度、可维护性、可读性、测试覆盖率等。评估的结果可以帮助开发团队了解代码的质量,并采取相应的措施进行改进。
-
代码质量跟踪:SonarQube能够帮助开发团队跟踪代码质量的变化,以便及时发现和解决代码质量问题。开发团队可以使用SonarQube来监控代码库的质量,并在代码发生变化时及时发现和解决问题。
-
持续集成:SonarQube能够与常见的持续集成工具(例如Jenkins、Travis CI等)集成,使代码分析和质量检查成为持续集成的一部分。这将有助于团队在开发周期的早期发现和解决问题。
-
代码规范检查:SonarQube能够对代码进行规范检查,以确保代码符合行业标准和最佳实践。这有助于团队编写一致性更好、可维护性更高的代码。
-
缺陷管理:SonarQube能够跟踪代码缺陷,并将缺陷分配给相应的开发人员。开发人员可以使用SonarQube来管理他们的缺陷列表,并解决代码中的问题。
TDD
TDD 的节奏:红 - 绿 - 重构。

img
自动化测试
https://hellosean1025.github.io/yapi/
压力测试
https://jmeter.apache.org/
https://mimeter.be.mi.com/scenes-info?scene=0&apiProtocol=1
性能测试
https://github.com/openjdk/jmh
单测规范建议
-
从冰淇淋蛋卷到测试金字塔
-
单测流程接入CICD流水线
-
本地编译test不要跳过!
-
修改某块代码的时候补充单测,不好写单测的先重构,单测覆盖率达到80%以上
-
单测写在test目录对应包下,类名为xxxTest
CampaignGateway.class --> CampaignGatewayTest.class
chatgpt的测试建议
对于Java遗留项目,写单元测试可能会比较困难,因为这些项目可能缺乏良好的架构和设计,代码可能也比较复杂和难以测试。以下是一些建议,可以帮助您在Java遗留项目中编写单元测试:
-
选择合适的单元测试框架:选择一个适合您项目的单元测试框架,比如JUnit或TestNG。这些框架都有广泛的文档和社区支持,可以帮助您快速入门并开始编写单元测试。
-
识别测试点:您需要识别您要测试的关键点,以确保您测试的是最关键的部分。您可以选择覆盖率较低的部分进行测试,或者优先测试对系统稳定性和性能有较大影响的部分。
-
逐步添加测试:由于遗留项目可能缺乏良好的架构和设计,可能难以编写全面的测试用例。建议您从一个小的、独立的模块开始,逐步添加测试,同时改进代码结构和设计,使其更易于测试。
-
使用Mock和Stub:遗留代码可能依赖于外部系统或库,这可能会导致单元测试变得困难。在这种情况下,您可以使用Mock和Stub来模拟外部依赖项,以确保您的测试不受外部环境的影响。
-
持续集成和自动化测试:为了确保您的测试是可靠和可重复的,建议您使用持续集成工具,如Jenkins或Travis CI,自动运行您的测试,并在每次代码提交后运行测试。
总之,编写单元测试需要一定的技能和经验,需要花费一些时间和精力,但它可以帮助您更好地理解代码并确保其质量。在编写单元测试时,始终要遵循良好的编码实践,如单一职责原则和依赖倒置原则,以确保您的测试是可读、可维护和可扩展的。
-
重构代码以使其更易于测试:当您在编写单元测试时,您可能会发现代码难以测试,这可能是由于代码缺乏良好的架构和设计所致。在这种情况下,您可以考虑重构代码以使其更易于测试。一些常见的重构技术包括拆分方法、提取接口、消除重复代码等。
-
使用代码覆盖率工具:使用代码覆盖率工具可以帮助您了解您的测试用例是否覆盖了足够的代码。这些工具可以帮助您找到测试用例覆盖不到的部分,并帮助您编写更全面的测试用例。
-
编写易于维护的测试用例:编写易于维护的测试用例是很重要的。这意味着您的测试用例应该易于理解和修改,并且应该清楚地描述您的测试目的。您可以使用注释和命名约定来帮助您编写易于维护的测试用例。
-
学习如何处理边缘情况:在编写单元测试时,您需要考虑各种情况,包括边缘情况和异常情况。这些情况可能会导致代码崩溃或出现不良行为,因此您需要确保您的测试用例覆盖这些情况。
-
与团队成员合作:编写单元测试是整个团队的责任。与您的团队成员合作,讨论测试策略和方法,确保您的测试用例能够覆盖关键点并且是有效的。在编写单元测试时,您还可以与其他开发人员和测试人员合作,以确保您的测试用例是全面的并且能够满足系统的需求。
-
使用数据驱动测试:数据驱动测试是一种测试方法,它将测试数据和测试代码分离开来,以便您可以更轻松地添加、删除和修改测试数据。您可以使用数据驱动测试来测试系统的不同方面,以确保代码能够处理各种数据情况。
-
选择合适的断言:选择合适的断言可以帮助您测试代码的正确性。JUnit和TestNG等单元测试框架提供了各种断言方法,包括比较对象、数组、布尔值等的方法。您可以根据需要选择适当的断言方法。
-
使用适当的测试级别:单元测试是一种测试级别,用于测试代码的单个组件或单个方法。除了单元测试之外,还有其他测试级别,包括集成测试和端到端测试。在编写单元测试时,您应该将测试重点放在代码的最低级别上,并在需要时添加其他测试级别。
-
保持测试用例独立:测试用例应该相互独立,这意味着它们不应该依赖于其他测试用例或测试顺序。独立的测试用例可以确保测试结果的可靠性,并使测试用例易于维护和修改。
-
记录和分析测试结果:在编写单元测试时,您应该记录测试结果并对其进行分析。这可以帮助您识别测试用例失败的原因,并找到需要改进的代码部分。您可以使用测试报告工具和分析工具来帮助您记录和分析测试结果。
总之,编写单元测试对于维护和改进遗留项目非常重要。在编写单元测试时,您需要选择合适的测试框架、识别测试点、重构代码、编写易于维护的测试用例等。通过编写全面、可靠的单元测试,您可以提高代码质量、减少错误和维护成本。
最后:下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

