x.1 高bias和高variance的意义
我们引入高bias和高variance是为了衡量模型是underfit还是overfit的问题。我们使用Jtrain来代表训练误差,使用Jcv即交叉熵损失表示验证集误差。高bias意味着欠拟合,而高variance意味着过拟合,我们可以通过下面这张图片更加了解,
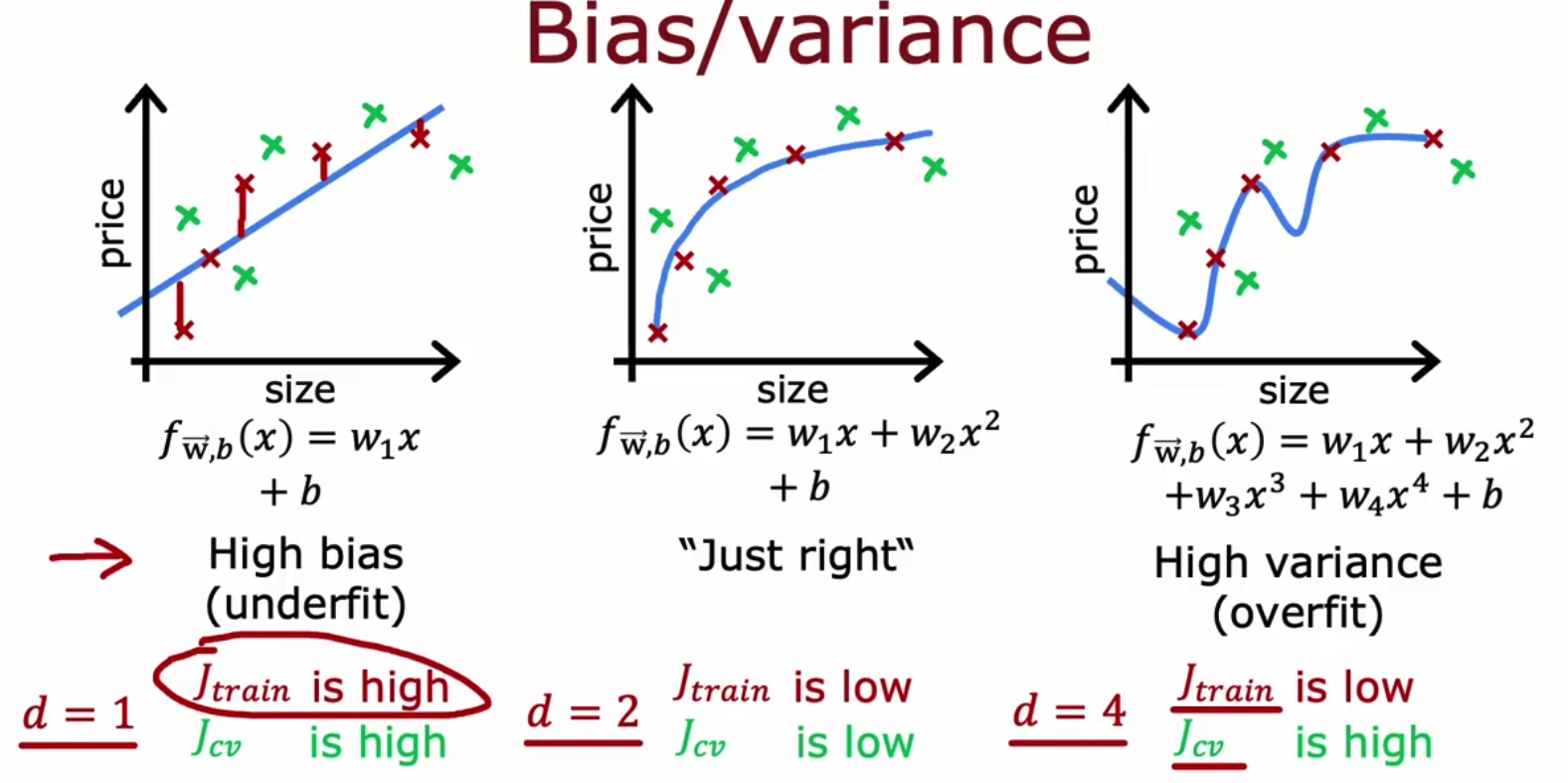
当然也会存在,既高bias又高variance的情况,如下,这种情况很糟糕,
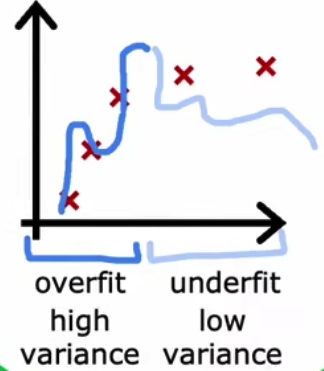
故,模型参数量影响着high bias或者high variance且模型参数量少时必然是high bias而当模型参数量大时则为high variance。
x.2 使用参数量判断
我们绘制参数个数(即模型复杂度)和两个损失函数见的关系,刚开始是欠拟合,随着参数数量的增加(即增加 x 2 , x 3 . . . x^2,x^3... x2,x3...等参),模型逐渐过拟合,
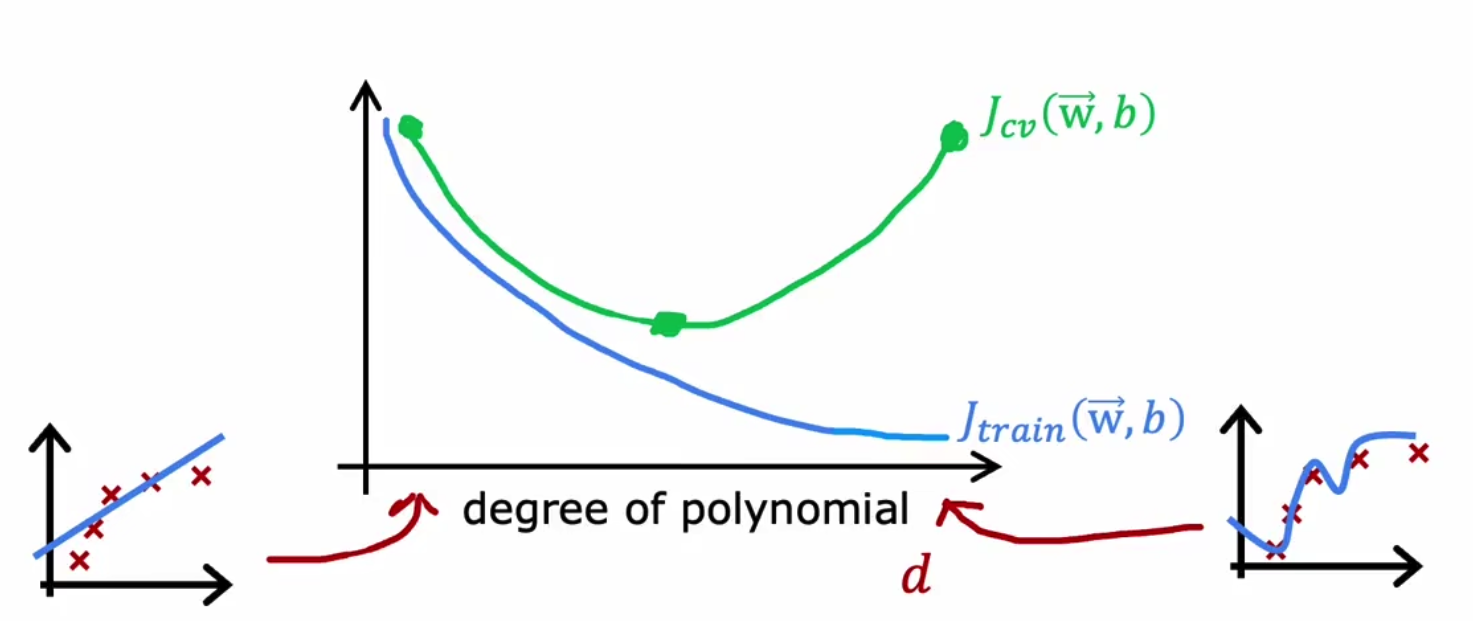
我们将刚开始的情况称为High Bias,而将尾部的情况称为High Variance,
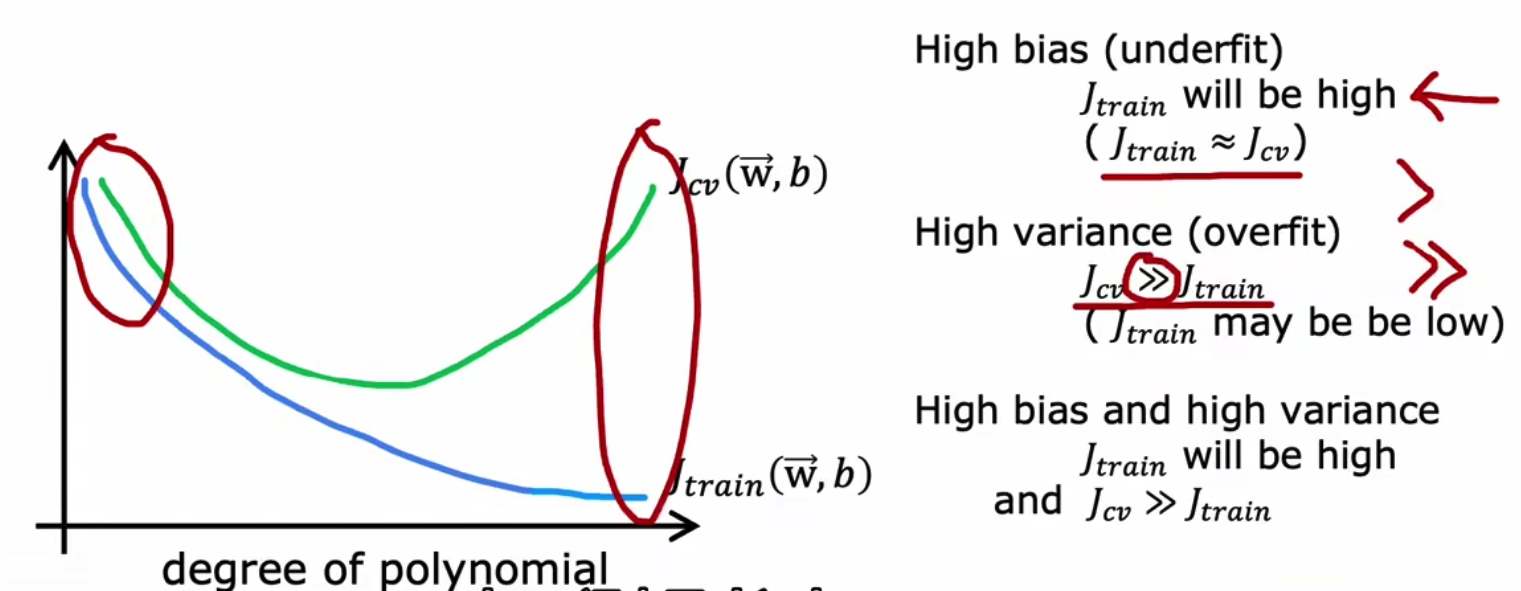
x.3 使用基准线判断判断是high bias还是high variance
我们需要有一个baseline基准,来进行判断,如当Jtrain和base的差值小于Jcv和train差值时候,则是high variance,

所以说基准的存在是非常有必要的。
x.4 使用训练集数量来判断是high bias/variance
使用训练集数量判断,即通过使用learning curves来判断是high bias/variance。
我们通过控制训练集数量,以横轴为训练集数量,以纵轴为两个损失函数值,绘制图像,High bias是随着训练集增加,Jtrain会上升,而Jcv下降,并二者高于基准biasline,
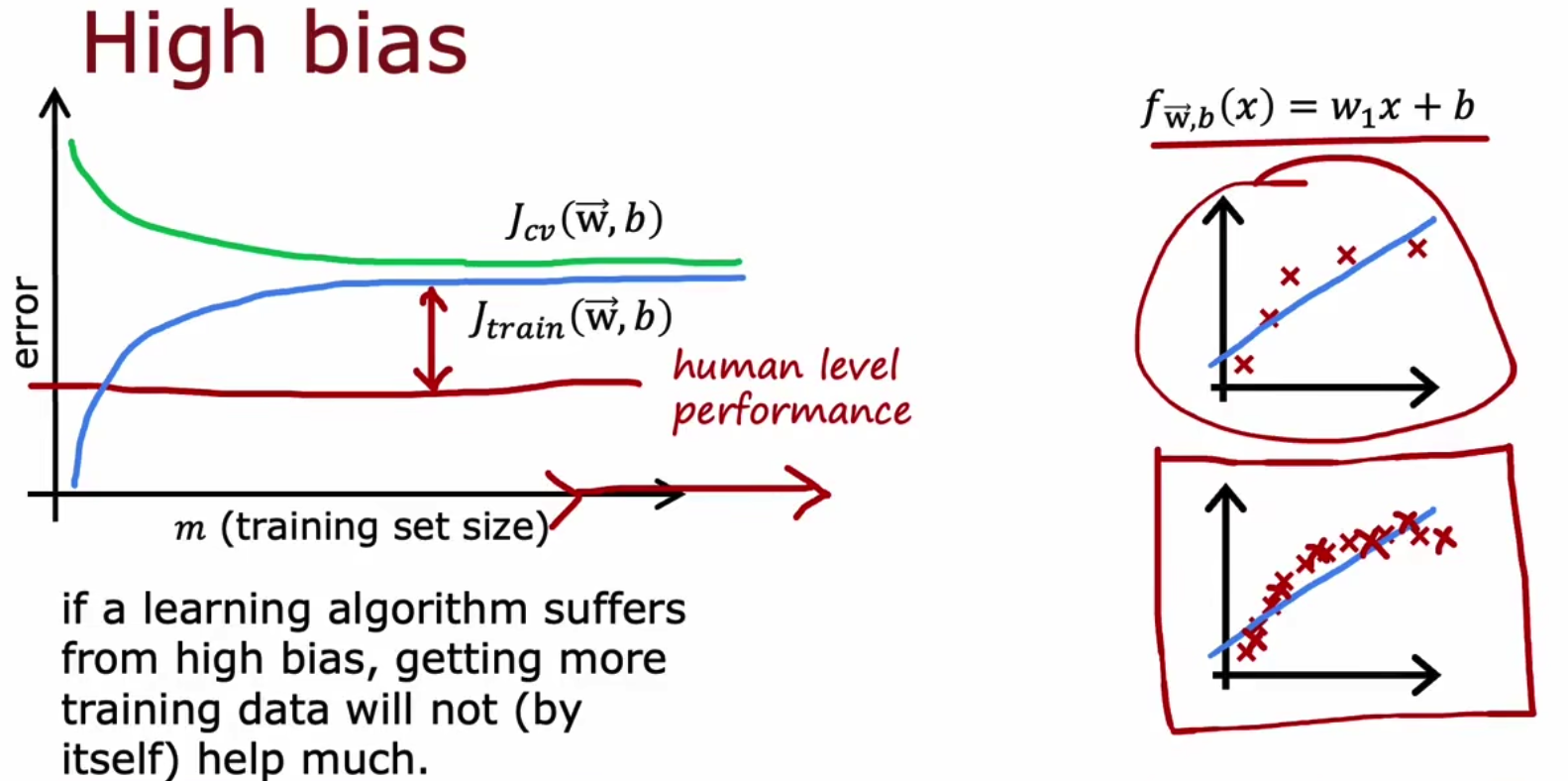
而high variance则是随着训练集数量增加,二者更加接近基准baseline,

x.5 理论上如何解决high bias/variance问题
理论上如何解决这个问题,因为data数量往往固定,所以当high bias时则增加模型参数量,而当high variance时则增加L2正则化权重值。我们可以将方法用前面的PPT解答,有3种解决high variance方法和3种解决high bias方法,

x.6 使用正则化权重来解决high variance问题
我们的损失函数如下,
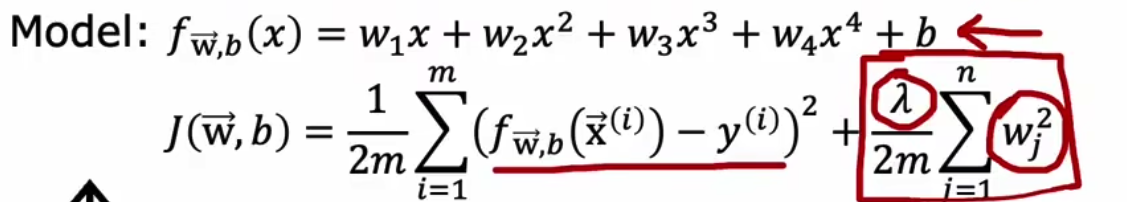
我们通过控制lambda来观察,当使用较大惩罚时候,则会欠拟合,反之则过拟合,
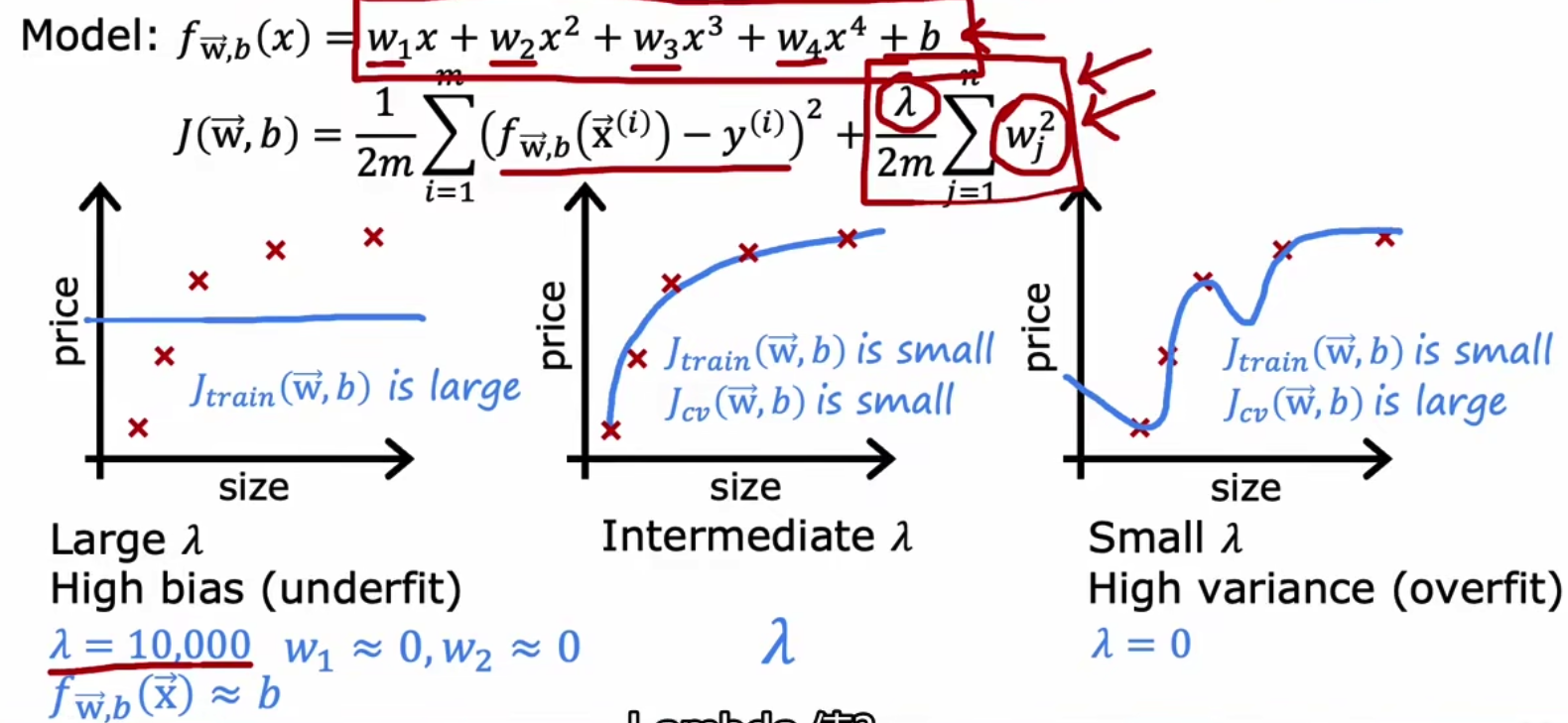
所以我们最佳方法是在实验中,使用多个lambda,然后选择Jcv较小的那一组lambda,

而lambda和两个损失函数间的图像如下所示,
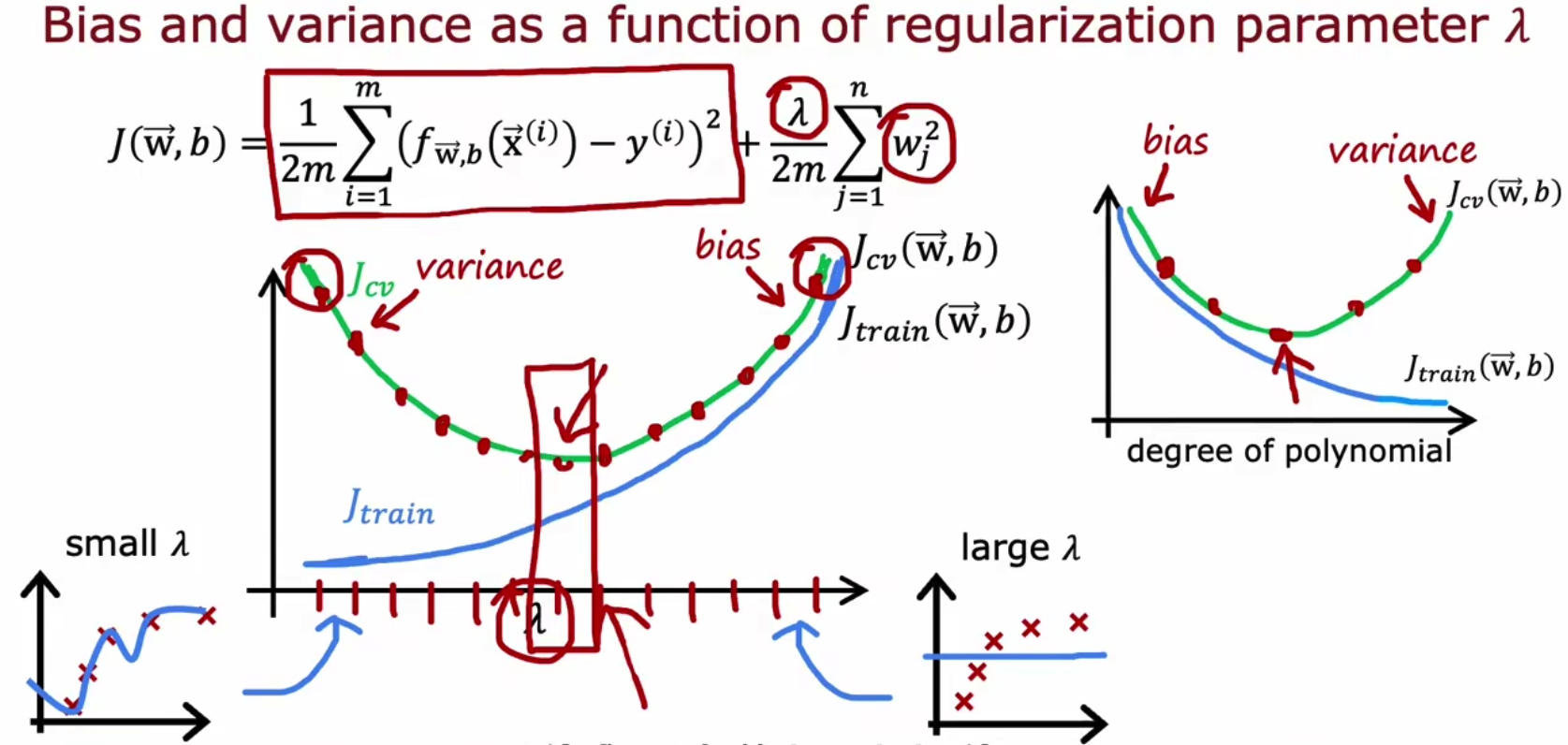
x.7 实践上如何解决high bias/variance问题
最正确的迭代模型如下,虽然我们实际开发并不使用,
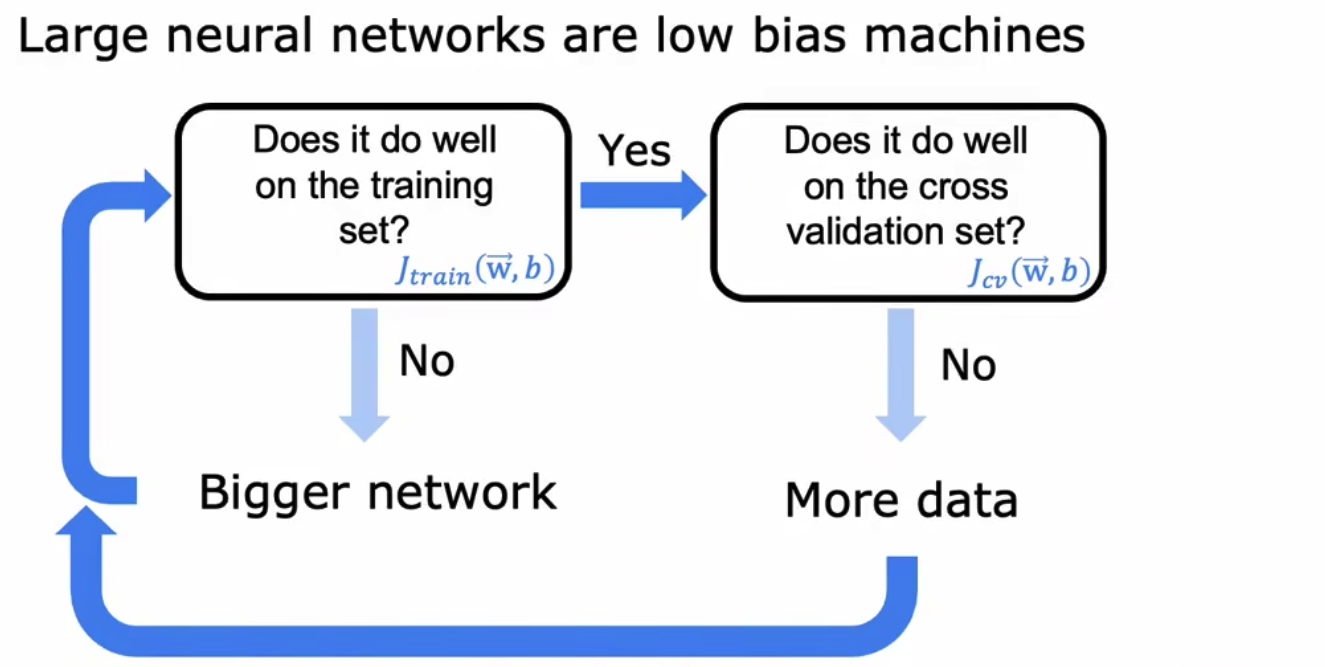
在实际中,我们往往会使用一个非常大的模型,这时候必然存在high variance的问题,此时我们通过调整L2正则化的权重来使得Jcv下降。通过实验我们知道,当使用一个大型网络+适当的L2正则化,其效果往往优于或者等于大小刚好合适的网络。所以我们往往先将Jtrain调下去,再用L2权重调整Jcv。
实际上的代码实现如下,
