nn.Embedding是一种词嵌入的方式,跟one-hot相似但又不同,会生成低维稠密向量,但是初始是随机化的,需要根据模型训练时进行调节,若使用预训练词向量模型会比较好。
1. one-hot
one-hot是给定每个单词一个索引,然后根据输入文本是否含有这个单词来决定向量。
| 单词 | 索引 |
|---|---|
| we | 0 |
| have | 1 |
| are | 2 |
| any | 3 |
| all | 4 |
| excellent | 5 |
| people | 6 |
| … | … |
给定“We are all excellent people”,生成one-hot向量[1,0,1,0,1,1,1,0,0,…]
2. nn.Embedding
nn.Embedding参数设置:
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, device=None, dtype=None)
- num_embeddings:字典的大小,如上表中字典大小是5000,就写5000。
- embedding_dim:嵌入向量的维度,表示将单词编码为多少维的向量。
- padding_idx:填充索引,意思是填充的索引,向量值默认为全0(可以自定义),相当于unknown,对未知的词编码为零向量。
其他参数并不常用,详情可以参考官网
Note, embedding只接受LongTensor类型的数据,且数据不能大于等于词典大小。
3. 应用
3.1 示例一
import torch
from torch import nn
embedding = nn.Embedding(10, 3) #设置字典大小为10,维度为3
input = torch.LongTensor([[0,2,0,5]]) #设置为LongTensor
vector = embedding(input)
print(vector)

3.2 示例2
import torch
from torch import nn
embedding = nn.Embedding(10, 3, padding_idx=2) #设置字典大小为10,维度为3
input = torch.LongTensor([[0,2,0,5]])
vector = embedding(input)
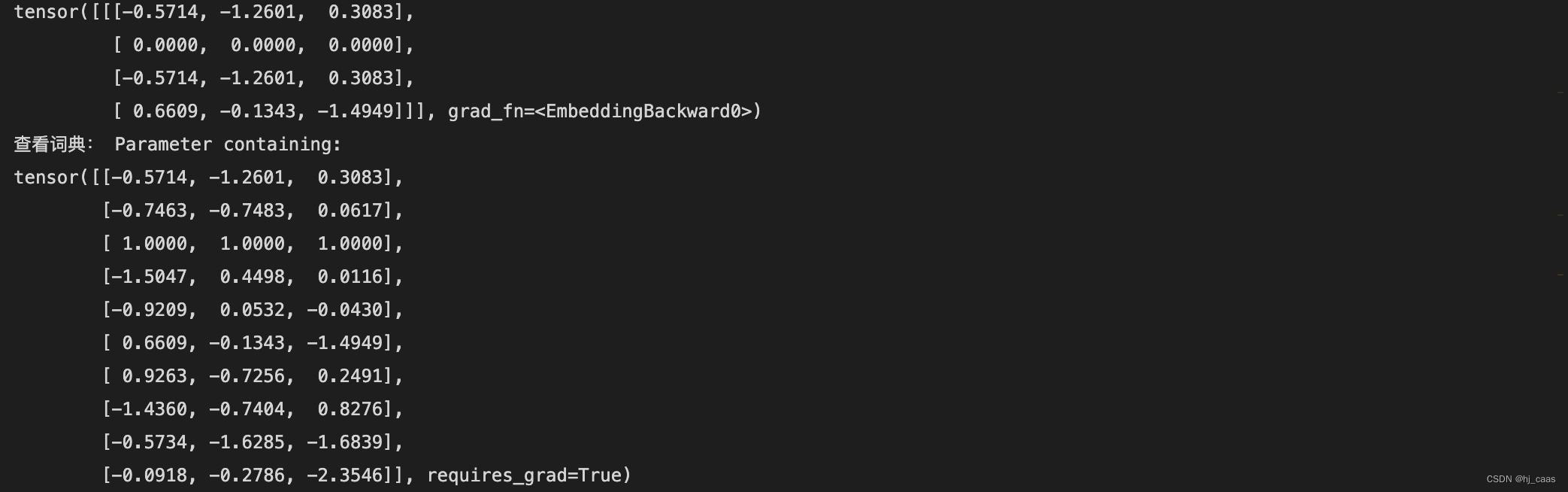
print(vector)
print("查看词典:",embedding.weight) #weight可以查看全部词的向量
通过结果可以看到,词向量跟字典中的向量一一对应。
3.3 示例三
import torch
from torch import nn
padding_idx = 2
embedding = nn.Embedding(10, 3, padding_idx=2) #设置字典大小为10,维度为3
input = torch.LongTensor([[0,2,0,5]])
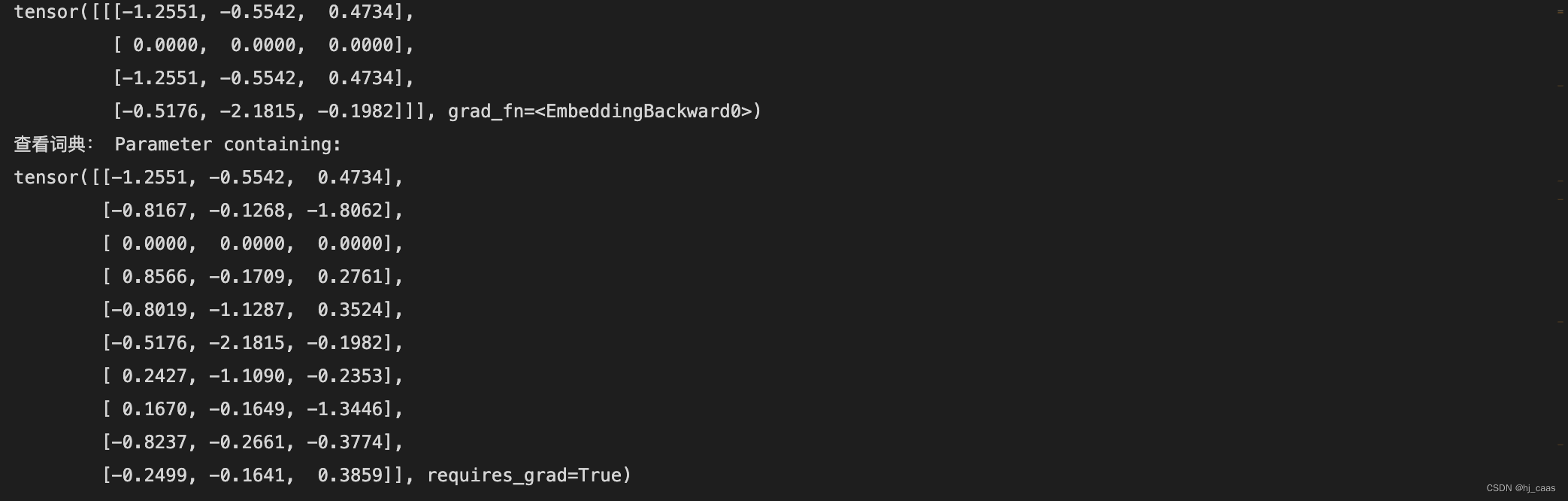
vector = embedding(input)
with torch.no_grad():
embedding.weight[padding_idx] = torch.ones(3) #设置填充向量
print(vector)
print("查看词典:",embedding.weight) #weight可以查看全部词的向量