一、Alexnet
2012年卷积神经网络的开篇鼻祖
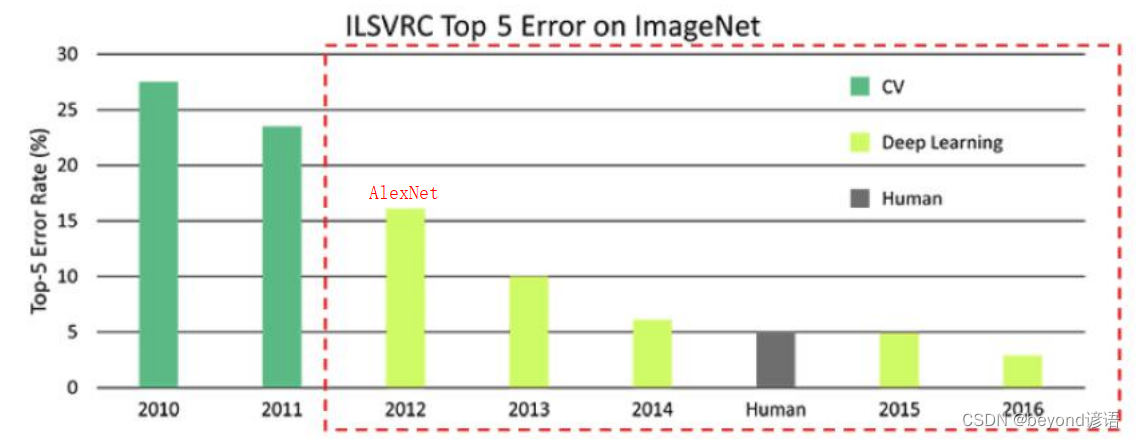
但放到现在确实有很多的弊端和有待改进的地方
1,网络基本架构
8层网络,其中有5层卷积,3层全连接
网络层数的定义:主要看有没有参数运算的参与,例如卷积层和全连接就可以算做层;而激活函数、池化等无参数的参与运算,故不可定义为层。
Local Response Norm层后续被证明是无用的
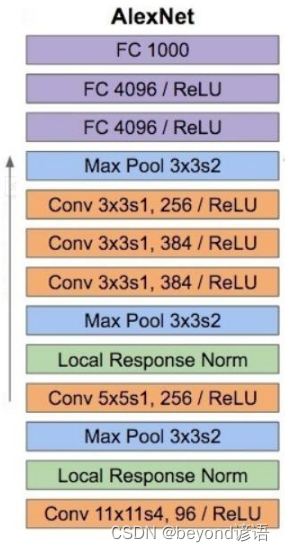
2,不足之处

二、VGG
1,网络基本架构
2014年的提出的VGG网络模型架构
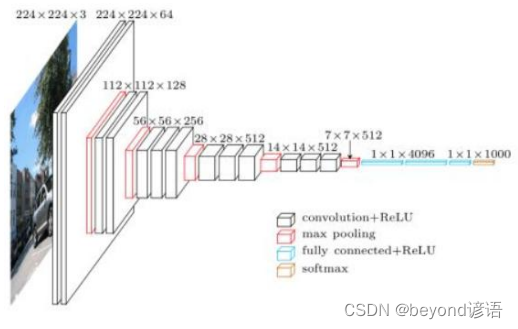
2,改进之处
VGG有很多的版本,其中VGG16为主流的版本
①VGG所有卷积的大小均为3*3,意味着提取特征的时候比较细腻
之前的AlexNet只有8层,而主流的VGG16有16层,VGG19则有19层
②再每次maxpool之后会损失一些特征信息,再下一次卷积的时候通过增加卷积核的数量从而增加特征图的个数来弥补长宽特征信息丢失的损失;例如先64个卷积核卷积,通过maxpool之后,下次卷积会使用128个卷积核进行卷积增加特征图个数弥补损失
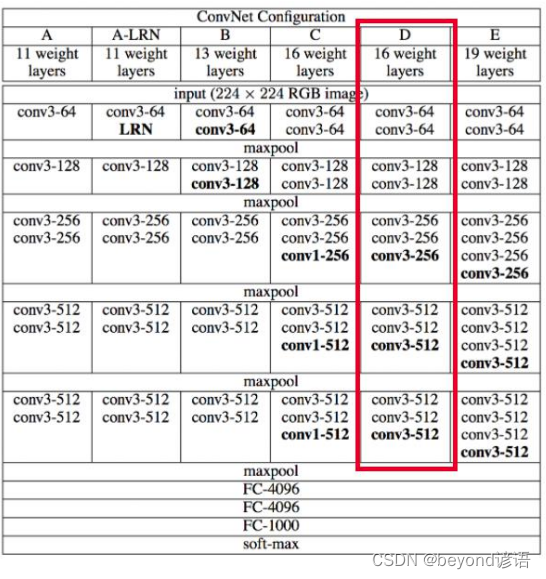
3,不足
AlexNet需要的时间短
相反VGG16网络层数更深一些,所需要的训练时间更长
4,展望
VGG为啥不用17层或者20层,AlexNet网络8层,而VGG16网络16层效果会比8层好,会不会使得网络层数越深,效果就会越好?
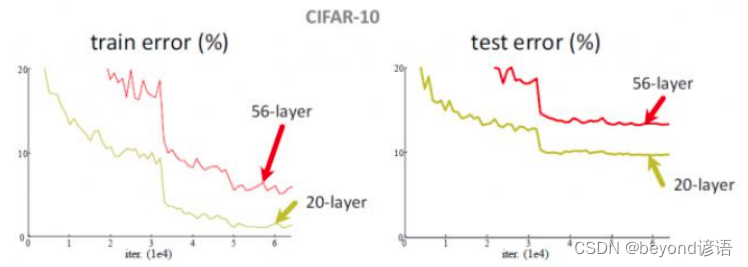
但事实并非如此,VGG56网络模型却没有VGG20网络模型效果好,反而错误率更高。所增加的层数,肯定有特征提取的不好的,故这些新增加的层数,把整体的效果给拉低了。
所谓的深度学习,按理说应该是网络层数越深越好,但是事实并非如此。完了,深度学习是不是也就这样了,没前景了,到这为止了?
随着卷积层的层数增加的时候,不一定所有的卷积层效果都好,因为卷积是在之前的特征的基础上再次去进行特征提取,但是能保证一定会比之前的好吗?不一定
这些问题成为了当时的难题
三、Resnet
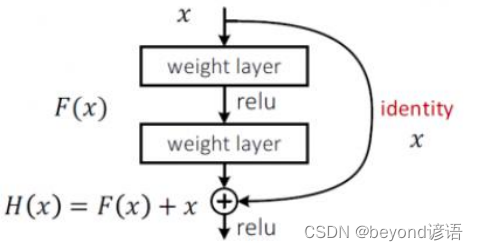
直到2015年中国大佬何恺明提出了Resnet残差网络,首次提出同等映射概念。之前加入了一些层数,即便这些提取特征表现不好,直接为0就好了,相对于加入的层数不用而已,表现不好的层数权重参数设置为0。
1,网络基本架构
x为卷积之后的某一层特征
此时的x有两条路可走,最后进行堆叠相加
直下的是F(x),原本的x还会接到下一层中,若F(x)效果不好,最起码还有之前的特征x可以进行保底,不能保证会变优,但至少可以保证不会比之前的效果要差
2,效果展示
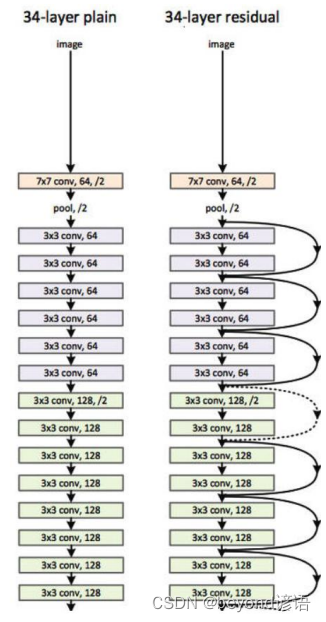
左图是非Resnet网络模型,可以看出,层数越多error值越大
右图是Resnet网络模型,层数越多,error比层数少的要小,模型效果要好
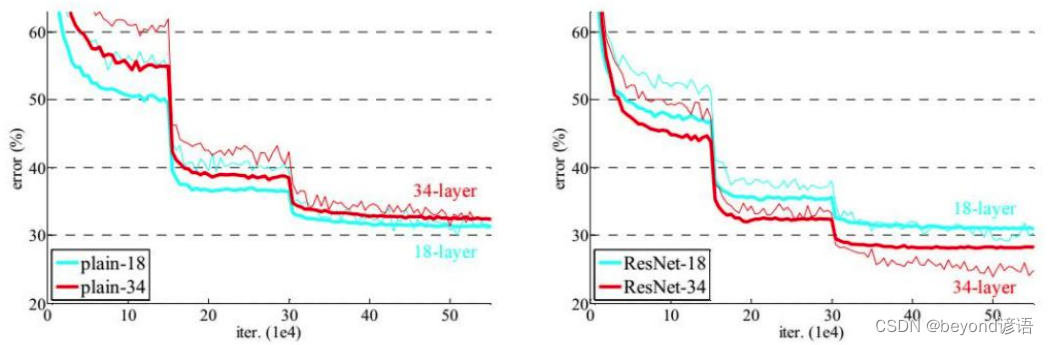
残差网络的提出,相当于把深度学习给再次救活了
3,网络对比
ResNet直接把error值干到了3.57%
VGG19那时候还是7.3%
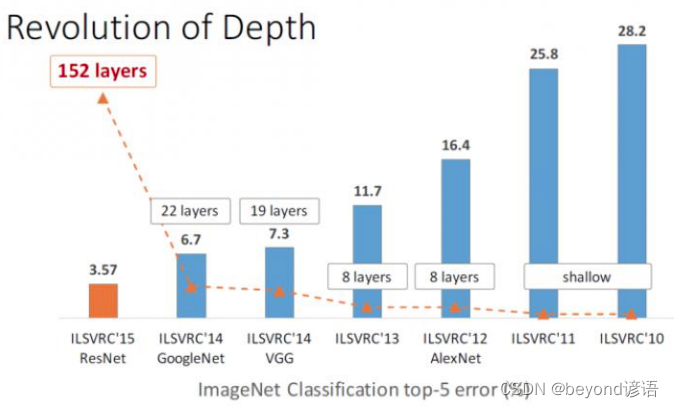
4,展望
ResNet网络理解成特征提取,不建议将其当成一个分类网络
一个问题是分类还是回归,起决定作用的是损失函数和最后的层如何连接
ResNet可以应用到各种各样的框架当中,物体检测、物体追踪、分类、检索、识别等任务都可以使用,相当于是个通用的网络结构
ResNet较为经典的是50和101层