文章目录:
效果图◕‿◕✌✌✌:opencv人脸识别效果图(请叫我真爱粉)
一:环境配置搭建(VS2015+Opencv4.6)
二:下资源文件
第一种:本地生成
第一步:进入自己的文件夹 D:\OpenCV\opencv\sources\samples\dnn\face_detector 第二步:cmd命令行进入改目录下面去 cd /d D:\OpenCV\opencv\sources\samples\dnn\face_detector 第三步:输入执行命令(如果你的目录下面没有download_weights.py文件夹,用第二种方法) Python download_weights.py
第二种 直接下载
地址:data——>modelsa——>face_detector文件夹下载
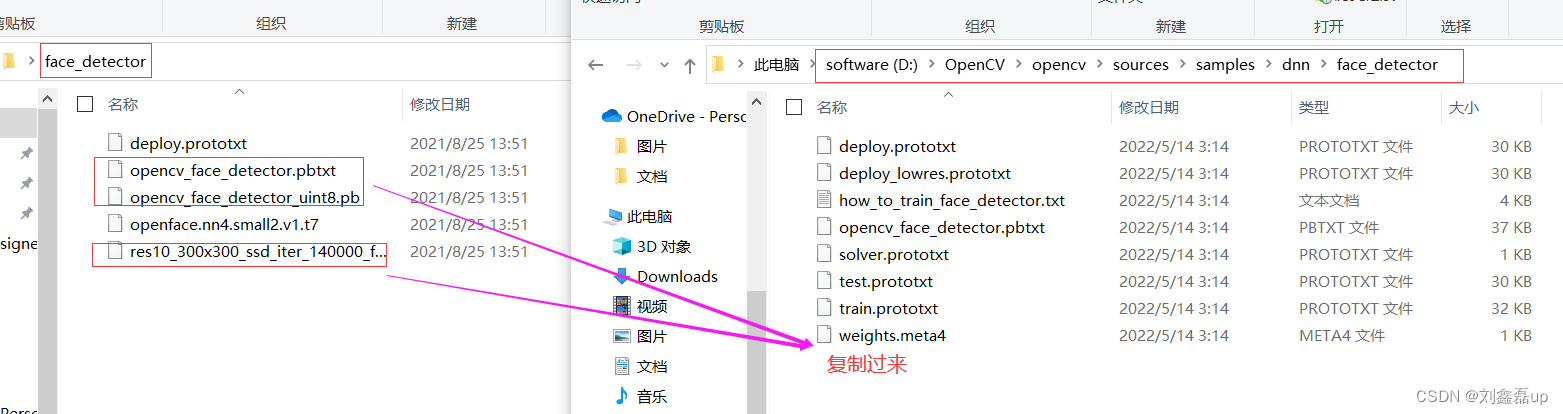
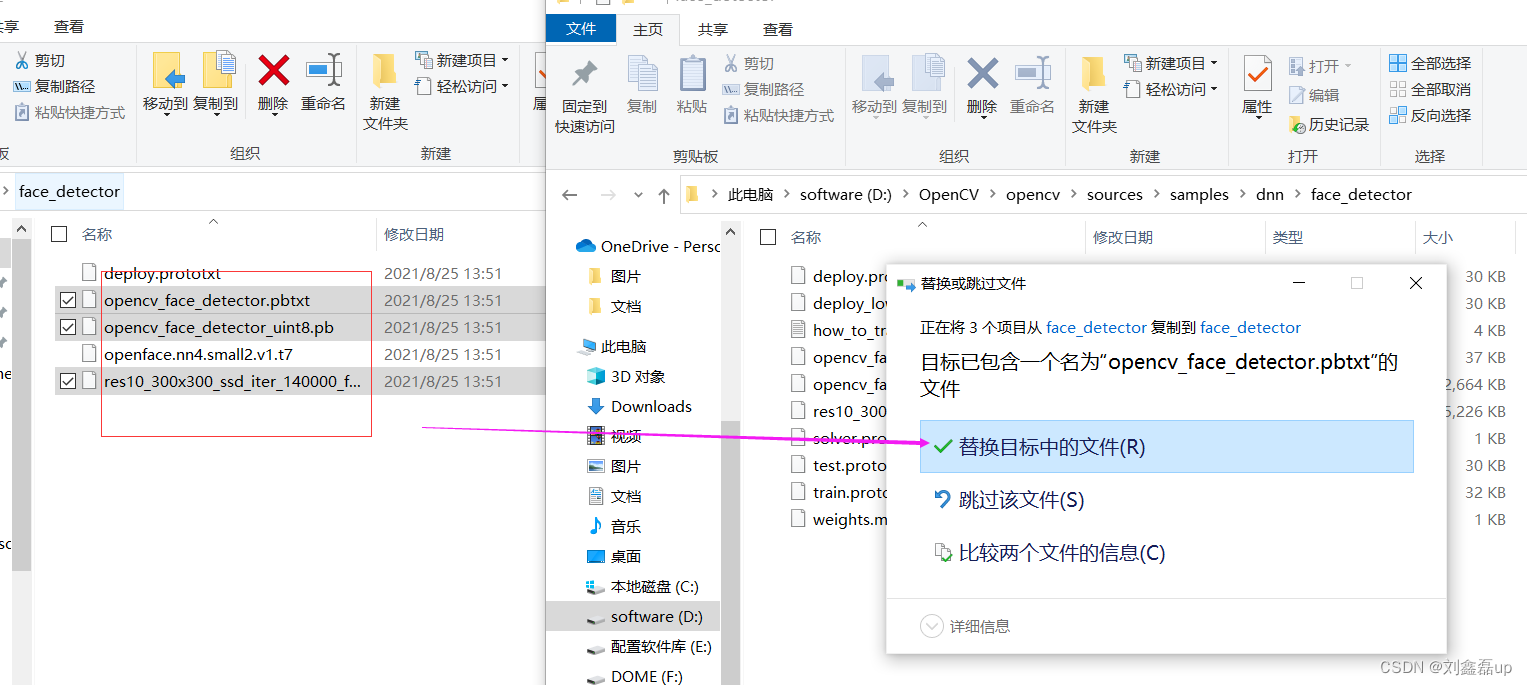
三:代码展示
窗口布局
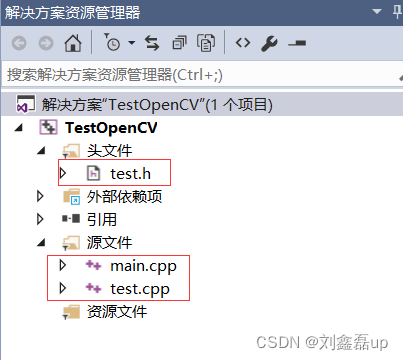
main.cpp
#include<opencv2/opencv.hpp> #include<iostream> #include<test.h> using namespace std; using namespace cv; int main() { //读取进来的数据以矩阵的形势 Mat src = imread("F:/images/gril.jpg", IMREAD_ANYCOLOR); //第二个参数代表显示一张灰度图像 //看是否是空图片 if (src.empty()) { printf("图片不存在"); return -1; } //在主函数中调用创建的类对象 QuickDemo qd; //实时人脸检测 qd.face_detection_demo(src); waitKey(0); //执行到这句,程序阻塞。参数表示延时时间。单位ms毫秒 destroyAllWindows(); //销毁前面创建的显示窗口 return 0; }
test.h
#include<opencv2/opencv.hpp> using namespace cv; //创建一个QuickDemo对象 class QuickDemo { public: //实时人脸检测 void QuickDemo::face_detection_demo(Mat &image); };
test.cpp
#include<test.h> #include<opencv2/dnn.hpp> //命名空间 using namespace cv; using namespace std; //实时人脸检测 void QuickDemo::face_detection_demo(Mat &image) { //自己opencv的face_detector文件夹路径 std::string root_dir = "D:/OpenCV/opencv/sources/samples/dnn/face_detector/"; //读取以TensorFlow框架格式存储的网络文件 //opencv_face_detector_uint8.pb模型 opencv_face_detector.pbtxt配置文件 dnn::Net net = dnn::readNetFromTensorflow(root_dir + "opencv_face_detector_uint8.pb", root_dir + "opencv_face_detector.pbtxt"); //第一种:对本地视频进行识别 //自己视频的地址 VideoCapture capture("F:/images/kunkun.mp4"); //第二种:摄像头进行人脸检测 //VideoCapture capture(0); // 定义一个Mat对象,用于存储捕获到的视频帧 Mat frame; while (true) { // 从摄像头捕获一帧视频,并将捕获到的视频帧传入frame capture.read(frame); // 如果捕获到的视频帧为空,跳出循环 if (frame.empty()) { break; } //左右翻转 //flip(frame, frame, 1); //DNN模块从图像创建blob的过程:从给定的图像帧创建一个blob,该blob可以用于深度学习模型的输入 //参数:输入的图像帧,图像缩放的因子,图像裁剪的大小,图像的色彩空间转换,后面2个参数是确定图像是否需要进行翻转或旋转的标记 Mat blob = dnn::blobFromImage(frame, 1.0, Size(300, 300), Scalar(104, 177, 123), false, false); // 设置深度学习模型的输入:将blob作为模型的输入。blob是一个包含了图像数据的矩阵,通常用于模型的输入层 net.setInput(blob); //是OpenCV中DNN模块的一个函数,用于前向传播计算模型的输出 Mat probs = net.forward(); //计算模型的预测结果 //从预测结果中获取人脸检测的矩阵 //新的Mat对象detectionMat:它的大小是probs的第二维和第三维的大小,数据类型为32位浮点数(对应于OpenCV中的CV_32F) Mat detectionMat(probs.size[2], probs.size[3], CV_32F, probs.ptr<float>()); // 解析检测结果,对每一个检测到的人脸进行处理 for (int i = 0; i < detectionMat.rows; i++) { //从detectionMat矩阵中提取第i行、第2列的元素,并将其存储在confidence变量中 // 获取检测到的人脸的概率(即得分),如果得分大于0.5,则认为检测到了人脸 float confidence = detectionMat.at<float>(i, 2); // 第三个值 得分 if (confidence > 0.5) { // 因为预测来的值为[0,1]范围的数,我们还需要*原图像的宽度和长度,得到实际的位置坐标 //从detectionMat中获取第i行、第3列的元素,也就是每个检测到的对象的置信度(confidence) //这是深度学习模型输出的一个值,表示模型对检测结果的信任程度 //第1个坐标的起始位置 //表示1个坐标或边界的起始位置的x坐标。 int x1 = static_cast<int>(detectionMat.at<float>(i, 3)*frame.cols); //frame.cols帧的列数 //表示1个坐标或边界的起始位置的y坐标。 int y1 = static_cast<int>(detectionMat.at<float>(i, 4)*frame.rows); //第2个坐标的起始位置 int x2 = static_cast<int>(detectionMat.at<float>(i, 5)*frame.cols); int y2 = static_cast<int>(detectionMat.at<float>(i, 6)*frame.rows); // 在原图像上画出检测到的人脸的位置框,并用红色边框显示出来 //左上角坐标(x1,y1)和右下角坐标(x2,y2) Rect box(x1, y1, x2 - x1, y2 - y1); //画矩形:原始图像,坐标,红色,线条宽度为2,线条类型为8,没有填充 rectangle(frame, box, Scalar(0, 0, 255), 2, 8, 0); } } imshow("人脸检测演示", frame); int c = waitKey(1); if (c == 27) { break;// 退出 } } capture.release(); //释放资源 }