1 FullGC调优
2 使用arthas诊断案例
2.1 使用arthas确定某一个耗时的请求来自哪一个controller,并且分析以及代码优化
2.1.1 为什么要做第一步的“确定请求来源的controller”?
分析:首先我们需要知道我们想要分析哪一个请求,比如用户登录请求,其次我们需要了解springMVC的特性,我们知道所有的请求都会走DispatcherServet这个类,然后会从一个getHandler的方法中返回给DispatcherServet处理该请求的controller。
2.1.2 第一阶段:找到具体的处理方法
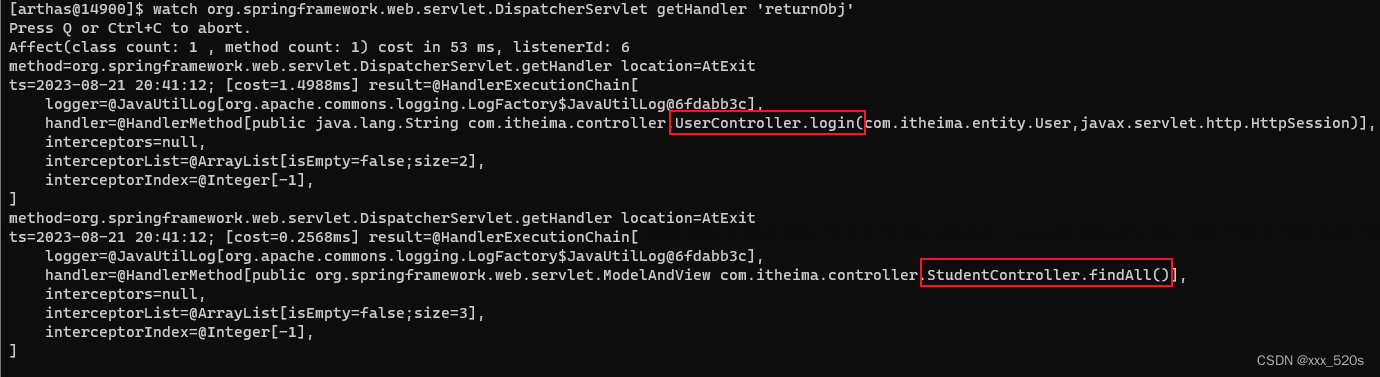
- 所以我们的重点就是直接使用watch命令观测这个getHandler方法的输入参数和返回值;
watch org.springframework.web.servlet.DispatcherServlet getHandler 'returnObj'
- 然后在前端或者postman上触发一次这样的请求,比如我这里触发登录请求。
 3. 查看得到的哪些controller:
3. 查看得到的哪些controller:
通过下面的标红的部分,可知这个登录请求经过了UserController控制器的login方法,和StudentController控制器的findAll方法。
2.1.3 第二阶段:分析
- 入参和返回值分析:使用watch命令观察这个具体的controller中的处理方法的入参和返回值
watch com.itheima.controller.* * '{params,returnObj}' -x 2
得到的结果如下所示:
method=com.itheima.controller.UserController.login location=AtExit
ts=2023-08-21 20:55:52; [cost=5.2786ms] result=@ArrayList[
@Object[][
@User[User{
id=null, name='newboy', password='123'}],
@StandardSessionFacade[org.apache.catalina.session.StandardSessionFacade@2a57d000],
],
@String[forward:/student/list],
]
method=com.itheima.controller.StudentController.findAll location=AtExit
ts=2023-08-21 20:55:52; [cost=6.0088ms] result=@ArrayList[
@Object[][isEmpty=true;size=0],
@ModelAndView[
view=@String[list],
model=@ModelMap[isEmpty=false;size=1],
status=null,
cleared=@Boolean[false],
],
]
- 调用链路和节点耗时分析:使用trace命令得到这个控制器处理方法的调用链路以及各个节点上耗费的时间
trace com.itheima.controller.* login

我们发现这个controller调用了"com.itheima.service.UserService:login()"这个最耗时的方法
- 于是我们可以继续分析这个业务层的login方法
trace com.itheima.service.UserService login
结果如下所示:我们发现最耗时的还是访问数据库的com.itheima.dao.UserDao:login()方法,由此可见,IO操作往往占用处理一个请求的绝大多数时间
Affect(class count: 3 , method count: 2) cost in 78 ms, listenerId: 12
`---ts=2023-08-21 21:10:42;thread_name=http-nio-8080-exec-3;id=1a;is_daemon=true;priority=5;TCCL=org.apache.catalina.loader.ParallelWebappClassLoader@64e2f243
`---[7.7167ms] com.sun.proxy.$Proxy25:login()
`---[28.93% 2.2322ms ] com.itheima.service.impl.UserServiceImpl:login()
`---[98.83% 2.206ms ] com.itheima.dao.UserDao:login() #17
- 查看这个生成的代理方法,并且使用jad命令反编译
jad com.sun.proxy.$Proxy24 login
ClassLoader:
+-java.net.URLClassLoader@1c4af82c
+-sun.misc.Launcher$AppClassLoader@764c12b6
+-sun.misc.Launcher$ExtClassLoader@3d82c5f3
Location:
public final User login(User user) {
try {
return (User)this.h.invoke(this, m3, new Object[]{
user});
}
catch (Error | RuntimeException throwable) {
throw throwable;
}
catch (Throwable throwable) {
throw new UndeclaredThrowableException(throwable);
}
}
2.1.4 第三阶段:代码优化
- sql优化:
注意:此项目中最耗费时间的方法是一个路径为com.sun.proxy.$Proxy25:login()的代理方法,这个方法是mybatis插件生成的,一般我们不能对其进行改动,如果访问数据库确实非常耗时,那也是去修改sql语句以及调整数据库的相关参数
- 如果是处理请求的业务层方法非常耗时,那一般我们的代码优化涉及到修改字节码文件,所以需要事先使用dump命令将这个业务方法所在的字节码文件保存到另一个目录中;假设我们第6步中的得到具体实现类-com.itheima.service.impl.UserServiceImpl:login()方法非常耗时,我们现在需要改进他
保存UserServiceImpl这个类到另一个目录以便恢复,
dump com.itheima.service.impl.UserServiceImpl > /root/UserServiceImpl.java
反编译UserServiceImpl实现类到指定目录,
jad --source-only com.itheima.service.impl.UserServiceImp > /root/UserServiceImpl.java
在本地idea或者在vim编辑器中修改 /root/UserServiceImpl.java文件,并且使用mc命令编译这个java文件到/root/bbb/目录下
mc -d /root/bbb/ /root/UserServiceImpl.java
使用redefine命令加载新的字节码
redefine /root/bbb/UserServiceImpl.class
3 OOM的故障如何排查和解决
当Java应用程序抛出OutOfMemoryError(通常简称为OOM)时,表示JVM无法为对象分配更多的内存,因为它已经耗尽了可用的内存。以下是排查和解决OOM的一般步骤:
-
查看错误信息:OOM错误消息通常会给出更多的上下文,例如是否是堆内存溢出 (
java.lang.OutOfMemoryError: Java heap space) 还是元空间溢出 (java.lang.OutOfMemoryError: Metaspace)。 -
生成堆转储:当发生OOM时,可以配置JVM生成堆转储(heap dump)。这可以通过JVM参数实现:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dump。堆转储文件可以使用工具如Eclipse MAT或VisualVM进行分析,找出占用大量内存的对象。 -
监控工具:使用像
VisualVM、JConsole、Grafana、Prometheus等工具,实时监控JVM的内存使用情况。 -
分析日志:检查应用程序和服务器的日志,寻找任何异常的行为或长时间运行的任务。
-
代码审查:寻找可能的内存泄露来源,例如长时间存活的大对象、集合类没有正确清除、数据库连接没有关闭等。
-
调整JVM参数:可以考虑增加堆内存限制(
-Xms和-Xmx),但这只是短期解决方案。长期来看,还是需要找出OOM的根本原因。
4 如果是因为某一个运行时的SQL语句查询出的数据量太大导致堆OOM,这种如何定位到这条SQL语句?
-
日志:查看数据库查询日志和应用程序日志,看是否有长时间运行的大查询。启用SQL慢查询日志可能对此有帮助。
-
监控工具:许多数据库都有监控工具,如MySQL的
Performance Schema和Information Schema,可以查看正在运行或最近执行的查询。 -
堆分析:OOM时生成的堆转储可以显示哪些对象占用了大量的内存。例如,如果你使用Hibernate,可能会看到大量的Hibernate实体。
-
分析代码:检查代码中的数据库查询,特别是那些可能返回大量数据的查询。考虑是否真的需要加载所有这些数据,或者是否可以分批加载或进行更多的过滤。
-
应用监控工具:工具如
New Relic、Dynatrace或Elastic APM等可以监控应用程序性能和数据库查询,帮助你定位高开销的查询。
总之,处理OOM需要系统地排查和多角度的分析。对于数据库查询导致的OOM,重点是优化查询和合理地管理内存使用,例如分页、使用流处理等。
5 大厂实习时的线上OOM故障排查,并且优化代码的case
5.1 背景
在大厂实习期间,接过一个需求是进行数据同步操作,将lldp接线和build的接线进行比较判断,lldp接线记录数据中心初始的接线状况,build为规划建设中的接线状况,规划建设的未实际实施的,而建设中的是计划实施但是还没有做的,如果实施成功了就会将build的接线数据替换到lldp,然后build用于存储新的建设规划数据。我的这个需求就是需要将lldp和build接线差异做一个比较,将比较信息插入到新的表中,方便数据中心运维人员查看,并且将建设规划的接线覆盖掉lldp中的接线,从而完成接线的建设。
5.2 故障产生的原因
lldp和build模块记录了多个数据中心的内部接线还有跨数据中心的实际接线情况,一开始我直接将测试库中的lldp表中记录的所有数据中心的接线都拿出来了然后放入到一个列表中,然后再取出build中所有的接线,这样两个进行比较。测试的时候没有问题,但是到了线上运行没多久就oom了,经过排查发现是因为这个select * from lldp left jon ... left join .... 语句导致的,因为线上的数据库接线记录得所有数据中心的接线有几十万条,每一条是联表查询的结果,所以当一次性全表查询时就OOM了。
5.3 排查步骤
可以参考第三步,
当Java应用程序抛出OutOfMemoryError(通常简称为OOM)时,表示JVM无法为对象分配更多的内存,因为它已经耗尽了可用的内存。以下是排查和解决OOM的一般步骤:
-
查看错误信息或者日志:OOM错误消息通常会给出更多的上下文,例如是否是堆内存溢出 (
java.lang.OutOfMemoryError: Java heap space) 还是元空间溢出 (java.lang.OutOfMemoryError: Metaspace)。 -
生成堆转储:当发生OOM时,可以配置JVM生成堆转储(heap dump)。这可以通过JVM参数实现:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/dump。堆转储文件可以使用工具如Eclipse MAT或VisualVM进行分析,找出占用大量内存的对象。
5.4 解决方案
使用粒度更小的比较方案,每次只按照单个的数据中心的粒度比较差异,比较完这个数据中心后,再比较下一个数据中心,这样每一个数据中心的接线数量不过10w条。