前言
公司开启新项目了,想着准备亮一手 Kotlin 协程应用到项目中去,之前有对 Kotlin 协程的知识进行一定量的学习,以为自己理解协程了,结果……实在拿不出手!

为了更好的加深记忆和理解,更全面系统深入地学习 Kotlin 协程的知识,协程将分为三部分来讲解,本文是第一篇:
Kotlin 协程实战进阶(一、筑基篇)
本文大纲
一、概述
协程的概念在1958年就开始出现(比线程还早), 目前很多语言开始原生支, Java 没有原生协程但是大型公司都自己或者使用第三方库来支持协程编程, 但是Kotlin原生支持协程。
Android 中的每个应用都会运行一个主线程,它主要是用来处理 UI,如果主线程上需要处理的任务太多,应用就感觉被卡主一样影响用户体验,得让那些耗时的任务不阻塞主线程的运行。要做到处理网络请求不会阻塞主线程,一个常用的做法就是使用回调,另一种是使用协程。
协程概念
很多人都会问协程是什么?这里引用官方的解释:
1.协程通过将复杂性放入库来简化异步编程。程序的逻辑可以在协程中顺序地表达,而底层库会为我们解决其异步性。该库可以将用户代码的相关部分包装为回调、订阅相关事件、在不同线程(甚至不同机器)上调度执行,而代码则保持如同顺序执行一样简单。
2.协程是一种并发设计模式。
协程就像轻量级的线程,为什么是轻量的?因为协程是依赖于线程,一个线程中可以创建N个协程,很重要的一点就是协程挂起时不会阻塞线程,几乎是无代价的。而且它基于线程池API,所以在处理并发任务这件事上它真的游刃有余。
协程只是一种概念,它提供了一种避免阻塞线程并用更简单、更可控的操作替代线程阻塞的方法:协程挂起和恢复。本质上Kotlin协程就是作为在Kotlin语言上进行异步编程的解决方案,处理异步代码的方法。
有可能有的同学问了,既然它基于线程池,那我直接使用线程池或者使用 Android 中其他的异步任务解决方案,比如 Handler、AsyncTask、RxJava等,不更好吗?
协程可以使用阻塞的方式写出非阻塞式的代码,解决并发中常见的回调地狱。消除了并发任务之间的协作的难度,协程可以让我们轻松地写出复杂的并发代码。一些本来不可能实现的并发任务变的可能,甚至简单,这些才是协程的优势所在。
作用
- 1.协程可以让异步代码同步化;
- 2.协程可以降低异步程序的设计复杂度。
特点
- 轻量:您可以在单个线程上运行多个协程,因为协程支持挂起,不会使正在运行协程的线程阻塞。挂起比阻塞节省内存,且支持多个并行操作。
- 内存泄漏更少:使用结构化并发机制在一个作用域内执行多项操作。
- 内置取消支持:取消操作会自动在运行中的整个协程层次结构内传播。
- Jetpack 集成:许多 Jetpack 库都包含提供全面协程支持的扩展。某些库还提供自己的协程作用域,可供您用于结构化并发。
Kotlin Coroutine 生态
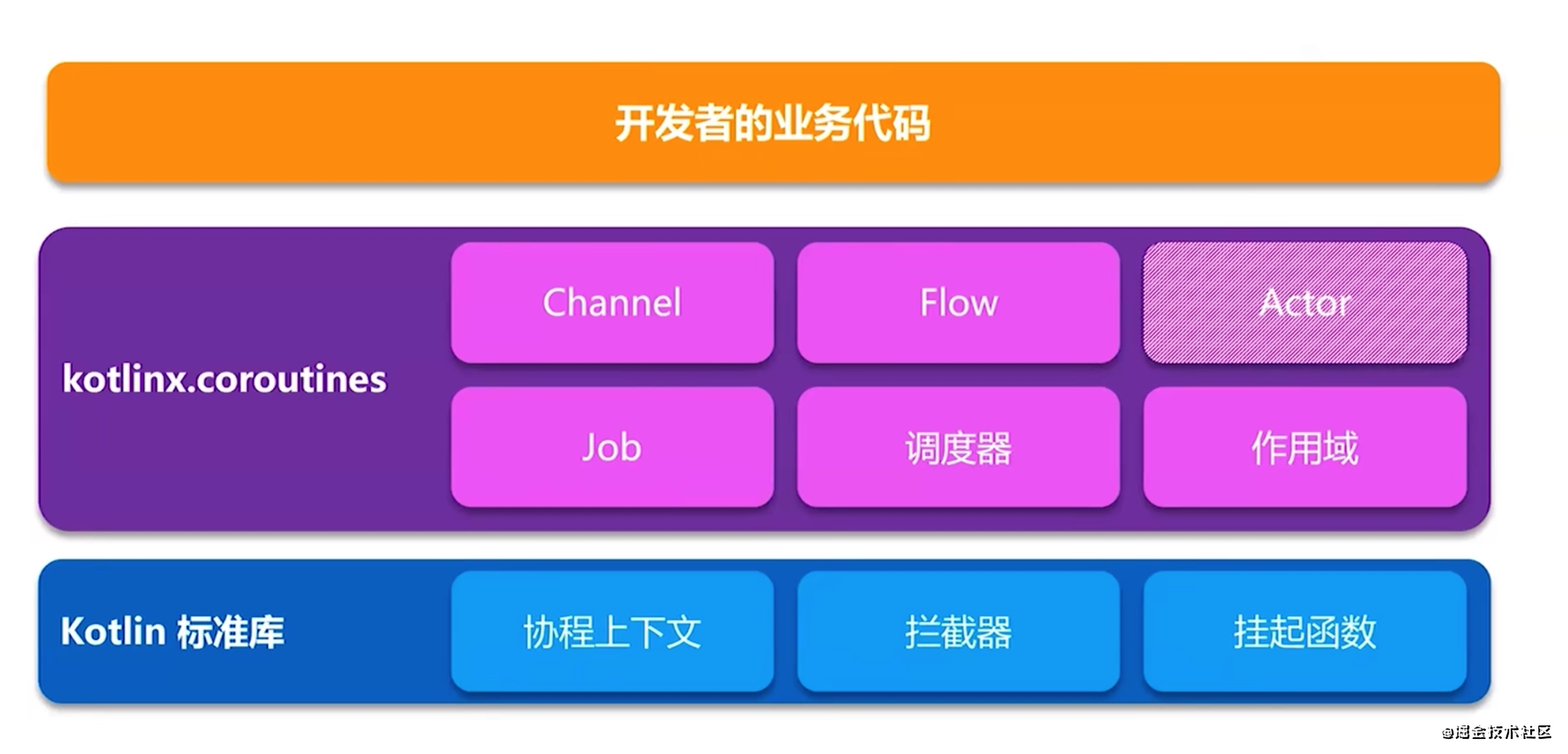
kotlin的协程实现分为了两个层次:
- 基础设施层:标准库的协程API,主要对协程提供了概念和语义上最基本的支持;
- 业务框架层 kotlin.coroutines:协程的上层框架支持,基于标准库实现的封装,也是我们日常开发使用的协程扩展库。
依赖库
在 project 的 gradle 添加 Kotlin 编译插件:
dependencies {
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:1.4.32"
}
要使用协程,还需要在app的 build.gradle 文件中添加依赖:
dependencies {
//协程标准库
implementation "org.jetbrains.kotlin:kotlin-stdlib:1.4.32"
//协程核心库
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.4.3"
//协程Android支持库,提供安卓UI调度器
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-android:1.4.3"
}
这里我们主要使用协程扩展库, kotlin协程标准库太过于简陋不适用于开发者使用。
二、原理
协程的概念最核心的点就是函数或者一段程序能够被挂起,稍后再在挂起的位置恢复。协程通过主动让出运行权来实现协作,程序自己处理挂起和恢复来实现程序执行流程的协作调度。因此它本质上就是在讨论程序控制流程的机制。
使用场景
kotlin协程基于Thread相关API的封装,让我们不用过多关心线程也可以方便地写出并发操作,这就是Kotlin的协程。协程的好处本质上和其他线程api一样,方便。
在 Android 平台上,协程有两个主要使用场景:
- 1、线程切换,保证线程安全。
- 2、处理耗时任务(比如网络请求、解析
JSON数据、从数据库中进行读写操作等)。
Kotlin协程的原理
我们使用 Retrofit 发起了一个异步请求,从服务端查询用户的信息,通过 CallBack 返回 response:
val call: Call<User> = userApi.getUserInfo("suming")
call.enqueue(object : Callback<User> {
//成功
override fun onResponse(call: Call<User>, response: Response<User>) {
val result = response.body()
result?.let {
showUser(result) }
}
//失败
override fun onFailure(call: Call<User>, t: Throwable) {
showError(t.message)
}
})
很明显我们需要处理很多的回调分支,如果业务多则更容易陷入「回调地狱」繁琐凌乱的代码中。
使用协程,同样可以像 Rx 那样有效地消除回调地狱,不过无论是设计理念,还是代码风格,两者是有很大区别的,协程在写法上和普通的顺序代码类似,同步的方式去编写异步执行的代码。使用协程改造后代码如下:
GlobalScope.launch(Dispatchers.Main) {
//开始协程:主线程
val result = userApi.getUserSuspend("suming")//网络请求(IO 线程)
tv_name.text = result?.name //更新 UI(主线程)
}
这就是kotlin最有名的【非阻塞式挂起】,使用同步的方式完成异步任务,而且很简洁,这是Kotlin协程的魅力所在。之所有可以用看起来同步的方式写异步代码,关键在于请求函数getUserSuspend()是一个挂起函数,被suspend关键字修饰,下面会介绍。

在上面的协程的原理图解中,耗时阻塞的操作并没有减少,只是交给了其他线程。userApi.getUserSuspend("suming")真正执行的时候会切换到IO线程中执行,获取结果后最后恢复到主线程上,然后继续执行剩下的流程。
将业务流程原理拆分得更细致一点,在主线程中创建协程A中执行整个业务流程,如果遇到异步调用任务则协程A被挂起,切换到IO线程中创建子协程B,获取结果后再恢复到主线程的协程A上,然后继续执行剩下的流程。
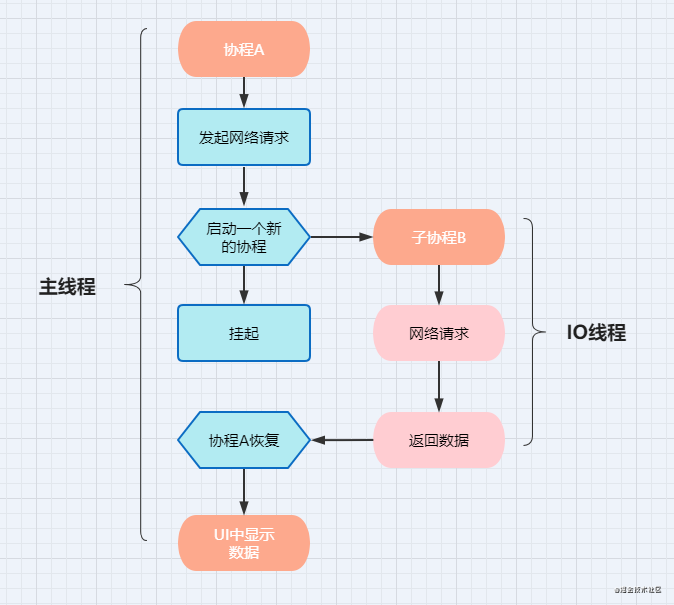
协程Coroutine虽然不能脱离线程而运行,但可以在不同的线程之间切换,而且一个线程上可以一个或多个协程。下图动态显示了进程 - 线程 - 协程微妙关系。
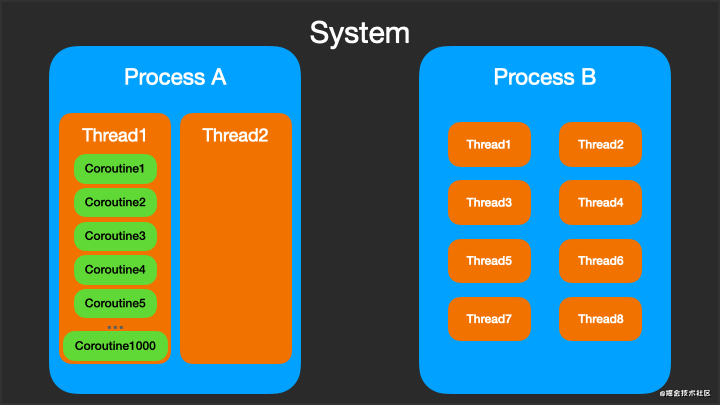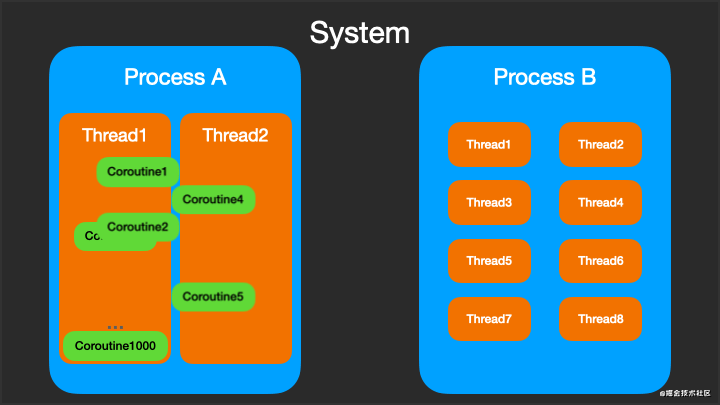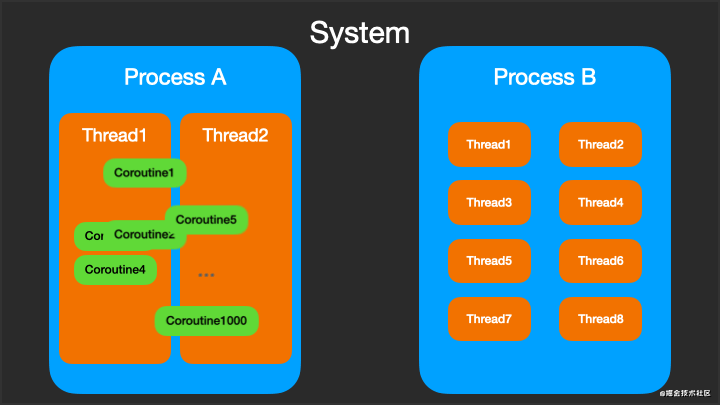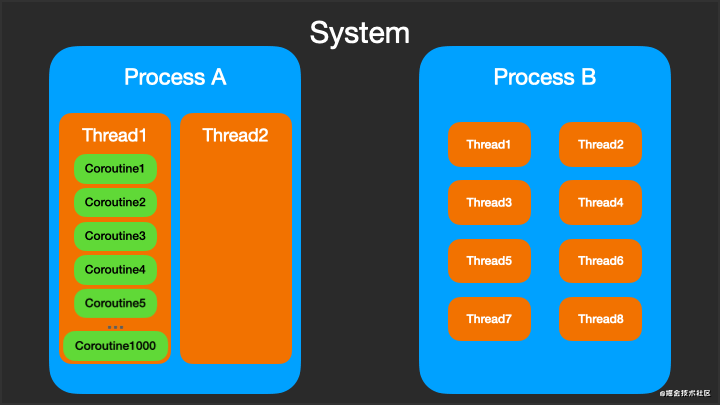
三、基础
GlobalScope.launch(Dispatchers.Main) {
//开始协程:主线程
val result = userApi.getUserSuspend("suming")//网络请求(IO 线程)
tv_name.text = result?.name //更新 UI(主线程)
}
上面就是启动协程的代码,启动协程的代码可以分为三部分:GlobalScope、launch、Dispatchers,它们分别对应:协程的作用域、构建器和调度器。
1.协程的构建
上面的GlobalScope.launch()属于协程构建器Coroutine builders,Kotlin 中还有其他几种 Builders,负责创建协程:
runBlocking:T:顶层函数,创建一个新的协程同时阻塞当前线程,直到其内部所有逻辑以及子协程所有逻辑全部执行完成,返回值是泛型T,一般在项目中不会使用,主要是为main函数和测试设计的。launch: 创建一个新的协程,不会阻塞当前线程,必须在协程作用域中才可以调用。它返回的是一个该协程任务的引用,即Job对象。这是最常用的用于启动协程的方式。async: 创建一个新的协程,不会阻塞当前线程,必须在协程作用域中才可以调用。并返回Deffer对象,可通过调用Deffer.await()方法等待该子协程执行完成并获取结果。常用于并发执行-同步等待和获取返回值的情况。
runBlocking
fun <T> runBlocking(context: CoroutineContext = EmptyCoroutineContext, block: suspend CoroutineScope.() -> T): T
- context: 协程的上下文,表示协程的运行环境,包括协程调度器、代表协程本身的Job、协程名称、协程ID等,默认值是当前线程上的事件循环。(这里的
context和Android的context不同,后面会讲解到) - block: 协程执行体,是一个用suspend关键字修饰的一个无参,无返回值的函数类型。是一个带接收者的函数字面量,接收者是CoroutineScope,因此执行体包含了一个隐式的
CoroutineScope,所以在runBlocking内部可以来直接启动协程。 - T: 返回值是泛型
T,协程体block中最后一行返回的是什么类型T就是什么类型。
它是一个顶层函数,不是GlobalScope的 API,可以在任意地方独立使用。它能创建一个新的协程同时阻塞当前线程,直到其内部所有逻辑以及子协程所有逻辑全部执行完成,它的目的是将常规的阻塞代码与以挂起suspend风格编写的库连接起来,常用于main函数和测试中。一般我们在项目中是不会使用的。
fun runBloTest() {
print("start")
//context上下文使用默认值,阻塞当前线程,直到代码块中的逻辑完成
runBlocking {
//这里是协程体
delay(1000)//挂起函数,延迟1000毫秒
print("runBlocking")
}
print("end")
}
打印数据如下:

只有在runBlocking协程体逻辑全部运行结束后,声明在runBlocking之后的代码才能执行,即runBlocking会阻塞其所在线程。
注意:runBlocking 虽然会阻塞当前线程的,但其内部运行的协程又是非阻塞的。
launch
launch是最常用的用于启动协程的方式,用于在不阻塞当前线程的情况下启动一个协程,并返回对该协程任务的引用,即Job对象。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job
- context: 协程的上下文,表示协程的运行环境,包括协程调度器、代表协程本身的Job、协程名称、协程ID等,默认值是当前线程上的事件循环。
- start: 协程启动模式,这些启动模式的设计主要是为了应对某些特殊的场景。业务开发实践中通常使用DEFAULT和LAZY这两个启动模式就够了。
- block: 协程代码,它将在提供的范围的上下文中被调用。它是一个用
suspend(挂起函数)关键字修饰的一个无参,无返回值的函数类型。接收者是CoroutineScope的函数字面量。 - Job: 协程构建函数的返回值,可以把
Job看成协程对象本身,封装了协程中需要执行的代码逻辑,是协程的唯一标识,Job可以取消,并且负责管理协程的生命周期。
协程需要运行在协程上下文环境中(即协程作用域,下面会讲解到),在非协程环境中launch有两种方式创建协程:
GlobalScope.launch()
在应用范围内启动一个新协程,不会阻塞调用线程,协程的生命周期与应用程序一致。表示一个不绑定任何Job的全局作用域,用于启动顶层协程,这些协程在整个应用程序生命周期中运行,不会提前取消(不存在Job)。
fun launchTest() {
print("start")
//创建一个全局作用域协程,不会阻塞当前线程,生命周期与应用程序一致
GlobalScope.launch {
//在这1000毫秒内该协程所处的线程不会阻塞
//协程将线程的执行权交出去,该线程继续干它要干的事情,到时间后会恢复至此继续向下执行
delay(1000)//1秒无阻塞延迟(默认单位为毫秒)
print("GlobalScope.launch")
}
print("end")//主线程继续,而协程被延迟
}
GlobalScope.launch()协程将线程的执行权交出去,该线程继续干它要干的事情,主线程继续,而协程被延迟,到时间后会恢复至此继续向下执行。
打印数据如下:

由于这样启动的协程存在组件已被销毁但协程还存在的情况,极限情况下可能导致资源耗尽,尤其是在 Android 客户端这种需要频繁创建销毁组件的场景,因此不推荐这种用法。
注意:这里说的是GlobalScope没有Job, 但是启动的launch是有Job的。 GlobalScope本身就是一个作用域, launch属于其子作用域。
CoroutineScope.launch()
启动一个新的协程而不阻塞当前线程,并返回对协程的引用作为一个Job。通过CoroutineContext至少一个协程上下文参数创建一个 CoroutineScope对象。协程上下文控制协程生命周期和线程调度,使得协程和该组件生命周期绑定,组件销毁时,协程一并销毁,从而实现安全可靠地协程调用。这是在应用中最推荐使用的协程使用方式。
fun launchTest2() {
print("start")
//开启一个IO模式的协程,通过协程上下文创建一个CoroutineScope对象,需要一个类型为CoroutineContext的参数
val job = CoroutineScope(Dispatchers.IO).launch {
delay(1000)//1秒无阻塞延迟(默认单位为毫秒)
print("CoroutineScope.launch")
}
print("end")//主线程继续,而协程被延迟
}
打印数据如下:

launch 创建子协程
通过launch在一个协程中启动子协程,可以根据业务需求创建一个或多个子协程:
fun launchTest3() {
print("start")
GlobalScope.launch {
delay(1000)
print("CoroutineScope.launch")
//在协程内创建子协程
launch {
delay(1500)//1.5秒无阻塞延迟(默认单位为毫秒)
print("launch 子协程")
}
}
print("end")
}
打印数据如下:

async
async类似于launch,都是创建一个不会阻塞当前线程的新的协程。它们区别在于:async的返回是Deferred对象,可通过Deffer.await()等待协程执行完成并获取结果,而 launch 不行。常用于并发执行-同步等待和获取返回值的情况。
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T>
- context: 协程的上下文,同
launch。 - start: 协程启动模式,同
launch。 - block: 协程代码,同
launch。 - Deferred: 协程构建函数的返回值,继承自
Job,一个有结果的Job,可通过Deffer.await()等待协程执行完成并获取结果。
await 获取返回值
//获取返回值
fun asyncTest1() {
print("start")
GlobalScope.launch {
val deferred: Deferred<String> = async {
//协程将线程的执行权交出去,该线程继续干它要干的事情,到时间后会恢复至此继续向下执行
delay(2000)//2秒无阻塞延迟(默认单位为毫秒)
print("asyncOne")
"HelloWord"//这里返回值为HelloWord
}
//等待async执行完成获取返回值,此处并不会阻塞线程,而是挂起,将线程的执行权交出去
//等到async的协程体执行完毕后,会恢复协程继续往下执行
val result = deferred.await()
print("result == $result")
}
print("end")
}
上面例子中返回对象Deferred, 通过函数await()获取结果值。打印数据如下:

注意:await() 不能在协程之外调用,因为它需要挂起直到计算完成,而且只有协程可以以非阻塞的方式挂起。所以把它放到协程中。
async 并发
当在协程作用域中使用async函数时可以创建并发任务:
fun asyncTest2() {
print("start")
GlobalScope.launch {
val time = measureTimeMillis {
//计算执行时间
val deferredOne: Deferred<Int> = async {
delay(2000)
print("asyncOne")
100//这里返回值为100
}
val deferredTwo: Deferred<Int> = async {
delay(3000)
print("asyncTwo")
200//这里返回值为200
}
val deferredThr: Deferred<Int> = async {
delay(4000)
print("asyncThr")
300//这里返回值为300
}
//等待所有需要结果的协程完成获取执行结果
val result = deferredOne.await() + deferredTwo.await() + deferredThr.await()
print("result == $result")
}
print("耗时 $time ms")
}
print("end")
}
打印数据如下:
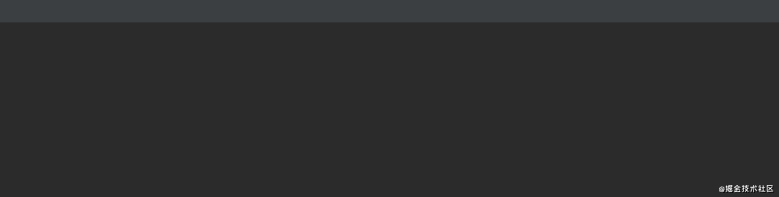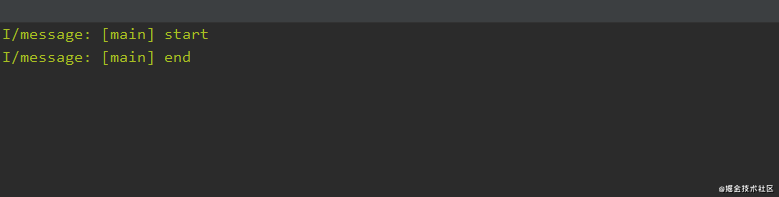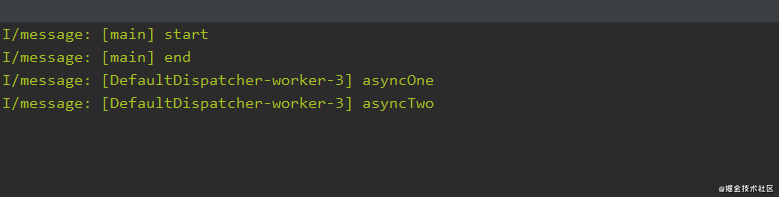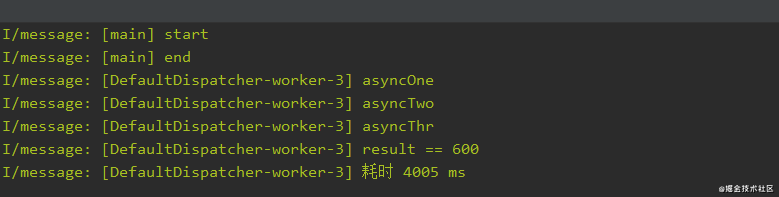
上面的代码就是一个简单的并发示例,async是不阻塞线程的,也就是说上面三个async{}异步任务是同时进行的。通过await()方法可以拿到async协程的执行结果,可以看到两个协程的总耗时是远少于9秒的,总耗时基本等于耗时最长的协程。
1.
Deferred集合还可以使用awaitAll()等待全部完成;2.如果
Deferred不执行await()则async内部抛出的异常不会被logCat或tryCatch捕获, 但是依然会导致作用域取消和异常崩溃; 但当执行await时异常信息会重新抛出。3.惰性并发,如果将
async函数中的启动模式设置为CoroutineStart.LAZY懒加载模式时则只有调用Deferred对象的await时(或者执行async.satrt())才会开始执行异步任务。
launch构建器适合执行 “一劳永逸” 的工作,意思就是说它可以启动新协程而不需要结果返回;async构建器可启动新协程并允许您使用一个名为await的挂起函数返回result,并且支持并发。另外launch和async之间的很大差异是它们对异常的处理方式不同。如果使用async作为最外层协程的开启方式,它期望最终是通过调用 await 来获取结果 (或者异常),所以默认情况下它不会抛出异常。这意味着如果使用 async启动新的最外层协程,而不使用await,它会静默地将异常丢弃。
2.Job & Deferred
反观线程,java平台上很明确地给出了线程的类型Thread,我们也需要一个这样的类来描述协程,它就是Job。它的API设计与Java的Thread殊途同归。
Job
Job 是协程的句柄。如果把门和门把手比作协程和Job之间的关系,那么协程就是这扇门,Job就是门把手。意思就是可以通过Job实现对协程的控制和管理。
从上面可以知道Job是launch构建协程返回的一个协程任务,完成时是没有返回值的。可以把Job看成协程对象本身,封装了协程中需要执行的代码逻辑,协程的操作方法都在Job身上。Job具有生命周期并且可以取消,它也是上下文元素,继承自CoroutineContext。
这里列举Job几个比较有用的函数:
public interface Job : CoroutineContext.Element {
//活跃的,是否仍在执行
public val isActive: Boolean
//启动协程,如果启动了协程,则为true;如果协程已经启动或完成,则为false
public fun start(): Boolean
//取消Job,可通过传入Exception说明具体原因
public fun cancel(cause: CancellationException? = null)
//挂起协程直到此Job完成
public suspend fun join()
//取消任务并等待任务完成,结合了[cancel]和[join]的调用
public suspend fun Job.cancelAndJoin()
//给Job设置一个完成通知,当Job执行完成的时候会同步执行这个函数
public fun invokeOnCompletion(handler: CompletionHandler): DisposableHandle
}
与Thread相比,Job同样有join(),调用时会挂起(线程的join()则会阻塞线程),直到协程完成;它的cancel()可以类比Thread的interrupt(),用于取消协程;isActive则是可以类比Thread的isAlive(),用于查询协程是否仍在执行。
Job是一个接口类型,它具有以下三种状态:
| 状态 | 说明 |
|---|---|
isActive |
活跃的。当Job处于活动状态时为true,如果Job已经开始,但还没有完成、也没有取消或者失败,则是处于active状态。 |
isCompleted |
已完成。当Job由于任何原因完成时为true,已取消、已失败和已完成Job都是被视为完成状态。 |
isCancelled |
已退出。当Job由于任何原因被取消时为true,无论是通过显式调用cancel或这因为它已经失败亦或者它的子或父被取消,都是被视为已退出状态。 |
这里模拟一个无限循环的协程,当协程是活跃状态时每秒钟打印两次消息,1.2秒后取消协程:
fun jobTest() = runBlocking {
val startTime = System.currentTimeMillis()
val job = launch(Dispatchers.Default){
var nextPrintTime = startTime
var i = 0
while (isActive) {
//当job是活跃状态继续执行
if (System.currentTimeMillis() >= nextPrintTime) {
//每秒钟打印两次消息
print("job: I'm sleeping ${
i++} ...")
nextPrintTime += 500
}
}
}
delay(1200)//延迟1.2s
print("等待1.2秒后")
//job.join()
//job.cancel()
job.cancelAndJoin()//取消任务并等待任务完成
print("协程被取消并等待完成")
}
join()是一个挂起函数,它需要等待协程的执行,如果协程尚未完成,join()立即挂起,直到协程完成;如果协程已经完成,join()不会挂起,而是立即返回。打印数据如下:

Job 还可以有层级关系,一个Job可以包含多个子Job,当父Job被取消后,所有的子Job也会被自动取消;当子Job被取消或者出现异常后父Job也会被取消。具有多个子 Job 的父Job 会等待所有子Job完成(或者取消)后,自己才会执行完成。
总的来说:它的作用是Job实例作为协程的唯一标识,用于处理协程,并且负责管理协程的生命周期。
Deferred
Deferred继承自Job,具有与Job相同的状态机制。它是async构建协程返回的一个协程任务,可通过调用await()方法等待协程执行完成并获取结果。不同的是Job没有结果值,Deffer有结果值。
public interface Deferred<out T> : Job {
//等待协程执行完成并获取结果
public suspend fun await(): T
}
await(): 等待协程执行完毕并返回结果,如果异常结束则会抛出异常;如果协程尚未完成,则挂起直到协程执行完成。T: 这里多了一个泛型参数T,它表示返回值类型,通过await()函数可以拿到这个返回值。
上面已有Deferred代码演示,这里就不再重复实践。
3.作用域
通常我们提到的域,都是用来描述范围的,域既有约束作用又有提供额外能力的作用。
协程作用域(CoroutineScope)其实就是为协程定义的作用范围,为了确保所有的协程都会被追踪,Kotlin 不允许在没有使用CoroutineScope的情况下启动新的协程。CoroutineScope可被看作是一个具有超能力的ExecutorService的轻量级版本。它能启动新的协程,同时这个协程还具备上面所说的suspend和resume的优势。
每个协程生成器launch、async等都是CoroutineScope的扩展,并继承了它的coroutineContext自动传播其所有元素和取消。协程作用域本质是一个接口:
public interface CoroutineScope {
//此域的上下文。Context被作用域封装,用于在作用域上扩展的协程构建器的实现。
public val coroutineContext: CoroutineContext
}
因为启动协程需要作用域,但是作用域又是在协程创建过程中产生的,这似乎是一个“先有鸡后有蛋还是先有蛋后有鸡”的问题。
常用作用域
官方库给我们提供了一些作用域可以直接来使用:
runBlocking:顶层函数,它的第二个参数为接收者是CoroutineScope的函数字面量,可启动协程。但是它会阻塞当前线程,主要用于测试。GlobalScope:全局协程作用域,通过GlobalScope创建的协程不会有父协程,可以把它称为根协程。它启动的协程的生命周期只受整个应用程序的生命周期的限制,且不能取消,在运行时会消耗一些内存资源,这可能会导致内存泄露,所以仍不适用于业务开发。coroutineScope:创建一个独立的协程作用域,直到所有启动的协程都完成后才结束自身。它是一个挂起函数,需要运行在协程内或挂起函数内。当这个作用域中的任何一个子协程失败时,这个作用域失败,所有其他的子程序都被取消。为并行分解工作而设计的。supervisorScope:与coroutineScope类似,不同的是子协程的异常不会影响父协程,也不会影响其他子协程。(作用域本身的失败(在block或取消中抛出异常)会导致作用域及其所有子协程失败,但不会取消父协程。)MainScope:为UI组件创建主作用域。一个顶层函数,上下文是SupervisorJob() + Dispatchers.Main,说明它是一个在主线程执行的协程作用域,通过cancel对协程进行取消。推荐使用。
fun scopeTest() {
//创建一个根协程
GlobalScope.launch {
//父协程
launch {
//子协程
print("GlobalScope的子协程")
}
launch {
//第二个子协程
print("GlobalScope的第二个子协程")
}
}
//为UI组件创建主作用域
val mainScope = MainScope()
mainScope.launch {
//启动协程
//todo
}
}
注意:MainScope作用域的好处就是方便地绑定到UI组件的声明周期上,在Activity销毁的时候mainScope.cancel()取消其作用域。
Lifecycle的协程支持
Android 官方对协程的支持是非常友好的,KTX 为 Jetpack 的Lifecycle相关组件提供了已经绑定UV声明周期的作用域供我们直接使用:
lifecycleScope:Lifecycle Ktx库提供的具有生命周期感知的协程作用域,与Lifecycle绑定生命周期,生命周期被销毁时,此作用域将被取消。会与当前的UI组件绑定生命周期,界面销毁时该协程作用域将被取消,不会造成协程泄漏,推荐使用。viewModelScope:与lifecycleScope类似,与ViewModel绑定生命周期,当ViewModel被清除时,这个作用域将被取消。推荐使用。
在build.gradle添加Lifecycle相应基础组件后,再添加以下组件即可:
// ViewModel
implementation "androidx.lifecycle:lifecycle-viewmodel-ktx:2.2.0"
// LiveData
implementation "androidx.lifecycle:lifecycle-livedata-ktx:2.2.0"
// 只有Lifecycles(没有 ViewModel 和 LiveData)
implementation "androidx.lifecycle:lifecycle-runtime-ktx:2.2.0"
因为Activity 实现了LifecycleOwner这个接口,而lifecycleScope则正是它的拓展成员,可以在Activity中直接使用lifecycleScope协程实例:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
btn_data.setOnClickListener {
lifecycleScope.launch {
//使用lifecycleScope创建协程
//协程执行体
}
}
}
}
在ViewModel中使用创建协程:
class MainViewModel : ViewModel() {
fun getData() {
viewModelScope.launch {
//使用viewModelScope创建协程
//执行协程
}
}
}
注意:VIewModel 的作用域会在它的 clear 函数调用时取消。
分类和行为规则
官方框架在实现复合协程的过程中也提供了作用域,主要用于明确父子关系,以及取消或者异常处理等方面的传播行为。该作用域分为以下三种:
- 顶级作用域:没有父协程的协程所在的作用域为顶级作用域。
- 协同作用域:协程中启动新的协程,新协程为所在协程的子协程,这种情况下,子协程所在的作用域默认为协同作用域。此时子协程抛出的未捕获异常,都将传递给父协程处理,父协程同时也会被取消。
- 主从作用域:与协同作用域在协程的父子关系上一致,区别在于,处于该作用域下的协程出现未捕获的异常时,不会将异常向上传递给父协程。
除了三种作用域中提到的行为以外,父子协程之间还存在以下规则:
- 父协程被取消,则所有子协程均被取消。由于协同作用域和主从作用域中都存在父子协程关系,因此此条规则都适用。
- 父协程需要等待子协程执行完毕之后才会最终进入完成状态,不管父协程自身的协程体是否已经执行完。
- 子协程会继承父协程的协程上下文中的元素,如果自身有相同
key的成员,则覆盖对应的key,覆盖的效果仅限自身范围内有效。
4.调度器
在上面介绍协程概念的时候,协程的挂起与恢复在哪挂起,什么时候恢复,为什么能切换线程,这因为调度器的作用:它确定相应的协程使用那些线程来执行。
CoroutineDispatcher调度器指定指定执行协程的目标载体,它确定了相关的协程在哪个线程或哪些线程上执行。可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。
协程需要调度的位置就是挂起点的位置,只有当挂起点正在挂起的时候才会进行调度,实现调度需要使用协程的拦截器。调度的本质就是解决挂起点恢复之后的协程逻辑在哪里运行的问题。调度器也属于协程上下文一类,它继承自拦截器:
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
//将可运行块的执行分派到给定上下文中的另一个线程上。这个方法应该保证给定的[block]最终会被调用。
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
//返回一个continuation,它封装了提供的[continuation],拦截了所有的恢复。
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T>
//CoroutineDispatcher是一个协程上下文元素,而'+'是一个用于协程上下文的集合和操作符。
public operator fun plus(other: CoroutineDispatcher): CoroutineDispatcher = other
}
它是所有协程调度程序实现扩展的基类(我们很少会自己自定义调度器)。可以使用newSingleThreadContext和newFixedThreadPoolContext创建私有线程池。也可以使用asCoroutineDispatcher扩展函数将任意java.util.concurrent.Executor转换为调度程序。
调度器模式
Kotlin 提供了四个调度器,您可以使用它们来指定应在何处运行协程:
| 调度器模式 | 说明 | 适用场景 |
|---|---|---|
Dispatchers.Default |
默认调度器,非主线程。CPU密集型任务调度器,适合处理后台计算。 |
通常处理一些单纯的计算任务,或者执行时间较短任务比如:Json的解析,数据计算等。 |
Dispatchers.Main |
UI调度器, Andorid 上的主线程。 |
调度程序是单线程的,通常用于UI交互,刷新等。 |
Dispatchers.Unconfined |
一个不局限于任何特定线程的协程调度程序,即非受限调度器。 | 子协程切换线程代码会运行在原来的线程上,协程在相应的挂起函数使用的任何线程中继续。 |
Dispatchers.IO |
IO调度器,非主线程,执行的线程是IO线程。 |
适合执行IO相关操作,比如:网络处理,数据库操作,文件读写等。 |
所有的协程构造器(如launch和async)都接受一个可选参数,即 CoroutineContext ,该参数可用于显式指定要创建的协程和其它上下文元素所要使用的CoroutineDispatcher。
fun dispatchersTest() {
//创建一个在主线程执行的协程作用域
val mainScope = MainScope()
mainScope.launch {
launch(Dispatchers.Main) {
//在协程上下参数中指定调度器
print("主线程调度器")
}
launch(Dispatchers.Default) {
print("默认调度器")
}
launch(Dispatchers.Unconfined) {
print("任意调度器")
}
launch(Dispatchers.IO) {
print("IO调度器")
}
}
}
打印数据如下:

withContext
在 Andorid 开发中,我们常常在子线程中请求网络获取数据,然后切换到主线程更新UI。官方为我们提供了一个withContext顶级函数,在获取数据函数内,调用withContext(Dispatchers.IO)来创建一个在IO线程池中运行的块。您放在该块内的任何代码都始终通过IO调度器执行。由于withContext本身就是一个suspend函数,它会使用协程来保证主线程安全。
//用给定的协程上下文调用指定的挂起块,挂起直到它完成,并返回结果。
public suspend fun <T> withContext(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T
): T
- context: 协程的上下文,同上(调度器也属于上下文一类)。
- block: 协程执行体,同上。
block中的代码会被调度到上面指定的调度器上执行,并返回结果值。
这个函数会使用新指定的上下文的dispatcher,将block的执行转移到指定的线程中。它会返回结果, 可以和当前协程的父协程存在交互关系, 主要作用为了来回切换调度器。
GlobalScope.launch(Dispatchers.Main) {
//开始协程:主线程
val result: User = withContext(Dispatchers.IO) {
//网络请求(IO 线程)
userApi.getUserSuspend("FollowExcellence")
}
tv_title.text = result.name //更新 UI(主线程)
}
在主线程中启动一个协程,然后再通过withContext(Dispatchers.IO)调度到IO线程上去做网络请求,获取结果返回后,主线程上的协程就会恢复继续执行,完成UI的更新。
由于withContext可让在不引入回调的情况下控制任何代码行的线程池,因此可以将其应用于非常小的函数,如从数据库中读取数据或执行网络请求。一种不错的做法是使用withContext来确保每个函数都是主线程安全的,那么可以从主线程调用每个函数。调用方也就无需再考虑应该使用哪个线程来执行函数了。您可以使用外部 withContext来让 Kotlin 只切换一次线程,这样可以在多次调用的情况下,以尽可能避免了线程切换所带来的性能损失。
5.协程上下文
CoroutineContext表示协程上下文,是 Kotlin 协程的一个基本结构单元。协程上下文主要承载着资源获取,配置管理等工作,是执行环境的通用数据资源的统一管理者。它有很多作用,包括携带参数,拦截协程执行等等。如何运用协程上下文是至关重要的,以此来实现正确的线程行为、生命周期、异常以及调试。
协程使用以下几种元素集定义协程的行为,它们均继承自CoroutineContext:
Job: 协程的句柄,对协程的控制和管理生命周期。CoroutineName: 协程的名称,可用于调试。CoroutineDispatcher: 调度器,确定协程在指定的线程来执行。CoroutineExceptionHandler:协程异常处理器,处理未捕获的异常。这里暂不做深入分析,后面的文章会讲解到,敬请期待。
协程上下文的数据结构特征更加显著,与List和Map非常类似。它包含用户定义的一些数据集合,这些数据与协程密切相关。它是一个有索引的 Element 实例集合。每个 element 在这个集合有一个唯一的Key。
//协程的持久上下文。它是[Element]实例的索引集,这个集合中的每个元素都有一个唯一的[Key]。
public interface CoroutineContext {
//从这个上下文中返回带有给定[key]的元素或null。
public operator fun <E : Element> get(key: Key<E>): E?
//从[initial]值开始累加该上下文的项,并从左到右应用[operation]到当前累加器值和该上下文的每个元素。
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
//返回一个上下文,包含来自这个上下文的元素和来自其他[context]的元素。
public operator fun plus(context: CoroutineContext): CoroutineContext
//返回一个包含来自该上下文的元素的上下文,但不包含指定的[key]元素。
public fun minusKey(key: Key<*>): CoroutineContext
//[CoroutineContext]元素的键。[E]是带有这个键的元素类型。
public interface Key<E : Element>
//[CoroutineContext]的一个元素。协程上下文的一个元素本身就是一个单例上下文。
public interface Element : CoroutineContext {
//这个协程上下文元素的key
public val key: Key<*>
public override operator fun <E : Element> get(key: Key<E>): E?
}
}
<E> get(key): 可以通过key从这个上下文中获取这个Element元素或者null。fold(): 提供遍历当前上下文中所有元素的能力。plus(context): 顾名思义它是一个加法运算,多个上下文元素可以通过+的形式整合成一个上下文返回。minusKey(key): 与plus相反,减法运算,删除当前上下文中指定key的元素,返回的是不包含指定Element: 协程上下文的一个元素,本身就是一个单例上下文,里面有一个key,是这个元素的索引。
Element本身也实现了CoroutineContext 接口,像Int实现了List<Int>一样,为什么元素本身也是集合呢?主要是Element它不会存放除它自己以外的数据;Element属性又有一个key,是协程上下文这个集合中元素的索引。这个索引在元素里面,说明元素一产生就找到自己的位置。
注意:协程上下文的内部实现实际是一个单链表。
CoroutineName
//用户指定的协程名称。此名称用于调试模式。
public data class CoroutineName(
//定义协程的名字
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
//CoroutineName实例在协程上下文中的key
public companion object Key : CoroutineContext.Key<CoroutineName>
}
CoroutineName是用户用来指定的协程名称的,用于方便调试和定位问题:
GlobalScope.launch(CoroutineName("GlobalScope")) {
launch(CoroutineName("CoroutineA")) {
//指定协程名称
val coroutineName = coroutineContext[CoroutineName]//获取协程名称
print(coroutineName)
}
}
协程内部可以通过coroutineContext这个全局属性直接获取当前协程的上下文。打印数据如下:
[DefaultDispatcher-worker-2] CoroutineName(CoroutineA)
上下文组合
从上面的协程创建的函数中可以看到,协程上下文的参数只有一个,但是怎么传递多个上下文元素呢?CoroutineContext可以使用 " + " 运算符进行合并。由于CoroutineContext是由一组元素组成的,所以加号右侧的元素会覆盖加号左侧的元素,进而组成新创建的CoroutineContext。
GlobalScope.launch {
//通过+号运算添加多个上下文元素
var context = CoroutineName("协程1") + Dispatchers.Main
print("context == $context")
context += Dispatchers.IO //添加重复Dispatchers元素,Dispatchers.IO 会替换 ispatchers.Main
print("context == $context")
val contextResult = context.minusKey(context[CoroutineName]!!.key)//移除CoroutineName元素
print("contextResult == $contextResult")
}
注意:如果有重复的元素(key一致)则会右边的会代替左边的元素。打印数据如下:
context == [CoroutineName(协程1), Dispatchers.Main]
context == [CoroutineName(协程1), Dispatchers.IO]
contextResult == Dispatchers.IO
6.启动模式
CoroutineStart是一个枚举类,为协程构建器定义启动选项。在协程构建的start参数中使用,
| 启动模式 | 含义 | 说明 |
|---|---|---|
DEFAULT |
默认启动模式,立即根据它的上下文调度协程的执行 | 是立即调度,不是立即执行,DEFAULT 是饿汉式启动,launch 调用后,会立即进入待调度状态,一旦调度器 OK 就可以开始执行。如果协程在执行前被取消,其将直接进入取消响应的状态。 |
LAZY |
懒启动模式,启动后并不会有任何调度行为,直到我们需要它执行的时候才会产生调度 | 包括主动调用该协程的start、join或者await等函数时才会开始调度,如果调度前就被取消,协程将直接进入异常结束状态。 |
ATOMIC |
类似[DEFAULT],以一种不可取消的方式调度协程的执行 | 虽然是立即调度,但其将调度和执行两个步骤合二为一了,就像它的名字一样,其保证调度和执行是原子操作,因此协程也一定会执行。 |
UNDISPATCHED |
类似[ATOMIC],立即执行协程,直到它在当前线程中的第一个挂起点。 | 是立即执行,因此协程一定会执行。即使协程已经被取消,它也会开始执行,但不同之处在于它在同一个线程中开始执行。 |
这些启动模式的设计主要是为了应对某些特殊的场景。业务开发实践中通常使用DEFAULT和LAZY这两个启动模式就够了。
7.suspend 挂起函数
suspend 是 Kotlin 协程最核心的关键字,使用suspend关键字修饰的函数叫作挂起函数,挂起函数只能在协程体内或者在其他挂起函数内调用。否则 IDE 就会提示一个错误:
Suspend function ‘xxxx’ should be called only from a coroutine or another suspend function
协程提供了一种避免阻塞线程并用更简单、更可控的操作替代线程阻塞的方法:协程挂起和恢复。协程在执行到有suspend标记的函数时,当前函数会被挂起(暂停),直到该挂起函数内部逻辑完成,才会在挂起的地方resume恢复继续执行。
本质上,挂起函数就是一个提醒作用,函数创建者给函数调用者的提醒,表示这是一个比较耗时的任务,被创建者用suspend标记函数,调用者只需把挂起函数放在协程里面,协程会自动调度处理,完成后在原来的位置恢复执行。
注意:协程会在主线程中运行,suspend 并不代表后台执行。
如果需要处理一个函数,且这个函数在主线程上执行太耗时,但是又要保证这个函数是主线程安全的,那么您可以让 Kotlin 协程在 Default 或 IO 调度器上执行工作。在 Kotlin 中,所有协程都必须在调度器中运行,即使它们是在主线程上运行也是如此。协程可以自行挂起(暂停),而调度器负责将其恢复。
挂起点
协程内部挂起函数调用的地方称为挂起点,或者有下面这个标识的表示这个就是挂起点。

挂起和恢复
协程在常规函数的基础上添加了suspend和 resume两项操作用于处理长时间运行的任务:
suspend:也称挂起或暂停,用于挂起(暂停)执行当前协程,并保存所有局部变量。resume:恢复,用于让已挂起(暂停)的协程从挂起(暂停)处恢复继续执行。
Kotlin 使用堆栈帧来管理要运行哪个函数以及所有局部变量。挂起(暂停)协程时,会复制并保存当前的堆栈帧以供稍后使用,将信息保存到Continuation对象中。恢复协程时,会将堆栈帧从其保存位置复制回来,对应的Continuation通过调用resumeWith函数才会恢复协程的执行,然后函数再次开始运行。同时返回Result<T>类型的成功或者异常的结果。
//Continuation接口表示挂起点之后的延续,该挂起点返回类型为“T”的值。
public interface Continuation<in T> {
//对应这个Continuation的协程上下文
public val context: CoroutineContext
//恢复相应协程的执行,传递一个成功或失败的结果作为最后一个挂起点的返回值。
public fun resumeWith(result: Result<T>)
}
//将[value]作为最后一个挂起点的返回值,恢复相应协程的执行。
fun <T> Continuation<T>.resume(value: T): Unit =
resumeWith(Result.success(value))
//恢复相应协程的执行,以便在最后一个挂起点之后重新抛出[异常]。
fun <T> Continuation<T>.resumeWithException(exception: Throwable): Unit =
resumeWith(Result.failure(exception))
Kotlin 的 Continuation 类有一个 resumeWith 函数可以接收 Result 类型的参数。在结果成功获取时,调用resumeWith(Result.success(value))或者调用拓展函数resume(value);出现异常时,调用resumeWith(Result.failure(exception))或者调用拓展函数resumeWithException(exception),这就是 Continuation 的恢复调用。
Continuation类似于网络请求回调Callback,也是一个请求成功和一个请求失败的回调:
public interface Callback {
//请求失败回调
void onFailure(Call call, IOException e);
//请求成功回调
void onResponse(Call call, Response response) throws IOException;
}
注意:suspend不一定真的会挂起,如果只是提供了挂起的条件,但是协程没有产生异步调用,那么协程还是不会被挂起。
那么协程是如何做到挂起和恢复?
suspend本质(夺命七步)
一个挂起函数要挂起,那么它必定得有一个挂起点,不然无法知道函数是否挂起,从哪挂起呢?
@GET("users/{login}")
suspend fun getUserSuspend(@Path("login") login: String): User
第一步:将上面的挂起函数解析成字节码:通过AS的工具栏中Tools->kotlin->show kotlin ByteCode
public abstract getUserSuspend(Ljava/lang/String;Lkotlin/coroutines/Continuation;)Ljava/lang/Object;
上面的挂起函数本质是这样的,你会发现多了一个参数,这个参数就是Continuation,也就是说调用挂起函数的时候需要传递一个Continuation给它,只是传递这个参数是由编译器悄悄传,而不是我们传递的。这就是挂起函数为什么只能在协程或者其他挂起函数中执行,因为只有挂起函数或者协程中才有Continuation。
第二步:这里的Continuation参数,其实它类似CallBack回调函数,resumeWith()就是成功或者失败回调的结果:
public interface Continuation<in T> {
//协程上下文
public val context: CoroutineContext
//恢复相应协程的执行,传递一个成功或失败的[result]作为最后一个挂起点的返回值。
public fun resumeWith(result: Result<T>)
}
第三步:但是它是从哪里传进来的呢?这个函数只能在协程或者挂起函数中执行,说明Continuation很有可能是从协程充传入来的,查看协程构建的源码:
public fun CoroutineScope.launch(): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
第四步:通过launch启动一个协程的时候,他通过coroutine的start方法启动协程:
public fun <R> start(start: CoroutineStart, receiver: R, block: suspend R.() -> T) {
initParentJob()
start(block, receiver, this)
}
第五步:然后start方法里面调用了CoroutineStart的invoke,这个时候我们发现了Continuation:
public operator fun <T> invoke(block: suspend () -> T, completion: Continuation<T>): Unit =
when (this) {
DEFAULT -> block.startCoroutineCancellable(completion)
ATOMIC -> block.startCoroutine(completion)
UNDISPATCHED -> block.startCoroutineUndispatched(completion)
LAZY -> Unit // will start lazily
}
第六步:而 Continuation通过block.startCoroutine(completion)传入:
public fun <T> (suspend () -> T).startCoroutine(completion: Continuation<T>) {
createCoroutineUnintercepted(completion).intercepted().resume(Unit)
}
第七步:最终回调到上面Continuation的resumeWith()恢复函数里面。这里可以看出协程体本身就是一个Continuation,这也就解释了为什么必须要在协程内调用suspend挂起函数了。(由于篇幅原因这里不做深入分析,后续的文章会分析这里,敬请期待!)
额外知识点:在创建协程的底层源码中,创建协程会返回一个
Continuation实例,这个实例就是套了几层马甲的协程体,调用它的resume可以触发协程的执行。
任何一个协程体或者挂起函数中都隐含有一个Continuation实例,编译器能够对这个实例进行正确的传递,并将这个细节隐藏在协程的背后,让我们的异步代码看起来像同步代码一样。
@GET("users/{login}")
suspend fun getUserSuspend(@Path("login") login: String): User
GlobalScope.launch(Dispatchers.Main) {
//开始协程:主线程
val result = userApi.getUserSuspend("suming")//网络请求(IO 线程)
tv_name.text = result?.name //更新 UI(主线程)
}
launch()创建的这个协程,在执行到某一个suspend挂起函数的时候,这个协程会被挂起,从当前线程挂起。
也就是说这个协程从正在执行它的线程上脱离,这个协程在挂起函数指定的线程上继续执行,当协程的任务完成时,再resume恢复切换到原来的线程上继续执行。
在主线程进行的 suspend 和 resume 的两个操作,既实现了将耗时任务交由后台线程完成,保障了主线程安全,也在不增加代码复杂度和保证代码可读性的前提下做到不阻塞主线程的执行。可以说,在 Android 平台上协程主要就用来解决异步和切换线程这两个问题。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,很感谢您阅读这篇文章。我是suming,感谢各位的支持和认可,您的点赞就是我创作的最大动力。山水有相逢,我们下篇文章见!
本人水平有限,文章难免会有错误,请批评指正,不胜感激 !
参考链接:
- Kotlin官网
- 《深入理解Kotlin协程》
- 慕课网之《新版Kotlin从入门到精通》
- 万字长文 - Kotlin 协程进阶
- 一文快速入门 Kotlin 协程
- 最全面的Kotlin协程: Coroutine/Channel/Flow 以及实际应用
- 史上最详Android版kotlin协程入门进阶实战(二)