关于本篇文章
第一次书写时间:2017/12/19/9:08
第二次书写时间:2017/12/19/14:07
第三次书写时间:2017/12/19:20
第四次书写时间:2017/12/19/22:55
第五次书写时间:2017/12/20/10:31
第六次书写时间:2017/12/21/8:32
架构设计
整体工程
概略图:
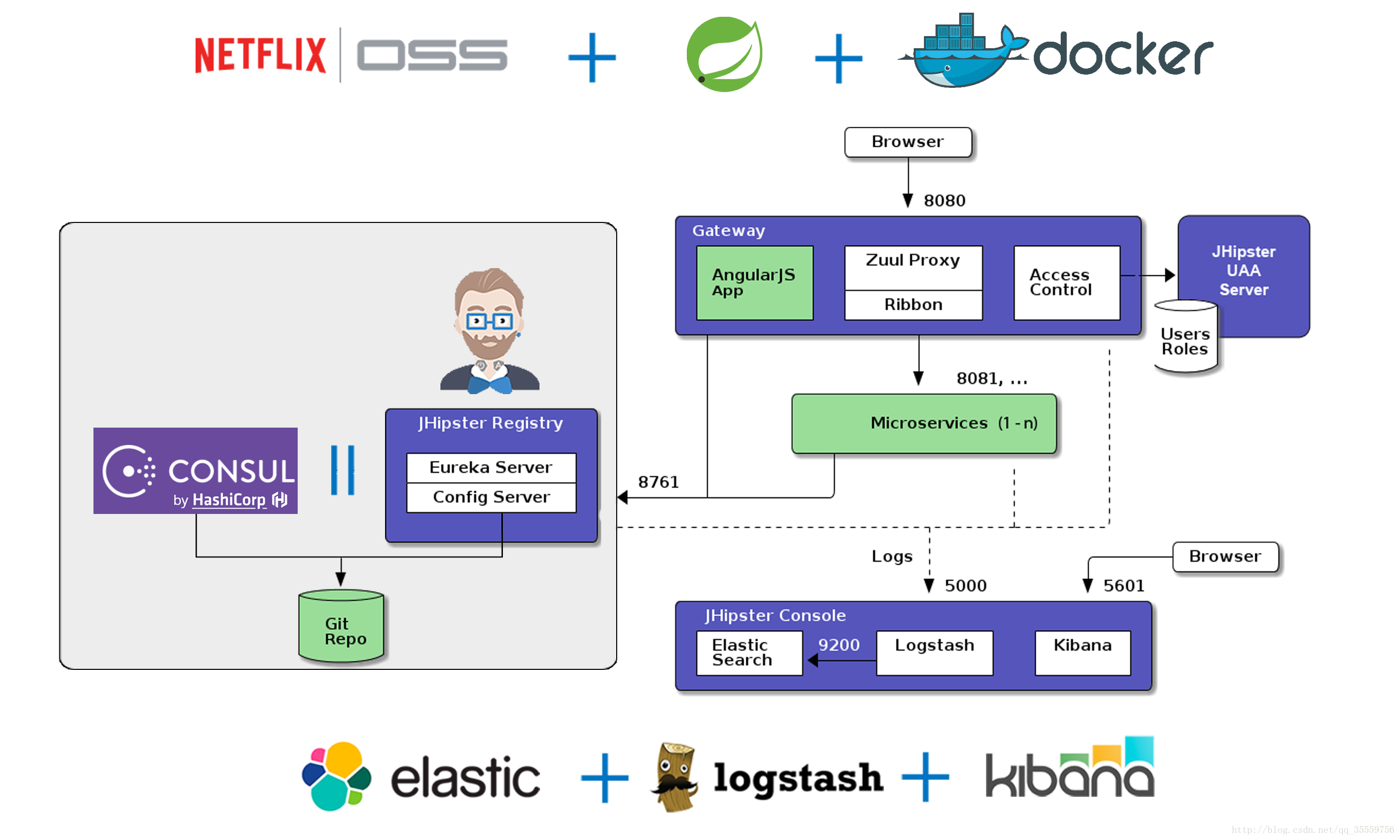
顶部层:
( NETFLIX|OSS =>Spring Cloud )和 Spring Boot 以及 docker
NETFLIX|OSS =>Spring Cloud:
属于aws那种以前的方式,Spring Cloud很大一部分都是基于NETFLIX |OSS,对于java开发者并且不在aws上部署服务来说可以几乎等同于Spring Cloud,以下也是基于Spring Cloud来讲述的
随着项目工程的越来越庞大、开发语言的差异渐大、业务闭环组合敏捷开发带来的指引,我们进入了多系统多部署[分布式]的时期,一个组合业务的系统划分成多个单独业务的系统并且每一个业务都可以通过部署在多台服务器来大大增加或者增强后台的响应速度、并发量、业务回环速度、系统稳定性等等。
同时这些一些问题必须急切的被解决: 服务注册及发现、负载均衡、调用链容错、统一路由、配置及依赖管理、多语言并存而统一调用声明、可视化运行状态监控。
服务注册及发现:运行在多台服务器上的同一个业务各自的所在ip不同,对于调用者或者说是服务消费者来说服务提供者是透明的,”我”需要引用特定而不需要明确指定具体调用的的提供者的最终ip,因为很有可能在某些情况下,那台服务提供者因为一些原因资源占用率过高而无法服务,因为没有哪种实现思路可以明确知道前台业务上使用者的资源消耗是多少,也有可能是某一台服务提供者的所在真实物理机器宕机了,此时如果是依赖的具体Ip就会导致无法获取服务,或许会说,就算这台服务器挂了,我换一台不就行了?确实是可以的,但是你如何得到下一个属于可用状态且不会再并发严重情况下获取可用物理ip地址呢?此时就会先需要一个数据库来记录、修改、删除、查询这些可用的属于你所依赖服务的服务器ip,Eureka Server 就是这么做的,一个较为完整的流程是:当服务提供者开启的时候将将自身ip和所属业务提交给eureka server,eureka server会将当前节点添加到它的内置数据库中,而且很完善的是eureka server会自动定时的去监测注册到它上面的服务提供者,同时也是需要服务器提供者配合,通过内部心跳机制向eureka server证明自己还活着,否则在超过一定时间后,eureka server就会将这台服务器提供者从数据库中移除,移除之后,其他消费者就不能引用到它了,通过这样的机制,服务提供者对于服务消费者来说是高可用的,任何一台服务提供者下线之后对整个服务提供者是无影响的,消费者是无感知的,但是会提高负载。但是也是有一个问题,eureka server此时就成了瓶颈了,eureka server能否工作以及是否流畅影响着整个系统的可用以及性能,对于一个系统来说维持这样一个其实还属于可容范围,但是如果宕机了就不能了所以其实eureka server有备份节点的,当其他节点发现当前工作节点已经无响应了,就会取代原节点继续工作,这里用分布式系统的组件来描述就是zookeeper分布式协调组件 和 redis 哨兵机制
负载均衡:一个系统能否流畅工作一个是取决于系统本身是否能容下业务所需资源,另一个是资源是否能分配合理,过多的资源压力会导致机器过早疲惫甚至宕机,当有机器无法负载而无法提供服务时,整个服务就会的平均负载就会提高导致滚雪球版崩溃,或许有人会说,有几台机器宕机了,我就再加几台机器不就行了吗?但是你要知道根本原因不解决好,再加进来的服务器一样会再次奔溃,然后原来的机器由于较少压力导致一直处于空闲状态,微服务集群中看起来有5份效率正常输入服务其实有可能是3:7 / 2的关系,而且频繁上线下线机器会导致服务管理者的效率下降从而是整个集群过早崩溃,常用的负载有随机分配RandomRule、轮询获取RoundRobinRule(默认)、试探性获取RetryRule、权重分析WeightedResponseTimeRule等等,在不考虑自身消耗且确实有可用的情况下,试探性获取是最有效果的实现,但是其实获取其他机器的负载情况是需要消耗性能的,尤其是在多次获取无果的情况下是非常浪费性能的,但是如果最终无果,那就该考虑实现自动扩容及自动收缩了,也就是说在集群变动情况较大情况下,是不太可取的,随机分配在刚开始时是可用且消耗低的,但是随着集群运行量及负载量达到一定程度时,随机分配是万万不可取的,轮询获取,是消耗低较为中性的,但是考虑到最终客户端的消耗可能大多不一样,可能会导致在分配圈中总是分配某一台或者某一些机器,此时就是不太好的,但是也可以通过非对距圈性关系来持续轮询,那样就不会导致持续磨损某一台机器了,最后的权重分析是属于统计的结果,server端每隔30秒统计一次给出权重,一个是多个业务情况下对server负载增加压力而且当某一个时间激增的情况下,可能激增的时间小于30S秒,此时这个算法就是难以切合实际的
调用链容错:从一开始的切分业务到最终组合业务可能会形成长距离的多分化的线路[链路],当某一个服务提供点出现问题并且依赖其服务的其他消费者存在调用链时,这条调用链就可能会造成失败,并且是级联失败。我们以前的做法是抛出异常让最终捕获做出处理,但是呢?一个花费了很大资源的操作因为一些可能不是很重要且必须的操作而失败,最后的结果为Null,其实有些操作我们可以实现一个后备数据,有些操作即使没有真实数据其实也是合理的,比如说我要买10个东西,结果第5个的时候出错了,不能购买,以往的做法是直接报错,整条链路返回,但是也是资源消耗极重的,spring cloud 模式的判断规则是5秒钟内失败20次表示此节点可以进入熔断模式了,也称为保护路模式。
统一路由:在一个十分庞大的分布式的业务系统中,其中对外暴露的功能是非常复杂以及繁琐的,如果是每个子系统各有一套声明规则,最终在组合成api文档时,这个文档的调用者肯定内心几乎是崩溃的,一会是REST风格,一会是带参风格,况且每一个系统的着重点不同,微服务最大的特点是架构再怎么变对整个系统来说都是无感知的,在互联网的时代,项目整体架构风格是不断迭代的,就像乐高积木,在做好了这些基础的方块之后,后面组合的形状取决于业务发展,也可以称为业务驱动,典型代表为淘宝,使用路由的思想,由路由入口打开流量入口,对外来说整个项目完全像是一个系统一样,接口文档的风格完全统一,对于不同业务系统的负载均衡策略也不同也是很容易实现的,对于像swagger这种项目动态文档肯定也是放在路由上的,对内实现为zull根据负载均衡策略转发请求到具体的实现者上.
配置及依赖管理:微服务虽说是各自系统维护各自功能,但是很多配置文件还是需要统一的,并且伴随中整体系统的升级,这样的全局配置变量如果是各自固定日写死的话,后面的改动就那么容易了.毕竟一个几十个系统能够非常迅速的改动同一个配置常量也是非常困难的,在eureka server中实现可以使用spring cloud configure,而在consul中是内部已经实现了,其实这样的配置中心只不过是一个微型的k-v数据库而已,当项目子服务系统中配置了配置中心时,在配置文件中引用变量会导致加载配置文件时动态从配置中心拉去数据并填充.与maven的思想有点类似.依赖管理使用的是maven来做到的,其实spring cloud 的实现一般都是maven项目,同时spring cloud官方推荐的是spring boot的基础项目构造.maven可以理解为一个特殊的能为你的功能导入jar库文件的软件,这个软件是apche下的一个优秀项目,项目受到开发人员的赞赏至今.这些具体的jar库文件会默认在你本地的c:/用户/用户名/.m2/repository下,以导入org.springframework.boot包的spring-boot举例,在repository下会有一个org的文件夹,其实就是以.分隔,每一个分隔的值都是一层目录,这里为org/springframework/boot/spring-boot文件夹,在之之下为各种版本号名称的文件夹,例如1.5.8.RELEASE/2.0.0.M3/…,在这之下为具体依赖的库文件了,例如:spring-boot-1.5.8.RELEASE.jar/spring-boot-1.5.8.RELEASE.pom/spring-boot-1.5.8.RELEASE-sources.jar/…,在项目的pom.xml文件依赖库文件的时候需要指定依赖的组织名和工程名和版本号,版本号会和这里的文件夹的版本号名一致,默认会导入运行依赖jar而不是source源码jar.同时在定义导入规则时可能不止3个,可能会有依赖环境,例如编译期compiler/测试期test/…,还有可能会到项目本地文件夹中依赖jar包,那么就需要使用systemPath标签填入${project.basedir}/lib/xxx名称-版本号.jar,这些jar库文件一般都是来自于maven的外部库,例如maven的中心库或者是其他公司的私有库,当然我们也可以搭建私有库,使用nexus搭建,一般在linux搭建服务的流程为下载文件,解压,配置配置文件,加入系统自启之类的环境变量文件中,使用给定的启动文件和参数启动服务.至于nexus的水平扩容,我暂时还没有做过.
多语言并存而统一调用声明:使用注解方式标注网络请求url来标注当前类为服务接口调用类,与以前使用的dubbo很相似,只不过dubbo是需要配置文件指明接口类对应的url,没有扩容功能,开发也并非简介,与spring boot的基于注解特点相违背,以前像这种都是将接口文件安装到nexus中,服务调用者需要先依赖该接口文件然后配置再调用即可,由于是基于http[s]网络接口的,所以拥有跨语言的强大功能,调用远程服务就像调用本地功能一般,当然也有一些属于正常范围的限制,比如说超时机制,比如说序列化效率低、效率不如dubbo/protocol buff/thrift.
在spring cloud中,这些问题的实现者为:服务注册及发现(Eueka Server/Consul+Eureka Client)、负载均衡(Ribbon)、调用链容错(hystrix)、统一路由(Zuul)、配置及依赖管理(Configure Server)、多语言并存而统一调用声明(Feign)、可视化运行状态监控(Metrix)。
值得一提的几个问题:
1、微服务与单体架构?最初项目由面向过程编程的c语言转向面向对象的java/c#编程,java以其一处编译处处运行,伴随着世界上最主流的服务器系统linux打败了其他语言,人们以为这是以后的趋势了,其实不然其实这才是开始,java工程通常对应小型企业来说是运行在tomcat上,中间或者会使用nginx做代理服务器来达到水平扩容,但是算一个数字,tomcat的并发量为300,不过新版本的tomcat的实现使用netty线程模型,可容并发量大大提升,但也是差不多,在通常情况下tomcat要实现业务的水平扩容必须实现session 共享,众所周知session 节点不能超过8台,否则此集群光是同步session所消耗的资源就已经将所有带宽都给占满了.这时候前面的nginx反向代理服务器难道就可以了吗?其实nginx并发量也是有限制的,毕竟nginx是无法反向代理的,理论上nginx的并发量为50000+,而实际并发量为30000+,一个系统难道十年前3W并发够了,今天还是3W并发量就够了吗?每一年的并发量都在指数级的增长,所以单体工程的容载量很难增长, 而微服务架构下的容载量就很容易提升了,以为服务之间的依赖是通过依赖服务实例名称的,而对外接口是网关分配可用实例的,微服务下不会直接使用session,所以对外来说使用哪一个正在运行中的实例都是没有很多区别的,而对于像是登录这种特殊操作,通常服务器都是会保存登录的客户端状态的,对此,我们往往使用SSO(single sign on)或者oauth2.0协议下的uaa系统.对于很早之前的互联网时代,需求都是来自分析的积累,刚开始的的项目都是几乎新生的,项目开始者需要面对于市场的风险、同类产品的竞争危机、工程技术的回避风险,在反复推打过程中就最终确定了项目的原型了,由于当时的IT项目的体验还是比较新鲜的,在新项目刚开始的一段时间,用户也是出于摸索阶段,项目的推广使用也是非常缓慢的,系统的维护时间还是非常充足的,找一个深更半夜停了再发布也是无足紧要的,但是,现在就不太一样了,用户量的海量增长,需求的迅速开发发布,如果是按照以往的方式,可能需要每几个小时整个系统都是需要重启的,而对于越来越庞大的代码量,越来越大的遗留问题,部署时间和开发时间越来越长,这样的系统最终会倒下,甚至会总是在忙于解决以往问题而无法解决新问题的。很庆幸,如果你使用微服务架构,你的系统的功能架构依旧不变,但是代码会拆分成多个子系统,子系统可以随意水平扩容,在有新需求的时候,如果是已有系统的功能增长,那么会在已有系统的基础上继续开发新功能,如果这个功能达到一定程度,这个时候子系统是可以继续切分的,此时开发人员是可以由内调或者外招的,各个系统的交互使用HTTP协议进行通讯,无论是java/c#/go开发的系统,整个系统都是高度兼容的.单体架构的push周期或者业务回环周期过长而由于微服务各部分是实现上的互不影响的,每次修改都是添加功能,不会影响其他模块,所以可以调高效率 .
2、微服务与分布式? 分布式是微服务的前生,分布式达到了一个大型项目的规模、兼容性和效率,但是其管理开发过程过于重量化,过于依赖运维没有统一实现、很多都是零零碎碎的拼接起来的,在服务注册与发现中使用的是RPC框架,比如说Dubbo和Zookeeper注册中心,在负载均衡上依赖Zookeeper或者nginx的实现,对于开发人员来说可用功能过于简单,在调用上过于依赖语言特点,例如: Java服务如果使用Dubbo的话就只能被java服务调用,配置文件过于零碎,难以管理,因为就算是依赖管理使用了maven以及私有库,但是配置文件的部分值也是很难实现的,而且分布式一致性在分布式项目中的实现并非是直接实现的,而在微服务spring cloud中确实很容易实现的,常见的实现者为consul.RPC框架一般都是基于二进制流(自定义序列化),所以在跨RPC框架的实现上也是比较难的,而微服务是基于HTTP协议的,兼容性更高,但是实际运行效率是更低的.在功能的划分上,分布式的粒度更大,因为他是重量级的,粒度过小对整个系统来说是灾难性的,而微服务粒度更小,因为各自服务是自治的并且有网关在流量入口把握.
Spring Boot:
一个经过整合过的轻量级的spring 框架,通篇项目中避免使用xml文件而是用注解来简化项目,提高开发效率.基于spring 4.x实现了项目依赖动态扫描达到动态配置,项目可自带运行容器环境,经过maven打包成jar包后可直接启动,在实际项目中启动命令可为 nohup java -jar xxx.jar & ,同时基于spring boot的maven依赖文件一般为spring-boot-xxx-starter,spring boot官方已经提供了很多starter依赖,例如:data-jpa/web/….同时非常适合作为spring cloud的 基础架构,spring boot的web依赖默认为spring mvc作为控制层处理框架,使用thymeleaf作为前端模板框架,同时效率比传统servlet工程的jsp的效率要高,在使用上接近于jsp和freemearker的面向对象,同时拥有jsp/freemarker的逻辑控制功能,作为固定填充数据非常容易.在spring boot工程中通常由标注了@SpringBootApplication的类的main启动加载整个项目,初始化spring 容器,生成被标注了组件的类的bean,
docker:
一个容器技术,容器技术并非近些年的新技术,而是很早之前已经投入大规模实际生产的,早几年前,有openstack等等商用容器化技术,而作为新技术docker与openstack的区别在于docker使用了中心镜像仓库,使得很多原本安装在linux的服务可以通过从中心镜像仓库pull下来后直接运行而无需再次重复进项常规的linux运维操作,甚至在结合k8s或者swarm之后,可以迅速的大规模的水平扩容,这在过去无容器技术时是想都想不到的.同时docker是基于linux宿主机的内核的,是基于进程的隔离,所以docker的启动时秒级别的,但是openstack呢?分钟级别,openstack也有镜像的概念,但是这个镜像与docker联合镜像文件有些不一样,docker的aufs可以基于镜像分层,使得很多镜像可以共享镜像基础层,与openstack不同的是运行中的docker容器是基于覆盖镜像文件达到修改的操作的,所以不同容器的运行状态可以不同却共享基础镜像文件.再看oepnstack的使用,繁琐的配置文件,复杂的运维,docker基于shell式的交互,提供了pull镜像,运行镜像,停止容器,重启容器,删除容器,通过-v参数指定数据卷的挂载位置实现持续的使用.同时作为容器常用功能可以映射端口或者随机ip到宿主机中,通常一般都是使用-P指定固定端口,docker轻量级、高效率、众多免费镜像可用、支持大规模集群.同时docker的安装也是非常简单的几乎不怎么需要修改配置文件,安装时也只是一条yum指令就可以了,其实docker也是有一些不足之处的,比如说docker的安全性并不是特别高,集群间的网络传输效率也不是很高,配置容器的一些环境变量时并非特别方便,记得很典型的一个问题,docker-mysql中,针对时区的配置,为何不默认直接挂载宿主机的时区配置文件呢?
中间层:
使用spring cloud 作为微服务实现框架,所以首先需要确定服务注册中心服务,对于spring cloud来说,实现可以为:consul或者eureka server,对于配置中心服务器,consul已经内置了,而eureka server需要另外搭配config server,对于这样的注册中心,默认端口为8761,同时eureka server和consul不能共存.而在正式系统中,为了保持一致性以及系统功能简化,使用gateway网关系统,通常实现为zull,以前我也不理解为什么需要一个多余的网关,但是后来才慢慢理解到,对于一个不断复杂的微服务系统,网关的作用是非常重要的,节点扩充后,外部不能直接访问固定的ip而是需要访问一个代理去获取所有可用的可用ip然后调用具体的ip的功能,获取可用ip列表是eureka server 或者consul可以做到的,但是这两个却无法直接调用ip的功能,所以需要一个能够调用转发的功能,这就是zull的一个特点,同时对于swagger这种动态接口文档,我们也是将其放到网关上的.简而言之就是浏览器直接访问gateway,gateway转发到具体微服务系统上去指定调用功能.但是也是有一些问题的,并非所有的转发都是有意义的,比如说有权限认证的系统,需要进行访问控制’Access Control’,具体使用基于oauth2.0标准的uaa系统,而这个系统需要使用用户权限规则的声明,另外一个问题就是对于一次调用的负载均衡也是在网关上做到,所以众所周知zull的starter依赖中默认都是有ribbon的.然后内部子系统直接首先需要配置注册中心所在ip位置然后直接依赖服务生产方的声明的名称在配置了ribbon的负载均衡之后会在每次消费服务接口时进行相应规则的负载均衡.
底部层:
著名的日志收集分析框架–>ELK,分别是ElasticSearch、Logstash、Kibana的简称.elasticsearch简称es,是一个分布式的拥有独立部署能力、多线程等特点的搜索引擎,与Luccen的区别?Luccen是一个文档搜索的开发包,并没有部署能力,同时在一个项目中如果继承了搜索功能,那是绝对不会将搜索功能内嵌到项目中的,因为搜索功能的负载也是非常大的,同时文档库的声明、持续使用、备份等操作与传统项目是相背道的.与Solr的区别?Solr是一个搜索引擎,实现也是使用luccen,其拥有部署能力,但是Solr的部署能力也是非常有限制的,Solr天生并不支持集群,在我以往开发过程中虽然也是搭建了Solr集群,但是借助apache的另一个项目:Zookeeper,虽然最终可以实现分布式,但是依然是有很多问题,一个是搭建复杂,依赖运维操作,一个是最终文件的一致性问题.而es不一样,es天生支持分布式,在使用docker镜像搭建es集群时,强烈建议配置内存大小至少分配4G以上,不过或许这也是solr的一个优点吧,占用资源更少一点.而logstash是日志的分析、kibana是将数据可视化了,使用了metrix技术
技术总结
在实现具体子微服务系统中,使用以下技术:
spring boot
作为每个子系统工程的承载者,以基于注解简化开发出名.基于spring 4.x,而spring 是现今java 网站开发的趋势框架.由原来的重量级的EJB框架到现在无人不认同的轻量级Spring框架.Spring并非强制规定了整个系统的开发流程,而是提供了辅助功能,在针对传统网站的输入->处理->输出抽象成了MVC的架构思想,控制数据输入输出->获取数据->独立界面层开发,spring一直起着辅助整个作用,刚开始面对使用strux/strux2的使用者,spring 的整合是非常优秀的,spring定义了项目的启动,即必须先加载spring容器,在依赖的strux是会加载配置文件配置的action类,在依赖了hibernate时会加载配置文件中配置的dao类,等等诸如此类,spring提出了依赖注入(DI[Depency inject])的思想来做到松耦合的效果,然后上面的加载操作也就是new bean的操作,我们称之为IOC控制反转,每一个模块中只需要使用@Autowired之类的注解即可在调用阶段获取已经实例化的bean,所以spring项目启动时十分漫长的.而且在开发阶段使用tomcat的时候还很可能造成启动失败的现象,那个时候需要将启动超时时间设置更长一点即可.spring boot默认搭配的是maven,与传统maven依赖不同的是spring boot的pom.xml中是肯定会依赖一个spring-boot-parent的parent的,而且就算当前parent不是spring-boot-parent,但是肯定也是有一层的parent是指定parent为springBoot特定的parent,在我写这篇文章的时候,springboot官方推荐的版本为1.5.9,但是更大一点的里程碑版本2.x也快出来了,而且2.x是基于spring5.x的,其中spring5.x是可以使用spring webflux的,对于喜欢使用异步框架写网络相关代码是非常好的,毕竟reactor是非常好的.在涉及到异步线程模型的时候传统方式是阻塞式的非常不利于实现实际运行过程中由于延迟造成的一系列问题.springboot唯一的配置文件为application[-xxx].properties/yml,其中yml是基于对象属性的书写配置文件的一种新方式,在观赏性和排列性上是非常高的,当然书写也是比较麻烦的,还好我使用的是idea工具,有配置提示功能.在标注了@SpringBootApplication的类即为启动类,这个启动类起到加载springboot的作用,同时也可以配置通用参数或者bean,而取决了以往配置在配置xml文件的是@Configuration注解,在标注了该注解的类中书写标注@Bean的方法返回特定的需要依赖的Bean对象,在这个方法里面一般都是自己手动的new的.
Spring boot web
通过这个starter从而可以获取一系列的依赖,如spring mvc相关,structs2的框架是几年前项目的标配了,而现在大部分项目都是使用spring mvc了,spring mvc使用@Controller规定了控制层的入口,类似的为@RestController(这个注解相当于组合@ResponseBody,但是ResponseEntity对象也是不需要@ResponseBody也是可以返回实际数据的),同时通过@RequestMapping,或者@GetMapping或者PostMapping等等,标注实际映射的url,这里有一个坑,以往的系统系统动不动就用特殊的请求参数来分别功能,这在实际使用中一个是不够直观,一个是是控制层平白无故多出代码,另外一个伪静态化操作,我们现在普遍使用的是REST风格的url,在返回前端界面时使用返回String类型的数据,并且保证标注在类上的一定是@Controller而不是@RestController,该方法上一定没有@ResponseBody注解,return 的数据为”[或有或无的文件夹名]模板名称[或有或无的后缀]”,当然这是forward转发请求的写法,当需要写重定向的时候需要在前面加上”redirect:”字符串,其实默认是”forward:”,这是省略的写法.在控制层上我们一般做获取请求参数,这些参数有点隐藏的rest里面,使用@PathVariable获取,隐藏在parameter里面使用@Parameter获取,隐藏在body里面,使用@RequestBody获取,还有点可能隐藏在cookie里面,这些参数的数据都是需要控制层去获取能封装尽量封装到对象里面.同时也对于可以直接校验的对象中的参数可以使用校验框架,在形参签名标注@Valid注解.在控制层一般都是注入业务层的接口,有些复杂操作通常需要组合多个业务的功能才能实现,当然这是非常司空见惯的,在一个系统中,通常不管如何,控制层的异常是绝对不能向上抛出的,这里涉及到向上传参的方法,业务层如何向控制层传递参数呢?一个是返回值、一个是传入引用值对象、一个是ThreadLocal对象,一个是向上抛出业务层及其下层的业务异常,我们通常规定好业务层出现异常通常都是向上抛出的,不做任何捕获,直到控制层的捕获,通常如果有异常的话最后向调用者表达出异常的详细原因,此时一般会单独写一个枚举类、写一个常量类,当然、如果项目文档如果足够强大,程序员足够细心、开发周期非常短而没有时间写的话,一般我们都是会去写的,这个常量类其实是一个接口类,因为本来仅仅是只需要放置一些属性就可以了,而接口类中默认的访问类型就是public,而且是static修饰的.最后有一个非常重要的概念:aop,面向切面编程,在spring boot中也是基于注解实现的,使用的是@Advice注解,组合@PointCut等注解
Spring data jpa
在现如今的面向对象开发中,提起万事万物皆对象,在数据库层开发中,通常会使用hibernate,而spring data jpa是hibernate的简化升级版,其特点为标注一个为@Repository,并且这个类需要实现JpaRepository<实体类型,主键类型>,这里的实体类在Jpa中也并发由于是hibernate就要是配置,我们使用@Entity注解标注一个类为类与表映射,使用@Table映射数据库服务器中实际表名,使用@Id标注当前字段为主键,同时对于可自增的字段使用@GenereteVlaue标注,而在一些特殊操作,需要标注当前实体类为@DynamicUpdate或者@DynamicCreate,这在使用Timestampt类型的参数是比较好用,然后我也理解到timestampt是存储库,localDateTime是工具类,同时我的项目中使用了Lombok,这个框架可以使用注解为实体类生成getter和setter以及constructor方法.在项目初始开发阶段推荐使用,同时这个需要配置ide,由于我的是idea所以配置还是比较简单的,安装插件即可,在实体类上加上@Data注解,对于空参构造使用@NoArgsConstructor和@AllConstructor注解.对于实体类中属性名和数据库中表中列名不一致的问题,一般使用@Columne注解即可.一般主键的类型为String或者Long,Long的承载量更小,运算速度更快,拓展性小,可自增,而String加上UUID这种全局唯一之后实现承载量更大,当然对于Long可承载量来说其实也是很大的,其实一般项目使用Long其实也是可以的.Spring Data Jpa默认已经提供好了基于直接插入整个对象、修改指定id值的对象、删除指定Id值的对象、查找所有对象、查找指定id值的对象,同时基于查询提供了Pageable接口的传入参数,在业务层可自由组合size和page实现分页操作,但是有一个bug就是分页并非那么容易的时候spring data jpa定义的pageable就不是那么容易使用了,反而mysql的limit参数确实那么的好用,同时也可以指定sort规则,这些都是简单的,更加复杂的在于根据指定条件查找/删除/修改,然后有些查询的优化在于使用@Query注解实现,一些自定义的修改规则在于使用@Update注解,总体来说spring data jpa的使用是非常简单的.
Spring data mybatis
mybatis作为以执行效率为主要的框架,与spring data jpa不同的是,spring data mybatis是基于具体sql语句的.依赖于具体数据库,多个系统之间的dao层代码无法融合起来,在升级数据库的时候整个系统会有短暂的疲惫期.同时也会出现由于切换数据库导致的数据的兼容性问题,在大数据量迁移方面也是一个比较麻烦的问题.对于开发者来说,一部分掌握sql语言能非常流畅的优化来自sql语句的执行效率的人来说mybatis是极为好用的,但是另外一部分不那么流畅的人来说就为困难了,当然也可以请专门的写sql语言的dba来写或者优化sql语句.但是比spring data jpa这种对象关系映射的ORM框架不同的是,mybatis的操作多表的效率是非常高的.而jpa的多表会有执行的冗杂性,同时jpa的优化执行语句是非常困难的.虽然jpa的@Query可以直接强制执行对象SQL语句.spring data mybatis与直接使用mybatis不同的是,其使用起来也是以注解使用较多,虽然都是使用接口类,但是其尽量使用@Mapper类对dao类进行标注,使用@Insert、@Delete@、@Update+@Param、@Selete+@Reuslts进行crud语句的操作,至于其他的与进行jdbc语句差不多,mybatis其实也只是做了那么两件事情,结合书写的sql语句将参数设置进去,对查询结果数据属性将数据取出.通常在对于效率要求很高的项目中都是使用mybatis的,因为对于一个项目来说在现如今每提升一点系统性能对于经济的获取也是非常大的,另外其实项目中是可以使用两套持久化技术的.前期使用spring data jpa实现,后期切换成mybatis其实也是可以的.
Thymeleaf
java网站开发从刚一开始的将页面冗杂到servelt中到提出mvc思想后将视图层单独出去,其中获取好处也是非常多的,由于将界面层作为三分之一,这样的前端可以直接由前端人员进行开发维护,刚开始的时候使用的是jsp技术,那个的时候的开发人员并非很多,网站承载量并非特别大,网页前端业务也并不复杂,所以导致对性能的要求不是很高,jsp的运行流程为转译编译运行,其中消耗的时间内在当初是并非很多的,但是对于现在来说这种消耗是很高的,这是导致我们弃用jsp的一个原因,还有一个非常重要的原因就是jsp非常依赖java servlet,这就使得jsp只能作为后端专属语言了,后来随着分布的口号,我们逐渐意识到前端渲染的重要性,那个时候我们使用的是Freeemarker网页静态化技术,这在当年还有一些类似的技术,例如:velocity,但是velocity的性能不如freemarker,后来网页静态化技术成了标准技术了,网页静态化技术为将传入数据传入模板中通过特点标签将数据填充到指定位置最后生成html文件,在一些高并发访问的网页使用这种静态化技术远远比动态化技术要好的多,典型代表为:淘宝,当年是什么支持了淘宝在那么用户冲击下服务器依然很流畅,一部分是cdn一部分就是静态化技术,另外的化就是其独特的架构了,要知道当前国内第一家开源RPC框架Dubbo就是阿里的.spring团队对市场上有先进性的技术都很感兴趣.比如struts2/hibernate,这些到现在逐渐变成了spring mvc以及最新基于reactor异步架构的spring wbflux和spring data jpa及其系列,甚至可以说freemarker就是thymeleaf的前生,同时spring 自家的spring mvc框架对thymleaf非常支持.同时thmeleaf对于面向对象思想支持的非常到位.将原本需要冗杂的标签改为属性,使得将html文件改为thymeleaf模板文件非常方便.
Spring data redis
redis是一个单线程基于内存支持分布式部署的服务.通常我们项目中使用redis一个是为了使用其基于内存的特点实现缓存,另一个是使用其单线程及其执行指令强原子性的特点实现并发锁机制.在项目中很多地方都会使用缓存,一个是用户登录信息token存入redis,而这在以往称之为单点登录.另外为业务数据缓存,如果是自己使用StringRedisTemplate实现缓存操作,那么这个业务的代码量又会平白增加很多了,在spring boot2.x中,我们通常是使用@Cache注解实现对缓存的操作,这个注解包含了获取缓存,清除缓存,修改缓存(当触发某种条件时),这种注解需要标注在方法名上,对于不同的方法实现不同的操作.其实redis一个更加重要的作用是作为并发锁,通常的秒杀操作都是能够使用这种并发锁达到单机程序锁所达不到的效率,因为这种锁是不会阻塞本地线程的.实现原理是因为一次向redis请求的指令为一组同时存取的原子操作,一次只能有一个操作成功,同时通常会在存数据的时候会设置过期时间,而取出数据时通常会使用时间戳做锁,将本机时间作为锁.而解锁的过程为将指定key的value移除掉.
Spring data ElasticSearch
在项目集成了搜索引擎之后,传统操作索引库是比较复杂的,但是功能最为完善,但是其实有些时候并不是需要那么完善的功能的,比如说高亮操作,这个时候我们通常是为了简化操作而封装一个通用方法,其实现在spring data 系列已经对es有了这种操作的支持了,使用spring data elasticsearch 可以非常简单的实现对索引库的CRUD操作,但是首先你需要定义一个文档类,使用@Document(“文档名称,通常类名也行”), 写一个接口类实现ElasticSearchRepository<文档库类,类中主键类型>.其使用方式与spring data jpa一致.
Logback
对于一个项目来说,日志是非常重要的,日志常用来分析程序漏洞、性能瓶颈、实际调用频率,同时对于自动化测试来说,没有日志就几乎是等于白测试了,因为有时候就算是自动化测试工具通过了,但是在实际运行过程中还是会遇到一些奇怪现象导致产生奇怪的数据,比如说就算是AssertNotNull(data)通过了,但是不代表这个data就是合理的了.现在可用的日志框架很多,比如说Log4j、Log4j2等等,它们都实现了同样的一些功能:以后台方式将运行时期的由开发人调制的数据和上下文信息通过灵活简便的配置(如日志输出格式、日志输出位置等等)实现非常高效的输出.但是log4j2由于过于先进,一些框架都还未支持,所以我们选择使用Logback框架,其实日志还有一个比较重要的作用是mybatis默认情况下不会输出执行语句,而是需要将mapper下的日志级别设置到dubug或者trace级别.
Swagger2
对一个web项目来说,接口文档是非常重要的.以前也有接口文档,但是以前的文档时有专门的维护人员或者开发人员去书写的,只是作为有哪些对外接口的文字描述,测试的时候需要测试人员再次复制黏贴Url并填入复杂的请求参数,同时这种测试是低效率的,对于多个复杂接口一起组合使用,是很实现的.多模块或者多子系统并行开发时,这种文档还影响着项目开发的进度,因为系统直接会有其他系统功能的依赖,swagger2打破了这一僵局,swagger2会扫描项目中所有加了@Controller或者@RestController的类,将这些类的映射路径分别收集起来在请求swagger暴露的REST API界面时会将这些映射路径分别隐藏在各自的Controller类中,同时可以手动指定Controller类的名称和方法名称以及请求参数声明.如果点进去会进入一个具体的请求url中,swagger会展示URL调用时需要传入哪些参数,哪些是必须的,参数的基本类型,如果再点击”Try it out”,会直接调用这个rest 的url,同时由于这个界面都是折叠效果做的,所以不必担心当前测试没有做完就去做下面或者上面的其他而导致丢失参数.总结来说:swagger的使用比较简单、而且测试非常方便
Apache ab
对于一个微服务的项目来说,如果你不测试它的并发量、容载量,那跟单体工程还有不同?Apache ab是一个命令行的可以测试并发效果的工具.至于使用是很简单的.
ActiveMQ/Kafka
对于一个中大型项目来说,任何的直接操作数据都有可能有未知原因导致操作失败.对于一些模块或者叫做系统来说,有些数据是不能丢失的,比如说订单系统,支付系统.分布式的项目常遇到的数据一致性问题都可以使用消息队列来解决.消息队列有AMQP和JMS两类,主流常见的消息队列服务有 ActiveMQ/RabbitMQ/Kafka,其性能大致都差不多,但是ActiveMQ不支持集群,如果需要集群的话需要借助Zookeeper.RabbitMQ天生支持分布式,Kafka在大数据生产环境中经常用到,所以在对于消息队列的话,功能最强的是Kafka,使用最简单的为ActiveMQ,同时由于spring整合的非常好,在使用Spring Kafka或者Spring Boot ActiveMQ,接受消息一般都是将一个方法上加上@XXXListener注解,在spring kafka中,传入参数为具体需求,返回参数的类型为Void,而在@XXXListener上需要标明id,topic等信息.而在发送消息使用@SendTo注解,并在注解中声明发送到的topic,topic中可以使用EL表达式从配置文件中获取话题名称.
Spring boot websocket
socket意思为套接字,一般用来维持长连接,使用长连接一般可以用作在线聊天,在spring boot框架下,有jetty/tomcat/undertow三种,如果是使用tomcat的话,由于已经内置了spring-boot-starter-tomcat所以不需要再次依赖,但是如果是使用的是jetty,那还需要spring-boot-starter-jetty.在使用中需要依赖spring-boot-starter-websocket并且清除掉spring-boot-starter-tomcat,写一个类继承TextWebSocket.重写handleTextMessage(处理消息)、afterConnectionEstablished(当消息处理之后)、afterConnectionClosed(连接关闭之后)、HandleTransportError(传输异常)方法,发送数据使用的是session的sendMessage方法,接受消息用的是TextMessage.
Docker
容器技术,安装一个mysql对于docker来说,仅仅只是查看一下文档,在dockerhub.com中查找mysql相关镜像,理解文档之后,按照他的pull指令在已经安装了docker的服务器中运行即可得到镜像,我一般都是用记事本将启动镜像需要的参数组织起来,在觉得OK之后再复制黏贴到SSH工具,如secureCRT软件,在镜像运行之后我一般会使用docker ps -a去查看容器运行情况,有点时候即使是当时启动成功了,后面也不一定能启动起来,当发现描述为EXIT时我都会查看一下启动参数和配置,而当运行一段时间之后为UP之后,这样的容器才有可能是认为是启动成功了.对于如何查看容器的基础信息,使用docker inspect.然后就是停止容器运行:docker stop 容器id,删除容器:docker rm 容器id,删除镜像而为本地文件系统腾出空间:docker rmi 镜像id,而对于如何查看容器id使用docker ps -a ,查看镜像id使用docker images.一个常见问题是容器内部时区问题,通常可以使用-e参数指定时区.另一个常见问题是docker中心库拉去镜像速度过慢问题,通常是需要配置加速器的,一般的加速器都很贵,但是阿里云有一个加速器速度非常快而且免费.进入容器中使用docker exec -it 容器id /bin/bash.
功能

卖家能够增加商品,修改商品(包括商品下架),删除商品,查找指定商品,搜索商品,查找所有商品并分页显示
买家能够根据商品的特征进行搜索商品,比如说红色手机,特征为红色和手机.
买家能够进行活动中的秒杀商品操作
平台会根据商品实际分类将商品进行分类显示给卖家,分类是一种多层次关系,比如说智能家电、床上用品
买家能够查看商品详情并且能够将该商品加入”收藏”/”到货通知”/”购物车”/”订单”
买家能够对未支付订单支付,或者在下订单的时候进行付款,买家能够使用支付宝或者微信支付,在App中用户能够提示打开微信或者支付宝进行支付,而在网页中,会跳转到支付宝或者非微信的支付界面,支付成功即为下单成功
卖家会能够及时的得到买家下的订单,这里我们使用websocket长连接,并及时进行发货等操作,并且能够选择物流的公司,并且在物流公司确认发货之后会告诉卖家开始发货,买家会通知买家已经开始发货了
买家能够支付关注到物流情况,这里我们集成了物流公司的实现查询接口API
有反馈系统,买家和卖家都可以直接向系统提出意见和建议
————————>如果只有上面的功能,那么这个项目将是毫无意义的—————>下面的才是开始:
随着社会的高速发展,生产力已经超过了过去十年的总和,IT时代的到来,我们渐渐意识到经济发展的规律,不管是淘宝还是京东,其核心功能为为生产力分配价值、加速流通,十年前淘宝是如此,今天还是如此,十年前人们觉得淘宝是多余的,觉得线下商店就够了,但是从第一座城市建立开始到现在,没有哪一家商店能够站在城市的角度思考生产力的分配,淘宝做到了,哪怕是十座城市的人口流量还是一百座都是同一个入口,同一家商城,淘宝利用其分层的思想将适合的商品送到合适的人手中,对外部看来淘宝就像是一个巨型的商店,甚至比线下商店更加专业,因为他的数据是统一的,用户需要看到商品、用户需要拿到商品、用户需要付款、用户需要退货等等.淘宝真的很牛逼,如果管理一个市中心的商店是有难度的话,中国那么多的线上商店的管理那将是指数级别难度的增长.十多年前淘宝以商家进入线上出售商品、物流公司将商品发送为驱动,利用互联网流通快、消耗小、入口统一的特点在中国消费者市场站稳,淘宝的盈利模式为商家管理费用,至于费用细节这里就不细谈了.
渐渐的,买家觉得购买的东西不够好,淘宝推出了已购买者的评价功能,淘宝平台以为这样就可以有效抑制差货现象,其实不然,在推出这个功能之后没过多久,大规模的刷单浪潮掀起,一单刷单,评论的质量就无法保障,一单这个的质量无法保障,买家在购买东西的时候将是没有任何的可信性,刷单的流程一般为互联网中随意的一名买家在购买这件商品之后发布好评,商家不发货或者接受退货,刷手不收货或者退货,这样的虚假交易带来的好评对其他消费者是一种误导甚至是坑骗,至于刷手的利益是什么?是来自商家额外的奖励,在退还本金之后额外一些小费,由于网络交易几乎不存在阻塞性,刷手很可能就是靠这种方便一天为几百家商店刷单.其实这不能怪刷手,这是平台的漏洞导致的.再看用户购买的操作,我相信很多刚开始用淘宝的买家可能会有同一种情况,由于新鲜感会抑制不住想买点新鲜东西,其实实际并非实用的东西,在经济繁荣时期这是正常的,后来才开始后悔,特别是结合花呗之后导致的迅速购买带来的偿还期,对于平台来说这并没有什么,甚至是越多购买记录越好,但是这也是我为了改进这种而想做这个项目的一个原因.
有人说,淘宝上的二手商店是不是太多了?确实是很多,因为平台对于这种二手并不感觉有什么疑问,因为对于他来说,越多的商家越好,但是对于整个交易过程中来说,每多一个二手商店,买家的付出价值越加沉重,每多一个二手商店,在买家的付出价值不变的情况下,质量更加低下,其实我曾经一度在想如何消灭二手商店,在我想到答案之后,我又陷入了如何去验证这个答案的艰难境地,直到共享单车的出现,经过这样的验证我明白了我的答案是对的.
在商品繁杂的今天,如何在一个已知的已经是很详细的列表里面找到最适合自己的.在过去,淘宝是没有这件事情,仅仅是展示一个商品列表又是有什么用呢?后来淘宝推出了个性推荐、同类历史记录推荐,当然这是在结合大数据和人工智能分析之后的成果,其中如何去获取数据,一个是历史记录数据,如果你浏览了或者搜索了某一跨商品,我坚信在能够推荐的地方,淘宝都会推荐相关商品给你,一个相同行为轨迹的推荐,如果你购买了手机,恨与可能推荐其他众多用户在购买手机之后再次购买的充电宝给你,其实很多都有数据,只不多淘宝仅仅是一个交易平台,甚至是如果我想买一个东西我都无法找到相关功能去与我交流,交流的意思为买家不断输出数据,平台捕获数据并分析得到商品特征,而淘宝有的仅仅是一个搜索功能,当买家知道要买个什么东西的时候需要搜索干嘛?不知道要买个什么东西的时候如何搜索?搜索得到的众多商品怎么去选择最适合自己的.
关于假货问题,也就是商品描述与实际商品不符合.甚至是很多东西都是买了很长时间之后才知道这个商品是否有质量问题.如何去区分呢?靠买家评价,完全靠不住的.靠平台打分?那也只是个数据,其实就我来说,最靠得住的是生产链,这是我前面画那张图中明确强调的部分.只有完全真实透明的生产链才能保证商品的质量.对于工程来说质量=测试,但是在实际实际中,很多东西都没有那么简单.只有靠消灭二手,公开生产链.然后我发现淘宝和实际生产厂家是分开的.所以要连接起来其中必定要多加上一个二手.所以我们的平台必须要讲生产厂家搬到线上,但是真实情况是很多厂家都是只是生产一个部分的商品,难道对于一个买家来说就是只买一个部件吗?例如我要买手机,难道只是买一个高通的处理器吗?所以针对这一点,里面还有一个转折点,部件也是商品,但是不是给普遍的消费者买的,而是给需要这种部件的买家买的,我们将所有的买家抽象成需求者,需求者有不用的身份,需求者在需求商品的时候可以指明自己的身份,也可以使用存留在平台的身份.过去的ERP只是作为企业内部的管理,企业外部即企业与企业之间的联系几乎还是原来的模式,企业的选择依然是人工的,不过有些大企业会有依赖资源分析系统,对,这也是我们要做的,这一点与普通消费者的购买心理一致,所以抽象起来,几乎所有的需求者都是同一种的需求心理,当然普通人的需求心理我们可以分析出来,因为有足够多的数据,企业就不一定了,对此也只是将数据排行展示而已.企业在生产过程中有内部依赖需求即自己a部门生产的东西会被b部门依赖,也有外部依赖需求即a公司会依赖b公司的技术、商品等等,在我感觉的理想状态是,同一种企业应该将下层生产力融合起来,对于技术应该在充分实践之后让落后公司学习更加先进公司的技术,这就存在着一个肯学、一个肯教的问题了,至于下层生产力融合起来可以理解为公司将自己的处于生产层员工向这样的处于同一生产类型的人力资源池填充,当需要多少资源时向资源池中获取多少资源,当多了就填充,少了就向其他公司平台管理或者各公司联合管理申请,如果这样做了,整个行业就容易把握了,员工不再有公司限制,有的只是属于自己实际经验的充分发挥.更容易的对社会进行管理.在这样的模型下生产力将大幅度提升.
其实交易从古至今一直由三部分构成,需求者,响应者,价值,平台其实也是只需要根据这三个抽象对象展开业务即可,传统的有囤货开店直销、现代的有基于商家管理然后由商家自己管理顾客.对于需求者来说,获取自身相关的需要的商品,平台能更加理解需求者想要的东西,能向需求者推荐意想不到的商品,需求者能够花更少的钱而获取更好的货,需求者收到的货物有更好的质量,而对于响应者来说,能够将自己的货物送到想要到的需求者手中,当市场更好的时候能够更容易扩大自己的生产力,能够简化生产模型并和互联网融合,能向经营或者技术更好的同类响应者学习,能够免费使用商用ERP并随着时代前进而前进即有人能够将非互联网的响应者持续的带入互联网并不需要钱.而对于价值来说,能够有永久的记录保存(就像区块链)、能够迅速的流通并发挥到需要的地方(小额贷),能够不受社会的动荡抑制而是由商品的消耗价值决定,所有的需求都能直接用某一种价值进行衡量而不受限.
如何认为是需响成功?需求者从浏览商品然后下单、平台分析推送,当需求者付出响应价值、平台保存价值、响应价值分发响应者、响应者发出商品,需求者确认响应成功,对于剩余价值,响应者回购已售商品残余价值,需求者出售已购商品残余价值。
需求者在当前平台与其他平台的区别?需求者直接发布+需求者对话提炼,需求者行为轨迹,在响应库中主流需求与需求者吻合,其他需求者推荐.需求者直接发布可以理解为搜索功能或者向需求库中添加一条需求,响应者会在收到来自平台与之匹配的需求记录,需求者对话提炼,会使用人工智能中的人机对象,然后从对话中提取出所需商品的特征,然后当需求者认为描述清楚之后向需求者展示匹配的商品列表.需求者行为轨迹可以理解为根据用户历史购买物品推断出还将会购买的东西,这是属于大数据分析或者人工智能分析的实现技术,当需求者符合某一系列特征后会将属于这一特征的一些更加符合需求者实际情况的东西推荐给需求者.朋友的直接推荐.
响应者在当前平台与其他平台的区别?响应者可以直接发布商品,能够免费使用统一的ERP系统,能够从友站链入,响应者可以作为一个成熟商品的一部分部件进行发布商品,这样的部件可以理解为商品,而且当前公司很有可能会依赖其他公司的部件的商品.之所以只用统一的ERP系统,一个是为了将这些企业联合起来,一个是为了整合数据时更容易.还有很多功能以后再补充.
实现
在这个项目初期分为3个系统1个辅助服务进行开发,分别是了需求者系统、响应者系统、服务网关、注册中心,在需求者系统上实现了买家系统、需求分析系统,买家系统中能够进行常规的用户登录、注册、修改密码、忘记密码、修改用户信息、人脸识别登录功能,需求分析系统中有人机对话功能、需求记录、支付宝和微信支付功能、关于文件管理使用了阿里云的OSS服务.响应者系统中有响应者登录、注册、修改密码、忘记密码、修改用户信息、还有商品管理模块,关于商品模块支持响应者进行div操作,实际上也是字符串替换而已,订单管理系统,物流管理系统、支持从淘宝或者京东直接导入商品,能够加入生产链作为完整商品中的一个模块,能够发起生产链,支持免费使用统一抽象的ERP(企业资源管理)+OA(办公自动化)+EMS(制造执行)系统.针对发布商品或者生产链有智能检测模块保证平台合法经营.
对于项目中的注册用户功能,我们使用了阿里云的短信接口服务,当用户注册时需要先请求专门的发送短信的接口,此接口内实现较为简单,无dao层操作,无需涉及到数据库的操作,但是需要集成阿里云短信java版的maven依赖(官网提示没有依赖而是需要自己在自己的私有库上去安装),在封装了简单的发送短信的工具类后,使用发送短信是非常简单的,在开始集成阿里云短信接口服务时,需要申请短信模块和短信签名,这两个申请还是很简单的.将参数配置进去后,将固定参数配置到application.yml中,当然也可以使用application.properties,对于这两者的区别在于yml更加面向对象,在ide工具中,如idea中修改时很简单的,但是在记事本或者notepad++中就不容易了.其实影响也不大.还是推荐使用application.yml.在需要使用的方式使用@Value(“${xxx}”)注解进行注入.如果用户是使用了正确的手机号码进行注册,当然我们后台也会进行基于正则表达式的检查传入的手机号码.用户手机会在1-2分钟内受到短信通知,而对于短信丢失率,官网给出的数据是99%.再调用短信接口时,我会先生成0-9的6位数字的随机值,然后将此值放入redis中,因为项目中使用的是spring boot框架,所以集成一个spring data reids还会很简单的.而通过在业务层使用@Autowired StringRedisTemplate stringRedisTemplate; 注入redis操作对象,而通过这个对象可以将手机号码和0-9的6为随机数字放入redis中。当然在实际项目中是这样做的,声明一个业务常量接口类,在里面声明一个常量,因为interface类里面所以的属性都是public static final 修饰的,所以可以使得更加贴合实际.我会声明一个redis中直接存放的string的key的前缀,例如为’requester_regist_’;然后后面再直接拼接上手机号码,这样就是直接是’requester_regist_123456’,通过添加到redis并设置过期时间,过期时间默认为30分钟.当用户来注册的时候回携带手机号码,这个时候需要校验是否有效,还是需要注册redis操作对象并调用取数据的方法,从常量类中取出注册前缀以及传入的手机号码,如果取出的值不为空并且与传入的verificationCode一致,则给与注册.同时对于账号名是否有效会进行校验,比如说是否与正则表达式符合,同时还会校验用户名是否已经存在,如果存在则不给予注册.在返回数据对象会封装一个抽象响应对象.需要封装一些必须的属性,例如:响应吗、数据(类型为泛型T,以为不管是返回单个pojo对象还是page对象还是list对象都是可行的)、消息内容,通常还会声明一个用户注册的枚举类,该类中必须设置int code和stirng msg,对于这样封装,虽然是增加了代码量,但是很好维护,代码格式很优美.就此客户端,不管是pc的html还是手机app都是可以通过判断code表示是否注册成功.对于数据校验成功之后就可以开始写入数据库了,本项目中使用的是mysql,并且将mysql是通过docker进项安装了,在启动时固定了映射端口为3306,其实个人感觉最好不要随机映射端口或者ip,原因也是很简单的,因为下次启动的时候服务的访问地址都改变了,对于项目来说就是灾难性的了,同时在启动容器时指定数据卷,以便数据备份导出以及持续使用.同时对于mysql镜像一个bug就是时区问题,这是我在使用timestamp类型的列才发现的,通过查资料才发现是容器内部时区问题,我随即登录宿主机使用date指令查看了宿主机时间及时区,同时通过docker exec -it 容器id /bin/bash 指令进入了容器内部,在同样使用了date指定之后发现时区果然不对,相差8个小时,随机我再次查阅官方文档,解决方法有两种,一种是挂载宿主机时区文件,一个是同时-e携带参数指定容器时区.至此最终解决问题.在项目中使用的是spring data jpa,spring data系列框架都是很容易被开发人员接受的,spring data jpa 是基于hibernate 实现的,在抛弃了hibernte冗杂的配置文件.并基于接口类实现基于的crud,同时提供了高级查询对象,在spring data jpa中,表与类的映射关系只是几个注解接口解决.@Entity,@Table@Column@Id@GenerateValue,在接口层,异常都是需要写一堆代码,同时对于分页操作也是不够简洁,jpa 中只是需要声明一个接口类继承JpaRepository<实体类类型,主键类型>,在实际的多条数据查询中使用pageable对象,封住了size和page和sort对象,分页查询时同时指定page第几页,size一页多少条,sort:以哪些字段排序以什么属性排序.通常注册只需要返回id即可.同时既然是注册,密码的安全性也是非常高的.使用3倍md5并且加盐实现了加密明文操作,同时将加密方法封装起来,因为当用户使用明文密码登录是还是需要使用该加密类实现加密再比对才能校验是否密码正确.
对于项目中最基础的登录功能,我们实现的是SSO,英文名为single sign on,称为单点登录.当用户首次完整登录成功,业务层会生成全局唯一的字符串,而这个操作使用uuid即可完成,在java中生成一个UUID值是非常简单的,使用UUID类调用randomUUID即可返回一个32+4位的字符串,同时将该字符串中所有的’-‘替换为”即可.将此字符串即token(令牌)存入redis中,至于key,还是可以像前面一样在接口类中声明前缀,例如”requester_login_”,然后再加上用户的id,因为登录方式可以有多种,但是id确实唯一的.同时在业务层注入redis操作类,同时调用设置值的方法将key和token存入redis中并设置默认过期时间为2个小时.因为spring data redis的stringRedsiTemplate.opsForValue的存值方法支持指定时间单位,所以可以不需要讲毫秒值换算为2小时,而是2,TimeUnit.Hour即可。对于pc的html/html5可以直接通过session对象操作cookie对象即可,而对于像手机app这种,可以将token直接作为返回参数返回,html5的本地存储,安卓的sqlite这些都是可行的存储方案.在下一次请求登录时,如果对于该账号的token有效不为空,并且与传入的token一致,即可认为是sso登录,在多平台的时代,sso登录有着重要意义.
对于项目中的修改密码,首先要确保用户现在是登录状态,然后与注册用户差不多,但是在使用spring data jpa进行修改操作时需要使用@Update注解标注修改,同时在@Query(“sql语句”)使用ddl语句进行修改指定密码类的值.
对于项目中的忘记密码,实现与注册有公共之处,即为忘记密码需要验证手机验证码.然后与修改密码类似
修改用户信息与修改密码类似
关于项目中的人脸识别功能的实现,由于大数据耗费资源较重,所以对于一些市场上已经有的第三方云服务,这里就直接集成了,比如说人脸识别,在刚开始集成的时候这个东西应该很难,实际上很容易,因为我在阿里云上有长时间的时间经历,所以我刚开始的时候是选择阿里云的人脸识别服务,阿里云的人脸识别是基于两个图片的比对的,对于像当前这样的系统来说,我直接抛弃了,因为上传两张图片文件的代价是比较大的,虽然也可以改进为一张从客户端上传,其他的从OSS对象文件存储中使用内网进行传输,但是由于实现起来确实很麻烦,后来我找了一些的服务商,都没有符合我的业务,直到碰到百度云的人脸识别,百度云的人脸识别从一开始就是瞄准的团体型,几个核心的接口分别为:上传用户图片到用户组中,从用户组中比对传入图片,从图片组中删除指定用户图片,所以事情就简单了,在用户开启人脸识别并至少上传了一张图片,登录时只需要打开摄像头,拍摄一张图片并调用接口到服务器,然后调用从用户组中比对用户的接口将图片.返回结果为一系列的比对结果数组,同时可以指定返回的结果数组的大小,但是也有默认值,返回的第一条数据为相似度最高的,可以获取之前上传用户图片时额外指定的用户id字符串,判断相似度是否高于85,如果高于85数据即为合理,重新刷新token,实现与用户登录类似.
关于项目中的需求记录,当用户搜索时将搜索值提取分析保存到需求记录表中,平台会使用hadoop平台定时每一天8点到9点分析所有的搜索记录表,将数据提取到hdfs文件系统中,通过对标签的匹配,将一部分需求记录发送给响应者的查询接口.因为这个对实时性和效率并不是要求特别高,所以是hadoop是极好的,因为在云服务器中硬盘的性价比比内存的性价比低的多.
关于项目中的文件管理使用了阿里云的OSS服务,因为普通文件系统有着带宽抑制、性价比更低、影响服务器性能、扩容复杂,在思考之后决定使用OSS 对象存储服务,OSS还支持CDN加速,影音文件读取加速等特点,但是这也有一个缺点,文件删除策略过于死板,文件删除标准应该为文件与项目无关联,实现这个并不复杂,甚至是很简单,但是涉及到安全问题其实阿里云OSS也是不容易做的,所以我们可以自己做,写一个数据库文件列的管理模块,能够在输入连接数据库的参数:Url、数据库类型、用户名、密码后连接实际数据库得到所有表,管理人员在通过验证后展开表,勾选字段,在勾选了所有的有文件名称引用的表的字段后,将这些数据上传,这样我们就可以得到所有需要提取数据的位置了,这里我并不是使用的spring data jpa而是jdbc,因为这个属于过于灵活的操作,jpa做不到,在得到这些表及其字段名后,将这些数据存入记录表中,方便管理,使用quat Z实现定时服务,当开始调用分析功能时,我一个是需要将所有的数据从哪些列中查出,一个是要讲oss文件中当前项目的bucket中的所有的文件名称获取出来,这里的数据量的级别已经达到了大数据的范畴了,获取数据之后的处理很简单就是将sso文件库中的文件名逐个与数据库中的列中的文件名进行比较,如果发现sso文件库中的文件名不存在于mysql数据库中的指定列名中,那么这个文件就是可以删除掉的,但是具体实现我才发现并不是那么理想,在上传数据时会有干扰因素,因此,我想出了将上传数据库中的文件名的操作分为3个操作,一个声明开始上传,一个多次上传数据,最后声明确认上传接受、甚至需要管理员输入手机验证码.当然在删除操作进行前会进行备份操作.这个功能的系统容载量可以很容易扩容。