今天刷帖刷到一个网站,可以免费OCR识别,但是具体的次数我没有计算,文档上也没有具体说明,那么我们一起来看看吧
首先网址在这里:点我直达
1、我们需要注册一个账号,获取非常重要的参数【ColaKey】
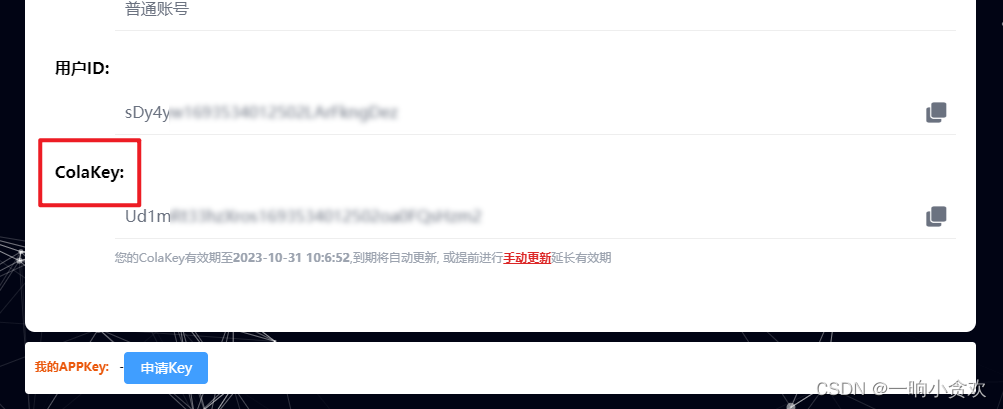
2、接着我们看一下文档说明(可跳过),点我直达

3、使用说明
1、URL,
POST请求:https://luckycola.com.cn/aiTools/imgOcr2、参数:重要提醒⚠️:该接口请求参数是multipart/form-data格式⚠️
| 序号 | 参数 | 是否必须 | 说明 |
| 1 | ColaKey | 是 | 唯一验证ColaKey, 可前往官网获取(http(s): //luckycola.com.cn (opens new window)) |
| 2 | file | 是 | 需要鉴别的图片资源(png、jpg、jpeg格式),注意:该接口请求参数是multipart/form-data格式 |
| 3 | lang | 否 | 当前检测的图片的内容是中文还是英文,如果是中文该参数值不传即可, 如果是英文传入“eng“,务必正确设置该值 |
3、我用的Postman测试的,下面是我的原图以及识别效果

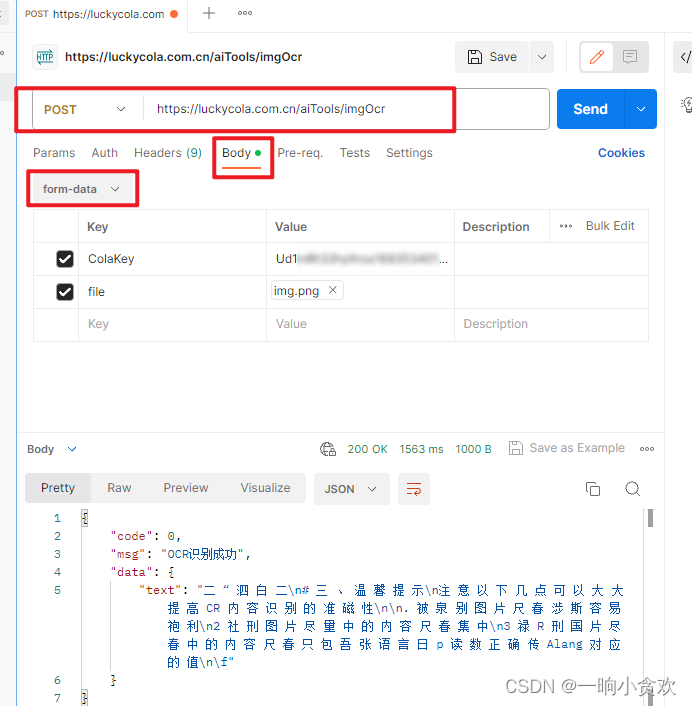
ok 识别成功,精度不是非常的准确
4、代码,可以直接利用Postman,生成代码!!
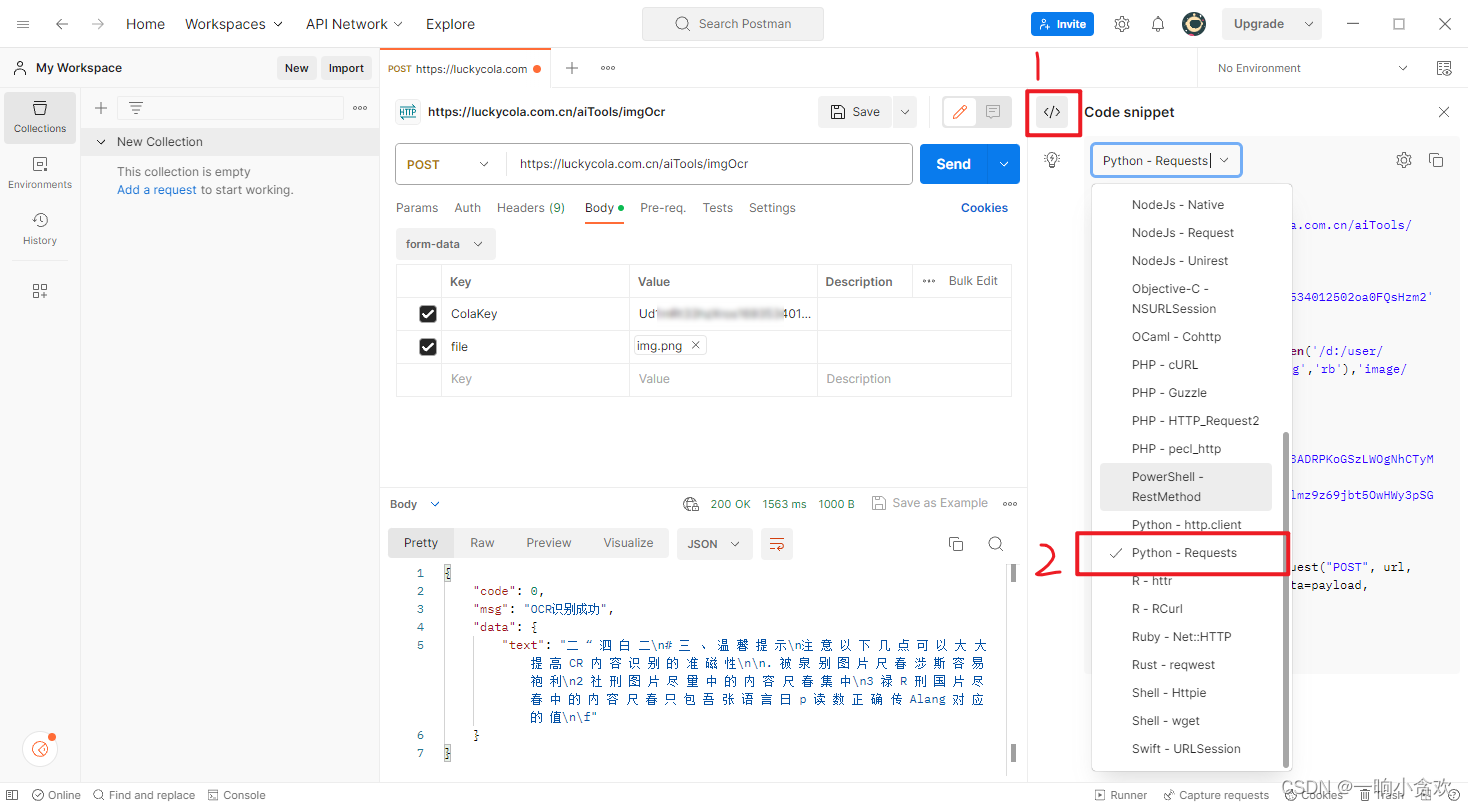
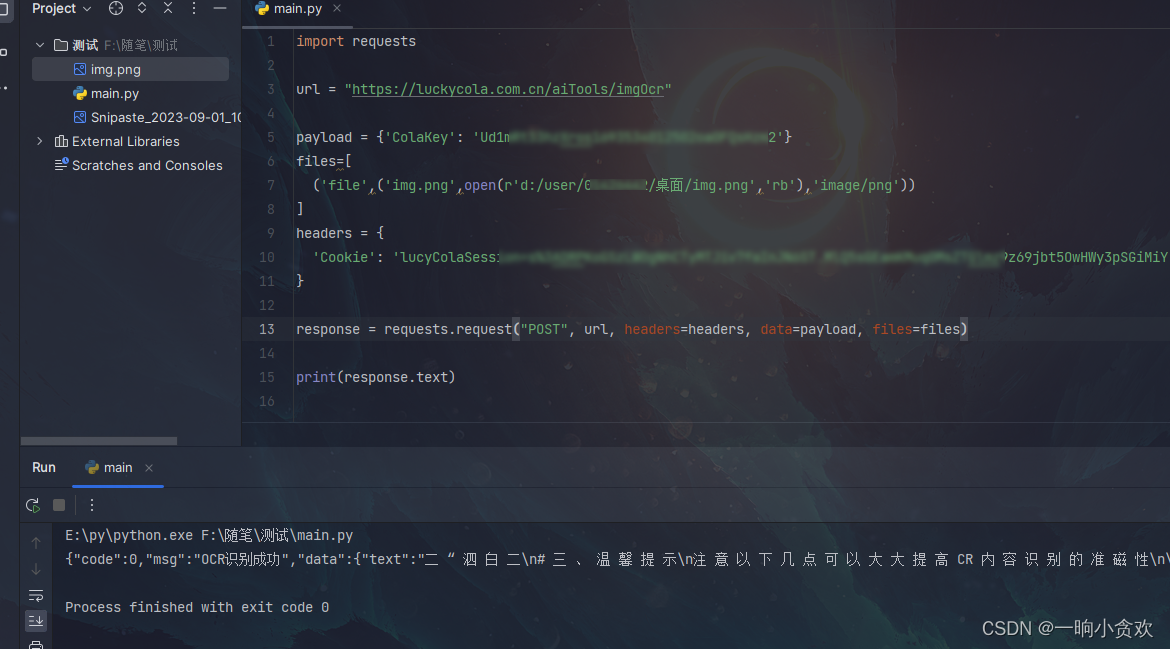
import requests
url = "https://luckycola.com.cn/aiTools/imgOcr"
payload = {
'ColaKey': '写上自己的'}
files=[
('file',('img.png',open(r'd:/user/桌面/img.png','rb'),'image/png'))
]
headers = {
'Cookie': '会自动生成'
}
response = requests.request("POST", url, headers=headers, data=payload, files=files)
print(response.text)
好了,今天的分享就到这里啦, 我之前也写过几篇,感兴趣的小伙伴,可以前去考古:
Python+Tesseract实现自己的OCR无限次识别(保姆级)
Python配置免费的OCR识别(OCRSpace)每月25000次(保姆级教学)
Python调用百度图片识别文字让自己有一个识别工具