Sentence-Bert论文全名: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Sentence-Bert论文地址:https://arxiv.org/abs/1908.10084
Sentence-Bert论文代码:https://github.com/UKPLab/sentence-transformers
Abstract - 摘要
BERT (Devlin et al., 2018) and RoBERTa (Liuet al., 2019) has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead: Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT. The construction of BERT makes it unsuitable for semantic similarity search as well as for unsupervised tasks like clustering.
In this publication, we present Sentence-BERT (SBERT), a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
We evaluate SBERT and SRoBERTa on common STS tasks and transfer learning tasks, where it outperforms other state-of-the-art sentence embeddings methods.1
BERT(Devlin等人,2018)和RoBERTa(Liuet al.,2019)在句子对回归任务上创造了最新最好的效果,例如语义文本相似性(STS)。然而,它需要将两个句子都送入网络,这造成了大量的计算开销:在10,000个句子的集合中找到最相似的一对,需要用BERT进行大约5千万次推理计算(约65小时)。BERT的构造使其不适合于语义相似性搜索以及聚类等无监督任务。
在这份论文中,我们提出了Sentence-BERT(SBERT),它是对预训练的BERT网络的修改,使用双连体和三连体网络结构来获得有语义含义的句子向量(embeddings),可以使用余弦相似度进行比较。这减少了寻找相似句子对的工作量,从BERT/RoBERTa的65小时减少到SBERT的约5秒,同时依然保持了BERT的准确性。
我们评估了SBERT和SRoBERTa在常见STS任务和迁移学习任务中的表现,其表现优于其他获取句向量的优秀方法。
一,Introduction - 简介
In this publication, we present Sentence-BERT (SBERT), a modification of the BERT network using siamese and triplet networks that is able to derive semantically meaningful sentence embeddings2. This enables BERT to be used for certain new tasks, which up-to-now were not applicable for BERT. These tasks include large-scale semantic similarity comparison, clustering, and information retrieval via semantic search.
BERT set new state-of-the-art performance on various sentence classification and sentence-pair regression tasks. BERT uses a cross-encoder: Two sentences are passed to the transformer network and the target value is predicted. However, this setup is unsuitable for various pair regression tasks due to too many possible combinations. Finding in a collection of n = 10 000 sentences the pair with the highest similarity requires with BERT n·(n−1)/2 = 49 995 000 inference computations. On a modern V100 GPU, this requires about 65 hours. Similar, finding which of the over 40 million existent questions of Quora is the most similar for a new question could be modeled as a pair-wise comparison with BERT, however, answering a single query would require over 50 hours.
A common method to address clustering and semantic search is to map each sentence to a vector space such that semantically similar sentences are close. Researchers have started to input individual sentences into BERT and to derive fixedsize sentence embeddings. The most commonly used approach is to average the BERT output layer (known as BERT embeddings) or by using the output of the first token (the [CLS] token). As we will show, this common practice yields rather bad sentence embeddings, often worse than averaging GloVe embeddings (Pennington et al., 2014).
在这份论文中,我们提出了Sentence-BERT(SBERT),这是一种使用双连体和三连体网络对BERT网络的修改,能够得出有语义的句向量。这使得BERT能够用于某些新的任务,而这些新任务到现在为止还不适用于BERT。这些新任务包括大规模的语义相似性比较、聚类和通过语义搜索来进行信息检索。
BERT在多种句子分类和句子对回归任务上创造了新的最优的表现效果。BERT使用一个交叉编码器:两个句子被传递给transformer网络,并预测出目标值。然而,由于有太多可能的组合,使得这种网络结构并不适合多种句子对的回归任务。在n =10000个句子的集合中找到相似度最高的一对,需要用BERT进行n*(n-1)/2=49 995 000次推理计算。在一个新式的V100 GPU上,这需要大约65小时。类似地,在Quora的4000多万个现有问题中找到一个与新问题最相似的问题,可以用BERT建模为一对一的比较,然而,回答一个查询需要花费50个小时以上。
解决聚类和语义搜索的一种常用方法是将每个句子映射到向量空间,这样语义相似的句子向量就会是相近的。研究人员已经开始将单个句子输入到BERT中,并导出固定大小的句子embedding向量。最常用的方法是将BERT的输出层(称为BERT的embedding向量) 平均池化或使用第一个token([CLS]token)作为BERT的输出句向量。正如我们将要展示的,这种常见的做法产生了相当糟糕的句向量,通常比GloVe向量(Pennington等人,2014)的平均更糟糕。
To alleviate this issue, we developed SBERT. The siamese network architecture enables that fixed-sized vectors for input sentences can be derived. Using a similarity measure like cosinesimilarity or Manhatten / Euclidean distance, semantically similar sentences can be found. These similarity measures can be performed extremely efficient on modern hardware, allowing SBERT to be used for semantic similarity search as well as for clustering. The complexity for finding the most similar sentence pair in a collection of 10,000 sentences is reduced from 65 hours with BERT to the computation of 10,000 sentence embeddings (~5 seconds with SBERT) and computing cosinesimilarity (~0.01 seconds). By using optimized index structures, finding the most similar Quora question can be reduced from 50 hours to a few milliseconds (Johnson et al., 2017).
We fine-tune SBERT on NLI data, which creates sentence embeddings that significantly outperform other state-of-the-art sentence embedding methods like InferSent (Conneau et al., 2017) and Universal Sentence Encoder (Cer et al., 2018). On seven Semantic Textual Similarity (STS) tasks, SBERT achieves an improvement of 11.7 points compared to InferSent and 5.5 points compared to Universal Sentence Encoder. On SentEval (Conneau and Kiela, 2018), an evaluation toolkit for sentence embeddings, we achieve an improvement of 2.1 and 2.6 points, respectively.
SBERT can be adapted to a specific task. It sets new state-of-the-art performance on a challenging argument similarity dataset (Misra et al., 2016) and on a triplet dataset to distinguish sentences from different sections of a Wikipedia article (Dor et al., 2018).
The paper is structured in the following way: Section 3 presents SBERT, section 4 evaluates SBERT on common STS tasks and on the challenging Argument Facet Similarity (AFS) corpus (Misra et al., 2016). Section 5 evaluates SBERT on SentEval. In section 6, we perform an ablation study to test some design aspect of SBERT. In section 7, we compare the computational efficiency of SBERT sentence embeddings in contrast to other state-of-the-art sentence embedding methods.
为了缓解这个问题,我们开发了SBERT。孪生网络体系结构使得可以导出输入句子的固定大小的向量。使用相似性指标,如余弦相似性或曼哈顿/欧氏距离,可以找到语义相似的句子。 这些相似性指标可以在新式硬件上非常高效地执行,从而允许SBERT用于语义相似性搜索以及聚类。在10000个句子的集合中查找最相似的句子对的复杂度从BERT的65小时降低到10000个句子向量的计算(SBERT约5秒)和计算余弦相似性(约0.01秒)。通过使用优化的索引结构,找到最相似的Quora问题可以从50小时减少到几毫秒(Johnson et al.,2017)。
我们在NLI数据上对SBERT进行了微调,这产生了明显优于其他优秀的句子向量方法的句子向量,如InferSent(Conneau et al.,2017)和Universal Sentence Encoder(Cer et al.,2018)。在七项语义-语篇相似性(STS)任务中,相较于InferSent任务,SBERT达到了11.7分的提升,相较于Universal Sentence Encoder任务提高了5.5分。在句子向量评估工具包SentEval(Conneau和Kiela,2018)上,我们分别获得了2.1分和2.6分的提升。
SBERT可以适应特定的任务。它在具有挑战性的论点相似性数据集(Misra et al.,2016)和区分维基百科文章不同句子的三元组数据集上(Dor et al.,2018)达到了新的最先进的性能。
本论文的结构如下:第3节介绍了SBERT,第4节评估了常见STS任务和具有挑战性的论点方面相似性(AFS)语料库的SBERT(Misra等人,2016)。第5节评估了SentEval上的SBERT。在第6节中,我们进行了消融研究,以测试SBERT的一些设计方面。在第7节中,我们比较了SBERT句向量方法与其他最先进的句向量方法的计算效率。
二,Related Work - 相关工作
We first introduce BERT, then, we discuss stateof-the-art sentence embedding methods.
BERT (Devlin et al., 2018) is a pre-trained transformer network (Vaswani et al., 2017), which set for various NLP tasks new state-of-the-art results, including question answering, sentence classification, and sentence-pair regression. The input for BERT for sentence-pair regression consists of the two sentences, separated by a special [SEP] token. Multi-head attention over 12 (base-model) or 24 layers (large-model) is applied and the output is passed to a simple regression function to derive the final label. Using this setup, BERT set a new state-of-the-art performance on the Semantic Textual Semilarity (STS) benchmark (Cer et al., 2017). RoBERTa (Liu et al., 2019) showed, that the performance of BERT can further improved by small adaptations to the pre-training process. We also tested XLNet (Yang et al., 2019), but it led in general to worse results than BERT.
A large disadvantage of the BERT network structure is that no independent sentence embeddings are computed, which makes it difficult to derive sentence embeddings from BERT. To bypass this limitations, researchers passed single sentences through BERT and then derive a fixed sized vector by either averaging the outputs (similar to average word embeddings) or by using the output of the special CLS token (for example: May et al. (2019); Zhang et al. (2019); Qiao et al. (2019)). These two options are also provided by the popular bert-as-a-service-repository3 . Up to our knowledge, there is so far no evaluation if these methods lead to useful sentence embeddings.
我们首先介绍BERT,然后讨论最先进的句子嵌入(向量)方法。
BERT(Devlin等人,2018年)是一个预训练的transformer网络(Vaswani等人,2017年),它达到了多种NLP任务的最新最佳效果,包括问答、句子分类和句子对回归。句子对回归任务的BERT输入是由两个句子组成,两个句子是由一个特殊的[SEP]token分隔。使用了超过12层(基本模型)或24层(大型模型)的多头注意力,并将输出传递到一个简单的回归函数以生成最终的标签。使用这种结构,BERT在语义-文本相似性(STS)的基准数据集(Cer等人,2017年)上达到了一种新的最先进的性能表现。RoBERTa(Liu等人,2019年)表明,通过对训练预处理进行少量的改编,可以进一步提高BERT的性能表现。我们还测试了XLNet(Yang等人,2019年),但总体而言,结果比BERT差。
BERT网络结构的一个很大的缺点是没有计算独立的句子向量(嵌入),这使得很难从BERT推导出句向量。为了绕过这一限制,研究人员通过BERT传递单个句子,然后通过平均池化输出(类似于平均词嵌入)或使用特殊CLS token池化输出(例如:May等人(2019);Zhang等人(2019);Qiao等人(2019))生成出固定大小的向量。这两个选项也由流行的bert-as-a-service-repository 提供。据我们所知,目前还没有评估这些方法是否会对句向量有益。
Sentence embeddings are a well studied area with dozens of proposed methods. Skip-Thought (Kiros et al., 2015) trains an encoder-decoder architecture to predict the surrounding sentences. InferSent (Conneau et al., 2017) uses labeled data of the Stanford Natural Language Inference dataset (Bowman et al., 2015) and the MultiGenre NLI dataset (Williams et al., 2018) to train a siamese BiLSTM network with max-pooling over the output. Conneau et al. showed, that InferSent consistently outperforms unsupervised methods like SkipThought. Universal Sentence Encoder (Cer et al., 2018) trains a transformer network and augments unsupervised learning with training on SNLI. Hill et al. (2016) showed, that the task on which sentence embeddings are trained significantly impacts their quality. Previous work (Conneau et al., 2017; Cer et al., 2018) found that the SNLI datasets are suitable for training sentence embeddings. Yang et al. (2018) presented a method to train on conversations from Reddit using siamese DAN and siamese transformer networks, which yielded good results on the STS benchmark dataset.
Humeau et al. (2019) addresses the run-time overhead of the cross-encoder from BERT and present a method (poly-encoders) to compute a score between m context vectors and pre-computed candidate embeddings using attention. This idea works for finding the highest scoring sentence in a larger collection. However, polyencoders have the drawback that the score function is not symmetric and the computational overhead is too large for use-cases like clustering, which would require O(n2) score computations.
Previous neural sentence embedding methods started the training from a random initialization. In this publication, we use the pre-trained BERT and RoBERTa network and only fine-tune it to yield useful sentence embeddings. This reduces significantly the needed training time: SBERT can be tuned in less than 20 minutes, while yielding better results than comparable sentence embedding methods.
句子向量是一个被广泛研究的领域,提出了许多方法。Skip-Thought (Kiros et al.,2015)训练encoder-decode网络结构来预测周围的句子。Inferesent(Conneau等人,2017年)使用斯坦福自然语言推理的标注数据集(Bowman等人,2015年)和MultiGenre NLI数据集(Williams等人,2018年)来训练孪生BiLSTM网络,以最大池化来输出结果。Conneau等人表明,InferSent 始终优于Skipthough等无监督方法。Universal Sentence Encoder(Cer等人,2018年)训练transformer网络,并通过SNLI训练增强无监督学习。Hill等人(2016)表明,句子向量训练任务明显影响其质量。 先前的研究工作(Conneau等人,2017年;Cer等人,2018年)发现SNLI数据集适合训练句子向量。Yang等人(2018年)提出了一种使用孪生DAN和孪生transformer网络带入红迪网(Reddit)的对话数据进行训练的方法,该方法在STS基准数据集上取得了良好的效果。
Humeau等人(2019年)解决了BERT的cross-encoder运行时间开销,并提出了一种方法(poly-encoders)来计算m个上下文向量之间的分数,并使用注意力预先计算候选向量。这个想法可以在更大的集合中找到得分最高的句子。然而,Polyncoders的缺点是得分函数不是对称的,并且对于如聚类等用例来说开销太大,需要O(n2)次得分计算。
先前的句子向量方法是从随机初始化开始训练的。在本论文中,我们使用BERT的预训练模型和RoBERTa网络,只对其进行微调,以产生有效的句子向量。这大大的减少了训练所需的时间:SBERT可以在不到20分钟内调整,同时生成比同类句子向量方法更好的向量结果。
三,Model - 模型
SBERT adds a pooling operation to the output of BERT / RoBERTa to derive a fixed sized sentence embedding. We experiment with three pooling strategies: Using the output of the CLS-token, computing the mean of all output vectors (MEANstrategy), and computing a max-over-time of the output vectors (MAX-strategy). The default configuration is MEAN.
In order to fine-tune BERT / RoBERTa, we create siamese and triplet networks (Schroff et al., 2015) to update the weights such that the produced sentence embeddings are semantically meaningful and can be compared with cosine-similarity.
The network structure depends on the available training data. We experiment with the following structures and objective functions.
Classification Objective Function. We concatenate the sentence embeddings u and v with the element-wise difference |u−v| and multiply it with the trainable weight Wt ∈ R 3n×k : o = softmax(Wt(u, v, |u − v|))
where n is the dimension of the sentence embeddings and k the number of labels. We optimize cross-entropy loss. This structure is depicted in Figure 1.
Regression Objective Function. The cosinesimilarity between the two sentence embeddings u and v is computed (Figure 2). We use meansquared-error loss as the objective function.
Triplet Objective Function. Given an anchor sentence a, a positive sentence p, and a negative sentence n, triplet loss tunes the network such that the distance between a and p is smaller than the distance between a and n. Mathematically, we minimize the following loss function: max(||sa − sp|| − ||sa − sn|| + , 0)
with sx the sentence embedding for a/n/p, || · || a distance metric and margin . Margin ensures that sp is at least closer to sa than sn. As metric we use Euclidean distance and we set = 1 in our experiments.
SBERT在BERT/RoBERTa的输出中添加一个池化层操作,以导出一个固定大小的句子向量。我们使用三种池化策略进行实验:使用CLS-token的输出,计算所有输出向量的平均值(MEAN strategy),以及计算输出向量的最大值(max strategy)。默认配置是MEAN。
为了微调BERT/RoBERTa,我们创建了孪生网络和三元组网络(Schroff et al.,2015),以更新权重,从而使生成的句子向量具有语义意义,并且可以使用余弦相似度进行比较。
网络结构取决于可用的训练数据。我们使用以下结构和目标函数进行实验。
分类目标函数。 我们分别获得u向量和v向量,与这两个向量按位求差向量| u-v |进行拼接,再将拼接好的向量乘上一个可训练的权重 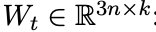
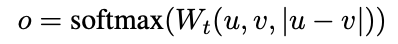
其中n是句子向量的维度,k是标签的数量。我们优化了交叉熵损失。该结构如图1所示。
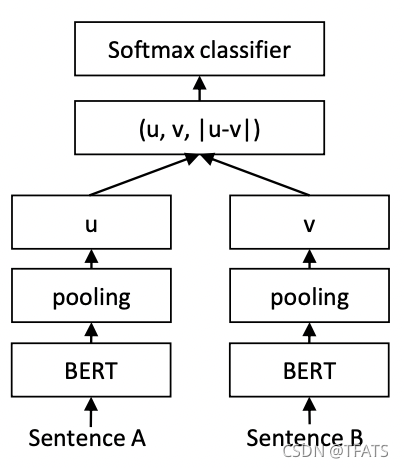
图1:具有分类目标函数的SBERT体系结构,例如,用于对SNLI数据集进行微调。两个BERT网络具有并列权重(孪生网络结构)。
回归目标函数。 计算了u向量和v向量的两个句子向量之间的余弦相似性(图2)。我们使用均方误差损失作为目标函数。
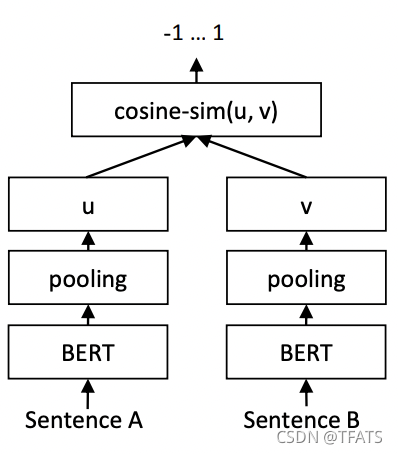
图2:例如,用于计算相似性分数的推理SBERT体系结构。该体系结构还与回归目标函数一起使用。
三元组目标函数。 给定一个锚定句a、一个肯定句p和一个否定句n,模型通过使 p和a 的距离小于 n和a 的距离,来优化模型。使其目标函数o最小,即:
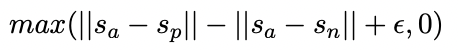
其中|| · ||代表的是两个样本的距离,本文采用的是欧氏距离,而S_a、S_p、S_n均为对应样本的sentence-Embedding。实验时,我们将超参数epsilon设为1.
1,Training Details - 训练详情
We train SBERT on the combination of the SNLI (Bowman et al., 2015) and the Multi-Genre NLI (Williams et al., 2018) dataset. The SNLI is a collection of 570,000 sentence pairs annotated with the labels contradiction, eintailment, and neutral. MultiNLI contains 430,000 sentence pairs and covers a range of genres of spoken and written text. We fine-tune SBERT with a 3-way softmaxclassifier objective function for one epoch. We used a batch-size of 16, Adam optimizer with learning rate 2e−5, and a linear learning rate warm-up over 10% of the training data. Our default pooling strategy is MEAN.
我们就SNLI(Bowman等人,2015)和多类别NLI(Williams等人,2018)的联合数据集上对SBERT进行训练。SNLI包含了57万句子对,这些句子对有对立,支持和中立的label标签。MultiNLI包含了43万句子对,涵盖各种类型的口语和书面文本。每一个epoch,我们使用3种softmax分类的目标函数微调SBERT。我们使用的batch-size为16,学习速为2e−5的Adam优化器,且训练数据集中的 10% 使用了线性的warm-up学习率。我们默认池化策略为平均池化策略。
四,Evaluation - Semantic Textual Similarity - 评估 - 语义文本相似
We evaluate the performance of SBERT for common Semantic Textual Similarity (STS) tasks.State-of-the-art methods often learn a (complex) regression function that maps sentence embeddings to a similarity score. However, these regression functions work pair-wise and due to the combinatorial explosion those are often not scalable if the collection of sentences reaches a certain size. Instead, we always use cosine-similarity to compare the similarity between two sentence embeddings. We ran our experiments also with negative Manhatten and negative Euclidean distances as similarity measures, but the results for all approaches remained roughly the same.
我们评估了SBERT在常见语义-文本相似性(STS)任务中的性能。最先进的方法通常学习将句子嵌入映射到相似性分数的(复杂)回归函数。然而,这些回归函数是成对工作的,并且由于组合爆炸,如果句子集合达到一定大小,这些函数通常是不可数的。相反,我们总是使用余弦相似性来比较两个句子嵌入之间的相似性。我们也使用负Manhatten距离和负欧几里德距离作为相似性度量进行了实验,但所有方法的结果基本相同。
1,Unsupervised STS - 非监督的STS
We evaluate the performance of SBERT for STS without using any STS specific training data. We use the STS tasks 2012 - 2016 (Agirre et al., 2012, 2013, 2014, 2015, 2016), the STS benchmark (Cer et al., 2017), and the SICK-Relatedness dataset (Marelli et al., 2014). These datasets provide labels between 0 and 5 on the semantic relatedness of sentence pairs. We showed in (Reimers et al., 2016) that Pearson correlation is badly suited for STS. Instead, we compute the Spearman’s rank correlation between the cosine-similarity of the sentence embeddings and the gold labels. The setup for the other sentence embedding methods is equivalent, the similarity is computed by cosinesimilarity. The results are depicted in Table 1.
我们在不使用任何特定的STS训练数据的情况下评估SBERT对STS的性能。我们使用2012-2016年STS任务(Agirre等人,2012、2013、2014、2015、2016)、STS基准(Cer等人,2017)和疾病相关性数据集(Marelli等人,2014)。这些数据集为句子对的语义相关性提供了介于0和5之间的标签。我们在(Reimers等人,2016年)中发现,皮尔逊相关性非常不适合STS。相反,我们计算了句子嵌入的余弦相似性和黄金标签之间的斯皮尔曼秩相关性。其他句子嵌入方法的设置是雷同的,相似度由余弦相似度计算。结果如表1所示。
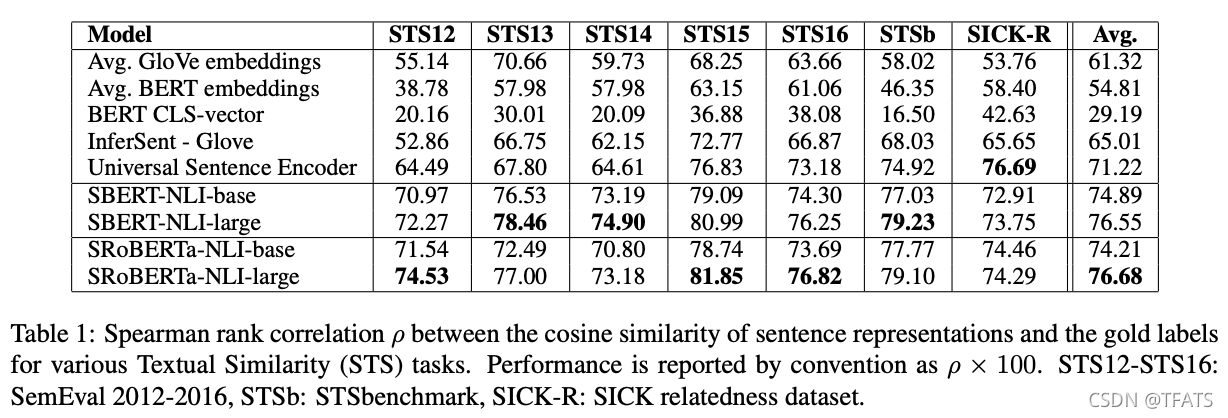
Spearman秩相关性ρ在句子表征的余弦相似性和各种文本相似性(STS)任务的黄金标签之间。按照惯例,性能报告为ρ×100。STS12-STS16:2012-2016年六月份,STSb:STSbenchmark,SICK-R:SICK关联性数据集。
The results shows that directly using the output of BERT leads to rather poor performances. Averaging the BERT embeddings achieves an average correlation of only 54.81, and using the CLStoken output only achieves an average correlation of 29.19. Both are worse than computing average GloVe embeddings.
结果表明,直接使用BERT的输出会导致相当差的表现。BERT 的 embedding 平均池化达到的平均得分仅为54.81,使用CLS token输出仅达到了29.19的平均分。这两者都差于计算平均 GloVe embedding。
Using the described siamese network structure and fine-tuning mechanism substantially improves the correlation, outperforming both InferSent and Universal Sentence Encoder substantially. The only dataset where SBERT performs worse than Universal Sentence Encoder is SICK-R. Universal Sentence Encoder was trained on various datasets, including news, question-answer pages and discussion forums, which appears to be more suitable to the data of SICK-R. In contrast, SBERT was pre-trained only on Wikipedia (via BERT) and on NLI data.
使用之前所描述的孪生网络结构和 fine-tuning 机制显著提高了相关性,大大优于 InferSent 和通用句子编码器。SBERT的表现比通用句子编码器差的唯一数据集是SICK-R。通用句子编码器在多种数据集上进行了训练,包括新闻、问答和论坛,这似乎更适合SICK-R的数据。相比之下,SBERT只在维基百科(通过BERT)和 NLI 数据上进行了预训练。
While RoBERTa was able to improve the performance for several supervised tasks, we only observe minor difference between SBERT and SRoBERTa for generating sentence embeddings.
虽然RoBERTa能够提高一些监督任务的性能,但我们只观察到SBERT和SRoBERTa在生成embedding句向量方面存在较小的差异。
2,Supervised STS - 有监督的STS
The STS benchmark (STSb) (Cer et al., 2017) provides is a popular dataset to evaluate supervised STS systems. The data includes 8,628 sentence pairs from the three categories captions, news, and forums. It is divided into train (5,749), dev (1,500) and test (1,379). BERT set a new state-of-the-art performance on this dataset by passing both sentences to the network and using a simple regression method for the output.
STS基准(STSb)(Cer等人,2017年)提供了一个通用的数据集,用于评估有监督的STS系统。数据包括8628个句子对,来自三个类别:标题、新闻和论坛。分为训练集(5749)、验证集(1500)和测试集(1379)。Bert 在这个数据集上达到了一个很好的效果,通过将两个句子传递到网络并使用简单的回归方法输出结果。
We use the training set to fine-tune SBERT using the regression objective function. At prediction time, we compute the cosine-similarity between the sentence embeddings. All systems are trained with 10 random seeds to counter variances (Reimers and Gurevych, 2018).
我们使用训练集来微调SBERT使用的回归目标函数。在预测时,我们计算句向量之间的余弦相似度。所有系统都使用10个随机种子进行训练以抵消差异(Reimers和Gurevych,2018)。
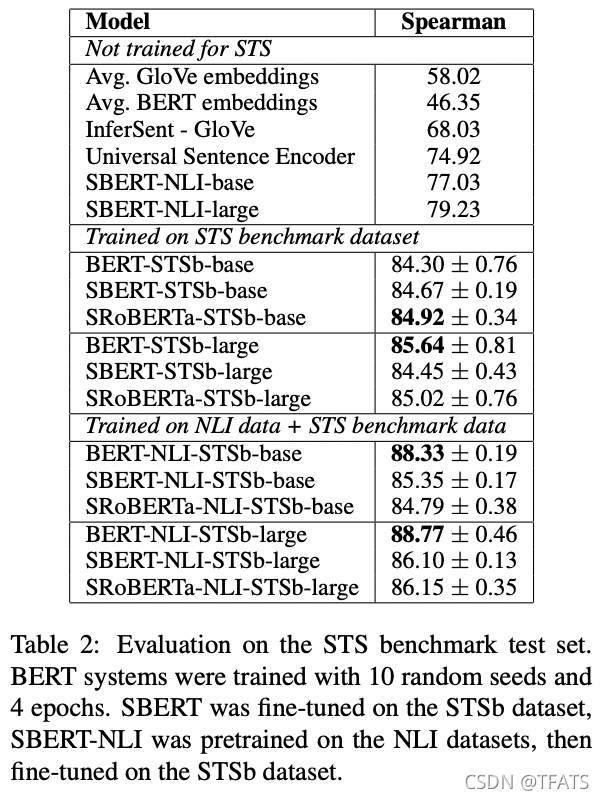
表2:STS基准测试集的评估。BERT系统使用10个随机种子和4个 epochs 进行训练。SBERT在STSb数据集上进行了微调,SBERT-NLI在NLI数据集上进行了预训练,然后在STSb数据集上进行了微调。
The results are depicted in Table 2. We experimented with two setups: Only training on STSb, and first training on NLI, then training on STSb. We observe that the later strategy leads to a slight improvement of 1-2 points. This two-step approach had an especially large impact for the BERT cross-encoder, which improved the performance by 3-4 points. We do not observe a significant difference between BERT and RoBERTa.
结果如表2所示。我们试验了两种方式:1,仅在STSb上进行训练,;2,首先在NLI上进行训练,然后在STSb上进行训练。我们观察到,后一种策略略微提高了1-2分。这种两步方法对BERT交叉编码器产生了特别大的影响,将性能提高了3-4个点。我们没有观察到 Bert 和 RoBert 之间的显著差异。
3, Argument Facet Similarity - 论证方面相似性
We evaluate SBERT on the Argument Facet Similarity (AFS) corpus by Misra et al. (2016). The AFS corpus annotated 6,000 sentential argument pairs from social media dialogs on three controversial topics: gun control, gay marriage, and death penalty. The data was annotated on a scale from 0 (“different topic”) to 5 (“completely equivalent”). The similarity notion in the AFS corpus is fairly different to the similarity notion in the STS datasets from SemEval. STS data is usually descriptive, while AFS data are argumentative excerpts from dialogs. To be considered similar, arguments must not only make similar claims, but also provide a similar reasoning. Further, the lexical gap between the sentences in AFS is much larger. Hence, simple unsupervised methods as well as state-of-the-art STS systems perform badly on this dataset (Reimers et al., 2019).
我们根据Misra等人(2016)的论点层面相似性(AFS)语料库对SBERT进行了评估。AFS语料库从社交媒体对话中注释了6000对句子论点对,涉及三个有争议的话题:枪支管制、同性婚姻和死刑。数据的标注范围从0(“不同主题”)到5(“完全等效”)。AFS语料库中的相似性概念与SemEval的STS数据集中的相似性概念大不相同。STS数据通常是描述性的,而AFS数据是对话中的辩论性摘录。为保证相似,论点不仅必须提出相似的主张,而且必须提供相似的推理。此外,AFS中句子之间的词汇差异要大得多。因此,简单的无监督方法以及最先进的STS系统在该数据集上表现不佳(Reimers et al.,2019)。
We evaluate SBERT on this dataset in two scenarios: 1) As proposed by Misra et al., we evaluate SBERT using 10-fold cross-validation. A drawback of this evaluation setup is that it is not clear how well approaches generalize to different topics. Hence, 2) we evaluate SBERT in a cross-topic setup. Two topics serve for training and the approach is evaluated on the left-out topic. We repeat this for all three topics and average the results.
我们在两种情况下对该数据集的SBERT进行评估:1)如Misra等人提出的,我们使用10折交叉验证对SBERT进行评估。这种评估方法的一个缺点是,不清楚方法对不同主题的概括程度。因此,2)我们在跨主题设置中评估SBERT。两个主题用于训练,并根据遗漏的主题进行评估。我们对所有三个主题重复此步骤,并取平均结果。
SBERT is fine-tuned using the Regression Objective Function. The similarity score is computed using cosine-similarity based on the sentence embeddings. We also provide the Pearson correlation r to make the results comparable to Misra et al. However, we showed (Reimers et al., 2016) that Pearson correlation has some serious drawbacks and should be avoided for comparing STS systems. The results are depicted in Table 3.
使用回归目标函数对SBERT进行微调。基于embedding句向量,使用余弦相似度计算相似度得分。我们还提供了Pearson相关性r,以使结果与Misra等人的结果具有可比性。然而,我们发现(Reimers等人,2016年)Pearson相关性存在一些严重缺陷,在比较STS系统时应避免使用。结果如表3所示。
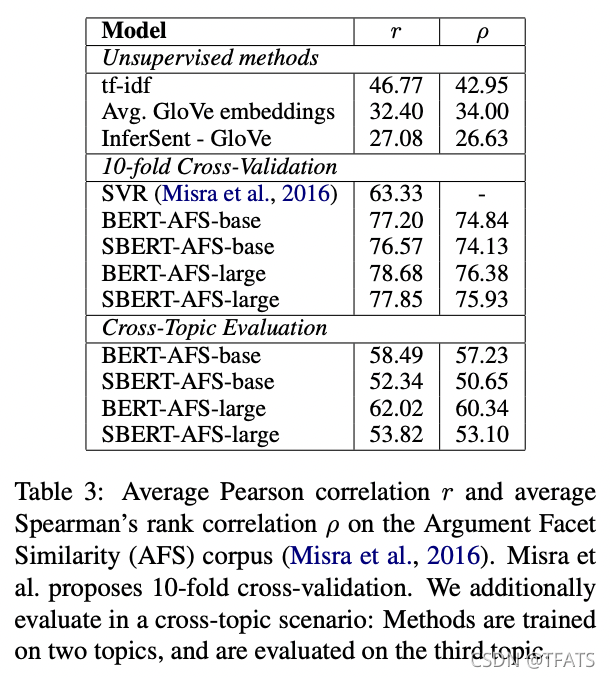
Unsupervised methods like tf-idf, average GloVe embeddings or InferSent perform rather badly on this dataset with low scores. Training SBERT in the 10-fold cross-validation setup gives a performance that is nearly on-par with BERT.
如 tf-idf、平均 GloVe embedding 或 InferSent 等无监督方法在该数据集上的表现相当糟糕,分数较低。在10折交叉验证方式中训练SBERT的性能几乎与BERT持平。
However, in the cross-topic evaluation, we observe a performance drop of SBERT by about 7 points Spearman correlation. To be considered similar, arguments should address the same claims and provide the same reasoning. BERT is able to use attention to compare directly both sentences (e.g. word-by-word comparison), while SBERT must map individual sentences from an unseen topic to a vector space such that arguments with similar claims and reasons are close. This is a much more challenging task, which appears to require more than just two topics for training to work on-par with BERT.
然而,在跨主题评估中,我们观察到SBERT的绩效下降了约7个斯皮尔曼相关点。为了保证相似,论点应该针对相同的主张并提供相同的推理。BERT能够利用注意力直接比较两个句子(例如逐字比较),而SBERT必须将单个句子从一个看不见的主题映射到一个向量空间,以便具有相似主张和理由的论点接近。这是一项更具挑战性的任务,似乎需要两个以上的主题做训练才能与BERT的效果相当。
4,Wikipedia Sections Distinction - 维基百科片段区分
Dor et al. (2018) use Wikipedia to create a thematically fine-grained train, dev and test set for sentence embeddings methods. Wikipedia articles are separated into distinct sections focusing on certain aspects. Dor et al. assume that sentences in the same section are thematically closer than sentences in different sections. They use this to create a large dataset of weakly labeled sentence triplets: The anchor and the positive example come from the same section, while the negative example comes from a different section of the same article. For example, from the Alice Arnold article: Anchor: Arnold joined the BBC Radio Drama Company in 1988., positive: Arnold gained media attention in May 2012., negative: Balding and Arnold are keen amateur golfers.
Dor等人(2018年)使用 Wikipedia 针对于句向量方法创建了一个细粒度主题的训练集、验证集和测试集。维基百科的文章分布在不同的部分,每个部分的文章集中在某一领域。Dor等人假设同一部分的句子比不同部分的句子在主题上更接近。他们使用这个假设创建了一个弱标记的三元句子组的大数据集:主题和正样例来自同一个部分,而负样例来自同一篇文章的不同部分。例如,摘自 Alice Arnold 的文章:主题:Arnold 于1988年加入英国广播公司广播剧公司。正样例:2012年5月,Arnold 获得媒体关注。负样例:Balding 和 Arnold 是热衷于业余高尔夫的人。
We use the dataset from Dor et al. We use the Triplet Objective, train SBERT for one epoch on the about 1.8 Million training triplets and evaluate it on the 222,957 test triplets. Test triplets are from a distinct set of Wikipedia articles. As evaluation metric, we use accuracy: Is the positive example closer to the anchor than the negative example?
我们使用Dor等人的数据集。我们使用三元组目标,每次迭代在180万三元组训练集上训练SBERT,并使用222957个测试三元组数据对其进行评估。测试三胞胎来自一组不同的维基百科文章。作为评估指标,我们使用准确度:是否正样例是否比负样例更接近主题?
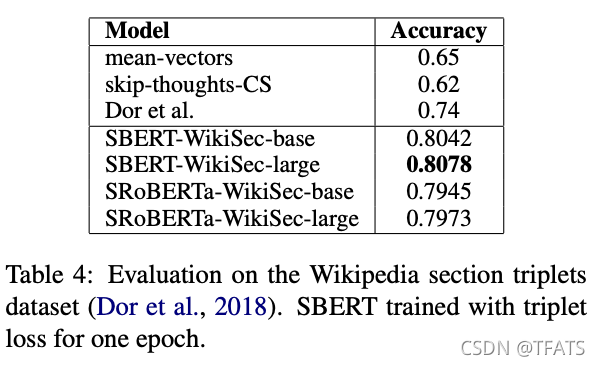
Results are presented in Table 4. Dor et al. finetuned a BiLSTM architecture with triplet loss to derive sentence embeddings for this dataset. As the table shows, SBERT clearly outperforms the BiLSTM approach by Dor et al.
结果如表4所示。Dor等人使用三元组损失函数来微调BiLSTM结构,从而生成这个数据集的句向量。如表所示,SBERT明显优于Dor等人的BiLSTM.
五,Evaluation - SentEval - 评估 - SentEval
SentEval (Conneau and Kiela, 2018) is a popular toolkit to evaluate the quality of sentence embeddings. Sentence embeddings are used as features for a logistic regression classifier. The logistic regression classifier is trained on various tasks in a 10-fold cross-validation setup and the prediction accuracy is computed for the test-fold.
SentEval(Conneau和Kiela,2018)是一个通用的评估句向量质量的工具包。句向量被用作逻辑回归分类器的特征。在10-折交叉验证的设置下,逻辑回归分类器在多个任务上进行训练,然后在测试集上计算预测准确率。
The purpose of SBERT sentence embeddings are not to be used for transfer learning for other tasks. Here, we think fine-tuning BERT as described by Devlin et al. (2018) for new tasks is the more suitable method, as it updates all layers of the BERT network. However, SentEval can still give an impression on the quality of our sentence embeddings for various tasks.
SBERT句向量的目的不用于其他任务的迁移学习。 在这里,我们认为Devlin et al.(2018)所述的微调BERT对于新任务是更合适的方法,因为它更新了BERT网络的所有层。然而,SentEval仍然可以给出,在多个任务上我们句向量质量的效果。
We compare the SBERT sentence embeddings to other sentence embeddings methods on the following seven SentEval transfer tasks:
• MR: Sentiment prediction for movie reviews snippets on a five start scale (Pang and Lee, 2005).
• CR: Sentiment prediction of customer product reviews (Hu and Liu, 2004).
• SUBJ: Subjectivity prediction of sentences from movie reviews and plot summaries (Pang and Lee, 2004).
• MPQA: Phrase level opinion polarity classification from newswire (Wiebe et al., 2005).
• SST: Stanford Sentiment Treebank with binary labels (Socher et al., 2013).
• TREC: Fine grained question-type classification from TREC (Li and Roth, 2002).
• MRPC: Microsoft Research Paraphrase Corpus from parallel news sources (Dolan et al., 2004).
我们使用以下7个SentEval 迁移任务来比较 SBERT 句向量与其他句向量方法:
•MR:电影评论片段的情绪预测,以五个起点为尺度(彭和李,2005年)。
•CR:客户产品评论的情绪预测(Hu和Liu,2004)。
•主题:电影评论和情节摘要中句子的主观性预测(庞和李,2004)。
•MPQA:新闻专线的短语级意见极性分类(Wiebe等人,2005年)。
•SST:Stanford情绪树库,带有二进制标签(Socher等人,2013年)。
•TREC:来自TREC的细粒度问题类型分类(Li和Roth,2002)。
•MRPC:微软研究院对平行新闻来源的语料库进行释义(Dolan等人,2004年)。
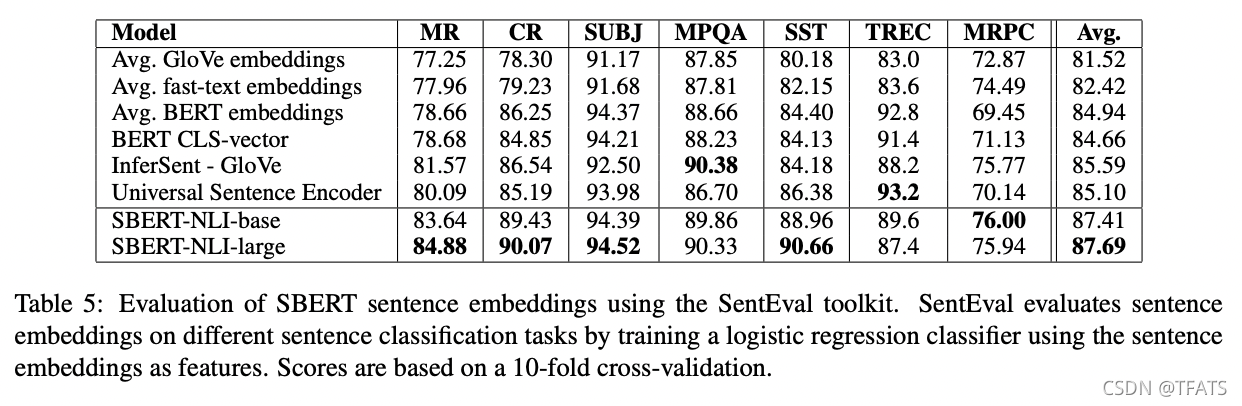
The results can be found in Table 5. SBERT is able to achieve the best performance in 5 out of 7 tasks. The average performance increases by about 2 percentage points compared to InferSent as well as the Universal Sentence Encoder. Even though transfer learning is not the purpose of SBERT, it outperforms other state-of-the-art sentence embeddings methods on this task.
结果见表5。SBERT能够在7项任务中的5项任务中实现最佳性能。与 InferSent 和通用句子编码器相比,平均性能提高了约2个百分点。尽管迁移学习不是SBERT的目的,但它在这项任务上优于其他最先进的句向量方法。
It appears that the sentence embeddings from SBERT capture well sentiment information: We observe large improvements for all sentiment tasks (MR, CR, and SST) from SentEval in comparison to InferSent and Universal Sentence Encoder.
SBERT的句向量似乎很好地捕捉了情感信息:我们观察到,相较于InferSent和通用句子编码器,我们发现在SentEval上的所有情感任务 (MR, CR, and SST) 都有很大的提升。
The only dataset where SBERT is significantly worse than Universal Sentence Encoder is the TREC dataset. Universal Sentence Encoder was pre-trained on question-answering data, which appears to be beneficial for the question-type classification task of the TREC dataset.
SBERT明显比通用句子编码器差的唯一数据集是TREC数据集。通用句子编码器是在问答数据上做预先训练,这对于TREC数据集的问题类型分类任务很有裨益。
Average BERT embeddings or using the CLStoken output from a BERT network achieved bad results for various STS tasks (Table 1), worse than average GloVe embeddings. However, for SentEval, average BERT embeddings and the BERT CLS-token output achieves decent results (Table 5), outperforming average GloVe embeddings. The reason for this are the different setups. For the STS tasks, we used cosine-similarity to estimate the similarities between sentence embeddings. Cosine-similarity treats all dimensions equally. In contrast, SentEval fits a logistic regression classifier to the sentence embeddings. This allows that certain dimensions can have higher or lower impact on the classification result.
对于各种STS任务(表1),BERT使用平均池化或者CLS-token的输出都获得了差强人意的结果,甚至比 GloVe embeddings还要糟糕。然而对于SentEval,两个都取得了比较好的效果(如表5),且优于均值化GloVe向量。造就这样不同的原因是设置不同。对于STS任务,我们使用余弦相似度来评估句向量之间的相似性。余弦相似度对于所有维度都是一样的。相反,SentEval将逻辑回归分类器适应于句向量。这就允许某些维度在分类结果上有或高或低的影响。
We conclude that average BERT embeddings / CLS-token output from BERT return sentence embeddings that are infeasible to be used with cosinesimilarity or with Manhatten / Euclidean distance. For transfer learning, they yield slightly worse results than InferSent or Universal Sentence Encoder. However, using the described fine-tuning setup with a siamese network structure on NLI datasets yields sentence embeddings that achieve a new state-of-the-art for the SentEval toolkit.
我们得出的结论是,BERT返回的平均池化或者CLS-token返回的句向量,使用余弦相似度 或者 曼哈顿距离 或者 欧氏距离是不可行的。 对于迁移学习来说,它们产生的结果比 InferSent 或通用句子编码器稍逊色一些。然而,在NLI数据集上使用孪生网络结构微调,产生的句向量对于SentEval工具包达到了新的最佳效果。
六,Ablation Study - 消融实验
We have demonstrated strong empirical results for the quality of SBERT sentence embeddings. In this section, we perform an ablation study of different aspects of SBERT in order to get a better understanding of their relative importance.
对于SBERT句向量的质量,我们已经有了强有力的实验结果来证明。在本节中,我们对SBERT的不同方面进行了消融研究,以便更好地了解其相对重要性。
We evaluated different pooling strategies (MEAN, MAX, and CLS). For the classification objective function, we evaluate different concatenation methods. For each possible configuration, we train SBERT with 10 different random seeds and average the performances.
我们评估了不同的池化策略(平均值、最大值和CLS)。对于分类的目标函数,我们评估了不同的拼接方法。对于每个可能的配置,我们使用10种不同的随机种子训练SBERT,并取其平均性能。
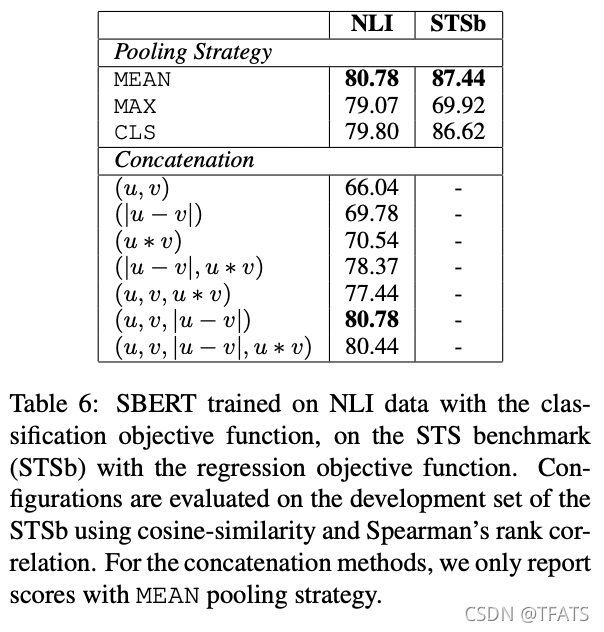
The objective function (classification vs. regression) depends on the annotated dataset. For the classification objective function, we train SBERTbase on the SNLI and the Multi-NLI dataset. For the regression objective function, we train on the training set of the STS benchmark dataset. Performances are measured on the development split of the STS benchmark dataset. Results are shown in Table 6.
目标函数(分类与回归)取决于数据集的注释。对于分类的目标函数,我们是基于SNLI和Multi-NLI数据集来训练SBERT。对于回归的目标函数,我们是在STS基准数据集的训练集上进行训练。表现效果是在STS基准数据集的分割验证集上衡量的。结果如表6所示。
When trained with the classification objective function on NLI data, the pooling strategy has a rather minor impact. The impact of the concatenation mode is much larger. InferSent (Conneau et al., 2017) and Universal Sentence Encoder (Cer et al., 2018) both use (u, v, |u − v|, u ∗ v) as input for a softmax classifier. However, in our architecture, adding the element-wise u ∗ v decreased the performance.
当在NLI数据上使用分类的目标函数进行训练时,池化策略的影响较小,拼接模式的影响要大得多。 InferSent(Conneau等人,2017年)和通用句子编码器(Cer等人,2018年)都使用(u,v,| u− v |,u∗ v) 作为softmax分类器的输入。然而,在我们的体系结构中,添加元素 u∗ v 反而降低了性能。
The most important component is the elementwise difference |u − v|. Note, that the concatenation mode is only relevant for training the softmax classifier. At inference, when predicting similarities for the STS benchmark dataset, only the sentence embeddings u and v are used in combination with cosine-similarity. The element-wise difference measures the distance between the dimensions of the two sentence embeddings, ensuring that similar pairs are closer and dissimilar pairs are further apart.
最重要的部分是元素之间的差异 | u− v |。 注意,拼接模式仅与训练 softmax 分类器有关。在推断时,当预测STS基准数据集的相似度时,只有句向量u和v用于和余弦相似性结合使用。 元素之间的差异度量的是两个句向量各个维度之间的距离,确保相似对更近,而不同对更远。
When trained with the regression objective function, we observe that the pooling strategy has a large impact. There, the MAX strategy perform significantly worse than MEAN or CLS-token strategy. This is in contrast to (Conneau et al., 2017), who found it beneficial for the BiLSTM-layer of InferSent to use MAX instead of MEAN pooling.
当使用回归的目标函数进行训练时,我们观察到池化策略有很大的影响。在这里,MAX池化策略的效果明显低于MEAN池化或CLS-token策略。 这与(Conneau et al.,2017)等人的研究形成对比,他们发现使用MAX而不是平均池化对Infresent的BiLSTM层是更有利的。
七,Computational Efficiency - 计算效率
Sentence embeddings need potentially be computed for Millions of sentences, hence, a high computation speed is desired. In this section, we compare SBERT to average GloVe embeddings, InferSent (Conneau et al., 2017), and Universal Sentence Encoder (Cer et al., 2018).
句向量可能需要计算数百万个句子,因此需要较高的计算速度。在本节中,我们将SBERT与 GloVe 、InferSent (Conneau等人,2017年)和通用句子编码器(Cer等人,2018年)进行比较。
For our comparison we use the sentences from the STS benchmark (Cer et al., 2017). We compute average GloVe embeddings using a simple for-loop with python dictionary lookups and NumPy. InferSent4 is based on PyTorch. For Universal Sentence Encoder, we use the TensorFlow Hub version5 , which is based on TensorFlow. SBERT is based on PyTorch. For improved computation of sentence embeddings, we implemented a smart batching strategy: Sentences with similar lengths are grouped together and are only padded to the longest element in a mini-batch. This drastically reduces computational overhead from padding tokens.
为了进行比较,我们使用了STS基准中的句子(Cer等人,2017年)。我们使用Python的字典查询和NumPy实现简单for循环来计算均值化的GloVe句向量。InferSent是基于PyTorch实现的。对于通用句子编码器,我们使用的是基于TensorFlow Github版本5来实现的。SBERT 是基于PyTorch实现的。为了改进句向量的计算,我们实现了一种智能批处理策略:长度相似的句子被分组在一起,并且只填充到批量中最长的元素。这大大减少了填充 token 的计算开销。

Performances were measured on a server with Intel i7-5820K CPU @ 3.30GHz, Nvidia Tesla V100 GPU, CUDA 9.2 and cuDNN. The results are depicted in Table 7.
性能评估是在配备 Intel i7-5820K CPU @ 3.30GHz, Nvidia Tesla V100 GPU, CUDA 9.2 和cuDNN的服务器上进行的。结果如表7所示。
On CPU, InferSent is about 65% faster than SBERT. This is due to the much simpler network architecture. InferSent uses a single BiLSTM layer, while BERT uses 12 stacked transformer layers. However, an advantage of transformer networks is the computational efficiency on GPUs. There, SBERT with smart batching is about 9% faster than InferSent and about 55% faster than Universal Sentence Encoder. Smart batching achieves a speed-up of 89% on CPU and 48% on GPU. Average GloVe embeddings is obviously by a large margin the fastest method to compute sentence embeddings.
在CPU上,InferSent 比SBERT快约65%,这是由于 InferSent 有更简单的网络架构。InferSent 使用单个 BiLSTM 层,而 BERT使用了12个堆叠的 transformer 层。然而,transformer 网络的一个优点是在GPU上的计算效率。在这里,带智能批处理的SBERT比 InferSent 快约9%,比通用句子编码器快约55%。智能批处理在CPU上实现了89%的速度提升,在GPU上实现了48%的速度提升。显然,Average GloVe 是计算句向量的最快方法。
八,Conclusion - 总结
We showed that BERT out-of-the-box maps sentences to a vector space that is rather unsuitable to be used with common similarity measures like cosine-similarity. The performance for seven STS tasks was below the performance of average GloVe embeddings
我们证明了BERT的输出embedding直接将句子映射到一个向量空间,而这个向量空间并不适合与常用的相似度(如余弦相似性)一起使用。七项STS任务的结果全部低于均值化的 GloVe 向量结果。
To overcome this shortcoming, we presented Sentence-BERT (SBERT). SBERT fine-tunes BERT in a siamese / triplet network architecture. We evaluated the quality on various common benchmarks, where it could achieve a significant improvement over state-of-the-art sentence embeddings methods. Replacing BERT with RoBERTa did not yield a significant improvement in our experiments.
为了克服这一缺点,我们提出了SBERT。SBERT在孪生/三元组网络体结构中微调。我们在多种常见的基准数据集上评估了SBERT的质量,在这些基准上,它可以比其他优秀的句向量方法实现显著的改进。使用 RoBERTa 代替 BERT 并没有在我们的实验中产生显著的改善。
SBERT is computationally efficient. On a GPU, it is about 9% faster than InferSent and about 55% faster than Universal Sentence Encoder. SBERT can be used for tasks which are computationally not feasible to be modeled with BERT. For example, clustering of 10,000 sentences with hierarchical clustering requires with BERT about 65 hours, as around 50 Million sentence combinations must be computed. With SBERT, we were able to reduce the effort to about 5 seconds.
SBERT的计算效率很高。在GPU上,它比InferSent快约9%,比通用句子编码器快约55%。SBERT可以用于计算那些BERT无法建模的任务。 举个例子:使用分层聚类对10000个句子进行两两聚类需要大约65个小时,因为必须计算大约5000万个句子对组合,而使用SBERT,我们能够将工作量减少到5秒左右。