一,下载对应版本驱动
1,选择对应的驱动版本
下载驱动地址:https://www.nvidia.in/Download/index.aspx?lang=en
本文内容以 A30(NCCL)、A100(NV-Link)、A100(NV-Switch) 为例:
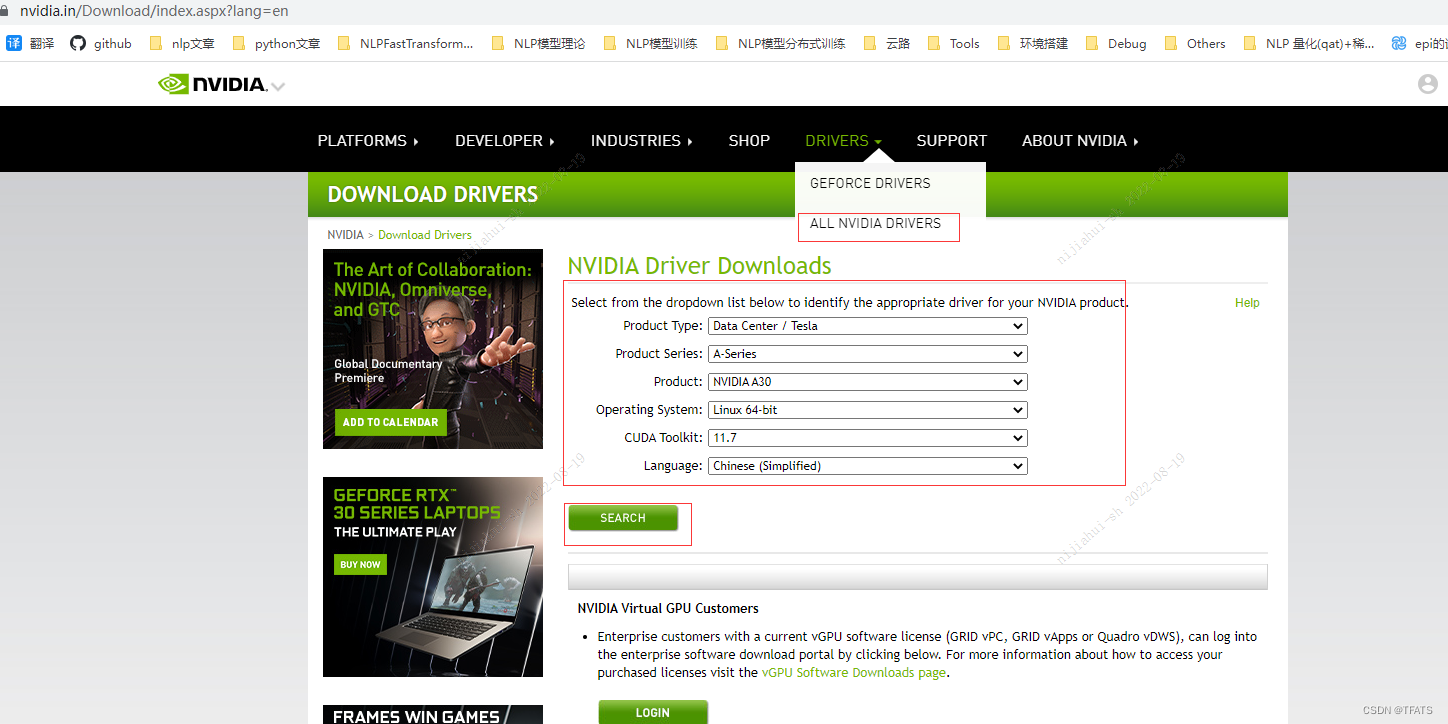
2,获取选择驱动的下载链接
1) 确认如下版本信息是否正确
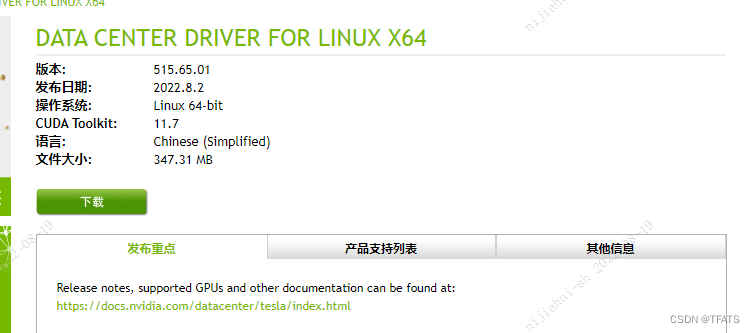
若正确则点击下载
2) 复制下载链接
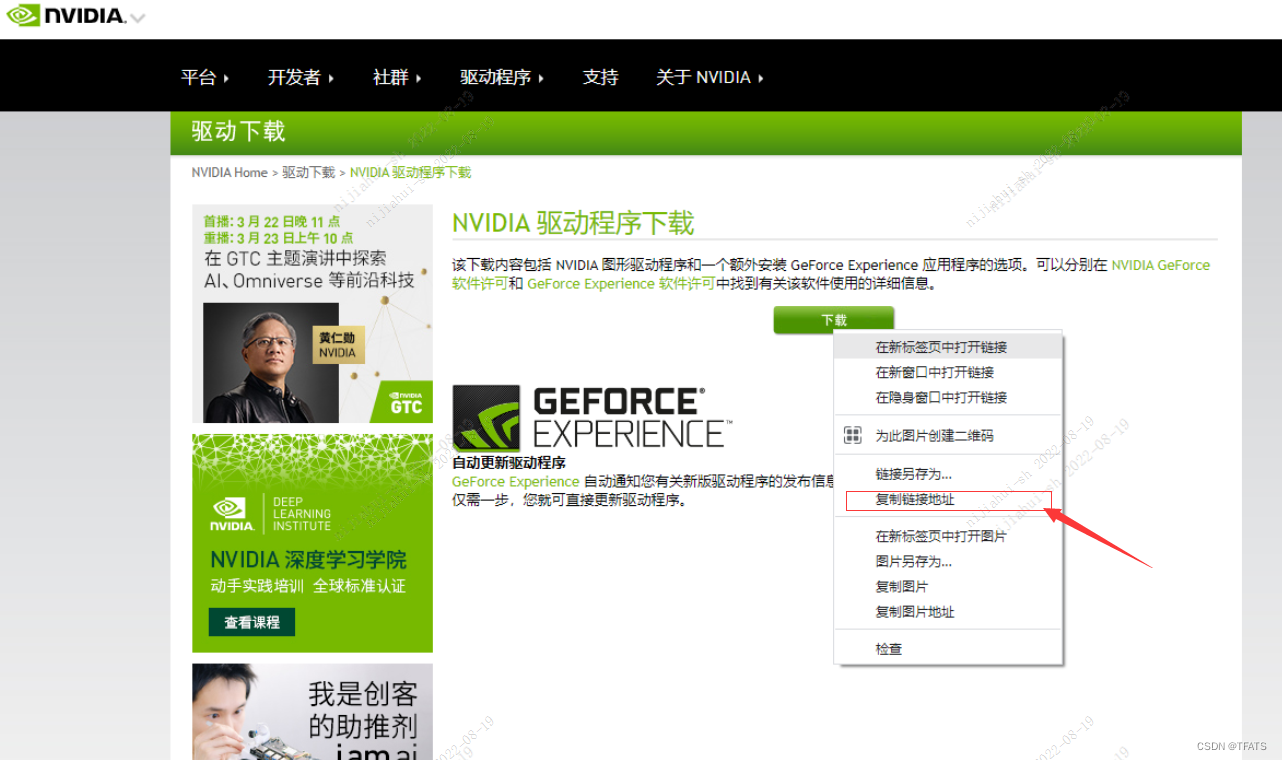
3,服务器中下载驱动
1)下载驱动
终端执行: wget 【复制的链接】
eg:
wget https://cn.download.nvidia.com/tesla/515.65.01/NVIDIA-Linux-x86_64-515.65.01.run
2)赋文件执行权限
chmod +x 【驱动文件】
eg:
chmod +x NVIDIA-Linux-x86_64-515.65.01.run
二,停掉所有和显存占用有关系的应用、容器
1、停掉容器
# nvidia-smi --query-compute-apps=gpu_uuid,pid,used_memory --format=csv | grep '[0-9]' | sed 's/[[:space:]]//g' | sed 's/MiB//g'
# docker inspect -f '{
{ .Name }}' $(ps -e -o pid,comm,cgroup | grep -v "/docker/" | grep <PID> | awk '{print $3}' | awk -F "[/.-]" '{print $5}') | sed 's/\///g'
docker ps | awk '{print $1}' | grep -v CONTAINER | xargs docker stop
2、查看 nvidia 占用应用
sudo lsof -n -w /dev/nvidia*
查看 PID 后,可使用 kill 命令结束该进程
3、确认是否有 nvidia 应用占用
ps -aux | grep nvidia
4、查看是否存在 k8s 应用占用
# 使用下面命令查看
systemctl status kubelet
# 若存在则执行下面命令
systemctl stop kubelet
三,执行驱动升级
./NVIDIA-Linux-x86_64-515.65.01.run
注:
- 所有选项选择 YES
- 可另起一个终端查看nvidia update 升级日志 :
tail -f /var/log/nvidia-installer.log
四, 启动多卡持久化模型
nvidia-smi -pm 1
五,升级 fabric (Nccl 并不需要此步骤;NV-Link、NV-Switch执行)
1、 查看当前 fabric 名称
rpm -qa | grep fabric
2、卸载 fabric
1) 根据查询到的 fabric 名称执行卸载命令
eg:
yum remove nvidia-fabricmanager-465-465.19.01-1.x86_64
2) 查看是否卸载成功
执行以下命令,若无返回值则表示成功
rpm -qa | grep fabric
3、 修改 gpg 检查参数
cd /etc/yum.repos.d/ && vim cuda-rhel7.repo
修改 gpgcheck 如下:
# gpgcheck=1
gpgcheck=0
4、 yum 升级
yum update -y
5、 安装新版本的 fabric
yum install -y cuda-drivers-fabricmanager nvidia-fabric-manager
6、查看是否成功安装
rpm -qa | grep fabric
7、启动 fabric
nv-fabricmanager
8、查看是否成功启动
ps -ef | grep fabric
六,重启并验证
1、重启
reboot
2、验证
1) 查看 GPU 显卡状态是否正常
nvidia-smi