作者 | 陈巍 责编 | 曾浩辰
出品 | NPCon(新程序员大会)
人工智能不断刷新技术高度,创造出了令人瞩目的创新成果。大模型作为一项引人注目的前沿技术,各类团队摩拳擦掌想把它植入自己的产品中去。但大模型技术深奥,团队面临部署复杂、运算成本、数据隐私等诸多挑战。在这个充满前景的领域中,如何应对大模型部署的困难?
千芯科技董事长、知乎科技领域答主陈巍(@陈巍谈芯)在 NPCon 北京站的演讲中指出,仅仅追求模型的高精度是不够的,低成本的模型运维同样至关重要。从多个角度出发,陈巍介绍了部署大模型不同的挑战并提出解决方案,以减少训练和推理的时间和成本,降低模型的规模和复杂度,加快训练速度等,为行业部署LLM提供了有效的建议和思路,拓展了思维边界,激发了大家对大模型部署的深刻思考。
本次分享主要包含五块内容,分别是:
一、大模型之前:Transformer 同时促进语言和图像算法
二、大模型的 What 和 How
三、LLM 部署架构
四、不只是模型:部署的额外考量
五、LLMOps 是如何解决这些问题的?
六、芯片选择有妙招

七、现场互动提问

大模型之前:Transformer 同时促进语言和图像算法
大模型部署在 AI 领域至关重要,因为其效果决定着能否获得资金支持。仅有模型的高精度并不足够,低成本模型的运维也很关键。从我们的主要 AI 和算法视角来看,早期阶段涵盖了视觉和语言模型,而语言模型最初并不是焦点,产业进展较慢。
然而,随着近年来 Transformer 技术的突破,人们开始认识到 Transformers 技术不仅可用于语音、语义识别,还可以应用于视觉领域。在 Transformer 架构的基础上,我们将整个语音、语义和图像算法领域进行了统一。当然,Transformer 并不是一个终极架构,更多更高效的算法也在出现。
大模型的本质有不同的解释。从我们多年的经验来看,大模型是人类在客观实践中对客观事物的认知。它是知识的高度压缩和反馈,其中知识压缩是存储过程,而反馈则是计算过程。模型的大小通常反映了存储的知识量和反馈的复杂度能力,这两者总体上反映了模型的整体能力。大模型的出现并没有明显增加计算要求,相反,它提升了部署方面的需求。

大模型的 What 和 How
在大模型的生命周期中,通常分为四个阶段。第一个阶段是模型或项目的计划(Scoping),第二阶段是关键数据的高质量收集(Data Collection),第三阶段是模型建模(Modeling),第四阶段是模型部署(Deployment)。模型建模和部署阶段通常需要最多的时间和成本,特别是对于大模型的应用,这会成为项目成功的关键因素,也是大模型技术的核心。
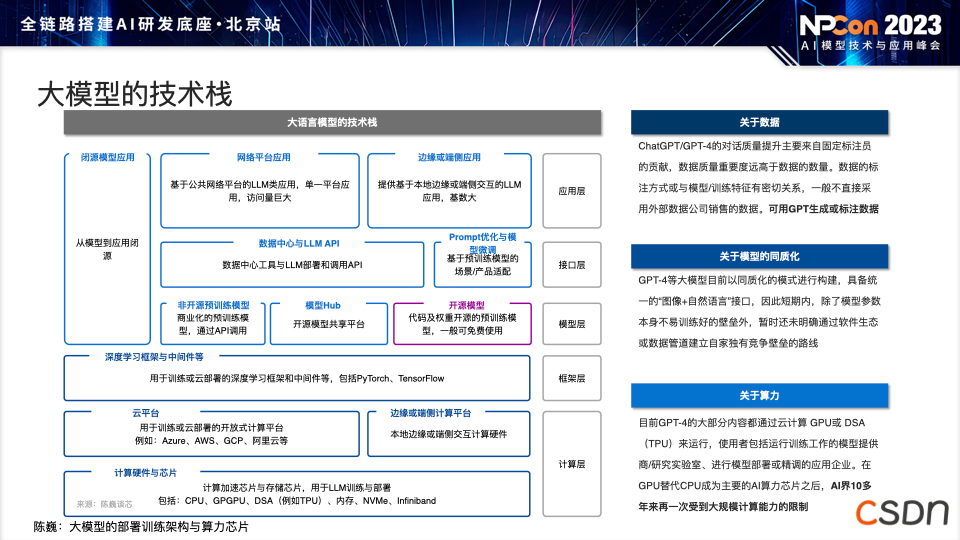
此图为总结的大模型技术栈,从下而上分为计算层、框架层、模型层、接口层、应用层。中间的开源模型很重要。目前,中国国内的大模型已经是百模大战甚至千模大战,处于快速发展的阶段。开源模型使许多没有大模型训练条件的程序员可以直接使用开源模型进行相应的应用部署,但在部署过程中有一些问题需要注意。
数据量并不是越多越好,过多的数据之间可能导致遗忘效果,以及模型本身在各种冲突信息中学到一些不好的东西。
随着模型的不断增多,许多模型都采用了 Transformer 或类似于 LLaMA 的架构,模型的同质化现象愈发常见。
大模型部署和训练对芯片的算力和存力提出了很高的要求,AI 界由于大模型第一次受到了 CPU 和 GPU 的硬件支撑限制。

从大模型的应用角度来看,它可以分为三个典型阶段和分类。第一是需要实际物理操作的环境,例如机器人、自动驾驶等。第二是基于图形操作界面(GUI)的工具。第三是编程工具中大模型发挥的作用。大模型的发展和落地可能会对所有程序员产生巨大影响,包括他们的工作方式和习惯。我们需要适应这种新的发展趋势,

LLM 部署架构

从下至上:
知识层:由三个方面组成:向量数据库、应用场景内部的搜索引擎、外部的搜索引擎(如百度和 Bing )。
模型层:LLM 模型并不单一,通常会有一个通用的主模型,以应对各种不同情况。此外,还可能加入专家模型,以回答一些专业或技术性问题。还有向量化模型,通常比主模型小得多,用于判断用户输入的问题与数据库中哪些最相似。安全模型也是必要的,用于审查模型的输出,确保没有不良或有偏见的内容。
服务层:将大模型整合到不同的行业大模型中。这可以通过IOM框架将大模型连接到不同的行业大模型上,而无需重新部署整个环境。此外,生成也是一个重要的环节,它涉及模型的输出。
交互层:用户与大模型的互动。
分流层:因为通常我们部署不只面向几个客户,而是面向成千上万甚至数百万的客户。分流可以将客户分类,以满足不同类型客户的质量需求,并缓存客户的对话,以防止潜在的攻击和信息泄露。

不只是模型:部署的额外考量
数据库:实际的大型对话模型部署需要考虑到文档和语料库,其中存储了与应用场景相关的各种信息和知识。这个过程体现了人类智慧的重要性。在使用时,我们会在存储向量上进行切片,将问题输入大模型。大模型在使用时不仅仅是根据问题进行回答,它实际上会根据问题以及从向量数据中检索到的最相关知识进行综合。这就像一个中学生或大学生分析问题,提取相关信息,然后提供答案。因此,大模型不仅仅是一个模型本身,对数据库的要求也是全新的。
许可证:开源模型对整个行业做出了重要贡献,尤其是在中国涌现的许多开源模型。它的快速发展使得许多没有大模型训练条件的开发者可以直接使用这些模型来部署应用。开源模型有不同的使用限制,例如有些只用于学术目的而不允许商用,或者有使用限制、需要与模型发布者登记,因此使用时需要注意许可证。
微调(Finetune):通过逐步迭代,将一个相对较小的模型调整为行业大模型,从而降低大模型部署的成本,将简单问题用简单模型处理,复杂问题用高精度模型解决。但随着模型规模变大,微调模型所有参数的可行性越来越低。我们可以使用LoRA(Low-Rank Adaptation,低秩适应/低秩调整),主要依靠低秩维度的内容做降维再升维的操作以减小大模型微调的成本,这对于很多企业成本是较小的。
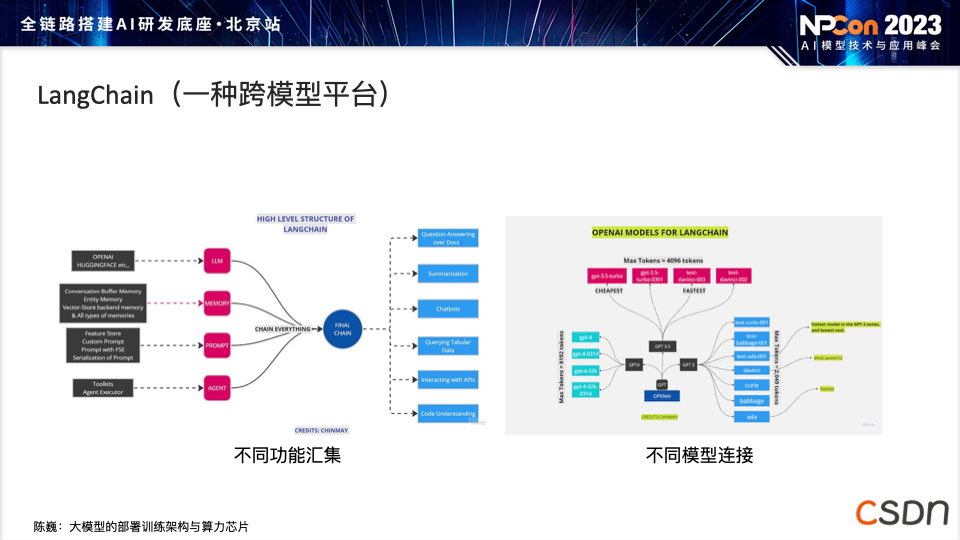
LangChain:一种跨模型平台,旨在为各行业的大模型部署提供高效、灵活的解决方案。这一平台的设计理念在于,在完成一次成功的模型部署后,能够快速地将模型适配到不同领域,实现快速服务的转型。通过 LangChain 架构,将原本规模相对较小的模型迁移至相关行业的大模型,同时实现模型之间的灵活连接,从而降低整体的运算成本。
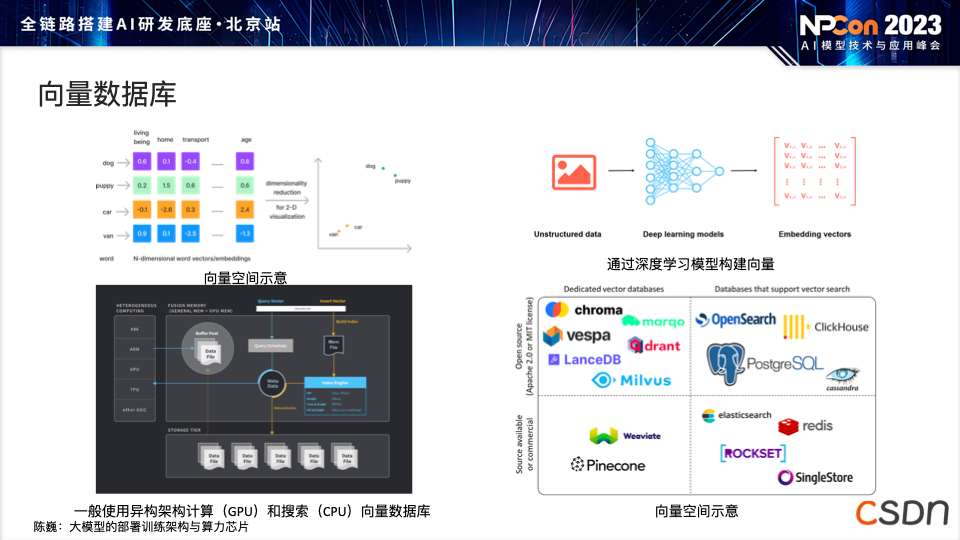
向量数据库:能够通过将不同语料转化为向量表示,快速赋予模型特定领域的知识(如编程领域的半专家水平)。通过整合高质量的语料和回答,向量数据库提升了模型在问题回答等任务中的表现,使相关语料在向量空间中聚集,从而提高模型的语义理解能力。虽然向量数据库可能规模庞大,甚至超过几 TB,但在部署时常采用在 CPU 上运行的方式。开源的向量数据库包括 m3e、text2vec等。
大模型的压缩:使用传统深度学习常用的技巧,帮助大模型减少占用内存,例如量化(最常见)、剪枝、蒸馏,将 fp32(单精度)、fp16、bfloat16(半精度)量化部署为 int8 或 int4。
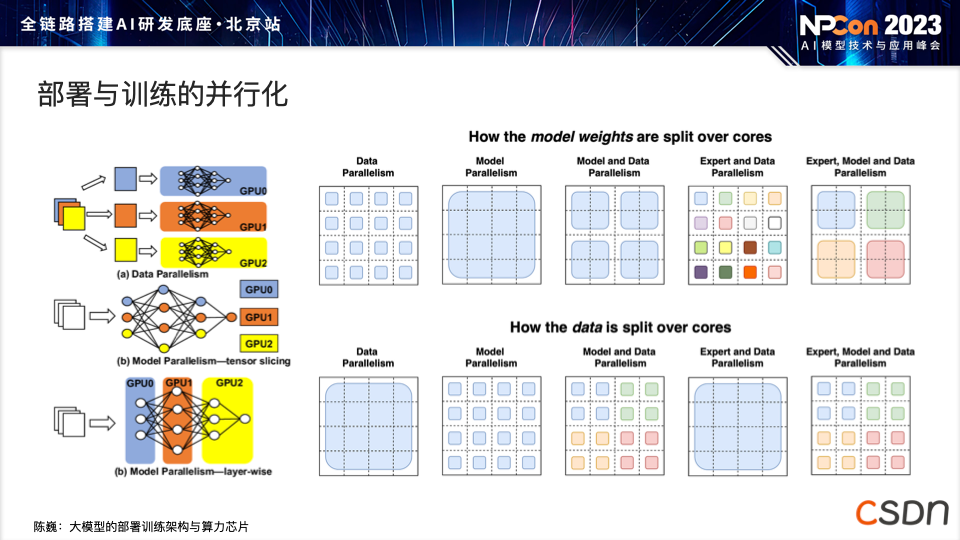
部署与训练的并行化:在之前的 GPU、TPU 部署和训练中,我们注意到模型训练速度相对较慢,但实际上有一些软件技术可以提升训练效率。因此,我们会使用各种并行化技术,如数据并行、模型并行以及其他形式的张量并行,充分利用计算芯片内部资源,尽可能减少通信时间中的数据传输,以避免为每个GPU或计算芯片传输整个训练数据时的冗余或重复文件。通过ZeRO技术,我们只传输每个计算器所需的相关信息,并进行局部更新,从而有效减少不同计算芯片之间的冗余数据传输。
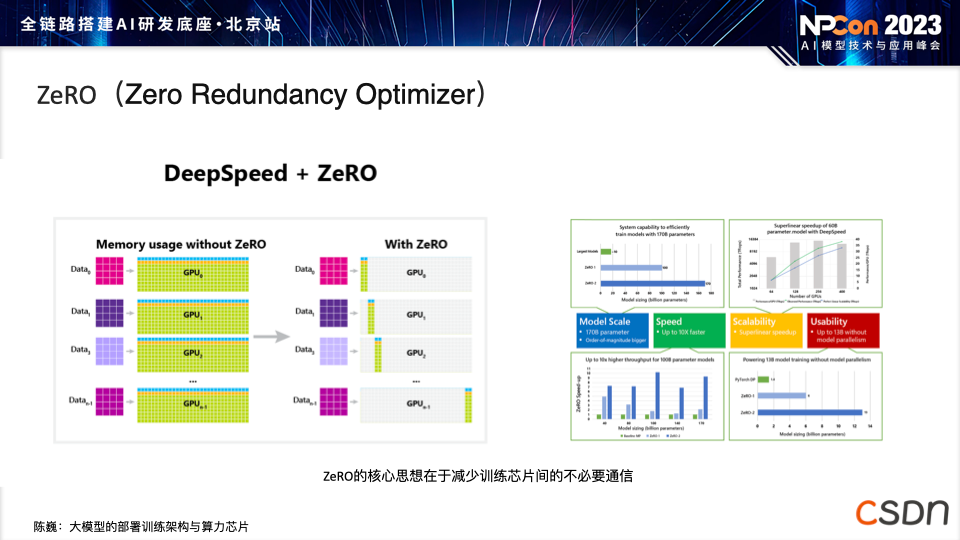
ZeRO(Zero Redundancy Optimizer):可用于减少数据传输中的冗余,以提升训练效率。通过巧妙的通信策略,ZeRO 能够将模型参数有效地分布到各个计算芯片上,避免冗余数据的传输,从而降低通信时间和数据带宽的开销。
隐私问题:由于模型可能包含敏感信息,特别是在给予个性化数据时,隐私保护技术是必要的。通常,会采用隐私保护技术,将不同的隐私数据融合起来,通过识别个人信息形成敏感信息的整体数据量。这个过程通常在 Fine-Tuning 过程中进行,同时会有相应机制来限制模型输出信用卡账号等隐私信息。最后可能需要进行审核,确定整个信息隐私集,以避免过于隐私或机密的信息被泄露。

芯片选择有妙招

计算芯片选择影响整体部署成本。GPU、TPU 和 DSA 是常见的选择。GPU 在生态上应用广泛,但成本可能相对较高。TPU 和 DSA 在大模型部署中可以降低成本,并通过高速互联进行通信。
使用 CPU 可以降低部署成本,CPU 有两种使用方式:
一是通过 CPU 和内存进行向量数据库检索,无需 GPU,充分利用空闲 CPU;
二是购买云服务时,CPU 和 GPU 的使用时间通常一起购买。在计算群使用 GPU 训练时,云服务可以将闲置的 CPU 用于大型模型的部署,降低边际成本,获得算力支持。
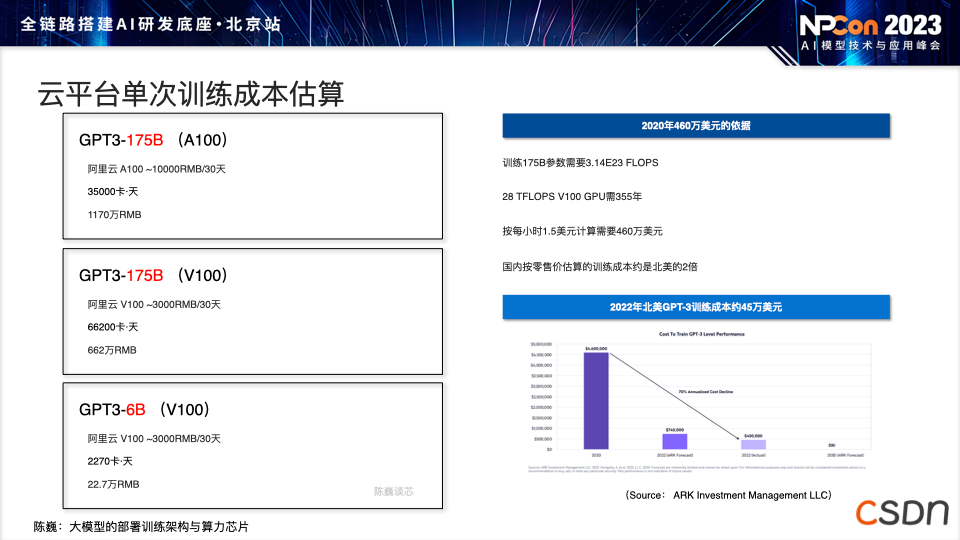
尽管现有的 GPU 正在通过更大规模集群提高训练速度和质量,但它们对训练的影响不如在实际部署和应用中显著。高端 GPU 导致许多场景高成本使用,部署时可能出现 GPU 供应不足情况,而目前先进芯片面临的各种生产及使用限制将促使GPU成 本更高。因此,我们要关注新兴技术和创新解决方案,以克服 GPU 供应和成本问题。

现场互动提问
问:基于存算一体的架构,以基本计算为例,存在哪些可提高效率、降低成本的技术路径?
陈巍:这个问题涉及到较为专业的领域。在大模型的计算中,主要涉及大量数据的相关计算。目前,我们已经在使用一些技术(如 GPU )以实现精准计算。最新的技术趋势是存内计算,通过这种方式可以大幅减少数据传输,降低成本,并提高芯片的可持续性。这对大模型的部署来说,有助于降低成本、提高部署的性价比,因为我们可以避免使用昂贵但规模较小的 GPU 芯片。
问:对于大模型,尤其是接受用户反馈后的下一步训练过程,如果遭遇大量恶意用户提供错误信息或垃圾数据,是否会影响大模型的准确性?另外,有人质疑大模型是未来真正人工智能的方向,认为其只是数据的机械化处理,不具备真正的智能。您对此有何看法?
陈巍:关于第一个问题,大模型在使用过程中如果受到恶意信息干扰,导致暴力、偏见或言辞不当的回答,实际上在部署和训练时,我们会对模型数据进行精练,避免引入有偏见的数据。我们通常会使用相对较小的模型对数据进行分析,从中筛选出质量较高的数据,避免模型受到不良数据的影响。一般来说,在大模型领域,这种情况相对较小。

关于第二个问题,是否大模型是未来真正人工智能的方向,这是一个引发争议的话题。从技术的角度来看,大模型取得了重大突破,可以处理复杂的任务。然而,与人类相比,大模型仍存在一定差距。大模型更像是一种基于反馈和知识库的智能,无法像人类一样进行独立思考和创新。它更像是将人类知识进行压缩,以特定方式回答问题。从这个角度来看,大模型仍有进一步发展的空间。
问:一些全球重要公司,如谷歌、苹果等,禁止员工使用像ChatGPT这样的人工智能工具,因为可能会存在机密泄露的风险。您对这种情况有何看法?
陈巍:目前我们使用的 ChatGPT 或 GPT-4 等模型会收集对话和信息,而一些半导体和大型 IT 公司禁止员工使用这些人工智能工具。原因有两方面,一是为了避免关键敏感信息在公网上传输,二是为了防止这些工具收集敏感信息。
然而,我认为这也为产业带来了机遇,因为真正落地应用最多的可能是在每个公司甚至每个人的私有大模型上。换句话说,如果每个人都拥有一个专门针对自己的大模型,可以根据工作领域和专业领域构建知识库,将模型部署在个人家庭或工作环境中,这将极大地提高效率。这种私有化部署可以有效解决安全问题,未来可能会形成一个巨大的市场。

