相关博客
【Megatron-DeepSpeed】张量并行工具代码mpu详解(四):张量并行版Embedding层及交叉熵的实现及测试
【Megatron-DeepSpeed】张量并行工具代码mpu详解(三):张量并行层的实现及测试
【Megatron-DeepSpeed】张量并行工具代码mpu详解(一):并行环境初始化
【Megatron-DeepSpeed】张量并行工具代码mpu详解(二):Collective通信操作的封装mappings
【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
【深度学习】混合精度训练与显存分析
【深度学习】【分布式训练】Collective通信操作及Pytorch示例
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
Megatron-DeepSpeed是DeepSpeed版本的NVIDIA Megatron-LM。像BLOOM、GLM-130B等主流大模型都是基于Megatron-DeepSpeed开发的。这里以BLOOM版本的Megetron-DeepSpeed为例,介绍其张量并行代码mpu的细节(位于megatron/mpu下)。
理解该部分的代码需要对张量并行的原理以及集合通信有一定的理解,可以看文章:
- 【深度学习】【分布式训练】Collective通信操作及Pytorch示例
- 【深度学习】【分布式训练】一文捋顺千亿模型训练技术:流水线并行、张量并行和3D并行
- 【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
阅读建议:
- 本文仅会解析核心代码,并会不介绍所有代码;
- 本文会提供一些测试脚本来展现各部分代码的功能;
- 建议实际动手实操来加深理解;
- 建议对Collective通信以及分布式模型训练有一定理解,再阅读本文;
一、总览
mpu目录下核心文件有:
- initialize.py:负责数据并行组、张量并行组和流水线并行组的初始化,以及获取与各类并行组相关的信息;
- data.py:实现张量并行中的数据广播功能;
- cross_entropy.py:张量并行版本的交叉熵;
- layers.py:并行版本的Embedding层,以及列并行线性层和行并行线性层;
- mappings.py:用于张量并行的通信操作;
二、初始化原理
Megatron-Deepspeed框架能够支持3D并行,而3D并行中显卡如何分配成不同的组等工作就是由mpu目录下的initialize.py完成的。
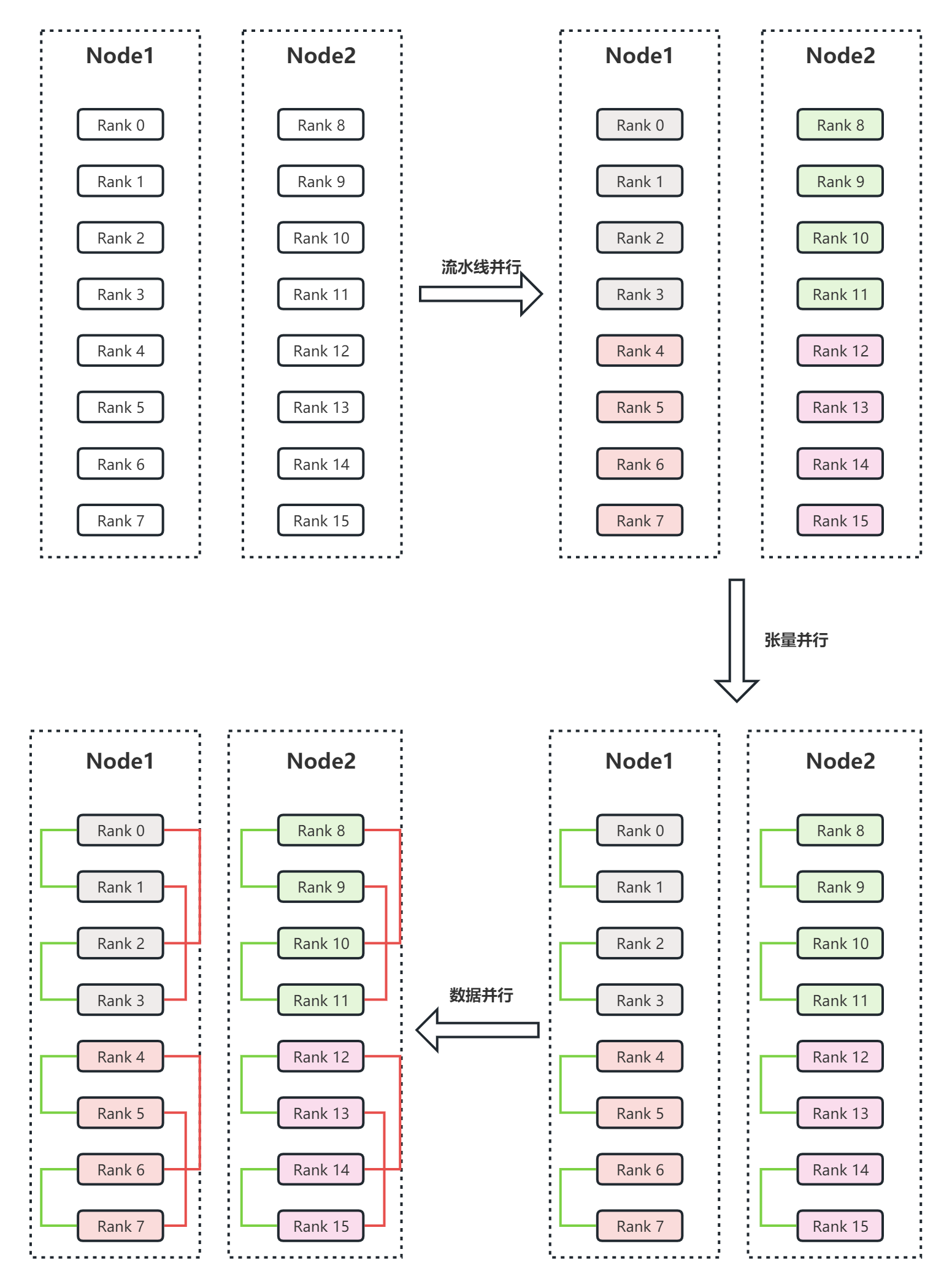
假设有两个节点Node1和Node2,每个节点有8个GPU,共计16个GPU。16个GPU的编号分别为Rank0、Rank1、…、Rank15。此外,假设用户设置流水线并行度为4,张量并行度为2。
-
流水线并行
流水线并行会将整个模型划分为4份,这里称为sub_model_1至sub_model_4。每连续的4张GPU负责一个sub_model。即上图右上角中,相同颜色的GPU负责相同的sub_model。
每个流水线并行组对应一个完整的模型,最终的流水线并行组:
[Rank0, Rank4, Rank8, Rank12], [Rank1, Rank5, Rank9, Rank13], [Rank2, Rank6, Rank10, Rank14], [Rank3, Rank7, Rank11, Rank15], -
张量并行
张量并行会针对流水线并行中的sub_model来进行张量的拆分。即Rank0和Rank1负责一份sub_model_1,Rank2和Rank3负责另一份sub_model_1;Rank4和Rank5负责sub_model_2,Rank6和Rank7负责另一份sub_model_2;以此类推。上图右下角中,绿色线条表示单个张量并行组,每个张量并行组都共同负责某个具体的sub_model。
最终的张量并行组:
[Rank0, Rank1], [Rank2, Rank3], [Rank4, Rank5], [Rank6, Rank7], [Rank8, Rank9], [Rank10, Rank11], [Rank12, Rank13], [Rank14, Rank15], -
数据并行
数据并行的目的是要保证并行中的相同模型参数读取相同的数据。经过流水线并行和张量并行后,Rank0和Rank2负责相同的模型参数,所以Rank0和Rank2是同一个数据并行组。上图左上角中的红色线条表示数据并行组。
[Rank0, Rank2], [Rank1, Rank3], [Rank4, Rank6], [Rank5, Rank7], [Rank8, Rank10], [Rank9, Rank11], [Rank12, Rank14], [Rank13, Rank15],
三、初始化代码
这里不对代码的所有细节进行解析。理解上面的原理后,细节部分只要花些时间即可弄明白。这里仅对整体的代码结构或者某些有代表性的函数进行说明。
总的来说,初始化的目标就是要赋予下面这些变量具体的值。
# Intra-layer model parallel group that the current rank belongs to.
_TENSOR_MODEL_PARALLEL_GROUP = None
# Inter-layer model parallel group that the current rank belongs to.
_PIPELINE_MODEL_PARALLEL_GROUP = None
# Model parallel group (both intra- and pipeline) that the current rank belongs to.
_MODEL_PARALLEL_GROUP = None
# Embedding group.
_EMBEDDING_GROUP = None
# Data parallel group that the current rank belongs to.
_DATA_PARALLEL_GROUP = None
_VIRTUAL_PIPELINE_MODEL_PARALLEL_RANK = None
_VIRTUAL_PIPELINE_MODEL_PARALLEL_WORLD_SIZE = None
# These values enable us to change the mpu sizes on the fly.
_MPU_TENSOR_MODEL_PARALLEL_WORLD_SIZE = None
_MPU_PIPELINE_MODEL_PARALLEL_WORLD_SIZE = None
_MPU_TENSOR_MODEL_PARALLEL_RANK = None
_MPU_PIPELINE_MODEL_PARALLEL_RANK = None
# A list of global ranks for each pipeline group to ease calculation of the source
# rank when broadcasting from the first or last pipeline stage
_PIPELINE_GLOBAL_RANKS = None
初始化功能的核心是函数 initialize_model_parallel,其主要的参数就是用户指定的张量并行数tensor_model_parallel_size_以及流水线并行数pipeline_model_parallel_size_。基于这两个用户参数来计算出各种分组。
def initialize_model_parallel(tensor_model_parallel_size_=1,
pipeline_model_parallel_size_=1,
virtual_pipeline_model_parallel_size_=None):
...
其余的函数主要功能是:获得初始化状态、获得当前rank所在的组、获得当前进行所在特定组里的rank等。这里功能会在后续的测试代码里展示具体的应用。
此外,官方代码中的函数 destroy_model_parallel中应该是存在bug,下面是可正常运行的版本:
def destroy_model_parallel():
"""Set the groups to none."""
global _TENSOR_MODEL_PARALLEL_GROUP
_TENSOR_MODEL_PARALLEL_GROUP = None
global _PIPELINE_MODEL_PARALLEL_GROUP
_PIPELINE_MODEL_PARALLEL_GROUP = None
global _DATA_PARALLEL_GROUP
_DATA_PARALLEL_GROUP = None
# 以下为新增
global _MODEL_PARALLEL_GROUP
_MODEL_PARALLEL_GROUP = None
global _EMBEDDING_GROUP
_EMBEDDING_GROUP = None
四、测试代码
1. 测试设置
- 测试使用8张GPU;
- 张量并行度为2,流水线并行度为2;
- 依据上面介绍的原理,流水线并行组为:[Rank0, Rank4],[Rank1, Rank5],[Rank2, Rank6], [Rank3, Rank7]
- 依据上面介绍的原理,张量并行组为:[Rank0, Rank1],[Rank2, Rank3],[Rank4,Rank5],[Rank6,Rank7]
- 依据上面介绍的原理,数据并行组为: [Rank0, Rank2],[Rank1, Rank3],[Rank4,Rank6],[Rank5,Rank7]
2. 辅助代码
这里的辅助代码仍然使用原始单元测试的代码,即/megatron/mpu/tests/commons.py。 下面会对这些代码进行简单的注释。
# commons.py
import sys
sys.path.append("..")
import argparse
import os
import random
import numpy
import torch
import megatron.mpu as mpu # 由于本文测试代码位于项目的根目录下,因此修改了mpu的import方式
class IdentityLayer(torch.nn.Module):
"""
一个单层网络,会在测试cross_entropy.py时使用。
"""
def __init__(self, size, scale=1.0):
super(IdentityLayer, self).__init__()
self.weight = torch.nn.Parameter(scale * torch.randn(size))
def forward(self):
return self.weight
def set_random_seed(seed):
"""Set random seed for reproducability."""
random.seed(seed)
numpy.random.seed(seed)
torch.manual_seed(seed)
mpu.model_parallel_cuda_manual_seed(seed)
def initialize_distributed(backend='nccl'):
"""初始化分布式环境"""
# Get local rank in case it is provided.
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', type=int, default=None,
help='local rank passed from distributed launcher')
args = parser.parse_args()
local_rank = args.local_rank
# Get rank and world size.
rank = int(os.getenv('RANK', '0')) # 当前进程所对应的rank(rank是显卡所对应的全局编号)
world_size = int(os.getenv("WORLD_SIZE", '1')) # world_size是指所有可用显卡的数量
print('> initializing torch.distributed with local rank: {}, '
'rank: {}, world size: {}'.format(local_rank, rank, world_size))
# Set the device id.
device = rank % torch.cuda.device_count()
if local_rank is not None:
device = local_rank
torch.cuda.set_device(device)
# 初始化分布式环境所需要的相关代码
init_method = 'tcp://'
master_ip = os.getenv('MASTER_ADDR', 'localhost')
master_port = os.getenv('MASTER_PORT', '6000')
init_method += master_ip + ':' + master_port
torch.distributed.init_process_group(
backend=backend, # 使用gpu时,backend最好选择nccl
world_size=world_size,
rank=rank,
init_method=init_method)
def print_separator(message):
"""
输出辅助函数
"""
torch.distributed.barrier() # 保证所有进程在此处保存同步,主要是为了防止多进行输出混乱
filler_len = (78 - len(message)) // 2
filler = '-' * filler_len
string = '\n' + filler + ' {} '.format(message) + filler
if torch.distributed.get_rank() == 0:
print(string, flush=True)
torch.distributed.barrier()
3. 测试代码
3.1 测试代码
为了展示各个函数的功能,这里并不使用原始项目中的测试代码,而是单独撰写的代码。
# test_initialize.py
import sys
sys.path.append("..")
from commons import print_separator
from commons import initialize_distributed
import megatron.mpu as mpu
import torch
def run_test(
tensor_model_parallel_size: int,
pipeline_model_parallel_size:int):
print_separator(f'> Test: TP={
tensor_model_parallel_size}, PP={
pipeline_model_parallel_size}')
mpu.initialize_model_parallel(
tensor_model_parallel_size,
pipeline_model_parallel_size) # 并行初始化
world_size = torch.distributed.get_world_size() # world_size, 总GPU数量
global_rank = torch.distributed.get_rank() # 当前GPU的编号
tp_world_size = mpu.get_tensor_model_parallel_world_size() # 每个张量并行组中GPU的数量
pp_world_size = mpu.get_pipeline_model_parallel_world_size() # 每个流水线并行组中GPU的数量
dp_world_size = mpu.get_data_parallel_world_size() # 每个数据并行组中的GPU数量
tp_rank = mpu.get_tensor_model_parallel_rank() # 在张量并行组中的编号
pp_rank = mpu.get_pipeline_model_parallel_rank() # 在流水线并行组中的编号
dp_rank = mpu.get_data_parallel_rank() # 在数据并行组中的编号
tp_group = mpu.get_tensor_model_parallel_group()
tp_group = torch.distributed.distributed_c10d._pg_group_ranks[tp_group] # 当前GPU所在张量并行组的映射字典
pp_group = mpu.get_pipeline_model_parallel_group()
pp_group = torch.distributed.distributed_c10d._pg_group_ranks[pp_group] # 当前GPU所在流水线并行组的映射字典
dp_group = mpu.get_data_parallel_group()
dp_group = torch.distributed.distributed_c10d._pg_group_ranks[dp_group] # 当前GPU所在数据并行组的映射字典
torch.distributed.barrier()
info = f"="*20 + \
f"\n> global_rank={
global_rank}\n" + \
f"> world_size={
world_size}\n" + \
f"> tp_world_size={
tp_world_size}\n" + \
f"> pp_world_size={
pp_world_size}\n" + \
f"> dp_world_size={
dp_world_size}\n" + \
f"> tp_rank={
tp_rank}\n" + \
f"> pp_rank={
pp_rank}\n" + \
f"> dp_rank={
dp_rank}\n" + \
f"> tp_group={
tp_group}\n" + \
f"> pp_group={
pp_group}\n" + \
f"> dp_group={
dp_group}\n"
print(info, flush=True)
torch.distributed.barrier()
if __name__ == '__main__':
initialize_distributed() # 初始化分布式环境
tensor_model_parallel_size = 2
pipeline_model_parallel_size = 2
run_test(tensor_model_parallel_size, pipeline_model_parallel_size)
3.2 启动脚本
deepspeed test_initialize.py
3.3 输出结果
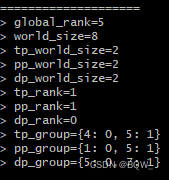
上图是Rank5的相关信息,符合前面对于其张量并行组、流水线并行组和数据并行组的分析。