文章来源 | 恒源云社区
原文地址 | 【新手指北】
一、NVIDIA显卡产品线
【主要类型】
GeForce类型:
这个系列显卡官方定位是消费级,常用来打游戏。但是它在深度学习上的表现也非常不错,很多人用来做推理、训练,单张卡的性能跟深度学习专业卡Tesla系列比起来其实差不太多,但是性价比却高很多。
Quadro类型:
Quadro系列显卡一般用于特定行业,比如设计、建筑等,图像处理专业显卡,比如CAD、Maya等软件。
Tesla类型:
Tesla系列显卡定位并行计算,一般用于数据中心,具体点,比如用于深度学习,做训练、推理等。Tesla系列显卡针对GPU集群做了优化,像那种4卡、8卡、甚至16卡服务器,Tesla多块显卡合起来的性能不会受很大影响,但是Geforce这种游戏卡性能损失严重,这也是Tesla主推并行计算的优势之一。
【常见系列】
Geforce类型-常见系列
Geforce 10系列:
GTX 1050、GTX 1050Ti、GTX 1060、GTX 1070、GTX 1070Ti、GTX 1080、GTX 1080Ti
Geforce 16系列:
GTX 1650、GTX 1650 Super、GTX 1660、GTX 1660 Super、GTX 1660Ti
Geforce 20系列:
RTX 2060、RTX 2060 Super、RTX 2070、RTX 2070 Super、RTX 2080、RTX 2080 Super、RTX 2080Ti
Geforce 30系列:
RTX 3050、RTX 3060、RTX 3060Ti、RTX 3070、RTX 3070Ti、RTX 3080、RTX 3080Ti、RTX 3090
Quadro类型-常见系列
NVIDIA RTX Series系列:
RTX A2000、RTX A4000、RTX A4500、RTX A5000、RTX A6000
Quadro RTX Series系列:
RTX 3000、RTX 4000、RTX 5000、RTX 6000、RTX 8000
Tesla类型-常见系列
A-Series系列: A10、A16、A30、A40、A100
T-Series系列: T4
V-Series系列: V100
P-Series系列: P4、P6、P40、P100
K-Series系列: K8、K10、K20c、K20s、K20m、K20Xm、K40t、K40st、K40s、K40m、K40c、K520、K80
二、GPU信息
三、性能选卡
【选择GPU】
显卡性能主要根据如下几个参数来判断:
显存:
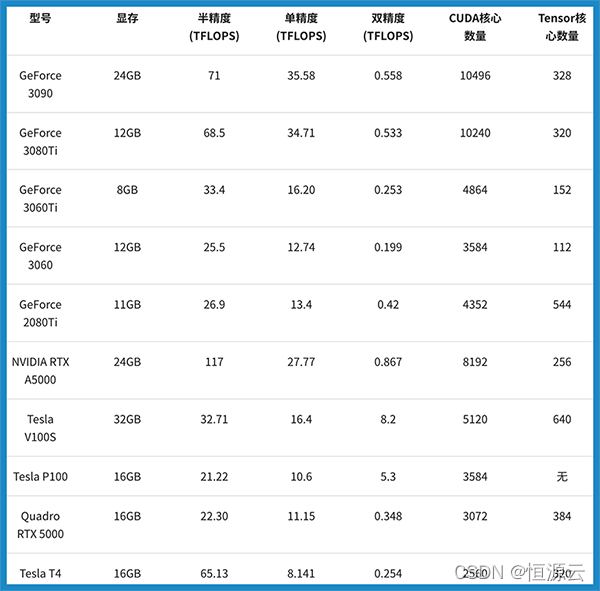
显存即显卡内存,显存主要用于存放数据模型,决定了我们一次读入显卡进行运算的数据多少(batch size)和我们能够搭建的模型大小(网络层数、单元数),是对深度学习研究人员来说很重要的指标,简述来讲,显存越大越好。
架构:
在显卡流处理器、核心频率等条件相同的情况下,不同款的GPU可能采用不同设计架构,不同的设计架构间的性能差距还是不小的,显卡架构性能排序为:Ampere > Turing > Volta > Pascal > Maxwell > Kepler > Fermi > Tesla
CUDA核心数量:
CUDA是NVIDIA推出的统一计算架构,NVIDIA几乎每款GPU都有CUDA核心,CUDA核心是每一个GPU始终执行一次值乘法运算,一般来说,同等计算架构下,CUDA核心数越高,计算能力会递增。
Tensor(张量)核心数量:
Tensor 核心是专为执行张量或矩阵运算而设计的专用执行单元,而这些运算正是深度学习所采用的核心计算函数,它能够大幅加速处于深度学习神经网络训练和推理运算核心的矩阵计算。Tensor Core使用的计算能力要比Cuda Core高得多,这就是为什么Tensor Core能加速处于深度学习神经网络训练和推理运算核心的矩阵计算,能够在维持超低精度损失的同时大幅加速推理吞吐效率。
半精度:
如果对运算的精度要求不高,那么就可以尝试使用半精度浮点数进行运算。这个时候,Tensor核心就派上了用场。Tensor Core专门执行矩阵数学运算,适用于深度学习和某些类型的HPC。Tensor Core执行融合乘法加法,其中两个44 FP16矩阵相乘,然后将结果添加到44 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵。NVIDIA将Tensor Core进行的这种运算称为混合精度数学,因为输入矩阵的精度为半精度,但乘积可以达到完全精度。Tensor Core所做的这种运算在深度学习训练和推理中很常见。
单精度:
Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
双精度:
双精度适合要求非常高的专业人士,例如医学图像,CAD。
具体的显卡使用需求,还要根据使用显卡处理的任务内容进行选择合适的卡,除了显卡性能外,还要考虑CPU、内存以及磁盘性能,关于GPU、CPU、内存、磁盘IO性能。
对于不同类型的神经网络,主要参考的指标是不太一样的。下面给出一种指标顺序的参考:
卷积网络和Transformer:Tensor核心数>单精度浮点性能>显存带宽>半精度浮点性能
循环神经网络:显存带宽>半精度浮点性能>Tensor核心数>单精度浮点性能
【选择内存】
内存应当选择采用时序频率高以及容量大的内存,虽然机器学习的性能和内存大小无关,但是为了避免GPU执行代码在执行时被交换到磁盘,需要配置足够的RAM,也就是GPU显存对等大小内存。
例如使用24G内存的Titan RTX,至少需要配置24G内存,不过,如果使用更多GPU并不需要更多内存。如果内存大小已经匹配上GPU卡的显存大小,仍然可能在处理极大的数据集出现内存不足的情况,这个时候应该升配GPU来获得比当 前双倍的内存或者更换内存更大实例。
因为内存在充足的情况下不会影响性能,如果内存使用超载则会导致进程被Killd或者程序运行缓慢情况。
【选择CPU】
在load数据过程中,就需要用到大量的CPU和内存,如果CPU主频较低或者CPU核心较少的情况下,会限制数据的读取速度,从而拉低整体训练速度,成为训练中的瓶颈。
建议选择核心较多且主频较高的的机器,每台机器中所分配的CPU核心数量可以通过创建页面查看,也可以通过CPU型号去搜索该CPU的主频和睿频的大小。
CPU的核心数量也关系到num_workers参数设置的数值,num_worker设置得大,好处是寻batch速度快,因为下一轮迭代的batch很可能在上一轮/上上一轮…迭代时已经加载好了。坏处是内存开销大,也加重了CPU负担(worker加载数据到RAM的进程是CPU进行复制)。num_workers的经验设置值是 <= 服务器的CPU核心数。
【选择磁盘】
在进行训练或者推理的过程中需要不断的与磁盘进行交互,如果磁盘IO性能较差,则同样会成为整个训练速度的瓶颈;恒源云一直推荐用户使用 /hy-tmp目录进行数据集存储和训练,因为该目录为机器本地磁盘,训练速度最快,IO效率最高。
平台的所有机器中,目前大多数机器都采用SSD高效磁盘,比传统机械磁盘速度要高几倍,还有速度更快的NVME磁盘,在进行机器选择的时可根据需要选择磁盘IO较好的磁盘。
平台中各种类型磁盘读写效率如下:
以下内容均测试为随机读/写性能,这也是磁盘在日常的使用场景,磁盘厂商所描述的3000MB+、5000MB+这种磁盘读写效率均为顺序读写,并不符合我们日常使用场景。
NVME类型磁盘: 每秒随机写 >= 1700MB 每秒随机读 >= 2400MB
SSD类型磁盘: 每秒随机写 >= 460MB 每秒随机读 >= 500MB
HDD类型磁盘: 每秒随机写 ~= 200MB 每秒随机读 ~= 200MB
四、价格选卡
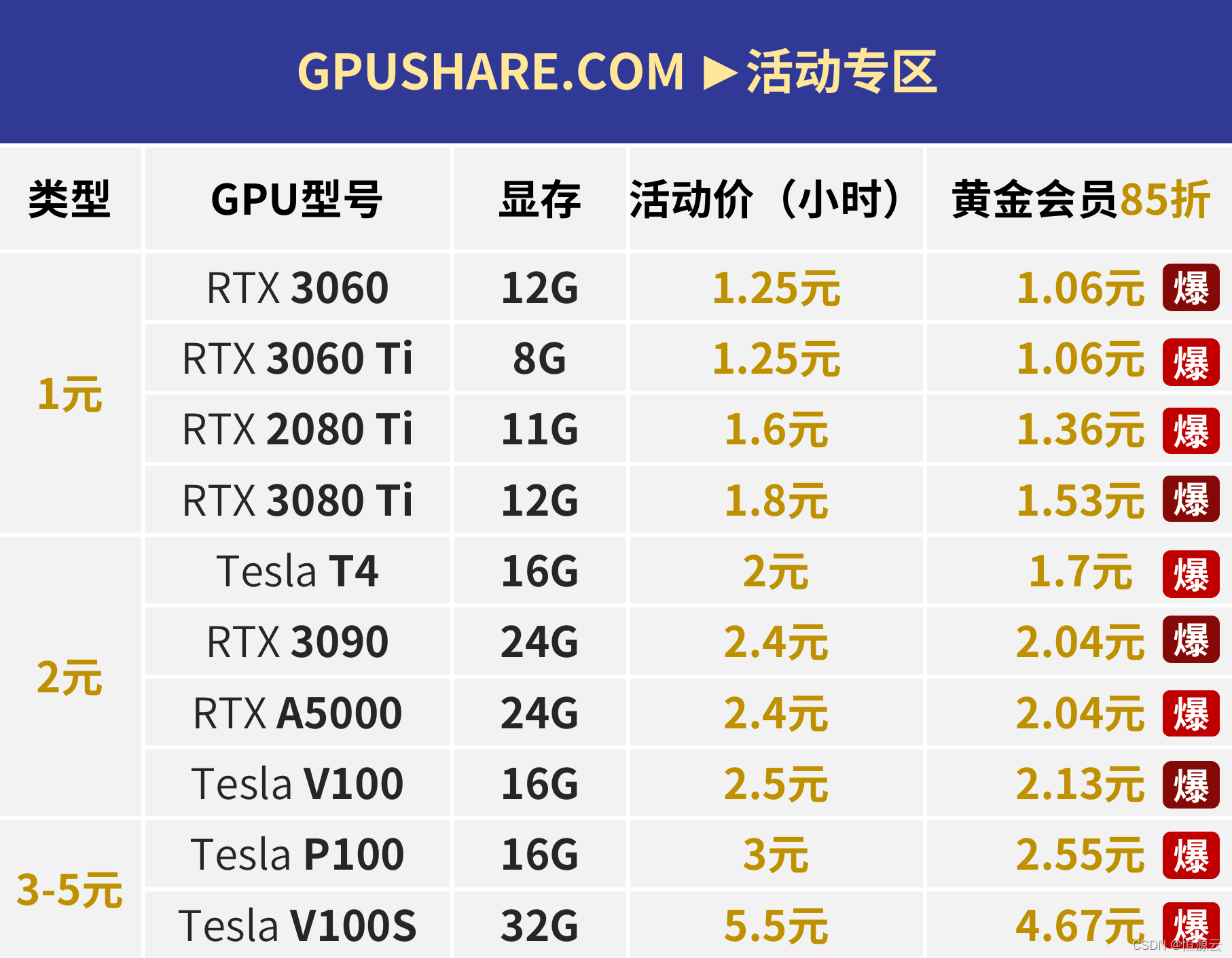
可通过云市场中的活动专区进行购卡,活动专区为当前正在进行折扣的机器,与其它同型号GPU并无差异。
可通过云市场中的代金券专区进行购卡,代金券专区中的多数机器也同样可以使用优惠券,通过完成平台给予的任务获得代金券和优惠券,以此来进行购卡。
同样可以通过云市场中的包天/周/月/年进行购卡,这种属于预付费模式,该模式适用于提前预估设备需求量的场景,价格相较于按量计费模式更低廉。
五、稳定性选卡
对于稳定性要求较高的用户可在云市场中的高可用专区进行购卡。